NVIDIA's Blackwell platform achieved fastest training times across all MLPerf Training 6.0 benchmarks, scaling to 8,192 GPUs and showcasing up to 1.6x performance gains with the GB300 NVL72 over the GB200 NVL72.
<div id="bsf_rt_marker"></div><p><span style="font-weight: 400;">Every breakthrough AI model starts the same way: with a training run. The infrastructure running those training jobs shapes everything: how fast teams can iterate, what scale of model they can build and whether those jobs complete reliably. </span></p>
<p><span style="font-weight: 400;">As models grow in size, complexity and intelligence, the demands on training infrastructure are also rising. </span></p>
<p><span style="font-weight: 400;">In MLPerf Training 6.0 — the latest of a series of rigorous, peer-reviewed industry benchmarks for evaluating AI training performance — the NVIDIA Blackwell platform led across every category, demonstrating:</span></p>
<ul>
<li style="font-weight: 400;" aria-level="1"><span style="font-weight: 400;">Fastest time to train on every benchmark</span></li>
<li style="font-weight: 400;" aria-level="1"><span style="font-weight: 400;">Largest-scale training across 8,192 GPUs using NVIDIA Blackwell NVL72 systems</span></li>
<li style="font-weight: 400;" aria-level="1"><span style="font-weight: 400;">The only platform with submissions across all seven benchmarks in the suite</span></li>
</ul>
<p><span style="font-weight: 400;">NVIDIA brings together performance, scale and reliability in a single platform engineered through extreme codesign to enable AI model builders to launch frontier models faster, minimize training costs and start generating revenue early. </span></p>
<h2><b>Performance: Fastest Time to Train on Every Benchmark</b></h2>
<p><span style="font-weight: 400;">MLPerf Training 6.0 added two new </span><a target="_blank" href="https://www.nvidia.com/en-us/glossary/mixture-of-experts/"><span style="font-weight: 400;">mixture-of-experts</span></a><span style="font-weight: 400;"> (MoE) pretraining workloads to the suite: DeepSeek-V3 671B and GPT-OSS-20B, reflecting the growing centrality of MoE architectures. The NVIDIA platform was the only one to be submitted across every benchmark, and delivered the fastest time to train on all seven.</span></p>
<p><img fetchpriority="high" decoding="async" class="alignnone wp-image-94513 size-full" src="https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide2.jpg" alt="" width="1920" height="1080" srcset="https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide2.jpg 1920w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide2-960x540.jpg 960w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide2-1680x945.jpg 1680w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide2-1280x720.jpg 1280w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide2-1536x864.jpg 1536w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide2-1290x725.jpg 1290w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide2-630x354.jpg 630w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide2-300x169.jpg 300w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide2-400x225.jpg 400w" sizes="(max-width: 1920px) 100vw, 1920px" /></p>
