Temporal-Decay Shapley: A Time-Aware Data Valuation Framework for Time-Series Data
Summary
This paper proposes Temporal-Decay Shapley (TDS), a data valuation framework for time-series data that incorporates temporal decay and multi-scale fusion to address the time-varying nature of sample values, outperforming traditional methods in noise detection and data selection.
View Cached Full Text
Cached at: 05/12/26, 06:56 AM
# Temporal-Decay Shapley: A Time-Aware Data Valuation Framework for Time-Series Data
Source: [https://arxiv.org/html/2605.08153](https://arxiv.org/html/2605.08153)
Chuwen Pang, Bing Mi, and Kongyang ChenChuwen Pang and Kongyang Chen are with School of Artificial Intelligence, Guangzhou University, Guangzhou 510006, China\. Bing Mi is with School of Public Finance and Taxation, Guangdong University of Finance and Economics, Guangzhou 510320, China\.
###### Abstract
With the rapid development of machine learning applications on time\-series data, accurately assessing the value of training samples has become essential for data selection, noise detection, and model optimization\. However, traditional data valuation methods usually assume that samples are independent and identically distributed, and thus ignore the time\-varying nature of sample value in time\-series data\. This paper proposes an improved temporal Shapley data valuation method that enables accurate sample valuation for time\-series data through a temporal decay mechanism and a multi\-scale fusion strategy\. Specifically, we propose three progressively enhanced temporal Shapley methods\. Temporal\-Decay Shapley \(TDS\) incorporates temporal information into Shapley value computation through exponential decay weights; the improved TDS adopts power exponential decay to better adapt to nonlinear temporal drift; and Multi\-Scale Temporal\-Decay Shapley \(MS\-TDS\) constructs a multi\-scale fusion mechanism that balances the value of short\-term hotspot samples and long\-term foundational samples through parallel multi\-scale valuation and sample\-level adaptive fusion\. Experimental results show that the proposed methods generally outperform traditional methods in noise detection and high\-value data identification tasks, with more evident advantages under most strongly temporal settings, thereby effectively improving the accuracy and robustness of data valuation\.
###### Index Terms:
Data valuation, Shapley value, time\-series data, temporal decay, multi\-scale fusion\.
## IIntroduction
In recent years, with the rapid development of artificial intelligence, machine learning models have achieved remarkable success in various fields such as computer vision, natural language processing, financial risk control, and medical diagnosis\. Data\-driven intelligent decision\-making has become an important feature of modern society\. However, during model training, different training samples often contribute differently to the final model performance\. Such differences are reflected not only in the amount of information contained in the samples, but also in their timeliness and applicability\. Accurately evaluating the value of training samples is of great importance for key tasks such as data selection, noise detection, and model optimization\. It can help construct more compact and effective training sets, identify and remove harmful noisy samples, and guide the design of data augmentation strategies\[[1](https://arxiv.org/html/2605.08153#bib.bib1),[2](https://arxiv.org/html/2605.08153#bib.bib2)\]\.
In traditional machine learning frameworks, data are typically regarded as a static collection of independent and identically distributed samples, and each sample is assumed to have equal learning value\. However, this assumption often fails to hold in real\-world applications\. In particular, in time\-series data scenarios, the value of samples may change significantly over time\. Recently generated data often better reflect the current data distribution and user behavior patterns, whereas historical data may gradually lose their reference value due to environmental changes, concept drift, and other factors\[[3](https://arxiv.org/html/2605.08153#bib.bib3),[4](https://arxiv.org/html/2605.08153#bib.bib4)\]\. Such differences in timeliness are especially prominent in real\-time applications such as financial trading, network traffic analysis, and sensor monitoring\.
The Shapley value, a classical concept in cooperative game theory\[[5](https://arxiv.org/html/2605.08153#bib.bib5)\], has become a core theoretical framework for data valuation because it rigorously satisfies four fundamental axioms: efficiency, symmetry, additivity, and dummy player\. This theory was originally proposed by Lloyd Shapley in 1953\. By calculating the marginal contribution of each participant, it determines the deserved payoff share of each participant and ensures the fairness and rationality of allocation\. Current mainstream data valuation methods, such as Leave\-One\-Out \(LOO\) and Monte Carlo Shapley approximation methods\[[6](https://arxiv.org/html/2605.08153#bib.bib6)\], are all based on the core assumption that training samples are independent and identically distributed \(IID\)\. They construct utility functions based on prediction probabilities or classification accuracy to statically evaluate sample value\.
However, in practical applications, many datasets exhibit clear temporal correlations and concept drift, which directly challenge the theoretical foundation of traditional methods\. Data timeliness is an important dimension of data quality and has a significant impact on sample value\. In time\-series data scenarios, the value of a sample is often closely related to its generation time\. Recent samples are more consistent with the current data distribution and model learning objectives, and the patterns they contain are more beneficial for improving model performance\. By contrast, historical samples may become less informative due to environmental evolution and pattern changes\. If all samples are valued without distinction, biases such as underestimating highly timely samples and overestimating outdated samples may occur\[[7](https://arxiv.org/html/2605.08153#bib.bib7),[8](https://arxiv.org/html/2605.08153#bib.bib8)\]\.
Traditional Shapley value methods face three main limitations when applied to time\-series data\. First, temporal information is lost, because traditional methods treat samples with different timestamps as equivalent individuals and fail to capture value differences along the temporal dimension\. Second, robustness is insufficient\. In concept drift scenarios, traditional methods may mistakenly assign low values to temporally important samples\. Third, adaptability is limited, because the fixed weighting mechanism of traditional methods cannot accommodate the temporal characteristics of different datasets\[[9](https://arxiv.org/html/2605.08153#bib.bib9),[10](https://arxiv.org/html/2605.08153#bib.bib10)\]\.
To address the above problems, this paper proposes an improved temporal Shapley data valuation method\. The core idea is to use a temporal decay mechanism and a multi\-scale fusion strategy to enable accurate valuation of samples in time\-series data, while reducing valuation bias caused by the absence of temporal information\. By treating the temporal dimension as a key regulating factor of sample value, the proposed method effectively couples “information value” and “temporal value”, providing a new solution for data valuation in temporally non\-stationary scenarios\.
The main contributions of this paper are summarized as follows:
- •We explicitly incorporate the temporal dimension into the Shapley value computation framework\. Through a temporal decay mechanism and a multi\-scale fusion strategy, we provide a new theoretical paradigm for valuing temporally non\-stationary data\. Three progressively enhanced temporal Shapley methods are proposed, ranging from basic temporal decay to multi\-scale adaptive fusion, forming a complete theoretical framework for time\-series data valuation\.
- •We design three progressively enhanced temporal Shapley methods, establishing a complete technical system from basic to advanced valuation\. The TDS method effectively incorporates temporal information through exponential decay weights; the improved TDS adopts power exponential decay to better adapt to nonlinear temporal changes; and MS\-TDS achieves a balance between the values of short\-term hotspot samples and long\-term foundational samples through multi\-scale parallel computation and adaptive fusion\.
- •The proposed methods exhibit strong engineering applicability and can effectively improve data cleaning efficiency and model robustness, providing valuable tools for practical applications\. Experimental results on multiple heterogeneous datasets show that the proposed methods generally outperform traditional methods in noise detection and high\-value data identification tasks under most settings\.
