Detecting the Undetectable: Enhancing Unsupervised time series Anomaly Detection via Active Learning
Summary
Proposes a novel framework combining active learning with masked reconstruction and minimax strategies to improve unsupervised time series anomaly detection, achieving 12.39% AUC improvement over baselines across 28 test cases.
View Cached Full Text
Cached at: 07/02/26, 05:39 AM
# Detecting the Undetectable: Enhancing Unsupervised time series Anomaly Detection via Active Learning Source: [https://arxiv.org/html/2607.00720](https://arxiv.org/html/2607.00720) Hyeongwon Kang[hyeongwon\_kang@korea\.ac\.kr](https://arxiv.org/html/2607.00720v1/mailto:[email protected])Jinwoo Park[jinwoo\_park@snu\.ac\.kr](https://arxiv.org/html/2607.00720v1/mailto:[email protected])Pilsung Kang[pilsung˙kang@snu\.ac\.kr](https://arxiv.org/html/2607.00720v1/mailto:pilsung%CB%[email protected])LG CNS, 71 Magokjungang 8\-ro, Gangseo\-gu, Seoul, Republic of KoreaDepartment of Industrial & Management Engineering, Korea University, 126\-16 Anam\-dong 5\-ga, Seongbuk\-gu, Seoul, Republic of KoreaDepartment of Industrial Engineering, Seoul National University, Gwanak\-ro 1, Gwanak\-gu, Seoul, Republic of Korea ###### Abstract Despite the increasing sophistication of industrial AI systems, the ability to reliably detect subtle and noisy anomalies in complex time series data remains a critical yet unresolved challenge\. In large\-scale industrial applications, labeling time series data is often prohibitively expensive and time\-consuming, making unsupervised learning a practical and widely adopted approach\. However, existing unsupervised methods frequently struggle to distinguish near\-normal anomalies from normal patterns and are vulnerable to noise contamination within normal samples\. To address these limitations, we propose a novel framework that leverages active learning to iteratively enhance the performance of unsupervised models\. Our framework’s core contributions are \(1\) a masked time\-series reconstruction feedback strategy that forces the model to learn robust temporal dependencies, and \(2\) a minimax learning strategy that promotes robustness by differentially treating normal and abnormal samples\. This process encourages the model to better capture the dynamics of subtle and noisy patterns\. The proposed framework is evaluated across 28 test cases involving four multivariate time\-series datasets and seven unsupervised backbone models\. Experimental results demonstrate a 12\.39% improvement in AUC compared to the original models, confirming that our method can be readily integrated into existing unsupervised reconstruction\-based anomaly detection systems to significantly enhance their performance\. ###### keywords: Multivariate time series , Unsupervised time series anomaly detection , Active learning ## 1Introduction In today’s increasingly automated and sensor\-rich industrial environments, vast streams of time series data are continuously generated, capturing the dynamic behaviors of machines, processes, and entire systems\. Amid this data deluge, even minor anomalies can signal critical issues such as equipment failure, cyberattacks, or financial risk, underscoring the importance of timely and accurate detection\. time series anomaly detection, which aims to identify patterns that deviate significantly from normal behavior, has therefore become a cornerstone of operational reliability and industrial risk mitigation\[[23](https://arxiv.org/html/2607.00720#bib.bib45)\]\. As modern systems grow more complex and interconnected, the need for intelligent and scalable anomaly detection tools has become more urgent than ever\[[23](https://arxiv.org/html/2607.00720#bib.bib45),[28](https://arxiv.org/html/2607.00720#bib.bib35)\]\. This growing demand has spurred intense research activity focused on developing effective methods for monitoring and detecting anomalies in multivariate time series data\[[23](https://arxiv.org/html/2607.00720#bib.bib45),[27](https://arxiv.org/html/2607.00720#bib.bib49),[19](https://arxiv.org/html/2607.00720#bib.bib48)\]\. Recent research on time series anomaly detection has increasingly emphasized unsupervised learning methods, primarily due to the practical challenges of obtaining high\-quality labeled data in real\-world applications\[[28](https://arxiv.org/html/2607.00720#bib.bib35),[4](https://arxiv.org/html/2607.00720#bib.bib38),[35](https://arxiv.org/html/2607.00720#bib.bib37)\]\. Annotating time series data is not only labor\-intensive and time\-consuming, but also requires substantial domain expertise and a nuanced understanding of temporal dependencies and inter\-variable relationships\[[3](https://arxiv.org/html/2607.00720#bib.bib2),[48](https://arxiv.org/html/2607.00720#bib.bib46),[9](https://arxiv.org/html/2607.00720#bib.bib47)\]\. As a result, most studies have focused on modeling normal behavioral patterns without labeled anomalies, identifying deviations as potential outliers\[[43](https://arxiv.org/html/2607.00720#bib.bib43),[13](https://arxiv.org/html/2607.00720#bib.bib33)\]\. Traditional unsupervised techniques, including Local Outlier Factor \(LOF\)\[[7](https://arxiv.org/html/2607.00720#bib.bib23)\], One\-Class SVM\[[32](https://arxiv.org/html/2607.00720#bib.bib22)\], Support Vector Data Description \(SVDD\)\[[37](https://arxiv.org/html/2607.00720#bib.bib18)\], and Isolation Forest\[[21](https://arxiv.org/html/2607.00720#bib.bib21)\], offer lightweight solutions but struggle with high\-dimensional or complex time series data due to their limited capacity to capture temporal structure\[[20](https://arxiv.org/html/2607.00720#bib.bib39),[36](https://arxiv.org/html/2607.00720#bib.bib40),[34](https://arxiv.org/html/2607.00720#bib.bib41)\]\. To address these limitations, deep learning\-based models—such as Convolutional Neural Networks \(CNNs\)\[[18](https://arxiv.org/html/2607.00720#bib.bib58)\], Recurrent Neural Networks \(RNNs\)\[[31](https://arxiv.org/html/2607.00720#bib.bib57)\], and Transformers\[[39](https://arxiv.org/html/2607.00720#bib.bib56)\]—have gained traction for their ability to learn complex sequential dynamics\. This shift has spurred widespread interest in applying deep learning to unsupervised time series anomaly detection, particularly in large\-scale industrial settings\[[4](https://arxiv.org/html/2607.00720#bib.bib38),[34](https://arxiv.org/html/2607.00720#bib.bib41)\]\. Despite the progress enabled by unsupervised deep learning models, fundamental limitations remain\. One key challenge lies in their susceptibility to noise: normal data with minor fluctuations is frequently misclassified as anomalous, resulting in a high false positive rate\[[10](https://arxiv.org/html/2607.00720#bib.bib1)\]\. Conversely, subtle anomalies that closely mimic normal patterns often go undetected, giving rise to false negatives\[[8](https://arxiv.org/html/2607.00720#bib.bib36)\]\. At the core of these limitations is the difficulty unsupervised models face in distinguishing between noisy normal samples and true anomalies—particularly in high\-dimensional time series data with complex temporal dynamics and inter\-variable dependencies\[[14](https://arxiv.org/html/2607.00720#bib.bib34),[16](https://arxiv.org/html/2607.00720#bib.bib44),[47](https://arxiv.org/html/2607.00720#bib.bib42)\]\. In response, recent research has sought to improve the fidelity of normal pattern learning and to enhance robustness against such confounding factors, aiming to bridge the performance gap in practical deployments\[[4](https://arxiv.org/html/2607.00720#bib.bib38),[13](https://arxiv.org/html/2607.00720#bib.bib33),[42](https://arxiv.org/html/2607.00720#bib.bib25)\]\. This limitation is not trivial; it is fundamental to the unsupervised paradigm, which lacks semantic grounding\. This ambiguity inevitably leads to a high false positive rate or critical false negatives, creating a performance ceiling that pure unsupervised methods cannot overcome\[[40](https://arxiv.org/html/2607.00720#bib.bib32)\]\. This necessitates a hybrid approach that strategically incorporates minimal human expertise\. To overcome the limitations of purely unsupervised models, recent research has explored hybrid approaches that incorporate limited supervision to guide anomaly detection\. In particular, active learning has emerged as a promising strategy for selectively annotating the most informative samples from unlabeled time series data, thereby enhancing model performance with minimal labeling effort\[[40](https://arxiv.org/html/2607.00720#bib.bib32),[44](https://arxiv.org/html/2607.00720#bib.bib30),[12](https://arxiv.org/html/2607.00720#bib.bib31),[5](https://arxiv.org/html/2607.00720#bib.bib29)\]\. By focusing annotation efforts on samples that are most uncertain or representative, active learning directly addresses the challenges unsupervised models face, especially in distinguishing noisy normal patterns from subtle anomalies\[[33](https://arxiv.org/html/2607.00720#bib.bib28)\]\. This paradigm offers a practical compromise between fully supervised and unsupervised learning, and is particularly well\-suited for time series anomaly detection, where exhaustive labeling is rarely feasible and unsupervised methods alone may fall short of desired accuracy\[[40](https://arxiv.org/html/2607.00720#bib.bib32)\]\. While active learning has shown promise in enhancing time series anomaly detection, its integration into deep learning\-based unsupervised reconstruction models remains relatively underexplored\. Existing approaches often employ traditional machine learning models as backbones\[[5](https://arxiv.org/html/2607.00720#bib.bib29)\], or rely on supervised pre\-training before applying active learning strategies\[[44](https://arxiv.org/html/2607.00720#bib.bib30),[12](https://arxiv.org/html/2607.00720#bib.bib31)\]\. Among them, Active\-MTSAD\[[40](https://arxiv.org/html/2607.00720#bib.bib32)\]most closely aligns with our objective by combining deep unsupervised models with selective supervision through active learning\. It adopts a pseudo\-labeling strategy in which selected queries from the unlabeled pool are annotated and used to train the model via metric learning\. However, this reliance on pseudo\-labels can be problematic, particularly when the limited labeled samples fail to capture the diversity of real\-world anomaly patterns\. Furthermore, Active\-MTSAD assumes that each query round includes at least one true anomaly, a condition that is often unmet in