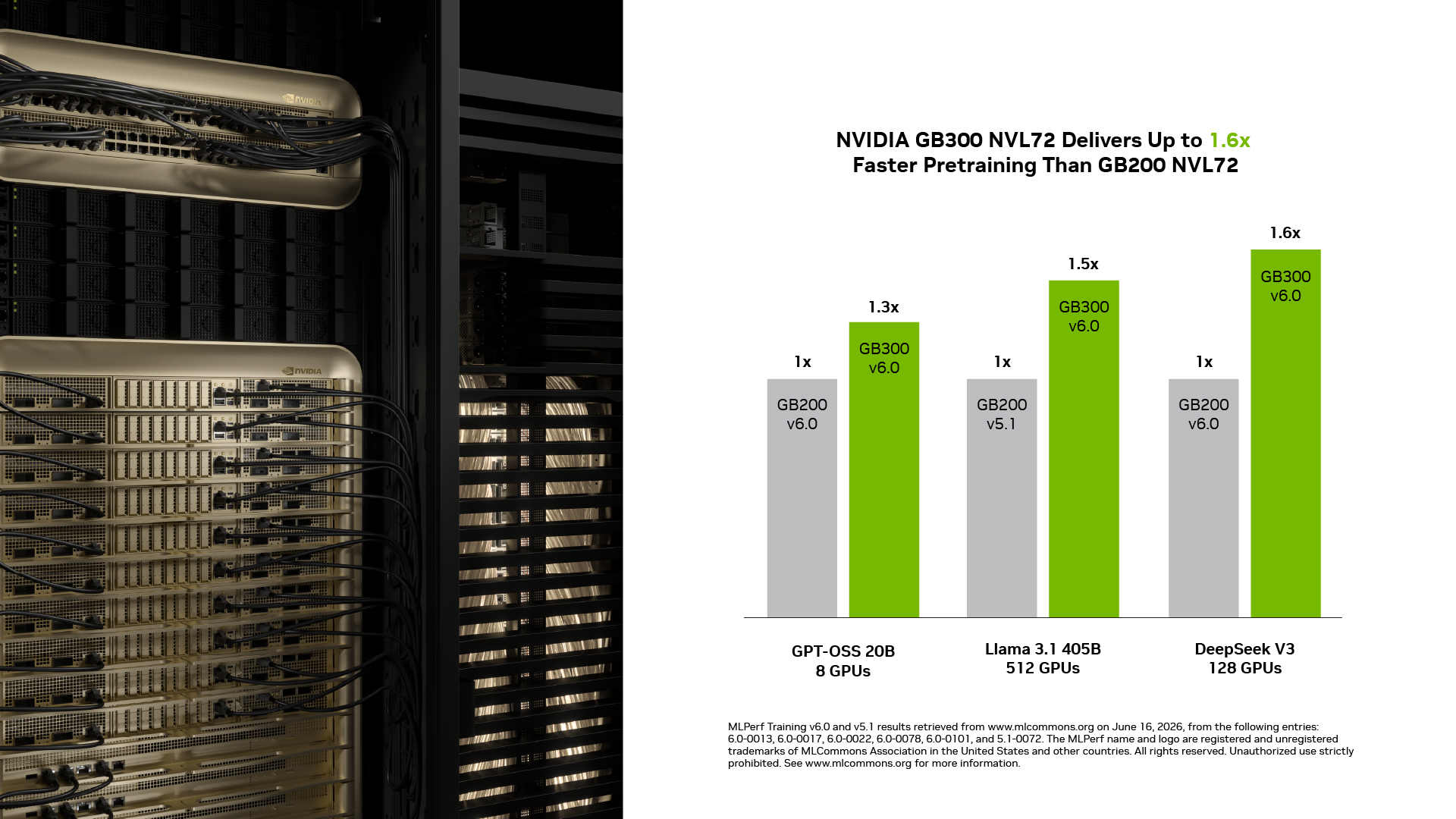
<p><span style="font-weight: 400;">This round, NVIDIA submitted results on both NVIDIA GB200 NVL72 and GB300 NVL72 rack-scale systems. Within each rack-scale system, fifth-generation NVIDIA NVLink Switches connect all 72 GPUs with high bandwidth, into a unified pool of compute and memory, enabling them to act as one giant GPU. </span></p>
<p><span style="font-weight: 400;">Large-scale MoE training faces the same all-to-all communication challenge as </span><a href="https://blogs.nvidia.com/blog/mixture-of-experts-frontier-models/"><span style="font-weight: 400;">MoE inference</span></a><span style="font-weight: 400;"> — tokens must be routed across GPUs to reach the right expert subnetwork — and NVLink’s bandwidth advantage is what makes that fast and efficient at scale. </span></p>
<p><span style="font-weight: 400;">NVIDIA also showcased NVFP4 training methods that increase performance while meeting strict accuracy requirements across large- and small-scale pretraining as well as fine-tuning workloads. NVIDIA continues to push low-precision training innovation across different model architectures, most recently using NVFP4 to pretrain the massive 550-billion-parameter </span><a target="_blank" href="https://developer.nvidia.com/blog/nvidia-nemotron-3-ultra-powers-faster-more-efficient-reasoning-for-long-running-agents/"><span style="font-weight: 400;">NVIDIA Nemotron 3 Ultra</span></a><span style="font-weight: 400;"> model.</span></p>
<p><b>NVIDIA GB300 NVL72 Delivered up to 1.6x Performance Over GB200 NVL72: </b><span style="font-weight: 400;">In this round, GB300 NVL72 delivered up to 1.6x faster training than GB200 NVL72 at the same scale. Key Blackwell Ultra capabilities such as higher compute density with NVFP4, expanded memory capacity and a higher power ceiling that lets the GPU sustain peak performance drive this improvement.</span></p>
<p><img decoding="async" class="alignnone wp-image-94516 size-full" src="https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide1.jpg" alt="" width="1920" height="1080" srcset="https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide1.jpg 1920w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide1-960x540.jpg 960w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide1-1680x945.jpg 1680w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide1-1280x720.jpg 1280w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide1-1536x864.jpg 1536w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide1-1290x725.jpg 1290w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide1-630x354.jpg 630w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide1-300x169.jpg 300w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide1-400x225.jpg 400w" sizes="(max-width: 1920px) 100vw, 1920px" /></p>
<h2><b>Scale: Largest Blackwell Cluster in MLPerf Training </b></h2>