Organization\. The rest of this paper is organized as follows\. Section 2 presents the research motivation and background of the main contributions\. Section 3 provides the problem formulation and theoretical modeling\. Section 4 details the improved temporal Shapley framework and algorithm design\. Section 5 discusses the experimental design and key results\. Section 6 reviews related research progress\. Section 7 concludes the paper and outlines future directions\.
## IIMotivation
### II\-ATime\-Series Data Valuation
Data valuation aims to quantify the marginal contribution of each training sample to model utility, and is commonly used in data selection, noise detection, training set reduction, and cost\-constrained priority annotation\. For a given learning task, a “valuable sample” usually satisfies two conditions\. First, it provides additional discriminative information and improves the utility functionU\(⋅\)U\(\\cdot\)on the validation set\. Second, it remains effective under the current distribution of the target application and helps the model adapt to the latest patterns in real\-world environments\.
Under the static IID setting, sample value can be regarded as a relatively stable quantity, and classical Shapley valuation provides a reasonable characterization in the sense of fairly allocating marginal contributions\. However, in time\-series scenarios, the data generation mechanism often changes over time due to concept drift, periodicity, sudden events, and other factors\. As a result, sample value exhibits significant temporal heterogeneity\. Recent samples are closer to the current distribution and are usually more critical to short\-term performance, whereas historical samples may contain long\-term regularities or extreme patterns that still contribute to robustness and generalization\. In other words, sample value is no longer determined solely by information contribution, but is jointly modulated by temporal position and temporal scale\.
Therefore, data valuation for time\-series data needs to answer a more specific question: when the model objective is to serve prediction at the current time or over a future period, which historical segments should be retained and assigned higher weights, and which segments should be down\-weighted or even removed, so as to achieve a better balance among accuracy, robustness, and computational cost?
### II\-BWhy Time\-Aware and Multi\-Scale
The core assumption of traditional Shapley value methods in data valuation is IID\. These methods quantify value only through marginal contributions, but ignore the fact that information changes dynamically over time in time\-series scenarios\. In tasks involving concept drift or sensitivity to a valid time window, treating samples with different timestamps equally may lead to biases such as underestimating highly timely samples and overestimating outdated samples, thereby weakening the adaptability of valuation results to dynamic scenarios\[[9](https://arxiv.org/html/2605.08153#bib.bib9),[10](https://arxiv.org/html/2605.08153#bib.bib10)\]\. In practice, this bias often manifests as the model being dominated by a large number of outdated historical samples, which weakens its learning of the latest distribution and eventually causes performance degradation during deployment or rolling prediction\.
From the perspective of method design, time\-series data valuation faces at least three key challenges:
- •Temporal correlation and dependency structure\.Time\-series samples often exhibit strong correlations and continuity\. The value of certain samples may not come from their isolated point\-wise contribution, but from the learnable patterns jointly formed with their neighboring segments\. If valuation relies only on marginal contributions without temporal distinction, the overall effect of key temporal segments may be underestimated\.
- •Concept drift and temporal decay\.When the distribution evolves over time, older samples are more likely to mismatch the current task\. Therefore, a mechanism that decreases with the time gapΔt\\Delta tis needed, so that valuation can explicitly reflect timeliness\.
- •Coexistence of short\-term hotspots and long\-term regularities\.Relying on a single temporal scale may cause a biased valuation\. Overemphasizing recent samples may lose long\-term regularities and extreme patterns, whereas overemphasizing historical samples may sacrifice adaptability to the current distribution\. In practical applications, short\-term changes determine immediate performance, while long\-term regularities affect robustness and generalization\. Both aspects should be characterized simultaneously\.
In addition, time\-series data often contain multi\-scale information such as short\-term hotspots and long\-term regularities\. A single decay form is difficult to accommodate both aspects: short\-term scales better reflect the current distribution, while long\-term scales better support generalization ability\[[11](https://arxiv.org/html/2605.08153#bib.bib11)\]\. Therefore, a valuation method is needed that can jointly model temporal timeliness and multi\-scale characteristics within a unified framework\.
Motivated by the above observations, this paper adopts a combined strategy of temporal decay and multi\-scale modeling\. First, temporal decay is used to explicitly model the timeliness of samples, allowing valuation to decrease controllably withΔt\\Delta t\. Furthermore, multi\-scale parallel valuation and sample\-level adaptive fusion are introduced, so that value information from different temporal scales can be integrated within a unified framework\. This enables the method to simultaneously account for short\-term adaptability and long\-term robustness\. A direct and testable expectation is that, in noise detection tasks, the ranking of low\-value samples should better match noise patterns that disrupt temporal regularities; in data selection or removal tasks, model utility should decline more rapidly when high\-value samples are removed first, thereby demonstrating the effectiveness of the valuation ranking\.
## IIIProblem Formulation
To address the limitations of traditional Shapley value methods in time\-series data, this paper proposes three progressively enhanced methods, forming a complete technical framework from basic to advanced valuation\. While preserving the theoretical rigor of the Shapley value, these three methods incorporate the temporal dimension into the data valuation process through different technical routes, thereby enabling accurate quantification of the value of time\-series data\.
### III\-ANotations and Data
Let the training dataset be
D=\{\(xi,yi,ti\)\}i=1N,D=\\\{\(x\_\{i\},y\_\{i\},t\_\{i\}\)\\\}\_\{i=1\}^\{N\},\(1\)wherexi∈ℝdx\_\{i\}\\in\\mathbb\{R\}^\{d\}denotes the feature vector,yi∈𝒴y\_\{i\}\\in\\mathcal\{Y\}denotes the label, andtit\_\{i\}denotes the timestamp\. This paper focuses on the supervised learning setting, with classification tasks as the main example\. Let𝒜\(⋅\)\\mathcal\{A\}\(\\cdot\)denote the learning algorithm, which takes a training subsetS⊆DS\\subseteq Das input and outputs a modelfS=𝒜\(S\)f\_\{S\}=\\mathcal\{A\}\(S\)\.
Let the validation set be
Dval=\{\(xjval,yjval\)\}j=1Nval,D\_\{\\mathrm\{val\}\}=\\\{\(x^\{\\mathrm\{val\}\}\_\{j\},y^\{\\mathrm\{val\}\}\_\{j\}\)\\\}\_\{j=1\}^\{N\_\{\\mathrm\{val\}\}\},\(2\)which is used to measure model utility\. The utility functionU\(S\)U\(S\)represents the evaluation result onDvalD\_\{\\mathrm\{val\}\}after trainingfSf\_\{S\}on the training subsetSS, such as accuracy, AUC, or negative log\-likelihood \(NLL\)\. For simplicity, this paper assumes that a larger value ofU\(⋅\)U\(\\cdot\)indicates better model performance\.
To highlight the temporal factor, we define a reference timetreft\_\{\\mathrm\{ref\}\}, which is usually set as the latest timestamp among the data visible during training, and define the time gap as
Δti=tref−ti\.\\Delta t\_\{i\}=t\_\{\\mathrm\{ref\}\}\-t\_\{i\}\.\(3\)When the data distribution evolves over time,Δti\\Delta t\_\{i\}characterizes the relative freshness or staleness of a sample, and is therefore an important variable affecting its temporal value\.