industrial settings where anomalies are both rare and stochastic\. These limitations reduce the method’s robustness and hinder its practical applicability in large\-scale industrial scenarios\. We propose an active learning\-based framework designed to enhance the performance of unsupervised reconstruction models for time series anomaly detection\. Our core novelty lies not in the selection of queries, but in how the model learns from them\. Our approach focuses on enabling the model to better distinguish between noisy normal samples and subtle anomalies\. Specifically, we introduce two key components: \(1\) a masked time series reconstruction feedback strategy that strengthens the model’s understanding of temporal dependencies, and \(2\) a minimax loss that treats normal and anomalous samples separately to guide the learning of discriminative temporal patterns\. To source informative samples for this sophisticated feedback mechanism, we employ an effective hybrid query strategy, adapting principles from prior work\[[40](https://arxiv.org/html/2607.00720#bib.bib32)\]\(e\.g\., top\-k and interval sampling\) to capture both noisy normal data with high scores and near\-normal anomalies with lower scores\. Unlike prior methods that rely on pseudo\-labeling and structural modifications, our framework is directly applicable to a wide range of reconstruction\-based unsupervised models\. Our main contributions are as follows: - 1\.Extraction of Noisy and Anomalous Patterns: We design a feedback mechanism that extracts noisy normal and near\-normal anomalous samples from unlabeled data using an active learning strategy\. These queries are labeled by an oracle and used to further train the backbone model\. A minimax loss function—applied separately to normal and anomalous queries—enhances detection accuracy\. - 2\.Temporal Reconstruction via Pretext Task: To capture complex temporal dynamics, we introduce a masked reconstruction task within the feedback strategy\. By reconstructing randomly masked segments of the input, the model is encouraged to learn richer temporal representations that improve anomaly discrimination\. - 3\.Model\-Agnostic Framework: Our framework is architecture\-agnostic and can be seamlessly integrated into existing deep unsupervised reconstruction models without structural modifications\. It consistently improves performance across diverse backbones\. The remainder of this paper is structured as follows\. Section[2](https://arxiv.org/html/2607.00720#S2)reviews related work on unsupervised time series anomaly detection and the application of active learning in time series analysis\. Section[3](https://arxiv.org/html/2607.00720#S3)presents the proposed methodology, detailing each component of the framework\. Section[4](https://arxiv.org/html/2607.00720#S4)describes the experimental setup and evaluation protocol\. Section[5](https://arxiv.org/html/2607.00720#S5)reports the results of extensive experiments and ablation studies\. Section[6](https://arxiv.org/html/2607.00720#S6)provides a comparative analysis of anomaly detection performance with and without active learning\. Finally, Section[7](https://arxiv.org/html/2607.00720#S7)concludes the paper with a summary of key findings and future research directions\. ## 2Related Works ### 2\.1Unsupervised Multivariate time series Anomaly Detection Unsupervised time series anomaly detection methods can be broadly categorized into four groups: density estimation\-based, clustering\-based, prediction\-based, and reconstruction\-based approaches\. Each category offers a distinct strategy for modeling normal behavior and identifying deviations as anomalies\. Density Estimation\-Based Approaches\.These methods identify anomalies as data points located in low\-density regions of the data distribution\. Local Outlier Factor \(LOF\)\[[7](https://arxiv.org/html/2607.00720#bib.bib23)\], for instance, classifies a point as anomalous if its local density significantly deviates from its neighbors\. DAGMM\[[49](https://arxiv.org/html/2607.00720#bib.bib17)\]extends this idea by integrating Gaussian Mixture Models \(GMMs\) with an autoencoder, jointly optimizing for reconstruction loss and density estimation\. Clustering\-Based Approaches\.Clustering\-based methods assume that normal samples form dense clusters, while anomalies reside far from cluster centroids\. Deep\-SVDD\[[30](https://arxiv.org/html/2607.00720#bib.bib16)\], a deep learning extension of Support Vector Data Description \(SVDD\)\[[37](https://arxiv.org/html/2607.00720#bib.bib18)\], maps data into a latent space and encloses normal samples within a compact hypersphere\. Samples falling outside this boundary are considered anomalies\. Prediction\-Based Approaches\.Prediction\-based techniques model normal temporal patterns and identify anomalies as instances with large prediction errors\. These methods vary by the prediction backbone used\. Traditional statistical models like ARIMA\[[6](https://arxiv.org/html/2607.00720#bib.bib51)\]capture linear trends, while deep learning models such as LSTM\-AD\[[22](https://arxiv.org/html/2607.00720#bib.bib20)\]and CNN\-based DeepANT\[[26](https://arxiv.org/html/2607.00720#bib.bib19)\]are designed to learn nonlinear temporal dependencies from multivariate sequences\. Reconstruction\-Based Approaches\.These models aim to learn a compressed representation of normal sequences, reconstructing them accurately while failing to reconstruct anomalies\. LSTM\-VAE\[[28](https://arxiv.org/html/2607.00720#bib.bib35)\]leverages a Variational Autoencoder to model the distribution of normal data and reconstruct samples from latent representations\. USAD\[[4](https://arxiv.org/html/2607.00720#bib.bib38)\]employs a dual\-autoencoder structure to minimize reconstruction error, while OmniAnomaly\[[35](https://arxiv.org/html/2607.00720#bib.bib37)\]combines a Stacked Recurrent Autoencoder \(SRAE\) with a VAE to jointly model temporal dynamics and probabilistic structure\. Recent methods adopt Transformer architectures to better capture long\-range dependencies in time series data\. Anomaly Transformer\[[42](https://arxiv.org/html/2607.00720#bib.bib25)\]introduces a mechanism based on association discrepancy, detecting anomalies by evaluating the inconsistency of attention patterns\. This reflects the observation that anomalous samples often fail to form strong associations with normal timestamps due to their rarity\. Variable Temporal Transformer \(VTT\)\[[13](https://arxiv.org/html/2607.00720#bib.bib33)\]further enhances temporal modeling by replacing standard self\-attention with a temporal self\-attention mechanism, allowing it to better capture variable dependencies across time\. ### 2\.2Active Learning in time series Anomaly Detection Recent efforts have explored the application of active learning to enhance time series anomaly detection, particularly in scenarios where labeling is costly and anomalies are rare\. SLA\-VAE\[[12](https://arxiv.org/html/2607.00720#bib.bib31)\]integrates active learning with LSTM\-VAE by minimizing the Evidence Lower Bound \(ELBO\) for normal data while maximizing it for anomalies, enabling uncertainty estimation for query selection\. AMAD\[[44](https://arxiv.org/html/2607.00720#bib.bib30)\]adopts a conventional active learning pipeline, beginning with a supervised training phase and iteratively refining the model by querying high\-uncertainty samples\. In another approach, Little Helps\[[5](https://arxiv.org/html/2607.00720#bib.bib29)\]uses an unsupervised Isolation Forest to generate anomaly scores and perform weighted feedback based on tree performance, operating in a feedback\-driven unsupervised learning setting\. RLVAL\[[11](https://arxiv.org/html/2607.00720#bib.bib61)\]proposes a novel framework for univariate time series that combines a Deep Reinforcement Learning \(DRL\) agent with a Variational Autoencoder \(VAE\) and Active Learning, utilizing an LSTM network to effectively model sequential dependencies\. The core objective of this method is to overcome the limitations of static models, particularly in adapting to new anomaly types\. By leveraging DRL and Active Learning, the framework aims to detect novel anomaly classes using minimal labeled data, addressing the common challenges of manual parameter tuning\. While these approaches have advanced the integration of active learning in anomaly detection, they typically rely on traditional machine learning backbones or assume a semi\-supervised initial setup, conditions that differ from the fully unsupervised reconstruction\-based models considered in this study\. Among prior works, Active\-MTSAD\[[40](https://arxiv.org/html/2607.00720#bib.bib32)\]is the most closely aligned with our research, as it also combines deep unsupervised models with active learning for time series anomaly detection\. Both approaches acknowledge the limitations of pure unsupervised methods and employ a hybrid query strategy, which combines high\-score sampling and diverse interval sampling to select informative samples\. However, our framework’s novelty lies not in the sampling strategy, but in the fundamental design of the feedback mechanism, learning objective, and label handling, which directly address key limitations of Active\-MTSAD\. First, Active\-MTSAD employs a pseudo\-labeling strategy, where labels from a small query set are extrapolated to the entire unlabeled pool to guide metric learning\. This reliance on pseudo\-labels is problematic, as inaccuracies from the initial, small set of queries can propagate and amplify during training, potentially misleading the model\. To address this, our framework avoids pseudo\-labeling altogether\. We exclusively use the high\-fidelity, oracle\-verified labels from the query set for supervised feedback, ensuring that the model learns from reliable ground\-truth information\. Second, Active\-MTSAD uses metric learning to pull similar samples together and push dissimilar ones apart in a latent space\. In contrast, we introduce a masked time series reconstruction feedback strategy\. This pretext task forces the backbone model to learn the underlying temporal dynamics and complex dependencies within the challenging ‘noisy\-normal’ and ‘subtle\-anomaly’ sequences themselves, rather than just learning their relative distances in a latent space\. Third, Active\-MTSAD’s feedback relies on an assumption that each query round includes at least one true anomaly\[[40](https://arxiv.org/html/2607.00720#bib.bib32)\], a condition