<p><span style="font-weight: 400;">To support distributed training at scale, NVIDIA offers two complementary scale-out networking platforms — </span><a target="_blank" href="https://www.nvidia.com/en-us/networking/quantum2/"><span style="font-weight: 400;">NVIDIA Quantum InfiniBand</span></a><span style="font-weight: 400;"> and </span><a target="_blank" href="https://www.nvidia.com/en-us/networking/spectrumx/"><span style="font-weight: 400;">NVIDIA Spectrum-X Ethernet</span></a><span style="font-weight: 400;"> — giving data centers the flexibility to build large-scale clusters optimized for their infrastructure. </span></p>
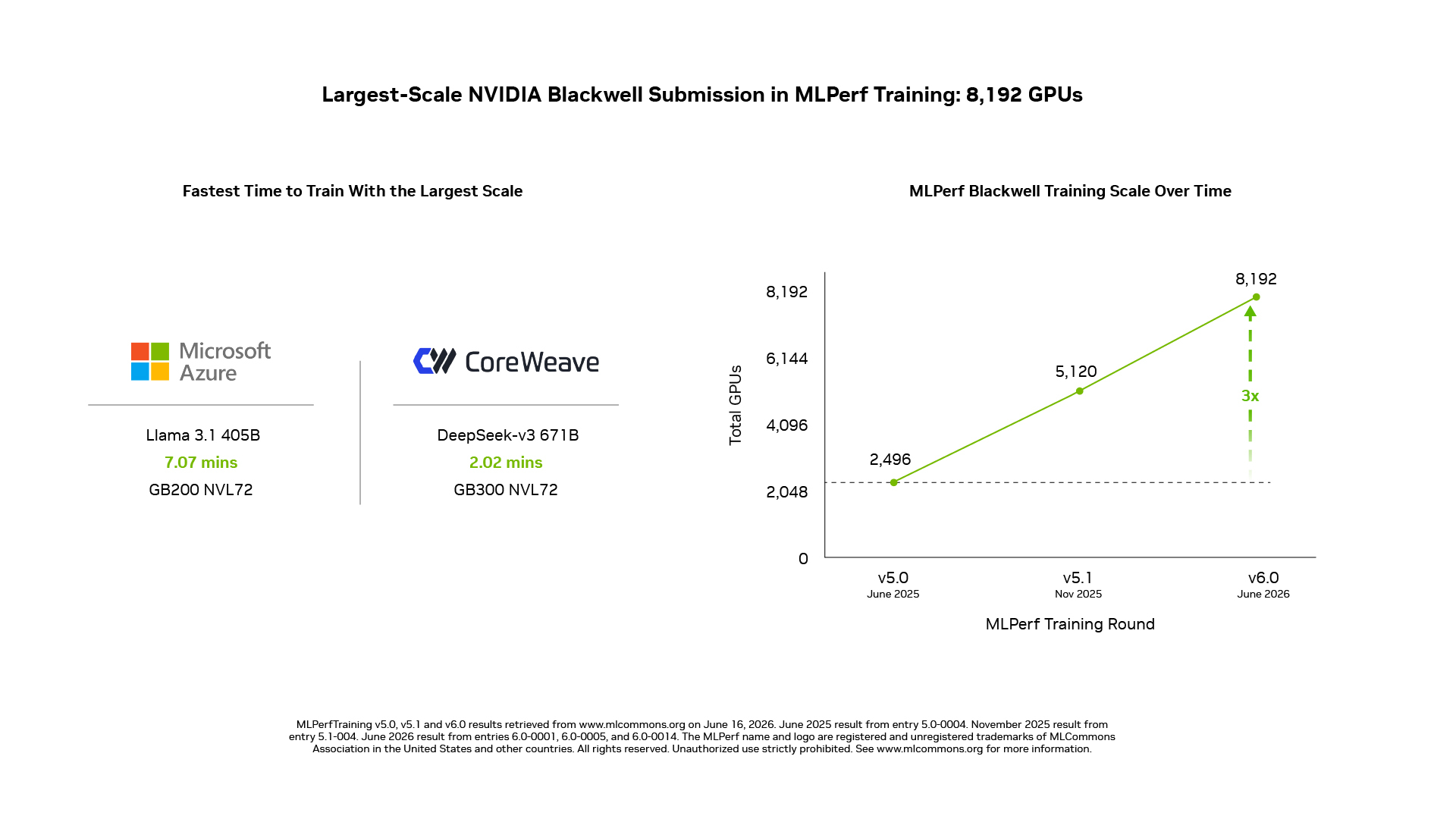
<p><span style="font-weight: 400;">On DeepSeek-V3 671B, the largest MoE model in the suite, NVIDIA scaled its submission to 8,192 GPUs using GB200 NVL72 systems, the largest-scale Blackwell-based submission in MLPerf Training to date.</span></p>
<p><span style="font-weight: 400;">NVIDIA also submitted results at 5,120 GPUs with NVIDIA GB200 NVL72 systems on Llama 3.1 405B, one of the largest dense LLMs in the suite. </span></p>
<p><img decoding="async" class="alignnone wp-image-94510 size-full" src="https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide3.jpg" alt="" width="1920" height="1080" srcset="https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide3.jpg 1920w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide3-960x540.jpg 960w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide3-1680x945.jpg 1680w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide3-1280x720.jpg 1280w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide3-1536x864.jpg 1536w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide3-1290x725.jpg 1290w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide3-630x354.jpg 630w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide3-300x169.jpg 300w, https://blogs.nvidia.com/wp-content/uploads/2026/06/end-to-end-graphics-mlperf-6.0-training-charts-5311563-v6_Slide3-400x225.jpg 400w" sizes="(max-width: 1920px) 100vw, 1920px" /></p>
<p><span style="font-weight: 400;">This round’s results also reflect the deep co-engineering between NVIDIA and its partners on system architecture, networking and software:</span></p>
<ul>
<li style="font-weight: 400;" aria-level="1"><span style="font-weight: 400;">Microsoft Azure </span><span style="font-weight: 400;">scaled Llama 3.1 405B training to 8,192 GPUs using GB200 NVL72 systems, and reached the reference quality target in 7.07 minutes, the fastest time to train for this benchmark.</span></li>
<li style="font-weight: 400;" aria-level="1"><span style="font-weight: 400;">CoreWeave </span><span style="font-weight: 400;">delivered the fastest time to train for DeepSeek-V3 671B, reaching the quality target in 2.02 minutes at 8,192-GPU scale using GB300 NVL72 systems connected with Spectrum-X Ethernet networking. </span></li>
</ul>
<h2><b>At-Scale Reliability: Built for Production</b></h2>