### III\-BClassical Data Shapley
In the traditional data valuation framework, the value of a sample is computed using the Shapley value:
ϕi=∑S⊆D∖\{xi\}\|S\|\!\(\|D\|−\|S\|−1\)\!\|D\|\!⋅\[U\(S∪\{xi\}\)−U\(S\)\],\\phi\_\{i\}=\\sum\_\{S\\subseteq D\\setminus\\\{x\_\{i\}\\\}\}\\frac\{\|S\|\!\(\|D\|\-\|S\|\-1\)\!\}\{\|D\|\!\}\\cdot\\left\[U\(S\\cup\\\{x\_\{i\}\\\}\)\-U\(S\)\\right\],\(4\)whereU\(S\)U\(S\)denotes the utility of the model trained on subsetSSand evaluated on an independent validation set, such as the average prediction probability or classification accuracy\.
### III\-CTime\-Aware Valuation Objective
However, in time\-series data scenarios, the value of a sample depends not only on its information contribution, but also on temporal factors\. Intuitively, when concept drift or valid\-window effects exist, samples closer totreft\_\{\\mathrm\{ref\}\}are often more representative of the current distribution\. Meanwhile, some historical samples may still contain regularities that are important for long\-term generalization\. Therefore, it is necessary to introduce a controllable temporal modulation mechanism into the Shapley framework for fairly allocating marginal contributions\.
Problem definition\.Given a timestamped training setDD, a validation setDvalD\_\{\\mathrm\{val\}\}, and a utility functionU\(⋅\)U\(\\cdot\), the goal is to learn a sample\-level valuation vectorϕTDS∈ℝN\\phi^\{\\mathrm\{TDS\}\}\\in\\mathbb\{R\}^\{N\}that simultaneously characterizes: \(1\) the marginal contribution of a sample to model utility, namely its information value; and \(2\) the timeliness of a sample relative totreft\_\{\\mathrm\{ref\}\}, namely its temporal value\. This can be formally expressed as
ϕiTDS=f\(ϕiShapley,Δti,λ\),\\phi^\{\\mathrm\{TDS\}\}\_\{i\}=f\\left\(\\phi^\{\\mathrm\{Shapley\}\}\_\{i\},\\Delta t\_\{i\},\\lambda\\right\),\(5\)whereϕiShapley\\phi^\{\\mathrm\{Shapley\}\}\_\{i\}denotes the traditional Shapley value, andλ\\lambdais the temporal decay parameter\.
In the model construction, the methods proposed in the following sections explicitly define a temporal weightwi\(Δti\)w\_\{i\}\(\\Delta t\_\{i\}\)and use it to weight marginal contributions, thereby obtaining time\-aware valuation results\. This enables the valuation to exhibit controllable decay or nonlinear variation with respect toΔt\\Delta t\. The overall framework is illustrated in Fig\.[1](https://arxiv.org/html/2605.08153#S3.F1): the temporal pathway maps the freshness or staleness of samples to temporal weights, while the utility pathway provides marginal utilities\. The two pathways are combined in the approximation process based on permutation sampling, producing sample valuation results that can be further used for downstream tasks such as noise detection and data selection/removal\.
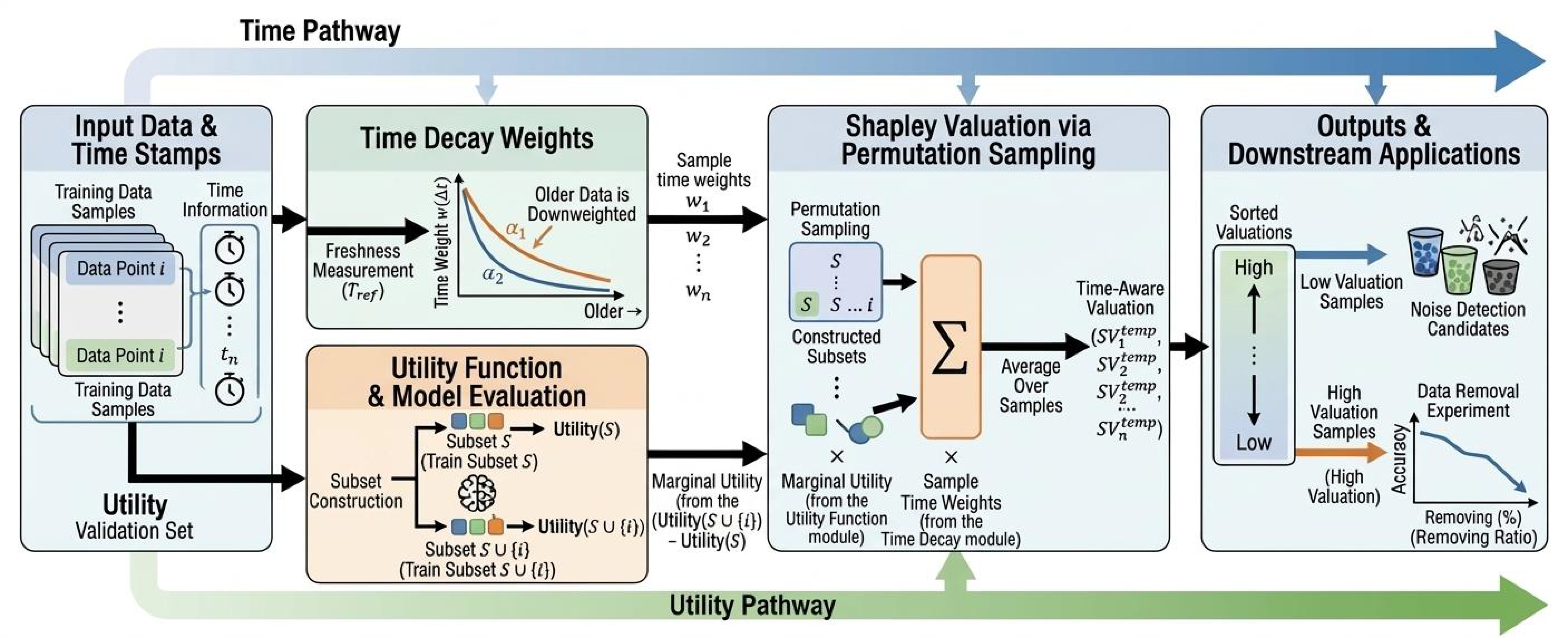Figure 1:Overview of the temporal Shapley valuation framework\. The upper temporal pathway maps sample freshness or staleness to temporal weights, while the lower utility pathway provides marginal utilities\. The two pathways are combined in the Shapley approximation process based on permutation sampling, producing sample valuations for downstream tasks such as noise detection and data removal\.
## IVMethodology
To address the limitations of traditional Shapley value methods in time\-series data, this paper proposes three progressively enhanced methods, forming a complete technical framework from basic to advanced valuation\. While preserving the theoretical rigor of the Shapley value, these three methods incorporate the temporal dimension into the data valuation process through different technical routes, thereby enabling accurate quantification of the value of time\-series data\.
### IV\-ATemporal\-Decay Shapley \(TDS\)
#### IV\-A1Core Idea
The core idea of TDS is to treat the temporal dimension as a key regulating factor of sample value\. By introducing a temporal decay mechanism, the computation of the Shapley value jointly couples the information contribution of a sample and its temporal timeliness\. In this way, TDS preserves the fairness and rigor of the Shapley value under the cooperative game\-theoretic framework, while accurately characterizing the dynamic value of time\-series data\.