often unmet in real\-world industrial settings with sparse anomalies\. Our minimax objective is inherently robust to this scenario\. If a query batch contains zero anomalies, the “maximize” phase is simply skipped, and the model robustly refines its understanding of ‘noisy normal’ samples, avoiding the instability or failure modes of the prior method\. In summary, while we adapt a similar query selection component, our framework introduces a fundamentally different feedback architecture that is more robust, avoids error propagation, and is better suited for practical, large\-scale industrial scenarios\. ## 3Proposed Method ### 3\.1Limitations of Unsupervised Anomaly Detection Models Figure 1:Raw time series of UCR 001 and anomaly score of each model where pink segments are anomalous timestepsDespite the advances in unsupervised learning, existing reconstruction\-based anomaly detection models often struggle to reliably distinguish between noisy normal samples and subtle anomalies that closely resemble normal patterns\. To empirically illustrate this issue, we evaluated three representative models, LSTM\-VAE\[[28](https://arxiv.org/html/2607.00720#bib.bib35)\], Transformer\[[39](https://arxiv.org/html/2607.00720#bib.bib56)\], and USAD\[[4](https://arxiv.org/html/2607.00720#bib.bib38)\], using a benchmark univariate time series dataset from the UCR archive\[[41](https://arxiv.org/html/2607.00720#bib.bib24)\], which includes both noisy normal and near\-normal anomalous segments\. As shown in[Figure 1](https://arxiv.org/html/2607.00720#S3.F1), the blue segment denotes normal data, while the pink segment indicates anomalous data\. Notably, all three models assign high anomaly scores to the blue segment due to abrupt but benign fluctuations, potentially leading to false positives\. Conversely, the red segment, although anomalous, exhibits only subtle deviations, resulting in low anomaly scores and thus false negatives\. This example highlights a critical limitation of unsupervised approaches: their reliance on reconstruction or prediction errors as indirect proxies for anomaly likelihood makes them sensitive to noise and less effective in capturing fine\-grained deviations\. Prior studies\[[9](https://arxiv.org/html/2607.00720#bib.bib47),[34](https://arxiv.org/html/2607.00720#bib.bib41),[47](https://arxiv.org/html/2607.00720#bib.bib42)\]have reported similar findings, showing that these models often fail to generalize in complex, real\-world time series settings\. To address this challenge, active learning has gained traction as a promising strategy\. By selectively labeling noisy normal and near\-normal anomalous samples, active learning supplements the unsupervised training process with minimal supervision, guiding the model to better discriminate between similar\-looking patterns\. This targeted feedback helps correct common misclassifications and improves model robustness with a modest labeling budget\. Motivated by these observations, we propose an active learning\-based framework that explicitly incorporates such challenging samples into the training loop\. Our method aims to bridge the gap between unsupervised generality and supervised precision, thereby enhancing anomaly detection performance in real\-world scenarios where noise and ambiguity are prevalent\. Figure 2:Overall architecture of proposed framework ### 3\.2Overall Framework In unsupervised multivariate time series anomaly detection, the input data is denoted by𝕏Total∈ℝS×C\\mathbb\{X\}\_\{\\text\{Total\}\}\\in\\mathbb\{R\}^\{S\\times C\}, whereSSis the total sequence length andCCrepresents the number of channels\. A sliding window approach is employed to generate fixed\-length subsequences\. At each timesteptt, a sequence of lengthLLis formed as𝕏t=Xt−L\+1,Xt−L\+2,…,Xt\\mathbb\{X\}\_\{t\}=\{X\_\{t\-L\+1\},X\_\{t\-L\+2\},\\ldots,X\_\{t\}\}, with eachXl∈ℝ1×CX\_\{l\}\\in\\mathbb\{R\}^\{1\\times C\}\. These sequences are input to the model, which is trained to reconstruct them as𝕏^t=X^t−L\+1,X^t−L\+2,…,X^t\\hat\{\\mathbb\{X\}\}\_\{t\}=\{\\hat\{X\}\_\{t\-L\+1\},\\hat\{X\}\_\{t\-L\+2\},\\ldots,\\hat\{X\}\_\{t\}\}, where eachX^l∈ℝ1×C\\hat\{X\}\_\{l\}\\in\\mathbb\{R\}^\{1\\times C\}\. The model learns to minimize the reconstruction loss between the original and reconstructed sequences\. During inference, the anomaly scoreStS\_\{t\}, based on Mean Squared Error \(MSE\), for each timestepttis computed as the average reconstruction error over the sequence\. Points with anomaly scores exceeding a predefined threshold are classified as anomalous\. The reconstruction loss is defined as follows: loss\(𝕏t,𝕏^t\)=1L∑l=0L−1\(Xt−l−X^t−l\)2\\displaystyle\\text\{loss\}\(\\mathbb\{X\}\_\{t\},\\hat\{\\mathbb\{X\}\}\_\{t\}\)=\\frac\{1\}\{L\}\\sum\_\{l=0\}^\{L\-1\}\\left\(X\_\{t\-l\}\-\\hat\{X\}\_\{t\-l\}\\right\)^\{2\}\(1\)The threshold is selected based on the Best\-F1 criterion to maximize detection performance on the evaluation dataset\. As illustrated in[Figure 2](https://arxiv.org/html/2607.00720#S3.F2), the proposed framework operates in three stages: Stage 1: Unsupervised Pretraining\.The backbone model is first trained in an unsupervised setting using normal time series data\. Given input sequences𝕏∈ℝL×C\\mathbb\{X\}\\in\\mathbb\{R\}^\{L\\times C\}, the model learns to reconstruct them by minimizing reconstruction error, effectively capturing normal temporal patterns\. Stage 2: Query Sampling\.An unlabeled dataset, drawn from the test set, is used for active learning\. This unlabeled set includes a mix of normal and anomalous sequences, but without labels\. A query sampling strategy selects the most informative samples for annotation\. In line with industrial environments, where large portions of data remain unlabeled\[[38](https://arxiv.org/html/2607.00720#bib.bib3)\], this stage mimics realistic conditions\. The remainder of the test set, which includes ground\-truth labels, is reserved for evaluation\. The dataset configuration is summarized in[Figure 3](https://arxiv.org/html/2607.00720#S3.F3)\. Stage 3: Supervised Feedback via Masked Reconstruction\.The selected queries and their labels are used to refine the model through a masked time series reconstruction strategy\. Specifically, random segments within each query sequence are masked, and the model is tasked with reconstructing these missing parts, a pretext task that encourages the learning of deeper temporal dependencies\. To guide learning more effectively, a minimax objective is applied: the model minimizes reconstruction loss for normal queries while maximizing it for anomalous ones, enhancing its ability to discriminate between the two\. Stages 2 and 3 are repeated iteratively until a predefined query budget is reached, at which point the active learning process terminates\. Figure 3:Example of dataset configuration process ### 3\.3Training time series Anomaly Detection Model The first stage of the proposed framework involves training the backbone model in an unsupervised manner using only normal time series data\. The model takes as input sequences𝕏∈ℝL×C\\mathbb\{X\}\\in\\mathbb\{R\}^\{L\\times C\}and learns to reconstruct them with minimal error, producing outputs𝕏^\\hat\{\\mathbb\{X\}\}of the same dimensions\. The training objective is to minimize the reconstruction loss, encouraging the model to capture the underlying temporal patterns characteristic of normal behavior\. This stage assumes that anomalous patterns, which deviate from the learned normal structure, will lead to noticeably higher reconstruction errors during inference\. By exclusively training on normal data, the model is equipped to differentiate between normal and abnormal sequences based on reconstruction performance\. ### 3\.4Query Sampling Strategy To enhance the anomaly discrimination capability of the backbone model, we introduce a query sampling strategy that selects informative time series samples from an unlabeled dataset for additional supervised training\. The pretrained model first computes a mean anomaly score for each sliding window in the unlabeled set, denoted asscoreunlabeled\\mathrm\{score\}\_\{\\mathrm\{unlabeled\}\}, using the model’s intrinsic scoring mechanism\. As illustrated in[Figure 4](https://arxiv.org/html/2607.00720#S3.F4), queries are selected in each iteration using a hybrid strategySSthat combines two sampling techniques—Top\-kkSamplingS1S\_\{1\}and Interval Random SamplingS2S\_\{2\}—following the methodology proposed in Active\-MTSAD\[[40](https://arxiv.org/html/2607.00720#bib.bib32)\]\. 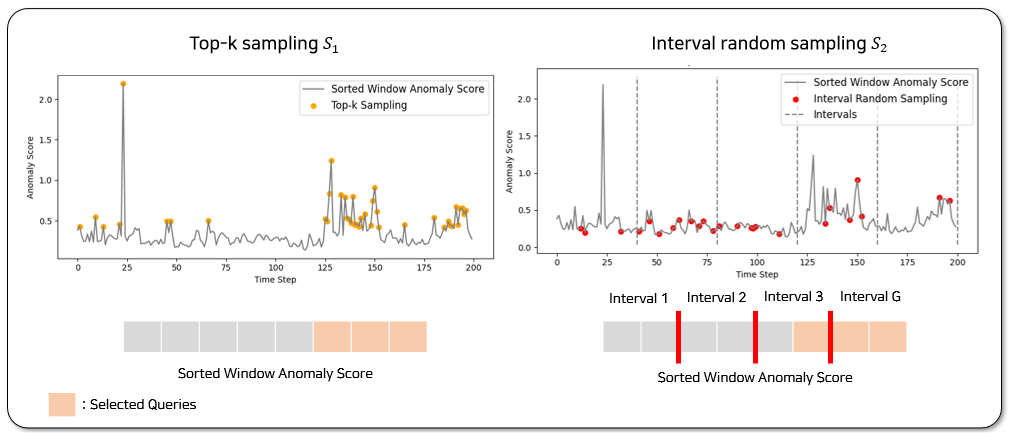Figure 4:Illustration of two different ways of query sampling strategiesTop\-kkSampling \(S1S\_\{1\}\): This method selects the top\-kkwindows with the highest anomaly scores fromscoreunlabeled\\mathrm\{score\}\_\{\\mathrm\{unlabeled\}\}, sorted in descending order\. As shown in the left panel of[Figure 4](https://arxiv.org/html/2607.00720#S3.F4), this sampling technique captures two critical cases: \(1\) noisy normal sequences that receive high anomaly scores, leading to false positives, and \(2\) genuine anomalies that are correctly ranked highly\. Incorporating both types into supervised training allows the model to better distinguish between noisy normal behavior and true anomalies\. 