<p><span style="font-weight: 400;">In production training environments, runs can span weeks or months across hundreds of thousands of GPUs. At that scale, effective training throughput depends on both the performance of the system and the resiliency that makes it reproducible over time. </span></p>
<p><span style="font-weight: 400;">The MLPerf Training v6.0 results above speak to the performance of NVIDIA’s platform. For resiliency, NVIDIA’s platform is engineered across two dimensions: </span></p>
<ul>
<li><b>Fewer interruptions</b><span style="font-weight: 400;">: NVIDIA GPUs are built to avoid failures before they occur. Before a GPU reaches a data center, NVIDIA screens it across 30+ manufacturing test stages to catch potential faults early. Once deployed, the Reliability, Availability and Serviceability Engine monitors nearly the entire chip, and self-healing capabilities automatically route around detected faults without interrupting the workload. At the network level, Spectrum-X Ethernet reroutes around failed links in milliseconds, keeping the fabric healthy without disrupting the job. </span></li>
<li><b>Faster recovery when interruptions happen</b><span style="font-weight: 400;">: NVIDIA Resiliency Extension, or NVRx, minimizes the time lost when faults do occur, with capabilities spanning fault detection, recovery and health monitoring across the cluster. It automatically detects and manages underperforming nodes before they slow the rest of the cluster down. When a node experiences an interruption, rather than restarting the entire job, the system resumes from a recent checkpoint, aka a saved snapshot of the training state. </span></li>
</ul>
<h2><b>Frontier AI Built on NVIDIA </b></h2>
<p><span style="font-weight: 400;">NVIDIA ecosystem partners also participated extensively this round, with compelling submissions from 19 organizations, including</span> <span style="font-weight: 400;">ASUSTeK</span><span style="font-weight: 400;">, Microsoft </span><span style="font-weight: 400;">Azure</span><span style="font-weight: 400;">, </span><span style="font-weight: 400;">Cisco</span><span style="font-weight: 400;">, </span><span style="font-weight: 400;">CoreWeave</span><span style="font-weight: 400;">,</span><span style="font-weight: 400;"> Dell Technologies</span><span style="font-weight: 400;">, </span><span style="font-weight: 400;">Fujitsu</span><span style="font-weight: 400;">, </span><span style="font-weight: 400;">Giga Computing</span><span style="font-weight: 400;">, </span><span style="font-weight: 400;">Google Cloud</span><span style="font-weight: 400;">, </span><span style="font-weight: 400;">Hewlett Packard Enterprise</span><span style="font-weight: 400;">, </span><span style="font-weight: 400;">Inventec</span><span style="font-weight: 400;">, Krai, </span><span style="font-weight: 400;">Lambda</span><span style="font-weight: 400;">, </span><span style="font-weight: 400;">Nebius</span><span style="font-weight: 400;">, Netweb Technologies India Ltd., </span><span style="font-weight: 400;">Quanta Cloud Computing (QCT)</span><span style="font-weight: 400;">, Scitix, </span><span style="font-weight: 400;">Supermicro </span><span style="font-weight: 400;">and </span><span style="font-weight: 400;">TTA</span><span style="font-weight: 400;">. Many of these partners are running some of the most demanding AI training workloads on NVIDIA infrastructure. </span></p>