#### IV\-A2Mathematical Definition
Based on the time gapΔti\\Delta t\_\{i\}, an exponential decay weightwiw\_\{i\}is introduced to characterize the regulating effect of time on sample value\. It is defined as
wi=exp\(−λΔti\),w\_\{i\}=\\exp\(\-\\lambda\\Delta t\_\{i\}\),\(6\)whereλ\\lambdais the decay coefficient that controls the overall decay intensity\. The baseline TDS adopts the above exponential form\. When stronger nonlinear temporal changes need to be modeled, the power exponential decay introduced in Section[IV\-B](https://arxiv.org/html/2605.08153#S4.SS2)can be used as an extension\.
Let the reference time betreft\_\{\\mathrm\{ref\}\}, and let the collection time of sampleiibetit\_\{i\}\. The time gap is defined as
Δti=max\(0,tref−ti\)\.\\Delta t\_\{i\}=\\max\(0,t\_\{\\mathrm\{ref\}\}\-t\_\{i\}\)\.\(7\)To eliminate the influence of measurement units,Δti\\Delta t\_\{i\}can be further normalized by a selected characteristic time scaleTrefT\_\{\\mathrm\{ref\}\}before being substituted into the weighting function\.
By incorporating temporal decay weights, the TDS value is defined as the expected weighted marginal contribution of a sample over all possible subset permutations:
ϕiTDS=∑S⊆D∖\{xi\}\|S\|\!\(\|D\|−\|S\|−1\)\!\|D\|\!⋅wi⋅\(U\(S∪\{xi\}\)−U\(S\)\)\.\\phi^\{\\mathrm\{TDS\}\}\_\{i\}=\\sum\_\{S\\subseteq D\\setminus\\\{x\_\{i\}\\\}\}\\frac\{\|S\|\!\(\|D\|\-\|S\|\-1\)\!\}\{\|D\|\!\}\\cdot w\_\{i\}\\cdot\\left\(U\(S\\cup\\\{x\_\{i\}\\\}\)\-U\(S\)\\right\)\.\(8\)
#### IV\-A3Algorithm Implementation
Since the exact computation of the Shapley value has a computational complexity ofO\(2N\)O\(2^\{N\}\), permutation\-sampling\-based approximation algorithms are commonly adopted in practical applications\. The approximation procedure of TDS is shown in Algorithm[1](https://arxiv.org/html/2605.08153#algorithm1)\. The time complexity of this algorithm isO\(M⋅N⋅C\)O\(M\\cdot N\\cdot C\), whereCCdenotes the cost of a single model training and evaluation process\. By adjusting the number of samplesMM, a balance can be achieved between computational accuracy and efficiency\.
Input:Training data
\(Xtrain,ytrain\)\(X\_\{\\mathrm\{train\}\},y\_\{\\mathrm\{train\}\}\); validation data
\(Xval,yval\)\(X\_\{\\mathrm\{val\}\},y\_\{\\mathrm\{val\}\}\); classifier
clfclf; timestamps; decay rate
λ\\lambda; number of samples
MM
Output:TDS valuation vector
ϕ\\phi
1
2Initialize
ϕ=0\\phi=0;
3Compute time gaps:
Δt=current\_time−timestamps\\Delta t=\\mathrm\{current\\\_time\}\-\\mathrm\{timestamps\};
4Compute decay weights:
wi=exp\(−λ⋅Δti\)w\_\{i\}=\\exp\(\-\\lambda\\cdot\\Delta t\_\{i\}\);
5
6for*m←1m\\leftarrow 1toMM*do
7Generate a random permutation
π=random\_permutation\(N\)\\pi=\\mathrm\{random\\\_permutation\}\(N\);
8Initialize subset
S=∅S=\\emptysetand previous performance
prev\_perf=Noneprev\\\_perf=\\mathrm\{None\};
9
10for*i∈πi\\in\\pi*do
11
S←S∪\{xi\}S\\leftarrow S\\cup\\\{x\_\{i\}\\\};
12Train classifier:
clf\.fit\(XS,yS\)clf\.fit\(X\_\{S\},y\_\{S\}\);
13Compute current performance:
curr\_perf=accuracy\(clf\.predict\(Xval\),yval\)curr\\\_perf=accuracy\(clf\.predict\(X\_\{\\mathrm\{val\}\}\),y\_\{\\mathrm\{val\}\}\);
14
15if*prev\_perf≠Noneprev\\\_perf\\neq\\mathrm\{None\}*then
16
ϕ\[i\]←ϕ\[i\]\+wi⋅\(curr\_perf−prev\_perf\)\\phi\[i\]\\leftarrow\\phi\[i\]\+w\_\{i\}\\cdot\(curr\\\_perf\-prev\\\_perf\);
17
18end if
19
prev\_perf←curr\_perfprev\\\_perf\\leftarrow curr\\\_perf;
20
21end for
22
23end for
24return*ϕ/M\\phi/M*;
Algorithm 1Approximate Computation of TDS
### IV\-BImproved TDS
#### IV\-B1Method Motivation
Although the exponential decay function used in the basic TDS method can adapt to scenarios with linear temporal drift, it has limitations in the following two types of complex time\-series scenarios:
1. 1\.Nonlinear temporal drift\.In some tasks, the decay of sample value exhibits nonlinear characteristics\. The uniformly decreasing nature of exponential decay cannot accurately fit such nonlinear trends\.
2. 2\.Valid\-window\-sensitive scenarios\.In some tasks, data have a clear valid time window\. However, the gradual decay of the exponential function may still assign relatively high weights to samples outside the valid window\.
#### IV\-B2Design of the Power Decay Function
In this paper, the improved TDS adopts the power exponential decay mode, which is defined as
wi=exp\(−λΔtip\),w\_\{i\}=\\exp\(\-\\lambda\\Delta t\_\{i\}^\{p\}\),\(9\)whereppis a nonlinear regulation parameter\. Whenp<1p<1, the decay rate slows down asΔti\\Delta t\_\{i\}increases; whenp\>1p\>1, the decay rate accelerates asΔti\\Delta t\_\{i\}increases; and whenp=1p=1, the function degenerates into standard exponential decay\.
#### IV\-B3Algorithm Implementation
The core algorithm of the improved TDS is built upon the basic TDS algorithm\. It introduces power exponential decay weights and controls the decay rate and degree of nonlinearity through the parameters\(λ,p\)\(\\lambda,p\)\. In addition, a positive scaling coefficientα\>0\\alpha\>0can be introduced, and the valuation can be uniformly written asϕ=αϕTDS\\phi=\\alpha\\phi^\{\\mathrm\{TDS\}\}\. This coefficient can be used to match numerical scales under different utility metrics or serve as an interface for linear combination with other additive valuation terms\.