1:Input:Trained backbone model LL, Unlabeled dataset UU 12:Output:Query set QQ 23:Initialize Q=\{\}Q=\\\{\\\} 4:score ←\\leftarrowCompute anomaly scores for all samples in UUwith LLusing[Equation 4](https://arxiv.org/html/2607.00720#S3.E4) 35: Sort\(score\)Sort\(\\text\{score\}\)\{Descending order\} 46:Select top k samples with the largest score to form set S1S\_\{1\}\{top\-k sampling\} 7:Divide score into GGbins\{Interval Random Sampling\} 8:foreach bin b=1b=1to GGdo 59: Sb←Randomly selectgsamples from bin bS\_\{b\}\\leftarrow\\text\{Randomly select $g$ samples from bin b\} 610: S2←S2∪SbS\_\{2\}\\leftarrow S\_\{2\}\\cup S\_\{b\} 711:endfor 812: Q←S1∪S2Q\\leftarrow S\_\{1\}\\cup S\_\{2\} 13:Return:Selected samples QQ Algorithm 1Query Sampling StrategyInterval Random Sampling \(S2S\_\{2\}\): To capture a broader range of patterns, this method first partitions the sorted anomaly scores intoGGintervals and randomly samplesggwindows from each, as illustrated in the right panel of[Figure 4](https://arxiv.org/html/2607.00720#S3.F4)\. This approach ensures the inclusion of diverse samples, such as subtle anomalies with low anomaly scores that might otherwise be misclassified as normal\. By doing so,S2S\_\{2\}complementsS1S\_\{1\}by reducing false negatives and enhancing the model’s robustness to variation in anomaly intensity\. To achieve comprehensive coverage of potential anomaly types, the final query setQQis defined as the union of both strategies:Q=S1∪S2Q=S\_\{1\}\\cup S\_\{2\}\. In real\-world industrial settings, the selected queries would require annotation by a human oracle\. However, for experimental purposes, we assume that ground\-truth labels are available immediately upon query selection\. The full sampling procedure is detailed in Algorithm[1](https://arxiv.org/html/2607.00720#alg1)\. ### 3\.5Masked time series Reconstruction based Feedback Strategy Figure 5:Illustration of Masked time series Reconstruction based Feedback StrategyIn the final stage of training, the backbone model is refined using a feedback strategy based on masked time series reconstruction and oracle\-labeled queries\. As illustrated in[Figure 5](https://arxiv.org/html/2607.00720#S3.F5), each selected multivariate query sequence is partially masked and reconstructed through the model\. Supervised feedback is then applied via a minimax learning strategy, which treats normal and anomalous queries differently depending on their labels\. Unlike Active\-MTSAD\[[40](https://arxiv.org/html/2607.00720#bib.bib32)\], which relies on pseudo\-labels and metric learning, our method exclusively uses oracle\-verified labels\. This design avoids the propagation of labeling errors and improves robustness, especially in early active learning rounds where anomalies may be sparse or absent\. The feedback mechanism adopts the same sliding window configuration described in Section[3\.4](https://arxiv.org/html/2607.00720#S3.SS4)\. A fixed ratio of timesteps in each window is randomly masked, forming a pretext task that encourages the model to capture the temporal dynamics of the data, a technique validated in recent time series representation learning studies\[[45](https://arxiv.org/html/2607.00720#bib.bib27),[46](https://arxiv.org/html/2607.00720#bib.bib26)\]\. The supervised learning objective adopts a minimax strategy based on the oracle\-provided labels of query samples to make the discrepancy between normal and abnormal patterns more distinguishable\. For each query at timesteptt, a binary labelYt∈\{0,1\}Y\_\{t\}\\in\\\{0,1\\\}indicates whether the sample is normal \(Yt=0Y\_\{t\}=0\) or anomalous \(Yt=1Y\_\{t\}=1\)\. The model is trained to minimize the reconstruction error on masked timesteps for normal queries and to maximize it for anomalous queries\. This dual\-objective strategy is defined as follows: Minimize Phase:ℒnormal=∑t=1TImask\(t\)⋅Inormal\(t\)⋅L\(Xt,X^t;θ\),\\displaystyle\\text\{Minimize Phase:\}\\quad\\mathcal\{L\}\_\{\\text\{normal\}\}=\\sum\_\{t=1\}^\{T\}I\_\{\\text\{mask\}\}\(t\)\\cdot I\_\{\\text\{normal\}\}\(t\)\\cdot L\(X\_\{t\},\\hat\{X\}\_\{t\};\\theta\),\(2\)Maximize Phase:ℒanomaly=−∑t=1TImask\(t\)⋅Iabnormal\(t\)⋅L\(Xt,X^t;θ\)\.\\displaystyle\\text\{Maximize Phase:\}\\quad\\mathcal\{L\}\_\{\\text\{anomaly\}\}=\-\\sum\_\{t=1\}^\{T\}I\_\{\\text\{mask\}\}\(t\)\\cdot I\_\{\\text\{abnormal\}\}\(t\)\\cdot L\(X\_\{t\},\\hat\{X\}\_\{t\};\\theta\)\.\(3\) Here,TTis the number of timesteps in the query window \(i\.e\., the window size\)\.XtX\_\{t\}andX^t\\hat\{X\}\_\{t\}denote the original and reconstructed values at timett, respectively\.θ\\thetarepresents the model parameters,L\(⋅\)L\(\\cdot\)refers to the reconstruction loss, computed as the Mean Squared Error \(MSE\)\.Imask\(t\)I\_\{\\text\{mask\}\}\(t\)is an indicator function \(1 if timestepttis masked, 0 otherwise\)\.Inormal\(t\)=𝕀\(Yt=0\)I\_\{\\text\{normal\}\}\(t\)=\\mathbb\{I\}\(Y\_\{t\}=0\)andIabnormal\(t\)=𝕀\(Yt=1\)I\_\{\\text\{abnormal\}\}\(t\)=\\mathbb\{I\}\(Y\_\{t\}=1\)are indicator functions selecting normal and anomalous samples, respectively\. By explicitly training the model to increase or decrease reconstruction error depending on the label, this minimax approach enhances its ability to differentiate between normal and anomalous sequences\. Each training iteration integrates both phases and thus requires two backpropagation steps\. Although a weighted combination of the two objectives was initially explored, the disjoint application of minimization and maximization yielded superior detection performance in empirical evaluation\. ### 3\.6Anomaly Detection Following model training, anomaly detection is performed by computing an anomaly scoreStS\_\{t\}for each timesteptt, based on the discrepancy between the input and reconstructed signals\. This score reflects the likelihood that a given time point is anomalous\. The anomaly score is defined as the mean reconstruction error across all channels, measured using the Euclidean distance: St=1C∑m=1C\(Xt,m−X^t,m\)2\\displaystyle S\_\{t\}=\\frac\{1\}\{C\}\\sum\_\{m=1\}^\{C\}\\sqrt\{\(X\_\{t,m\}\-\\hat\{X\}\_\{t,m\}\)^\{2\}\}\(4\)Here,Xt,mX\_\{t,m\}andX^t,m\\hat\{X\}\_\{t,m\}denote the original and reconstructed values, respectively, for channelmmat timesteptt, andCCis the total number of channels\. A sample at timettis classified as anomalous ifStS\_\{t\}exceeds a predefined threshold\. The threshold is selected based on the Best\-F1 criterion, optimizing the balance between precision and recall on the validation or test set\. ## 4Experimental Settings ### 4\.1Datasets To effectively evaluate the proposed active learning framework, it is essential to use datasets that contain diverse and independent anomalous segments, enabling the model to capture a broad range of anomaly patterns through iterative sampling\. Among the five available time series anomaly detection benchmarks, we selected four datasets—SWaT\[[24](https://arxiv.org/html/2607.00720#bib.bib8)\], PSM\[[1](https://arxiv.org/html/2607.00720#bib.bib7)\], Gecco\[[17](https://arxiv.org/html/2607.00720#bib.bib6),[25](https://arxiv.org/html/2607.00720#bib.bib4)\], and Swan\[[17](https://arxiv.org/html/2607.00720#bib.bib6),[2](https://arxiv.org/html/2607.00720#bib.bib5)\], which provide sufficient temporal and structural variety in their anomaly instances\. The univariate benchmark used in Section[3\.1](https://arxiv.org/html/2607.00720#S3.SS1)was excluded from the main experiments due to its limited anomaly diversity, containing only a single anomaly segment\. [Table 1](https://arxiv.org/html/2607.00720#S4.T1)summarizes the key characteristics of the selected datasets\. Each dataset is partitioned as follows\. The training set consists exclusively of normal time series data to support unsupervised pretraining\. The unlabeled set is constructed by extracting the initial portion of the original test set based on a predefined unlabeled ratio\. The remainder of the test set, containing both normal and anomalous samples with ground\-truth labels, is used for evaluation\. This data partitioning procedure is visually illustrated in[Figure 3](https://arxiv.org/html/2607.00720#S3.F3)\. Table 1:Details of time series anomaly detection benchmark datasetsCharacteristicsSWaTPSMGeccoSwanUCR\-001\# of Variables51259381\# of Train396,000132,48169,26060,00014,113,128\# of Test \(Labeled\)449,91987,84169,26160,00018,109,080Anomaly \(%\)12\.027\.81\.132\.61\.4 ### 4\.2Baselines To evaluate the generalizability of the proposed framework and its ability to improve existing models, we adopt seven widely used reconstruction\-based time series anomaly detection methods as backbone models: LSTM\-VAE \(2018\)\[[28](https://arxiv.org/html/2607.00720#bib.bib35)\], USAD \(2020\)\[[4](https://arxiv.org/html/2607.00720#bib.bib38)\], OmniAnomaly \(2019\)\[[35](https://arxiv.org/html/2607.00720#bib.bib37)\], Transformer \(2017\)\[[39](https://arxiv.org/html/2607.00720#bib.bib56)\], Anomaly Transformer \(AT\) \(2022\)\[[42](https://arxiv.org/html/2607.00720#bib.bib25)\], VTT\-SAT and VTT\-PAT \(2024\)\[[13](https://arxiv.org/html/2607.00720#bib.bib33)\]\. In the case of Transformer, a multilayer perceptron \(MLP\) head is appended to the final encoder layer to align input and output dimensions\. All models are trained by minimizing the reconstruction error between the input and the reconstructed output\. We also consider Active\-MTSAD\[[40](https://arxiv.org/html/2607.00720#bib.bib32)\]as a relevant baseline due to its focus on active learning for anomaly detection under a similar problem setting\. However, a direct comparison is not feasible for two key reasons\. First, the official implementation is not publicly available, limiting reproducibility\. Second, based on our re\-implementation efforts, the framework halts in rounds where no anomalous queries are selected, an issue frequently encountered in realistic industrial datasets with sparse anomalies\. This makes it incompatible with our evaluation protocol, which emphasizes continuous learning even in anomaly\-scarce rounds\. While Active\-MTSAD provides valuable conceptual groundwork, these limitations underscore the practical advantage of our framework, which remains effective regardless of the anomaly distribution in the query rounds\. ### 4\.3Implementation Details We conduct a grid search over key hyperparameters to identify the configuration that yields the best F1 score\. For Top\-kksampling, we testk∈\{1,5,10,15,20\}k\\in\\\{1,5,10,15,20\\\}, and for Interval Random Sampling, the number of samples per bin is selected fromg∈\{1,3,5,10\}g\\in\\\{1,3,5,10\\\}\. The query budget is explored over\{10,50,100\}\\\{10,50,100\\\}, and the unlabeled ratio is varied across\{0\.1,0\.2,0\.3,0\.4\}\\\{0\.1,0\.2,0\.3,0\.4\\\}\. Additionally, the number of epochs used during feedback training—referred to as feedback epochs—is selected from\{10,50,100\}\\\{10,50,100\\\}\. All experiments use a non\-overlapping sliding window of fixed size 50 across all datasets\. We adopt the Adam optimizer\[[15](https://arxiv.org/html/2607.00720#bib.bib60)\]with a learning rate of10−210^\{\-2\}, and use a batch size of 8\. Early stopping is applied with a patience of 10 epochs\. Hyperparameters specific to each backbone model are configured according to the original implementations in their respective papers\. The active learning process proceeds iteratively until the cumulative number of annotated queries reaches the predefined budget\. All experiments are implemented in PyTorch\[[29](https://arxiv.org/html/2607.00720#bib.bib59)\]and executed on an NVIDIA GeForce RTX 2080 Ti BLOWER 11GB GPU\. ### 4\.4Evaluation Metrics We evaluate model performance using three widely adopted metrics for time series anomaly detection: Point\-wise F1 