<p><span style="font-weight: 400;">CoreWeave, which houses its NVIDIA infrastructure within Dell PowerRack systems with Dell PowerEdge servers, is home to several of these workloads. </span><a target="_blank" href="https://www.coreweave.com/resources/case-studies/cohere-accelerates-training-of-north-agentic-ai-for-enterprise"><span style="font-weight: 400;">Cohere </span><span style="font-weight: 400;">achieved 3x faster training on GB200 NVL72</span></a><span style="font-weight: 400;"> for its North agentic AI platform.</span><span style="font-weight: 400;"> Midjourney,</span> <span style="font-weight: 400;">which trained its v8 image generation model on a Blackwell cluster, is now scaling a large fleet of Blackwell Ultra GPUs on </span><span style="font-weight: 400;">CoreWeave </span><span style="font-weight: 400;">to train upcoming image and video models.</span></p>
<p><a target="_blank" href="https://www.googlecloudpresscorner.com/2026-04-22-Thinking-Machines-Expands-Use-of-Google-Cloud-AI-Hypercomputer"><span style="font-weight: 400;">On </span><span style="font-weight: 400;">Google Cloud,</span><span style="font-weight: 400;"> Thinking Machines Lab</span></a><span style="font-weight: 400;"> saw 2x faster training and serving speeds on GB300 NVL72 compared with prior-generation GPUs, accelerating frontier model research and reinforcement learning workflows. </span></p>
<p><span style="font-weight: 400;">Nebius</span><span style="font-weight: 400;">, running NVIDIA Blackwell and Blackwell Ultra infrastructure on its AI cloud, </span><a target="_blank" href="https://www.nvidia.com/en-us/case-studies/higgsfield/"><span style="font-weight: 400;">enabled Higgsfield</span></a><span style="font-weight: 400;"> to reduce model training time by 30%, supporting a platform that now serves 22 million users and generates over 6 million pieces of AI content per day. </span></p>
<p><span style="font-weight: 400;">For a deeper technical look at the MLPerf Training 6.0 results and the optimizations behind them, read </span><span style="font-weight: 400;">this <a target="_blank" href="https://developer.nvidia.com/blog/nvidia-blackwell-tops-mlperf-training-6-0-with-industry-leading-scale-and-performance/">technical blog</a>.</span></p>
# Fastest, Largest, Strongest: NVIDIA Blackwell Sweeps MLPerf Training 6.0
Source: [https://blogs.nvidia.com/blog/blackwell-mlperf-training-6-0/](https://blogs.nvidia.com/blog/blackwell-mlperf-training-6-0/)
Every breakthrough AI model starts the same way: with a training run\. The infrastructure running those training jobs shapes everything: how fast teams can iterate, what scale of model they can build and whether those jobs complete reliably\.