Input:Training data
\(Xtrain,ytrain\)\(X\_\{\\mathrm\{train\}\},y\_\{\\mathrm\{train\}\}\); validation data
\(Xval,yval\)\(X\_\{\\mathrm\{val\}\},y\_\{\\mathrm\{val\}\}\); classifier
clfclf; timestamps; power decay parameters
\(λ,p\)\(\\lambda,p\); scaling coefficient
α\\alpha; number of samples
MM
Output:Improved TDS valuation vector
ϕ\\phi
1
2Initialize
ϕ=0\\phi=0;
3Compute time gaps:
Δt=current\_time−timestamps\\Delta t=\\mathrm\{current\\\_time\}\-\\mathrm\{timestamps\};
4Compute power exponential decay weights:
wi=exp\(−λ⋅\(Δti\)p\)w\_\{i\}=\\exp\(\-\\lambda\\cdot\(\\Delta t\_\{i\}\)^\{p\}\);
5
6for*m←1m\\leftarrow 1toMM*do
7Generate a random permutation
π=random\_permutation\(N\)\\pi=\\mathrm\{random\\\_permutation\}\(N\);
8Initialize subset
S=∅S=\\emptysetand previous performance
prev\_perf=Noneprev\\\_perf=\\mathrm\{None\};
9
10for*i∈πi\\in\\pi*do
11
S←S∪\{xi\}S\\leftarrow S\\cup\\\{x\_\{i\}\\\};
12Train classifier:
clf\.fit\(XS,yS\)clf\.fit\(X\_\{S\},y\_\{S\}\);
13Compute current performance:
curr\_perf=accuracy\(clf\.predict\(Xval\),yval\)curr\\\_perf=accuracy\(clf\.predict\(X\_\{\\mathrm\{val\}\}\),y\_\{\\mathrm\{val\}\}\);
14
15if*prev\_perf≠Noneprev\\\_perf\\neq\\mathrm\{None\}*then
16
ϕ\[i\]←ϕ\[i\]\+wi⋅\(curr\_perf−prev\_perf\)\\phi\[i\]\\leftarrow\\phi\[i\]\+w\_\{i\}\\cdot\(curr\\\_perf\-prev\\\_perf\);
17
18end if
19
prev\_perf←curr\_perfprev\\\_perf\\leftarrow curr\\\_perf;
20
21end for
22
23end for
24return*α⋅\(ϕ/M\)\\alpha\\cdot\(\\phi/M\)*;
Algorithm 2Improved TDS Algorithm
### IV\-CMulti\-Scale Temporal\-Decay Shapley \(MS\-TDS\)
#### IV\-C1Method Motivation
Both the basic TDS and the improved TDS follow a single\-scale temporal decay logic, which has clear limitations for multi\-scale time\-series data\. In real\-world time\-series tasks, samples often contain both short\-term hotspot information and long\-term foundational information\. Short\-term information reflects immediate patterns in the data and is crucial for adapting the model to the current distribution, whereas long\-term information reflects fundamental regularities and is indispensable for maintaining model generalization ability\.
#### IV\-C2Multi\-Scale Computation
The multi\-scale design of MS\-TDS follows the principle of prioritizing physical interpretability\. The scale set is defined as\{τ1,τ2,τ3\}\\\{\\tau\_\{1\},\\tau\_\{2\},\\tau\_\{3\}\\\}\. To ensure that the decay rate of each scale matches its temporal granularity, each scaleτk\\tau\_\{k\}is transformed into a corresponding decay coefficientλk\\lambda\_\{k\}:
λk=λτk,\\lambda\_\{k\}=\\frac\{\\lambda\}\{\\tau\_\{k\}\},\(10\)whereλ\\lambdais a predefined baseline decay intensity, which has the same meaning as in the single\-scale TDS, andτk\\tau\_\{k\}denotes the temporal granularity of thekk\-th scale\. A largerτk\\tau\_\{k\}corresponds to a smallerλk\\lambda\_\{k\}, resulting in smoother weight decay and thus placing greater emphasis on sample contributions over longer periods\.
#### IV\-C3Multi\-Scale Parallel Valuation
For each scalekk, the temporal weightwi\(k\)w\_\{i\}^\{\(k\)\}is calculated using the decay coefficientλk\\lambda\_\{k\}of that scale\. It is then combined with Shapley marginal contributions to obtain the valuation of sampleiiat scalekk:
ϕi\(k\)=∑S⊆D∖\{xi\}\|S\|\!\(\|D\|−\|S\|−1\)\!\|D\|\!⋅wi\(k\)⋅\[U\(S∪\{xi\}\)−U\(S\)\]\.\\phi\_\{i\}^\{\(k\)\}=\\sum\_\{S\\subseteq D\\setminus\\\{x\_\{i\}\\\}\}\\frac\{\|S\|\!\(\|D\|\-\|S\|\-1\)\!\}\{\|D\|\!\}\\cdot w\_\{i\}^\{\(k\)\}\\cdot\\left\[U\(S\\cup\\\{x\_\{i\}\\\}\)\-U\(S\)\\right\]\.\(11\)
#### IV\-C4Sample\-Level Adaptive Fusion
This paper adopts sample\-level adaptive fusion based on cross\-scale summation and inverse\-variance rescaling\. The dispersion of multi\-scale valuations is used to characterize uncertainty, and a stability\-related coefficient is applied to the cross\-scale aggregated result\. Let the valuation vector of theii\-th sample acrossKKscales be
Φi=\[ϕi\(1\),…,ϕi\(K\)\]\.\\Phi\_\{i\}=\[\\phi\_\{i\}^\{\(1\)\},\\ldots,\\phi\_\{i\}^\{\(K\)\}\]\.\(12\)The fusion process is defined as follows\.
1. 1\.Variance statistic: σi2=Var\(Φi\)\.\\sigma\_\{i\}^\{2\}=\\mathrm\{Var\}\(\\Phi\_\{i\}\)\.\(13\)
2. 2\.Sample\-level stability coefficient: ai=1σi2\+ϵ\.a\_\{i\}=\\frac\{1\}\{\\sigma\_\{i\}^\{2\}\+\\epsilon\}\.\(14\)
3. 3\.Final valuation: ϕiMS=ai∑k=1Kϕi\(k\)\.\\phi\_\{i\}^\{\\mathrm\{MS\}\}=a\_\{i\}\\sum\_\{k=1\}^\{K\}\\phi\_\{i\}^\{\(k\)\}\.\(15\)
This formulation is equivalent to first linearly aggregating the multi\-scale valuations and then applying an overall rescaling based on the sample\-level stability coefficient\. Samples with higher cross\-scale consistency, namely smaller variance, obtain larger stability coefficientsaia\_\{i\}and are therefore more strongly emphasized in the final valuation\. In contrast, samples with larger cross\-scale disagreement, namely larger variance, are relatively suppressed to reduce valuation noise caused by scale uncertainty\. In implementation,ϵ\\epsilonis used to avoid numerical amplification when the variance is too small\. The number of scalesKKand the selection of\{τk\}\\\{\\tau\_\{k\}\\\}should be consistent with the sampling interval and the major identifiable periodic scales in the data, and should be kept consistent across datasets for fair comparison\.
#### IV\-C5Algorithm Implementation
In summary, TDS, improved TDS, and MS\-TDS share the same implementation backbone in terms of permutation sampling and marginal utility evaluation\. Their main differences lie in the construction of temporal weights and whether cross\-scale fusion is performed\. In the following experiments, under the same training\-validation split and utility definition, these three methods and the baselines are compared in a unified manner for noise detection and high\-value data removal\. The experimental section first describes the datasets, baselines, and evaluation metrics, and then presents the main tables and curves for noise detection and high\-value removal, so as to align the methodology described in this section with the empirical results reported later\.
Accordingly, MS\-TDS first calls Algorithm[2](https://arxiv.org/html/2605.08153#algorithm2)at each scalekkto obtainϕ\(k\)\\phi^\{\(k\)\}, and then estimates cross\-scale dispersion at the sample level and performs inverse\-variance rescaling\. The pseudo\-code is shown in Algorithm[3](https://arxiv.org/html/2605.08153#algorithm3)\.