score \(F1\), Point\-Adjusted F1 score \(F1PA\\text\{F1\}\_\{\\text\{PA\}\}\), and AUC \(Area Under the PA%K Curve\)\. The Point\-Adjusted F1 score \(F1PA\\text\{F1\}\_\{\\text\{PA\}\}\) considers an entire anomaly segment to be correctly detected if at least one point within the segment is identified as anomalous\[[42](https://arxiv.org/html/2607.00720#bib.bib25),[13](https://arxiv.org/html/2607.00720#bib.bib33)\]\. This metric reflects a practical assumption in industrial settings, where a single fault often affects multiple consecutive timestamps\. However, it has been shown to overestimate detection performance in certain cases\[[14](https://arxiv.org/html/2607.00720#bib.bib34)\]\. To address this limitation, the PA%K metric was introduced as a refined evaluation method\[[14](https://arxiv.org/html/2607.00720#bib.bib34)\]\. It applies the PA adjustment only if the detected anomalies cover at least K% of the ground\-truth anomaly segment\. In this study, we compute the AUC by varying K from 0 to 100 \(in increments of 1\) and measuring the area under the resulting PA%K curve\. This AUC provides a more comprehensive and robust evaluation of anomaly detection performance across varying levels of detection coverage\. ### 4\.5Best\-F1 Threshold Searching A significant challenge in evaluating unsupervised time series anomaly detection models lies in establishing a classification threshold\. Since these models inherently produce anomaly scores rather than discrete labels, the choice of a specific thresholding technique can itself become a confounding variable, influencing the final performance metrics\. In this study, our primary objective is to assess the intrinsic anomaly detection capacity of each model that is, the quality of the anomaly scores they generate\. Therefore, to ensure a fair and direct comparison, we adhere to a standard benchmarking protocol used in time series anomaly detection literature\. For our proposed model and all baseline models, we evaluate the anomaly scores generated for the test dataset against all possible threshold values\. The performance is then reported based on the threshold that yields the maximum F1\-score, i\.e\., Best\-F1\. This approach ensures that all models are compared under their most optimal conditions, allowing their core detection capabilities to be evaluated fairly without performance being skewed by the choice of a sub\-optimal thresholding heuristic\[[13](https://arxiv.org/html/2607.00720#bib.bib33)\]\. ## 5Experimental Results ### 5\.1Main Results To verify that the performance gains of the proposed framework are not simply attributable to increased exposure to normal data, we conduct comparative experiments under different training set configurations\. Specifically, we compare three setups: \(1\) the backbone model trained only on the original training set \(w/o unlabeled\), \(2\) trained with both the training set and the unlabeled set \(w/ unlabeled\), and \(3\) trained using the proposed active learning framework \(Ours\)\. In theOursconfiguration, the backbone model is first trained in an unsupervised manner \(w/o unlabeled\) and then fine\-tuned using our active learning framework\. Detailed results are presented in[Table 2](https://arxiv.org/html/2607.00720#S5.T2)\. Bolded values in the table indicate the best performance across all backbone models for each dataset and metrics\. To clarify the gains,average diff\.in[Table 3](https://arxiv.org/html/2607.00720#S5.T3)quantifies the average improvement in AUC between thew/ unlabeledmodel and the same model enhanced by active learning, across the four benchmark datasets\. The consistently higher bars \(light blue\) in[Figure 6](https://arxiv.org/html/2607.00720#S5.F6)for the active learning models highlight the effectiveness of the proposed framework\. Notably, the Transformer with active learning achieves the greatest overall improvement, with an average AUC increase of 3\.95%\. Moreover, this configuration achieves the top rank in 11 out of 12 evaluation scenarios \(4 datasets×\\times3 metrics\), and secures 10 first\-place results out of 21 model variations, covering seven backbones across three training setups\. This suggests that attention\-based architectures, such as the Transformer, are especially well\-suited for feedback\-based learning due to their strength in capturing temporal dependencies\. Table 2:Experiment results on each benchmark for seven different backbone modelsDatasetPSMSWaTGeccoSwanBackboneTypeF1PA\\text\{F1\}\_\{\\text\{PA\}\}F1AUCF1PA\\text\{F1\}\_\{\\text\{PA\}\}F1AUCF1PA\\text\{F1\}\_\{\\text\{PA\}\}F1AUCF1PA\\text\{F1\}\_\{\\text\{PA\}\}F1AUCw/ unlabeled0\.93110\.53940\.59140\.92100\.84630\.89760\.30020\.21680\.27390\.89150\.61320\.7763LSTM\-VAE\[[28](https://arxiv.org/html/2607.00720#bib.bib35)\]w/o unlabeled0\.93320\.52590\.57890\.92150\.84630\.89760\.30080\.22090\.27720\.89180\.64940\.7938Ours0\.93140\.54010\.59170\.92350\.84630\.89780\.30140\.22490\.28010\.89880\.79140\.8736w/ unlabeled0\.87340\.52930\.58780\.92310\.84630\.89760\.30020\.21680\.27390\.89140\.62790\.7847USAD\[[4](https://arxiv.org/html/2607.00720#bib.bib38)\]w/o unlabeled0\.88570\.52700\.58610\.91320\.84630\.89760\.30020\.21680\.27440\.89140\.62790\.7847Ours0\.92970\.52240\.58960\.91130\.84630\.89750\.30080\.22090\.27770\.89020\.60640\.7453w/ unlabeled0\.93000\.53690\.58880\.92240\.84630\.89760\.30020\.21680\.27390\.89160\.62200\.7821OmniAnomaly\[[35](https://arxiv.org/html/2607.00720#bib.bib37)\]w/o unlabeled0\.93000\.53690\.58880\.92230\.84630\.89760\.30020\.21680\.27390\.89160\.62200\.7821Ours0\.92200\.53690\.59070\.92220\.84630\.89760\.30080\.22090\.27770\.89050\.58550\.7340w/ unlabeled0\.93190\.54020\.59180\.92060\.84630\.89760\.30020\.21680\.27490\.88980\.66290\.8026Transformer\[[39](https://arxiv.org/html/2607.00720#bib.bib56)\]w/o unlabeled0\.88970\.56410\.61520\.91810\.85140\.90230\.30020\.21680\.27490\.89020\.72580\.8330Ours0\.93240\.56530\.62480\.91080\.85300\.90440\.31360\.30670\.31350\.90570\.80100\.8821w/ unlabeled0\.97200\.05000\.07590\.97280\.04260\.06720\.27950\.01260\.02190\.83810\.05000\.0725AT\[[42](https://arxiv.org/html/2607.00720#bib.bib25)\]w/o unlabeled0\.97250\.04700\.07170\.96080\.03740\.06110\.27300\.00820\.01480\.84420\.04770\.0706Ours0\.92400\.52460\.61130\.92390\.78470\.87830\.30370\.19710\.26270\.87980\.61500\.7696w/ unlabeled0\.86060\.40440\.42850\.92800\.48150\.70970\.29110\.15130\.24730\.84330\.60840\.7621VTT\-SAT\[[13](https://arxiv.org/html/2607.00720#bib.bib33)\]w/o unlabeled0\.86060\.40440\.50000\.92800\.48150\.69770\.28680\.11860\.18380\.84340\.60940\.7451Ours0\.93320\.41460\.56610\.92180\.70790\.83000\.30560\.25360\.29570\.84660\.71970\.8241w/ unlabeled0\.93920\.40760\.40000\.86830\.33190\.51290\.29000\.14310\.21420\.84340\.60800\.7551VTT\-PAT\[[13](https://arxiv.org/html/2607.00720#bib.bib33)\]w/o unlabeled0\.93920\.40760\.52010\.94710\.28230\.29720\.30370\.24130\.28940\.84340\.60800\.7315Ours0\.93120\.53750\.58940\.92680\.72690\.85860\.29220\.15950\.22760\.84780\.78810\.8394 Bold: Best result among each backbone and benchmark group Table 3:Average performance difference \(Ours– Baseline\) across datasets for each backboneMetricLSTM\-VAEUSADOmniAnomalyTransformerATVTT\-SATVTT\-PATF1PA\\text\{F1\}\_\{\\text\{PA\}\}0\.00280\.0110\-0\.00220\.0050\-0\.00770\.02100\.0143F10\.0468\-0\.0061\-0\.00810\.06500\.49160\.11250\.1804AUC0\.0260\-0\.0085\-0\.01060\.03950\.57110\.09210\.1582 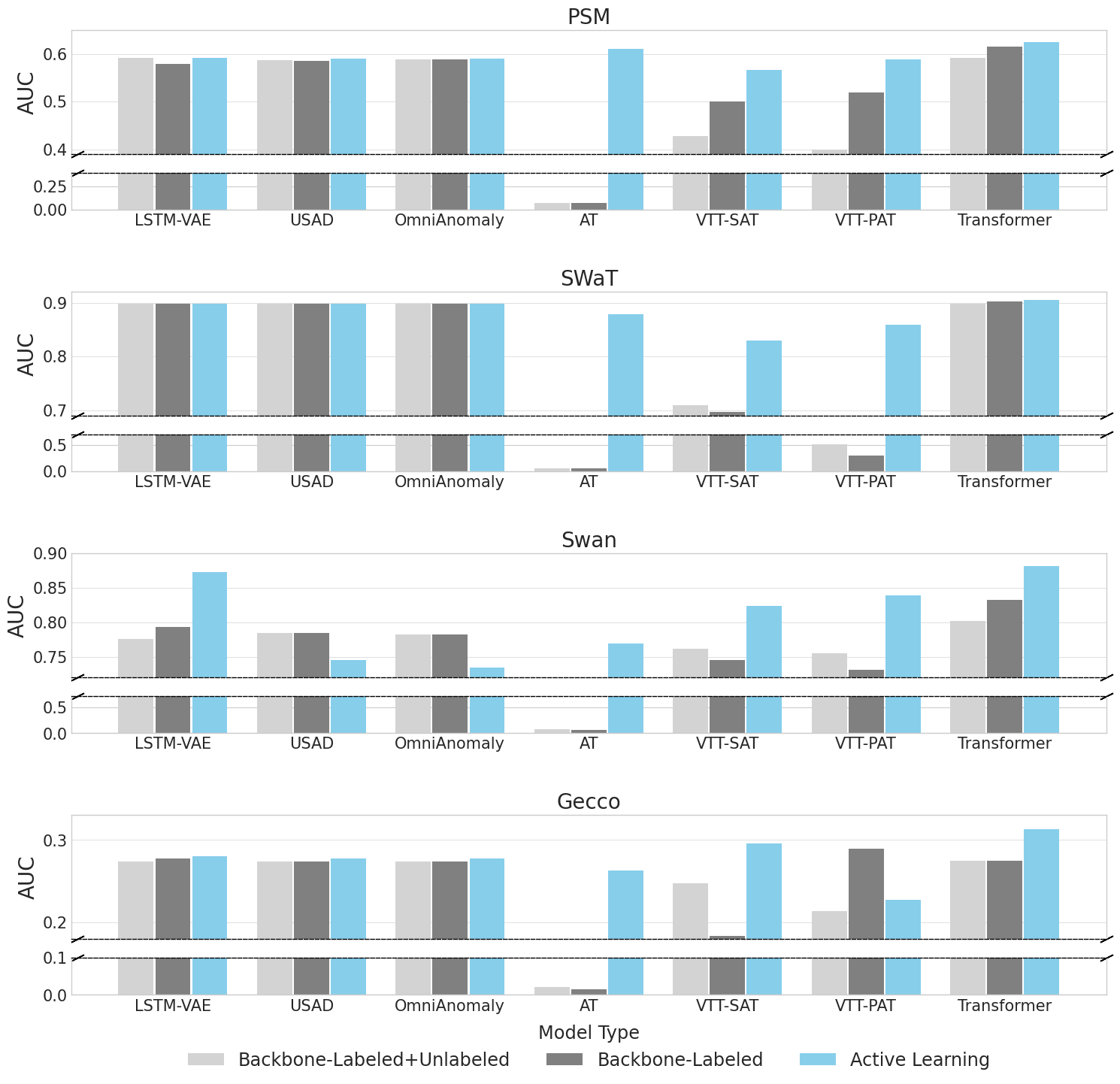Figure 6:Bar plot showing AUC of experimental result with seven different backbone models on each benchmark\. Backbone\-Labeled\+Unlabeled corresponds tow/\{w/\}unlabeled\{unlabeled\}, Backbone\-Labeled corresponds tow/o\{w/o\}unlabeled\{unlabeled\}and Active Learning corresponds toOursOursin[Table 2](https://arxiv.org/html/2607.00720#S5.T2)The Anomaly Transformer \(AT\) also benefits significantly from our framework, particularly in narrowing the gap between PA and point\-wise F1 scores\. It shows an average improvement of 49\.16% in F1 and 57\.11% in AUC\. Likewise, VTT\-SAT and VTT\-PAT which modify the standard Transformer attention with temporal\-variable attention—achieve AUC gains of 9\.21% and 15\.82%, respectively\. However, performance degradation is observed for USAD and OmniAnomaly in some datasets\. These models incorporate adversarial or probabilistic learning objectives beyond reconstruction loss, which may conflict with the minimax\-based feedback strategy\. This indicates that the proposed method is more effective when aligned with models that rely primarily on reconstruction\-based objectives\. While comparing thew/ unlabeledandw/o unlabeledtraining configurations, we observe that performance trends are not always consistent across models\. For instance, USAD and OmniAnomaly sometimes perform better when trained with additional unlabeled data than when enhanced with active learning, whereas the opposite is true in other configurations\. These inconsistencies suggest that simply increasing the training data volume does not guarantee improved performance\. Instead, the observed gains from our method are attributable to the quality of the selected queries and the effectiveness of the feedback strategy, rather than the quantity of training data alone\. [Figure 7](https://arxiv.org/html/2607.00720#S5.F7)shows the PA%K curves across different models and datasets\. For most datasets, PA%K values decline gradually asKKincreases, except for Gecco, where shorter anomaly segments lead to steeper drops in performance\. Despite this, models enhanced with active learning show stable detection performance across a wide range ofKKvalues\. Lastly, the Anomaly Transformer demonstrates high sensitivity toKKdue to its reliance on association discrepancy in anomaly scoring\. While this makes it effective at detecting long\-duration anomalies, it can reduce precision in point\-wise evaluations\. Figure 7:PA%K curve for four datasets and seven backbone models with our proposed framework appliedA notable observation from Table 2 is that while our framework significantly improves Transformer\-based models on e\.g\., Swan, Gecco and SWaT, the performance gain on PSM is marginal\. This is not a flaw in the framework, but rather an assumption mismatch between our Active Learning strategy and the unique characteristics of the PSM dataset\. Our framework, like most active learning strategies for anomaly detection, is designed for scenarios where anomalies in the unlabeled set are rare and ambiguous as in SWaT, Swan, allowing the query strategy to efficiently concentrate these high\-value ‘noisy normal’ and ‘subtle anomaly’ samples from a large pool of normal data\. However, as the PSM unlabeled dataset consists of 31% anomalies, the fundamental premise of Active Learning is violated\. This data saturation leads to a critical failure in the query strategy\. First failure is a biased Feedback where query sampling strategy, which is not designed for such anomaly\-abundant data, selects a small and non\-representative biased subset from a massive, diverse anomaly class\. Second failure is ab overfitting of Feedback\. Our feedback strategy trains the model to maximize error on these specific anomalous queries\. However, as these queries do not represent the full diversity of anomalies in PSM, the model may overfit to reject these specific patterns while failing to generalize to other anomaly types in the test set\. Therefore, the marginal gain on PSM is due to the dataset’s violation of the “rare anomaly” assumption, which in turn limits the generalization potential of our robust feedback mechanism\. ### 5\.2Ablation Study Figure 8:AUC score of Transformer backbone model for four datasets when major components of proposed framework are removed individuallyTo evaluate the individual contribution of each component in the proposed framework, we conduct an ablation study using the Transformer, which showed the strongest performance in the main experiments\. We define the following ablation settings: - 1\.