As models grow in size, complexity and intelligence, the demands on training infrastructure are also rising\.
In MLPerf Training 6\.0 — the latest of a series of rigorous, peer\-reviewed industry benchmarks for evaluating AI training performance — the NVIDIA Blackwell platform led across every category, demonstrating:
- Fastest time to train on every benchmark
- Largest\-scale training across 8,192 GPUs using NVIDIA Blackwell NVL72 systems
- The only platform with submissions across all seven benchmarks in the suite
NVIDIA brings together performance, scale and reliability in a single platform engineered through extreme codesign to enable AI model builders to launch frontier models faster, minimize training costs and start generating revenue early\.
## **Performance: Fastest Time to Train on Every Benchmark**
MLPerf Training 6\.0 added two new[mixture\-of\-experts](https://www.nvidia.com/en-us/glossary/mixture-of-experts/)\(MoE\) pretraining workloads to the suite: DeepSeek\-V3 671B and GPT\-OSS\-20B, reflecting the growing centrality of MoE architectures\. The NVIDIA platform was the only one to be submitted across every benchmark, and delivered the fastest time to train on all seven\.

This round, NVIDIA submitted results on both NVIDIA GB200 NVL72 and GB300 NVL72 rack\-scale systems\. Within each rack\-scale system, fifth\-generation NVIDIA NVLink Switches connect all 72 GPUs with high bandwidth, into a unified pool of compute and memory, enabling them to act as one giant GPU\.
Large\-scale MoE training faces the same all\-to\-all communication challenge as[MoE inference](https://blogs.nvidia.com/blog/mixture-of-experts-frontier-models/)— tokens must be routed across GPUs to reach the right expert subnetwork — and NVLink’s bandwidth advantage is what makes that fast and efficient at scale\.
NVIDIA also showcased NVFP4 training methods that increase performance while meeting strict accuracy requirements across large\- and small\-scale pretraining as well as fine\-tuning workloads\. NVIDIA continues to push low\-precision training innovation across different model architectures, most recently using NVFP4 to pretrain the massive 550\-billion\-parameter[NVIDIA Nemotron 3 Ultra](https://developer.nvidia.com/blog/nvidia-nemotron-3-ultra-powers-faster-more-efficient-reasoning-for-long-running-agents/)model\.
**NVIDIA GB300 NVL72 Delivered up to 1\.6x Performance Over GB200 NVL72:**In this round, GB300 NVL72 delivered up to 1\.6x faster training than GB200 NVL72 at the same scale\. Key Blackwell Ultra capabilities such as higher compute density with NVFP4, expanded memory capacity and a higher power ceiling that lets the GPU sustain peak performance drive this improvement\.
## **Scale: Largest Blackwell Cluster in MLPerf Training**
To support distributed training at scale, NVIDIA offers two complementary scale\-out networking platforms —[NVIDIA Quantum InfiniBand](https://www.nvidia.com/en-us/networking/quantum2/)and[NVIDIA Spectrum\-X Ethernet](https://www.nvidia.com/en-us/networking/spectrumx/)— giving data centers the flexibility to build large\-scale clusters optimized for their infrastructure\.
On DeepSeek\-V3 671B, the largest MoE model in the suite, NVIDIA scaled its submission to 8,192 GPUs using GB200 NVL72 systems, the largest\-scale Blackwell\-based submission in MLPerf Training to date\.
NVIDIA also submitted results at 5,120 GPUs with NVIDIA GB200 NVL72 systems on Llama 3\.1 405B, one of the largest dense LLMs in the suite\.
This round’s results also reflect the deep co\-engineering between NVIDIA and its partners on system architecture, networking and software:
- Microsoft Azurescaled Llama 3\.1 405B training to 8,192 GPUs using GB200 NVL72 systems, and reached the reference quality target in 7\.07 minutes, the fastest time to train for this benchmark\.
- CoreWeavedelivered the fastest time to train for DeepSeek\-V3 671B, reaching the quality target in 2\.02 minutes at 8,192\-GPU scale using GB300 NVL72 systems connected with Spectrum\-X Ethernet networking\.