Input:Training data
\(Xtrain,ytrain\)\(X\_\{\\mathrm\{train\}\},y\_\{\\mathrm\{train\}\}\); validation data
\(Xval,yval\)\(X\_\{\\mathrm\{val\}\},y\_\{\\mathrm\{val\}\}\); classifier
clfclf; timestamps; scale set
\{τk\}\\\{\\tau\_\{k\}\\\}; parameters
\(λ,ϵ\)\(\\lambda,\\epsilon\)
Output:MS\-TDS valuation vector
ϕMS\\phi^\{\\mathrm\{MS\}\}
1
2Initialize
K←\|\{τk\}\|K\\leftarrow\|\\\{\\tau\_\{k\}\\\}\|,
N←\|Xtrain\|N\\leftarrow\|X\_\{\\mathrm\{train\}\}\|;
3
4for*k←1k\\leftarrow 1toKK*do
5Compute scale\-specific decay rate:
λk←λ/τk\\lambda\_\{k\}\\leftarrow\\lambda/\\tau\_\{k\};
6Run Algorithm[2](https://arxiv.org/html/2605.08153#algorithm2)to obtain scale\-specific valuation
ϕ\(k\)\\phi^\{\(k\)\};
7
8end for
9
10for*i←1i\\leftarrow 1toNN*do
11Compute mean:
ϕ¯i←1K∑k=1Kϕi\(k\)\\bar\{\\phi\}\_\{i\}\\leftarrow\\frac\{1\}\{K\}\\sum\_\{k=1\}^\{K\}\\phi\_\{i\}^\{\(k\)\};
12
13Compute variance:
σi2←1K∑k=1K\(ϕi\(k\)−ϕ¯i\)2\\sigma\_\{i\}^\{2\}\\leftarrow\\frac\{1\}\{K\}\\sum\_\{k=1\}^\{K\}\(\\phi\_\{i\}^\{\(k\)\}\-\\bar\{\\phi\}\_\{i\}\)^\{2\};
14
15Compute stability coefficient:
ai←1σi2\+ϵa\_\{i\}\\leftarrow\\frac\{1\}\{\\sigma\_\{i\}^\{2\}\+\\epsilon\};
16
17Compute fused valuation:
ϕiMS←ai∑k=1Kϕi\(k\)\\phi\_\{i\}^\{\\mathrm\{MS\}\}\\leftarrow a\_\{i\}\\sum\_\{k=1\}^\{K\}\\phi\_\{i\}^\{\(k\)\};
18
19end for
20return*ϕMS\\phi^\{\\mathrm\{MS\}\}*;
Algorithm 3MS\-TDS Multi\-Scale Adaptive Fusion Algorithm
## VExperiments
### V\-AExperimental Setup
#### V\-A1Datasets
Table[I](https://arxiv.org/html/2605.08153#S5.T1)summarizes the basic statistics and temporal property labels of the four experimental subsets\. The task meanings and feature profiles of each dataset are described as follows\.
Covertype dataset\.This dataset corresponds to a classification task related to forest cover types\. It contains a relatively large number of features, with 54 dimensions, and exhibits weak temporal characteristics, mainly reflected in collection batches or weak drift\.
Wind dataset\.This dataset corresponds to a binary classification task related to wind power or meteorological data\. It exhibits clear periodic changes and is therefore regarded as strongly time\-series data, with 14\-dimensional features\.
Electricity dataset\.This dataset corresponds to a binary classification task related to power load\. It contains dynamic characteristics such as intra\-day and weekly periodic patterns, and is regarded as strongly time\-series data, with 8\-dimensional features\.
Traffic dataset\.This dataset corresponds to a binary classification task for traffic congestion prediction\. It contains features such as traffic flow, speed, accidents, hour, and weekday\. The time span is relatively long, about 62\.46 days, and the dataset exhibits strong temporal characteristics\.
To ensure cross\-dataset comparability, all experiments use subsets of the same scale and preserve the original temporal order\. The time span is calculated as the difference between the maximum and minimum timestamps in each subset, consistent with Table[I](https://arxiv.org/html/2605.08153#S5.T1)\. Unless otherwise specified, the data splitting strategy, training process, and utility function are kept identical across different methods, so as to avoid implementation differences interfering with the comparison of valuation methods themselves\.
TABLE I:Summary of time\-series datasets used in the experiments\.DatasetTotal samplesFeaturesTime span \(days\)Temporal propertycovertype1500540\.01Weakly time\-series \(batch\-wise drift\)wind1500140\.01Strongly time\-series \(meteorological, periodicity\)electricity150080\.01Strongly time\-series \(power load, periodicity\)traffic1500562\.46Strongly time\-series \(daily/weekly patterns\)
#### V\-A2Baseline Methods
We compare six types of methods, which can be divided into two groups: traditional Shapley variants and temporal Shapley methods\. The former mainly optimize marginal contribution estimation under supervised predictive performance, whereas the latter explicitly model temporal correlation and timeliness\.
Traditional Shapley variants:
- •LOO \(Leave\-One\-Out\):This method measures sample value by removing each sample individually and retraining the model, using the change in model loss or performance as the valuation criterion\.
- •TMC\-Shapley \(Truncated Monte Carlo Shapley\):This method approximates Shapley values using truncated Monte Carlo permutation sampling\[[6](https://arxiv.org/html/2605.08153#bib.bib6)\]\.
- •Beta\-Shapley:This method introduces a Beta distribution to adjust the weights of sample subsets and reduces valuation noise by controlling the shape parameters of the distribution\.
Temporal Shapley methods proposed in this paper:
- •TDS \(Temporal\-Decay Shapley\):This is the basic temporal decay method, which adopts exponential decay weights\.
- •Improved TDS:This method extends TDS by adopting power exponential decay, thereby improving its adaptability to nonlinear temporal patterns\.
- •MS\-TDS \(Multi\-Scale Temporal\-Decay Shapley\):This is an adaptive multi\-scale method that performs multi\-scale parallel valuation and sample\-level adaptive fusion\.
#### V\-A3Evaluation Metrics
Considering two core applications of data valuation, namely identifying harmful samples and selecting key samples, this paper reports results from two perspectives: noise detectability and high\-value ranking consistency\. The corresponding metrics are described below\.
Noise data detection\.
Noise identification AUC\.After random noise, namely label flipping, is introduced into the training labels, samples whose valuation scores are lower than the median valuation score of all training samples are regarded as noise candidates\. A binary classification task is then constructed, and the area under the ROC curve \(AUC\) is calculated\.
High\-value data removal\.
The following three metrics are all based on weighted cumulative quantities derived from removal curves, consistent with the implementation\. Specifically, performance differences between adjacent removal steps are first calculated and accumulated, and then weighted by1/k1/k\. For Brier score and cross\-entropy, the sign is reversed so that larger values indicate more severe performance degradation after removing high\-value samples\.