\-Minimax Loss: The minimax loss in the feedback strategy is replaced with a weighted sum of reconstruction losses for normal and anomalous queries\. - 2\.\-Top\-k sampling/\-Interval Random Sampling: Each sampling method \(S1S\_\{1\}orS2S\_\{2\}\) is independently replaced with uniform random sampling of the same size\. - 3\.\-Top\-k & Interval Random Sampling: All queries are randomly sampled in each round, effectively removing the designed sampling strategy\. - 4\.\-Window Masking: The masking pretext task is removed; the model directly reconstructs raw sequences without any masked input\. [Figure 8](https://arxiv.org/html/2607.00720#S5.F8)presents the results of the ablation study across the benchmark datasets\. Overall, applying all components of the proposed framework yields the highest performance across all datasets except for the PSM\. The analysis reveals the following key findings: - 1\.Query Sampling Strategy: Replacing eitherS1S\_\{1\}\(top\-kk\) orS2S\_\{2\}\(interval sampling\) with random sampling consistently leads to performance degradation or marginal gains over the backbone model\. This confirms that our proposed feedback mechanism is highly synergistic with a targeted query strategy\. - 2\.Masking Pretext Task: Removing the masking task from the feedback strategy results in a notable decline in performance\. This underscores the importance of learning temporal dependencies through masked reconstruction, aligning with findings from time series representation learning literature\. - 3\.Minimax Loss: Substituting the minimax objective with a simple weighted sum leads to a significant drop in AUC\. This result strongly validates our hypothesis, aligning with findings from\[[42](https://arxiv.org/html/2607.00720#bib.bib25)\], that simply reconstructing samples is insufficient\. The minimax objective’s role in actively maximizing the error for anomalies while minimizing it for normals is crucial for making the reconstruction discrepancy distinguishable\. The performance drop confirms that treating normal and anomalous queries with distinct, opposing optimization goals is essential for robust discrimination\. These results collectively highlight the effectiveness and necessity of each component in the proposed framework\. The synergy between targeted sampling, masking\-based feedback, and asymmetric loss formulation is crucial to achieving reliable performance improvements in active learning\-based time series anomaly detection\. ## 6Analysis ### 6\.1Effect of Active Learning on Backbone model Figure 9:Comparison of anomaly score of Transformer backbone model when active learning is implemented on SWaT test set from timestep 255,000 to 259,000[Figure 9](https://arxiv.org/html/2607.00720#S6.F9)compares the anomaly scores generated by the original Transformer backbone and the active Transformer, which incorporates the proposed framework, for the SWaT dataset\. As shown in the figure, the active Transformer produces significantly elevated anomaly scores within anomalous segments, improving the separation between normal and abnormal patterns\. Although a slight increase in scores is also observed in normal segments, the contrast between the two regions becomes more distinct, reducing false negatives\. This suggests that our framework enhances the model’s ability to detect subtle anomalies by refining its sensitivity to abnormal patterns through supervised feedback\. ### 6\.2Budget Size for Active Learning Table 4:Size of each four benchmark and portion that each corresponding budget size takes from unlabeled set of each benchmarkDatasetBudget Size \(windows\)\# of TrainTimesteps\# of TestTimesteps\# of windowsin unlabeled set3050100PSM4\.27%7\.12%\\ul14\.25%132,48187,841702SWaT0\.83%\\ul1\.39%2\.78%495,000449,9193,599Gecco5\.42%\\ul9\.03%18\.05%69,26069,261554Swan6\.25%\\ul10\.42%20\.83%60,00060,000480To assess the trade\-off between annotation effort and detection performance, we evaluate three different budget sizes: 30, 50, and 100 queries\.[Table 4](https://arxiv.org/html/2607.00720#S6.T4)reports the relative proportion of each budget compared to the total number of windows in the unlabeled set for each dataset\. The optimal budget for the active Transformer, in terms of F1 score, is highlighted in bold\. As the results show, annotating as little as 21% of the unlabeled windows can yield substantial performance gains\. For example, the Transformer backbone achieves the best results with a budget of 50 in SWaT, Gecco, and Swan, and 100 in PSM\. These figures correspond to only 1% to 14% of the total unlabeled windows; demonstrating the framework’s ability to deliver strong improvements with minimal annotation cost\. ### 6\.3Statistics of Selected Queries Table 5:Query sampling result with set of hyperparameters that yields the highest AUC for Transformer\-backboned active learningDatasetAnomaly ratioBudgetAnomaly ratioin unlabeled set\# of windowsin unlabeled setPSM9%3031%702SWaT45%506%3,599Gecco22%502%554Swan85%5016%480[Table 5](https://arxiv.org/html/2607.00720#S6.T5)shows the proportion of anomalies among the queries selected by the active learning strategy in each round when using the Transformer as the backbone\. Notably, across three datasets, the fraction of anomalous queries exceeds the anomaly ratio in the entire unlabeled set\. This outcome indicates that the query sampling strategy, combining top\-kkselection and interval\-based random sampling, successfully prioritizes informative samples within a limited budget\. Moreover, the sampling maintains a balance by capturing both noisy normal data and genuine anomalies, which is essential for effective supervised feedback and model refinement\. ## 7Conclusion Time series anomaly detection plays a vital role in domains such as manufacturing, finance, and healthcare, where the timely identification of anomalies is crucial for preventing operational disruptions and financial losses\. While unsupervised learning has been widely adopted to mitigate the scarcity of labeled data, existing methods often struggle to capture the complex temporal dependencies in multivariate sequences\. In particular, they frequently misclassify noisy normal data as anomalies and fail to detect subtle anomalous patterns—limiting their practical effectiveness\. To address these challenges, we proposed an active learning\-based framework that enhances reconstruction\-based unsupervised anomaly detection models by selectively incorporating supervised feedback\. The framework introduces a dual query sampling strategy, combining top\-kkselection and interval\-based random sampling, to obtain a diverse set of informative queries from unlabeled data\. This sampling approach ensures the inclusion of both noisy normal sequences and near\-normal anomalies\. To refine model discrimination, we introduced a masked reconstruction\-based feedback mechanism guided by oracle\-provided labels\. Using a minimax loss, the model is trained to minimize reconstruction error for normal queries while maximizing it for anomalies, improving its ability to distinguish between the two\. The framework is model\-agnostic and demonstrated its effectiveness across seven backbones and four datasets, achieving AUC improvements in 82% of the 28 evaluation cases\. Notably, when applied to a Transformer encoder, the framework achieved an average AUC gain of 7\.56 percentage points, surpassing all baseline methods\. While the proposed method shows strong performance, its reliance on the minimax objective may introduce learning instability under certain conditions\. Future work will investigate alternative feedback strategies, such as those based on metric learning without pseudo\-labels, to improve training stability and generalization\. Moreover, given the framework’s sensitivity to hyperparameter settings, future research should aim to develop more robust and adaptive mechanisms to ensure consistent performance across datasets and model configurations\. ## References - \[1\]A\. Abdulaal, Z\. Liu, and T\. Lancewicki\(2021\)Practical approach to asynchronous multivariate time series anomaly detection and localization\.InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining,KDD ’21,New York, NY, USA,pp\. 2485–2494\.External Links:ISBN 9781450383325,[Link](https://doi.org/10.1145/3447548.3467174),[Document](https://dx.doi.org/10.1145/3447548.3467174)Cited by:[§4\.1](https://arxiv.org/html/2607.00720#S4.SS1.p1.1)\. - \[2\]R\. Angryk, P\. Martens, B\. Aydin, D\. Kempton, S\. Mahajan, S\. Basodi, A\. Ahmadzadeh, X\. Cai, S\. Filali Boubrahimi, S\. M\. Hamdi, M\. Schuh, and M\. Georgoulis\(2020\)SWAN\-SF\.External Links:[Document](https://dx.doi.org/10.7910/DVN/EBCFKM),[Link](https://doi.org/10.7910/DVN/EBCFKM)Cited by:[§4\.1](https://arxiv.org/html/2607.00720#S4.SS1.p1.1)\. - \[3\]F\. Arslan, A\. Javaid, M\. D\. Z\. Awan, and Ebad\-ur\-Rehman\(2023\)Anomaly detection in time series: current focus and future challenges\.InAnomaly Detection,V\. K\. Parimala \(Ed\.