## **At\-Scale Reliability: Built for Production**
In production training environments, runs can span weeks or months across hundreds of thousands of GPUs\. At that scale, effective training throughput depends on both the performance of the system and the resiliency that makes it reproducible over time\.
The MLPerf Training v6\.0 results above speak to the performance of NVIDIA’s platform\. For resiliency, NVIDIA’s platform is engineered across two dimensions:
- **Fewer interruptions**: NVIDIA GPUs are built to avoid failures before they occur\. Before a GPU reaches a data center, NVIDIA screens it across 30\+ manufacturing test stages to catch potential faults early\. Once deployed, the Reliability, Availability and Serviceability Engine monitors nearly the entire chip, and self\-healing capabilities automatically route around detected faults without interrupting the workload\. At the network level, Spectrum\-X Ethernet reroutes around failed links in milliseconds, keeping the fabric healthy without disrupting the job\.
- **Faster recovery when interruptions happen**: NVIDIA Resiliency Extension, or NVRx, minimizes the time lost when faults do occur, with capabilities spanning fault detection, recovery and health monitoring across the cluster\. It automatically detects and manages underperforming nodes before they slow the rest of the cluster down\. When a node experiences an interruption, rather than restarting the entire job, the system resumes from a recent checkpoint, aka a saved snapshot of the training state\.
## **Frontier AI Built on NVIDIA**
NVIDIA ecosystem partners also participated extensively this round, with compelling submissions from 19 organizations, includingASUSTeK, MicrosoftAzure,Cisco,CoreWeave,Dell Technologies,Fujitsu,Giga Computing,Google Cloud,Hewlett Packard Enterprise,Inventec, Krai,Lambda,Nebius, Netweb Technologies India Ltd\.,Quanta Cloud Computing \(QCT\), Scitix,SupermicroandTTA\. Many of these partners are running some of the most demanding AI training workloads on NVIDIA infrastructure\.
CoreWeave, which houses its NVIDIA infrastructure within Dell PowerRack systems with Dell PowerEdge servers, is home to several of these workloads\.[Cohereachieved 3x faster training on GB200 NVL72](https://www.coreweave.com/resources/case-studies/cohere-accelerates-training-of-north-agentic-ai-for-enterprise)for its North agentic AI platform\.Midjourney,which trained its v8 image generation model on a Blackwell cluster, is now scaling a large fleet of Blackwell Ultra GPUs onCoreWeaveto train upcoming image and video models\.
[OnGoogle Cloud,Thinking Machines Lab](https://www.googlecloudpresscorner.com/2026-04-22-Thinking-Machines-Expands-Use-of-Google-Cloud-AI-Hypercomputer)saw 2x faster training and serving speeds on GB300 NVL72 compared with prior\-generation GPUs, accelerating frontier model research and reinforcement learning workflows\.
Nebius, running NVIDIA Blackwell and Blackwell Ultra infrastructure on its AI cloud,[enabled Higgsfield](https://www.nvidia.com/en-us/case-studies/higgsfield/)to reduce model training time by 30%, supporting a platform that now serves 22 million users and generates over 6 million pieces of AI content per day\.
For a deeper technical look at the MLPerf Training 6\.0 results and the optimizations behind them, readthis[technical blog](https://developer.nvidia.com/blog/nvidia-blackwell-tops-mlperf-training-6-0-with-industry-leading-scale-and-performance/)\.
NVIDIA's Blackwell GB300 NVL72 platform leads the first agentic AI infrastructure benchmark, AgentPerf from Artificial Analysis, delivering up to 20x more agents per megawatt than the previous Hopper generation.
A developer toolkit providing configurations, wheels, and benchmarks for running large language models with NVFP4 precision on Nvidia Blackwell GPUs using TensorRT-LLM.
NVIDIA published the first agentic AI benchmark results showing the GB300 NVL72 can run up to 20x more coding agents per megawatt than the H200, using the AgentPerf benchmark from Artificial Analysis.
A user shares performance benchmarks comparing the Nvidia RTX Pro 4500 Blackwell 32GB GPU against the RTX 5060 Ti 16GB for AI inference, showing 1.6-6x speed improvements depending on model size and quantization.
Llama.cpp now supports Nvidia's Programmatic Dependent Launch (PDL) for Blackwell GPUs, offering a 5-10% performance boost on token generation. The feature is not enabled by default and requires a build flag.