Weighted accuracy drop \(WAD\)\.Let the accuracy sequence obtained under different removal ratios be\{ak\}k=0T\\\{a\_\{k\}\\\}\_\{k=0\}^\{T\}, wherea0a\_\{0\}denotes the performance before removal, and setaT\+1=0a\_\{T\+1\}=0\. LetΔk=ak−1−ak\\Delta\_\{k\}=a\_\{k\-1\}\-a\_\{k\}andCk=∑j=1kΔjC\_\{k\}=\\sum\_\{j=1\}^\{k\}\\Delta\_\{j\}\. Then,
WAD=∑k=1T\+11kCk\.\\mathrm\{WAD\}=\\sum\_\{k=1\}^\{T\+1\}\\frac\{1\}\{k\}C\_\{k\}\.\(16\)This definition characterizes the overall degradation of the removal curve rather than the performance difference at a single point\.
Weighted Brier score drop \(WBD\)\.For the Brier score sequence, a cumulative quantityCk\(BS\)C\_\{k\}^\{\(\\mathrm\{BS\}\)\}is constructed in the same way as above, and the sign is reversed:
WBD=−∑k=1T\+11kCk\(BS\)\.\\mathrm\{WBD\}=\-\\sum\_\{k=1\}^\{T\+1\}\\frac\{1\}\{k\}C\_\{k\}^\{\(\\mathrm\{BS\}\)\}\.\(17\)Here,Ck\(BS\)C\_\{k\}^\{\(\\mathrm\{BS\}\)\}is obtained by accumulating adjacent differences in the Brier score sequence\. A larger WBD indicates a more significant degradation in probabilistic prediction quality after high\-value samples are removed\.
Weighted cross\-entropy drop \(WCD\)\.Similarly, for the cross\-entropy sequence,
WCD=−∑k=1T\+11kCk\(CE\)\.\\mathrm\{WCD\}=\-\\sum\_\{k=1\}^\{T\+1\}\\frac\{1\}\{k\}C\_\{k\}^\{\(\\mathrm\{CE\}\)\}\.\(18\)Here,Ck\(CE\)C\_\{k\}^\{\(\\mathrm\{CE\}\)\}is obtained by accumulating adjacent differences in the cross\-entropy sequence\. A larger WCD indicates a more significant increase in uncertainty after high\-value samples are removed\.
### V\-BExperimental Results
#### V\-B1Noise Data Detection
Table[II](https://arxiv.org/html/2605.08153#S5.T2)reports the noise identification AUC on four datasets under LR and NB models\. Overall, no single method consistently performs best across all settings\. TMC\-Shapley and Beta\-Shapley achieve the highest AUC in several cases, while TDS, improved TDS, and MS\-TDS remain competitive in most settings and are generally among the leading methods\.
This phenomenon is consistent with the optimization objectives of different methods\. Noise detection is essentially a supervised task, evaluating whether a sample harms predictive performance due to incorrect labels\. Methods such as TMC\-Shapley directly construct valuation scores around marginal predictive gains, and are therefore naturally aligned with this objective, often achieving better AUC results\. In contrast, the core objective of TDS is to model temporal correlation and timeliness, such as recency and temporal consistency, rather than explicitly optimizing label correctness\. Therefore, it may not always achieve the best performance under the definition of label\-flipping noise\.
Furthermore, the noise construction in this paper adopts random label flipping\. Such synthetic noise is weakly correlated with the temporal structure itself, and therefore does not always align with the temporal weighting mechanism\. In other words, although the TDS family may not always lead in noise AUC, this does not negate its value in time\-varying data scenarios\. When the task focuses on concept drift, non\-stationary processes, or temporally correlated distribution shifts, temporal information provides a value dimension that is orthogonal to supervised noise detectability\.
TABLE II:Noise detection AUC of different valuation methods on four datasets with LR and NB models\.MethodLRNBcovertypewindelectricitytrafficcovertypewindelectricitytrafficLOO0\.5250\.4670\.5340\.4420\.4300\.4760\.4550\.491Beta\-Shapley0\.6630\.6140\.6770\.8920\.6310\.6020\.6250\.757TMC\-Shapley0\.7110\.7140\.8060\.8920\.6800\.7120\.7410\.804TDS0\.7210\.7050\.7530\.8640\.6630\.7340\.7280\.773TDS\-improved0\.7410\.6930\.7520\.8660\.6650\.7130\.7230\.753MS\-TDS0\.7380\.6990\.7630\.8780\.6890\.7160\.7210\.766
#### V\-B2High\-Value Data Removal
The WAD, WBD, and WCD results for high\-value sample removal are reported in Table[III](https://arxiv.org/html/2605.08153#S5.T3)for LR and Table[IV](https://arxiv.org/html/2605.08153#S5.T4)for NB\. The following discussion first summarizes the rankings and curve patterns shown in the tables, and then presents the removal curves under LR and NB\.
Tables[III](https://arxiv.org/html/2605.08153#S5.T3)and[IV](https://arxiv.org/html/2605.08153#S5.T4)report three types of degradation metrics after high\-value samples are removed\. Compared with noise detection, the TDS family shows more stable advantages in this task\. In particular, MS\-TDS achieves the best results for almost all metrics under the LR setting, and also belongs to the leading group under the NB setting\.
This result indicates that temporal information directly improves the quality of sample ranking\. If a valuation method can more accurately identify samples that are most critical to the current distribution, then removing samples in descending order of valuation should lead to faster model performance degradation, corresponding to higher WAD, WBD, and WCD values\. The advantages of MS\-TDS across multiple datasets suggest that multi\-scale fusion helps simultaneously capture short\-term fluctuations and long\-term structures, thereby improving the stability of high\-value sample identification\.
The removal curves in Fig\.[2](https://arxiv.org/html/2605.08153#S5.F2)and Fig\.[3](https://arxiv.org/html/2605.08153#S5.F3)are consistent with the conclusions from the tables\. Time\-sensitive methods usually trigger steeper performance degradation in the early and middle stages of removal, whereas some static baselines show slower degradation\. This provides complementary evidence to the noise detection experiments: temporal valuation methods may not always be optimal for label noise identification, but they are more advantageous in data selection tasks driven by time\-varying correlations\.
TABLE III:High\-value data removal performance \(LR\): WAD, WBD, and WCD on four time\-series datasets\.MethodcovertypewindelectricitytrafficWADWBDWCDWADWBDWCDWADWBDWCDWADWBDWCDLOO\-0\.0220\.0520\.6670\.1280\.1011\.1790\.1260\.1201\.7920\.1650\.0240\.067Beta\-Shapley0\.1790\.1722\.1900\.2360\.2285\.9370\.2830\.2103\.4440\.1280\.0640\.184TMC\-Shapley0\.2350\.2152\.1290\.3040\.2964\.3320\.2280\.1692\.3540\.2460\.1150\.329TDS0\.3280\.3052\.4250\.4120\.4217\.0180\.4300\.3524\.4530\.3840\.1820\.543TDS\-improved0\.3240\.3002\.8390\.4020\.4087\.0010\.4510\.3764\.8220\.3540\.1970\.590MS\-TDS0\.3670\.3383\.4630\.4310\.4437\.8400\.4660\.4046\.1100\.4140\.2250\.696
TABLE IV:High\-value data removal performance \(NB\): WAD, WBD, and WCD on four time\-series datasets\.MethodcovertypewindelectricitytrafficWADWBDWCDWADWBDWCDWADWBDWCDWADWBDWCDLOO0\.0010\.0240\.3840\.0220\.0240\.4320\.1170\.0980\.9680\.1300\.0120\.044Beta\-Shapley0\.1840\.1470\.8990\.2020\.1791\.7340\.1570\.1371\.7270\.0850\.0360\.105TMC\-Shapley0\.2450\.1601\.2170\.2170\.1661\.3910\.2070\.1150\.9800\.1130\.0300\.089TDS0\.3020\.2221\.8670\.3190\.2884\.0320\.3180\.2194\.0870\.1210\.0460\.144TDS\-improved0\.3140\.2231\.5730\.3290\.2913\.7420\.3080\.2242\.4200\.1210\.0330\.106MS\-TDS0\.3370\.2531\.8670\.3550\.3324\.8680\.3260\.2334\.3150\.1540\.0500\.152
Figure 2:High\-value data removal under the LR model, where the performance of different valuation methods changes as the removal ratio increases\.Figure 3:High\-value data removal under the NB model, where the performance of different valuation methods changes as the removal ratio increases\.