\),External Links:[Document](https://dx.doi.org/10.5772/intechopen.111886),[Link](https://doi.org/10.5772/intechopen.111886)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1)\. - \[4\]J\. Audibert, P\. Michiardi, F\. Guyard, S\. Marti, and M\. A\. Zuluaga\(2020\)USAD: unsupervised anomaly detection on multivariate time series\.InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining,KDD ’20,New York, NY, USA,pp\. 3395–3404\.External Links:ISBN 9781450379984,[Link](https://doi.org/10.1145/3394486.3403392),[Document](https://dx.doi.org/10.1145/3394486.3403392)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1),[§1](https://arxiv.org/html/2607.00720#S1.p3.1),[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p5.1),[§3\.1](https://arxiv.org/html/2607.00720#S3.SS1.p1.1),[§4\.2](https://arxiv.org/html/2607.00720#S4.SS2.p1.1),[Table 2](https://arxiv.org/html/2607.00720#S5.T2.4.4.10.1.1)\. - \[5\]H\. Bodor, T\. V\. Hoang, and Z\. Zhang\(2022\)Little help makes a big difference: leveraging active learning to improve unsupervised time series anomaly detection\.InService\-Oriented Computing – ICSOC 2021 Workshops,pp\. 165–176\.External Links:ISBN 9783031141355,ISSN 1611\-3349,[Link](http://dx.doi.org/10.1007/978-3-031-14135-5_13),[Document](https://dx.doi.org/10.1007/978-3-031-14135-5%5F13)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p4.1),[§1](https://arxiv.org/html/2607.00720#S1.p5.1),[§2\.2](https://arxiv.org/html/2607.00720#S2.SS2.p1.1)\. - \[6\]G\. E\. Box, G\. M\. Jenkins, G\. C\. Reinsel, and G\. M\. Ljung\(2015\)Time series analysis: forecasting and control\.John Wiley & Sons\.Cited by:[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p4.1)\. - \[7\]M\. M\. Breunig, H\. Kriegel, R\. T\. Ng, and J\. Sander\(2000\-05\)LOF: identifying density\-based local outliers\.SIGMOD Rec\.29\(2\),pp\. 93–104\.External Links:ISSN 0163\-5808,[Link](https://doi.org/10.1145/335191.335388),[Document](https://dx.doi.org/10.1145/335191.335388)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1),[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p2.1)\. - \[8\]Y\. Chen, C\. Zhang, M\. Ma, Y\. Liu, R\. Ding, B\. Li, S\. He, S\. Rajmohan, Q\. Lin, and D\. Zhang\(2023\)ImDiffusion: imputed diffusion models for multivariate time series anomaly detection\.External Links:2307\.00754,[Link](https://arxiv.org/abs/2307.00754)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p3.1)\. - \[9\]K\. Choi, J\. Yi, C\. Park, and S\. Yoon\(2021\)Deep learning for anomaly detection in time\-series data: review, analysis, and guidelines\.9\(\),pp\. 120043–120065\.External Links:[Document](https://dx.doi.org/10.1109/ACCESS.2021.3107975)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1),[§3\.1](https://arxiv.org/html/2607.00720#S3.SS1.p3.1)\. - \[10\]Y\. Feng, W\. Zhang, Y\. Fu, W\. Jiang, J\. Zhu, and W\. Ren\(2024\)SensitiveHUE: multivariate time series anomaly detection by enhancing the sensitivity to normal patterns\.InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining,KDD ’24,New York, NY, USA,pp\. 782–793\.External Links:ISBN 9798400704901,[Link](https://doi.org/10.1145/3637528.3671919),[Document](https://dx.doi.org/10.1145/3637528.3671919)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p3.1)\. - \[11\]B\. Golchin and B\. Rekabdar\(2025\)Anomaly detection in time series data using reinforcement learning, variational autoencoder, and active learning\.External Links:2504\.02999,[Link](https://arxiv.org/abs/2504.02999)Cited by:[§2\.2](https://arxiv.org/html/2607.00720#S2.SS2.p1.1)\. - \[12\]T\. Huang, P\. Chen, and R\. Li\(2022\)A semi\-supervised vae based active anomaly detection framework in multivariate time series for online systems\.External Links:[Link](https://api.semanticscholar.org/CorpusID:248367573)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p4.1),[§1](https://arxiv.org/html/2607.00720#S1.p5.1),[§2\.2](https://arxiv.org/html/2607.00720#S2.SS2.p1.1)\. - \[13\]H\. Kang and P\. Kang\(2024\)Transformer\-based multivariate time series anomaly detection using inter\-variable attention mechanism\.290,pp\. 111507\.External Links:ISSN 0950\-7051,[Document](https://dx.doi.org/https%3A//doi.org/10.1016/j.knosys.2024.111507),[Link](https://www.sciencedirect.com/science/article/pii/S0950705124001424)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1),[§1](https://arxiv.org/html/2607.00720#S1.p3.1),[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p6.1),[§4\.2](https://arxiv.org/html/2607.00720#S4.SS2.p1.1),[§4\.4](https://arxiv.org/html/2607.00720#S4.SS4.p2.1),[§4\.5](https://arxiv.org/html/2607.00720#S4.SS5.p1.1),[Table 2](https://arxiv.org/html/2607.00720#S5.T2.4.4.22.1.1),[Table 2](https://arxiv.org/html/2607.00720#S5.T2.4.4.25.1)\. - \[14\]S\. Kim, K\. Choi, H\. Choi, B\. Lee, and S\. Yoon\(2022\)Towards a rigorous evaluation of time\-series anomaly detection\.External Links:2109\.05257,[Link](https://arxiv.org/abs/2109.05257)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p3.1),[§4\.4](https://arxiv.org/html/2607.00720#S4.SS4.p2.1),[§4\.4](https://arxiv.org/html/2607.00720#S4.SS4.p3.1)\. - \[15\]D\. P\. Kingma and J\. Ba\(2014\)Adam: a method for stochastic optimization\.Cited by:[§4\.3](https://arxiv.org/html/2607.00720#S4.SS3.p2.1)\. - \[16\]A\. Koran, H\. Hojjati, and N\. Armanfard\(2024\)Unveiling the flaws: a critical analysis of initialization effect on time series anomaly detection\.External Links:2408\.06620,[Link](https://arxiv.org/abs/2408.06620)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p3.1)\. - \[17\]K\. Lai, D\. Zha, J\. Xu, Y\. Zhao, G\. Wang, and X\. Hu\(2021\)Revisiting time series outlier detection: definitions and benchmarks\.InThirty\-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track \(Round 1\),External Links:[Link](https://openreview.net/forum?id=r8IvOsnHchr)Cited by:[§4\.1](https://arxiv.org/html/2607.00720#S4.SS1.p1.1)\. - \[18\]Y\. LeCun, B\. Boser, J\. Denker, D\. Henderson, R\. Howard, W\. Hubbard, and L\. Jackel\(1989\)Handwritten digit recognition with a back\-propagation network\.2\.Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1)\. - \[19\]L\. Li, J\. Yan, H\. Wang, and Y\. Jin\(2021\)Anomaly detection of time series with smoothness\-inducing sequential variational auto\-encoder\.External Links:2102\.01331,[Link](https://arxiv.org/abs/2102.01331)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p1.1)\. - \[20\]Z\. Li, Y\. Zhao, J\. Han, Y\. Su, R\. Jiao, X\. Wen, and D\. Pei\(2021\)Multivariate time series anomaly detection and interpretation using hierarchical inter\-metric and temporal embedding\.InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining,KDD ’21,New York, NY, USA,pp\. 3220–3230\.External Links:ISBN 9781450383325,[Link](https://doi.org/10.1145/3447548.3467075),[Document](https://dx.doi.org/10.1145/3447548.3467075)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1)\. - \[21\]F\. T\. Liu, K\. M\. Ting, and Z\. Zhou\(2008\)Isolation forest\.In2008 Eighth IEEE International Conference on Data Mining,Vol\.,pp\. 413–422\.External Links:[Document](https://dx.doi.org/10.1109/ICDM.2008.17)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1)\. - \[22\]P\. Malhotra, L\. Vig, G\. M\. Shroff, and P\. Agarwal\(2015\)Long short term memory networks for anomaly detection in time series\.InThe European Symposium on Artificial Neural Networks,External Links:[Link](https://api.semanticscholar.org/CorpusID:43680425)Cited by:[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p4.1)\. - \[23\]L\. Marti, N\. Sanchez\-Pi, J\. M\. Molina, and A\. C\. B\. Garcia\(2015\)Anomaly detection based on sensor data in petroleum industry applications\.15\(2\),pp\. 2774–2797\.Note:Ce7br Times Cited:76 Cited References Count:48External Links:[Document](https://dx.doi.org/10.3390/s150202774)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p1.1)\. - \[24\]A\. P\. Mathur and N\. O\. Tippenhauer\(2016\)SWat: a water treatment testbed for research and training on ics security\.2016 International Workshop on Cyber\-Physical Systems for Smart Water Networks \(Cyswater\),pp\. 31–36\.Note:Bg0wk Times Cited:163 Cited References Count:13External Links:[Document](https://dx.doi.org/DOI%2010.1109/cyswater.2016.7469060),[Link](https://arxiv.org/html/2607.00720v1/%3CGo%20to%20ISI%3E://WOS:000386536900006)Cited by:[§4\.1](https://arxiv.org/html/2607.00720#S4.SS1.p1.1)\. - \[25\]S\. Moritz, F\. Rehbach, S\. Chandrasekaran, M\. Rebolledo, and T\. Bartz\-Beielstein\(2018\)GECCO Industrial Challenge 2018 Dataset: A water quality dataset for the ’Internet of Things: Online Anomaly Detection for Drinking Water Quality’ competition at the Genetic and Evolutionary Computation Conference 2018, Kyoto, Japan\.\.Cited by:[§4\.1](https://arxiv.org/html/2607.00720#S4.SS1.p1.1)\. - \[26\]M\. Munir, S\. A\. Siddiqui, A\. Dengel, and S\. Ahmed\(2019\)DeepAnT: a deep learning approach for unsupervised anomaly detection in time series\.IEEE Access7\(\),pp\. 1991–2005\.External Links:[Document](https://dx.doi.org/10.1109/ACCESS.2018.2886457)Cited by:[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p4.1)\. - \[27\]Z\. Niu, K\. Yu, and X\. Wu\(2020\)LSTM\-based vae\-gan for time\-series anomaly detection\.20\(13\)\.External Links:[Link](https://www.mdpi.com/1424-8220/20/13/3738),ISSN 1424\-8220,[Document](https://dx.doi.org/10.3390/s20133738)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p1.1)\. - \[28\]D\. Park, Y\. Hoshi, and C\. C\. Kemp\(2018\)A multimodal anomaly detector for robot\-assisted feeding using an lstm\-based variational autoencoder\.3\(3\),pp\. 1544–1551\.External Links:[Document](https://dx.doi.org/10.1109/LRA.2018.2801475)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p1.1),[§1](https://arxiv.org/html/2607.00720#S1.p2.1),[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p5.1),[§3\.1](https://arxiv.org/html/2607.00720#S3.SS1.p1.1),[§4\.2](https://arxiv.org/html/2607.00720#S4.SS2.p1.1),[Table 2](https://arxiv.org/html/2607.00720#S5.T2.4.4.7.1.1)\. - \[29\]A\. Paszke, S\. Gross, F\. Massa, A\. Lerer, J\. Bradbury, G\. Chanan, T\. Killeen, Z\. Lin, N\. Gimelshein, L\. Antiga,et al\.\(2019\)Pytorch: an imperative style, high\-performance deep learning library\.32\.Cited by:[§4\.3](https://arxiv.org/html/2607.00720#S4.SS3.p3.1)\. - \[30\]L\. Ruff, R\. Vandermeulen, N\. Goernitz, L\. Deecke, S\. A\. Siddiqui, A\. Binder, E\. Müller, and M\. Kloft\(2018\-10–15 Jul\)Deep one\-class classification\.InProceedings of the 35th International Conference on Machine Learning,J\. Dy and A\. Krause \(Eds\.\),Proceedings of Machine Learning Research, Vol\.80,pp\. 4393–4402\.External Links:[Link](https://proceedings.mlr.press/v80/ruff18a.html)Cited by:[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p3.1)\. - \[31\]D\. E\. Rumelhart, G\. E\. Hinton, and R\. J\. Williams\(1986\)Learning internal representations by error propagation, parallel distributed processing, explorations in the microstructure of cognition, ed\. de rumelhart and j\. mcclelland\. vol\. 1\. 1986\.71,pp\. 599–607\.Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1)\. - \[32\]B\. Schölkopf, R\. C\. Williamson, A\. Smola, J\. Shawe\-Taylor, and J\. Platt\(1999\)Support vector method for novelty detection\.InAdvances in Neural Information Processing Systems,S\. Solla, T\. Leen, and K\. Müller \(Eds\.\),Vol\.12,pp\.\.External Links:[Link](https://proceedings.neurips.cc/paper_files/paper/1999/file/8725fb777f25776ffa9076e44fcfd776-Paper.pdf)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1)\. - \[33\]B\. Settles\(2010\-07\)Active learning literature survey\.pp\.\.Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p4.1)\. - \[34\]L\. Shen, Z\. Li, and J\. Kwok\(2020\)Timeseries anomaly detection using temporal hierarchical one\-class network\.InAdvances in Neural Information Processing Systems,H\. Larochelle, M\. Ranzato, R\. Hadsell, M\.F\. Balcan, and H\. Lin \(Eds\.\),Vol\.33,pp\. 13016–13026\.External Links:[Link](https://proceedings.neurips.cc/paper_files/paper/2020/file/97e401a02082021fd24957f852e0e475-Paper.pdf)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1),[§3\.1](https://arxiv.org/html/2607.00720#S3.SS1.p3.1)\. - \[35\]Y\. Su, Y\. Zhao, C\. Niu, R\. Liu, W\. Sun, and D\. Pei\(2019\)Robust anomaly detection for multivariate time series through stochastic recurrent neural network\.InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining,KDD ’19,New York, NY, USA,pp\. 2828–2837\.External Links:ISBN 9781450362016,[Link](https://doi.org/10.1145/3292500.3330672),[Document](https://dx.doi.org/10.1145/3292500.3330672)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1),[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p5.1),[§4\.2](https://arxiv.org/html/2607.00720#S4.SS2.p1.1),[Table 2](https://arxiv.org/html/2607.00720#S5.T2.4.4.13.1.1)\. - \[36\]Y\. Su, Y\. Zhao, C\. Niu, R\. Liu, W\. Sun, and D\. Pei\(2019\)Robust anomaly detection for multivariate time series through stochastic recurrent neural network\.InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining,KDD ’19,New York, NY, USA,pp\. 2828–2837\.External Links:ISBN 9781450362016,[Link](https://doi.org/10.1145/3292500.3330672),[Document](https://dx.doi.org/10.1145/3292500.3330672)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1)\. - \[37\]D\. Tax and R\. Duin\(2004\)Support vector data description\.Machine Learning\.Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1),[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p3.1)\. - \[38\]A\. Tharwat and W\. Schenck\(2023\)A survey on active learning: state\-of\-the\-art, practical challenges and research directions\.Mathematics11\(4\)\.External Links:[Link](https://www.mdpi.com/2227-7390/11/4/820),ISSN 2227\-7390,[Document](https://dx.doi.org/10.3390/math11040820)Cited by:[§3\.2](https://arxiv.org/html/2607.00720#S3.SS2.p5.1)\. - \[39\]A\. Vaswani, N\. Shazeer, N\. Parmar, J\. Uszkoreit, L\. Jones, A\. N\. Gomez, Ł\. Kaiser, and I\. Polosukhin\(2017\)Attention is all you need\.30\.Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1),[§3\.1](https://arxiv.org/html/2607.00720#S3.SS1.p1.1),[§4\.2](https://arxiv.org/html/2607.00720#S4.SS2.p1.1),[Table 2](https://arxiv.org/html/2607.00720#S5.T2.4.4.16.1.1)\. - \[40\]W\. Wang, P\. Chen, Y\. Xu, and Z\. He\(2022\)Active\-mtsad: multivariate time series anomaly detection with active learning\.In2022 52nd Annual IEEE/IFIP International Conference on Dependable Systems and Networks \(DSN\),Vol\.,pp\. 263–274\.External Links:[Document](https://dx.doi.org/10.1109/DSN53405.2022.00036)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p3.1),[§1](https://arxiv.org/html/2607.00720#S1.p4.1),[§1](https://arxiv.org/html/2607.00720#S1.p5.1),[§1](https://arxiv.org/html/2607.00720#S1.p6.1),[§2\.2](https://arxiv.org/html/2607.00720#S2.SS2.p2.1),[§3\.4](https://arxiv.org/html/2607.00720#S3.SS4.p2.4),[§3\.5](https://arxiv.org/html/2607.00720#S3.SS5.p1.1),[§4\.2](https://arxiv.org/html/2607.00720#S4.SS2.p2.1)\. - \[41\]R\. Wu and E\. Keogh\(2023\)Current time series anomaly detection benchmarks are flawed and are creating the illusion of progress\.IEEE Transactions on Knowledge and Data Engineering35\(3\),pp\. 2421–2429\.External Links:[Document](https://dx.doi.org/10.1109/TKDE.2021.3112126)Cited by:[§3\.1](https://arxiv.org/html/2607.00720#S3.SS1.p1.1)\. - \[42\]J\. Xu, H\. Wu, J\. Wang, and M\. Long\(2022\)Anomaly transformer: time series anomaly detection with association discrepancy\.External Links:2110\.02642,[Link](https://arxiv.org/abs/2110.02642)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p3.1),[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p6.1),[§4\.2](https://arxiv.org/html/2607.00720#S4.SS2.p1.1),[§4\.4](https://arxiv.org/html/2607.00720#S4.SS4.p2.1),[item 3](https://arxiv.org/html/2607.00720#S5.I2.i3.p1.1),[Table 2](https://arxiv.org/html/2607.00720#S5.T2.4.4.19.1.1)\. - \[43\]Y\. Yang, C\. Zhang, T\. Zhou, Q\. Wen, and L\. Sun\(2023\-08\)DCdetector: dual attention contrastive representation learning for time series anomaly detection\.InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining,KDD ’23\.External Links:[Link](http://dx.doi.org/10.1145/3580305.3599295),[Document](https://dx.doi.org/10.1145/3580305.3599295)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1)\. - \[44\]R\. Yu, Y\. Wang, and W\. Wang\(2024\)AMAD: active learning\-based multivariate time series anomaly detection for large\-scale it systems\.Computers & SecurityProceedings of the ACM Web Conference 2022Knowledge\-Based SystemsIEEE Robotics and Automation LettersSensorsIEEE AccessSensorsProceedings of the ACM Web Conference 2022Journal of the Royal Statistical Society: Series C \(Applied Statistics\)Neural computationAdvances in neural information processing systemsBiometrikaAdvances in neural information processing systemsAdvances in neural information processing systemsarXiv preprint arXiv:1412\.6980137,pp\. 103603\.External Links:ISSN 0167\-4048,[Document](https://dx.doi.org/https%3A//doi.org/10.1016/j.cose.2023.103603),[Link](https://www.sciencedirect.com/science/article/pii/S0167404823005138)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p4.1),[§1](https://arxiv.org/html/2607.00720#S1.p5.1),[§2\.2](https://arxiv.org/html/2607.00720#S2.SS2.p1.1)\. - \[45\]Z\. Yue, Y\. Wang, J\. Duan, T\. Yang, C\. Huang, Y\. Tong, and B\. Xu\(2022\)TS2Vec: towards universal representation of time series\.External Links:2106\.10466,[Link](https://arxiv.org/abs/2106.10466)Cited by:[§3\.5](https://arxiv.org/html/2607.00720#S3.SS5.p2.1)\. - \[46\]G\. Zerveas, S\. Jayaraman, D\. Patel, A\. Bhamidipaty, and C\. Eickhoff\(2020\)A transformer\-based framework for multivariate time series representation learning\.External Links:2010\.02803,[Link](https://arxiv.org/abs/2010.02803)Cited by:[§3\.5](https://arxiv.org/html/2607.00720#S3.SS5.p2.1)\. - \[47\]C\. Zhang, D\. Song, Y\. Chen, X\. Feng, C\. Lumezanu, W\. Cheng, J\. Ni, B\. Zong, H\. Chen, and N\. V\. Chawla\(2018\)A deep neural network for unsupervised anomaly detection and diagnosis in multivariate time series data\.External Links:1811\.08055,[Link](https://arxiv.org/abs/1811.08055)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p3.1),[§3\.1](https://arxiv.org/html/2607.00720#S3.SS1.p3.1)\. - \[48\]Y\. Zhao, L\. Deng, X\. Chen, C\. Guo, B\. Yang, T\. Kieu, F\. Huang, T\. B\. Pedersen, K\. Zheng, and C\. S\. Jensen\(2022\)A comparative study on unsupervised anomaly detection for time series: experiments and analysis\.External Links:2209\.04635,[Link](https://arxiv.org/abs/2209.04635)Cited by:[§1](https://arxiv.org/html/2607.00720#S1.p2.1)\. - \[49\]B\. Zong, Q\. Song, M\. R\. Min, W\. Cheng, C\. Lumezanu, D\. Cho, and H\. Chen\(2018\)Deep autoencoding gaussian mixture model for unsupervised anomaly detection\.InInternational Conference on Learning Representations,External Links:[Link](https://openreview.net/forum?id=BJJLHbb0-)Cited by:[§2\.1](https://arxiv.org/html/2607.00720#S2.SS1.p2.1)\.
Similar Articles
Bridging Classification and Reconstruction: Cooperative Time Series Anomaly Detection
This paper proposes CoAD, a novel framework that unifies Outlier Exposure (classification) and Masked Autoencoder (reconstruction) paradigms for time series anomaly detection, addressing their respective limitations. Extensive experiments show that CoAD significantly outperforms state-of-the-art methods while being lightweight and fast.
CALAD: Channel-Aware contrastive Learning for multivariate time series Anomaly Detection
Proposes CALAD, a channel-aware contrastive learning framework for multivariate time series anomaly detection that uses estimated channel relevance to construct contrastive samples, achieving state-of-the-art performance.
Detecting Time Series Anomalies Like an Expert: A Multi-Agent LLM Framework with Specialized Analyzers
The article introduces SAGE, a multi-agent LLM framework for time-series anomaly detection that uses specialized analyzers to improve interpretability and reliability. It demonstrates superior performance over baselines on three benchmarks and enhances diagnostic reporting through structured evidence consolidation.
TPA-AD: A Two-Stage Pseudo Anomaly-Guided Method for Bearing Time-Series Anomaly Detection
TPA-AD is a two-stage pseudo anomaly-guided method for bearing time-series anomaly detection that generates pseudo-anomalous windows near normal boundaries using reconstruction models and contrastive learning, then scores anomalies with KNN—without requiring real anomaly samples during training. It is evaluated on bearing fault and degradation datasets, including high-speed train axle-box bearing data.
Back to Repair: A Minimal Denoising Network\ for Time Series Anomaly Detection
This paper introduces JuRe (Just Repair), a minimal denoising network for time series anomaly detection that matches or exceeds complex neural baselines on the TSB-AD and UCR benchmarks, demonstrating that a proper manifold-projection training objective is more important than architectural complexity.