## VIRelated Work
### VI\-AShapley Value Theory
The Shapley value theory originates from cooperative game theory and was first proposed by Shapley in 1953\[[5](https://arxiv.org/html/2605.08153#bib.bib5)\], providing a mathematical foundation for fair allocation problems\. This theory quantifies the value of each participant through the weighted average of marginal contributions, and possesses desirable properties such as uniqueness, symmetry, and additivity\. In recent years, with the growing demand for interpretability in machine learning, Shapley values have been widely applied to feature importance analysis and model explanation\[[12](https://arxiv.org/html/2605.08153#bib.bib12),[13](https://arxiv.org/html/2605.08153#bib.bib13)\]\.
The SHAP framework proposed by Lundberg and Lee in 2017\[[14](https://arxiv.org/html/2605.08153#bib.bib14)\]successfully introduced Shapley values into the field of machine learning and enabled interpretability analysis of model predictions\. By modeling feature contributions as Shapley values, this framework provides a unified explanation tool for black\-box models and has promoted the rapid development of explainable AI\. However, SHAP mainly focuses on feature\-level contribution analysis and pays relatively limited attention to sample\-level data valuation\.
### VI\-BData Valuation Methods
In the field of data valuation, Jia et al\. proposed the Fast Approximate Shapley method in 2019\[[2](https://arxiv.org/html/2605.08153#bib.bib2)\], which reduces the computational complexity fromO\(2N\)O\(2^\{N\}\)toO\(M⋅N\)O\(M\\cdot N\)through Monte Carlo sampling, providing a feasible path for large\-scale data valuation\. Ghorbani and Zou further extended the theory of data valuation in 2019 and proposed the Data Shapley method\[[1](https://arxiv.org/html/2605.08153#bib.bib1)\], which is specifically designed to evaluate the contribution of training data to model performance\. Ancona et al\. proposed a polynomial\-time approximation method for Shapley values in 2019\[[15](https://arxiv.org/html/2605.08153#bib.bib15)\], offering a scalable approach for Shapley\-based explanations of deep neural networks\.
For approximate Shapley value computation, Castro et al\. proposed a sampling\-based polynomial method in 2009\[[6](https://arxiv.org/html/2605.08153#bib.bib6)\], which reduces computational complexity through Monte Carlo sampling\. Frye et al\. proposed an asymmetric Shapley value framework in 2020\[[16](https://arxiv.org/html/2605.08153#bib.bib16)\], incorporating causal priors into model\-agnostic interpretability analysis\.
### VI\-CTime\-Series Data Analysis
The key challenge in time\-series data valuation lies in how to effectively model the influence of the temporal dimension on sample value\. Traditional data valuation methods usually assume that samples are independent and identically distributed, and thus ignore the time\-varying nature of sample value in time\-series data\. In the field of time\-series modeling, the ARIMA model proposed by Box and Jenkins in 1970\[[17](https://arxiv.org/html/2605.08153#bib.bib17)\]laid an important foundation for time\-series analysis\. The LSTM network proposed by Hochreiter and Schmidhuber in 1997\[[18](https://arxiv.org/html/2605.08153#bib.bib18)\]addressed the gradient vanishing problem in traditional recurrent neural networks and provided an effective solution for modeling long\-term dependencies\. Cho et al\. further proposed the GRU network in 2014\[[19](https://arxiv.org/html/2605.08153#bib.bib19)\], simplifying the network structure while maintaining the performance of LSTM\.
In deep learning\-based time\-series modeling, the Transformer model proposed by Vaswani et al\. in 2017\[[20](https://arxiv.org/html/2605.08153#bib.bib20)\]achieved parallel sequence processing through the self\-attention mechanism, providing a new direction for modeling long time\-series data\. Zhou et al\. proposed the Informer model in 2021\[[21](https://arxiv.org/html/2605.08153#bib.bib21)\], which is specifically designed for long sequence time\-series forecasting\. By introducing the ProbSparse self\-attention mechanism and distillation operations, Informer significantly improves computational efficiency\.
### VI\-DMulti\-Scale Analysis
Time\-series data often contain information at multiple temporal scales, and a single temporal decay function is difficult to fully capture the temporal value characteristics of samples\. In multi\-scale analysis, the wavelet transform theory proposed by Mallat in 1989\[[11](https://arxiv.org/html/2605.08153#bib.bib11)\]provides a mathematical foundation for multi\-scale signal decomposition\. Overall, existing studies have made progress in three directions: Shapley approximation\-based valuation, time\-series modeling, and multi\-scale analysis\. However, for the specific problem of time\-series data valuation, there is still a lack of a unified framework that integrates temporal timeliness modeling and multi\-scale information fusion into the same valuation process\. Based on the idea of sample\-level Shapley valuation, this paper combines temporal decay with sample\-level multi\-scale fusion, forming a unified data valuation framework for time\-series data\.
## VIIConclusion
This paper proposes an improved temporal Shapley data valuation method that enables accurate assessment of sample value in time\-series data through a temporal decay mechanism and a multi\-scale fusion strategy\. Specifically, three progressively enhanced temporal Shapley methods are proposed\. TDS incorporates temporal information into Shapley value computation through exponential decay weights; the improved TDS adopts power exponential decay to better adapt to nonlinear temporal drift; and MS\-TDS constructs a multi\-scale fusion mechanism that balances the value of short\-term hotspot samples and long\-term foundational samples through parallel multi\-scale valuation and sample\-level adaptive fusion\.
Experimental results on four heterogeneous datasets show that the proposed methods generally outperform traditional methods in noise detection and high\-value data identification tasks\. In most settings with strongly temporal data, the advantages of the proposed methods are relatively more evident, demonstrating their ability to improve the accuracy and robustness of data valuation\. These results indicate that jointly modeling temporal timeliness and multi\-scale information can bring stable benefits, and provide an empirically supported methodological path for time\-series data valuation\.
Meanwhile, this paper still has several limitations\. The current experiments are mainly conducted on fixed\-size subsets and classification tasks, and the form of the utility function is relatively fixed\. Future work can conduct more systematic evaluations on larger\-scale datasets, more task types such as regression and long\-sequence forecasting, and more diverse utility definitions, so as to further verify the generalization ability of the proposed methods\.
Future research directions include: \(1\) adaptive optimization of timestamp quality, by combining time\-series imputation algorithms and anomaly detection algorithms to construct an end\-to\-end pipeline; \(2\) efficient approximate computation, by drawing on quantized valuation ideas to store and compute multi\-scale valuation results with low precision; \(3\) customized utility functions, by designing task\-specific utility functions for extreme samples and special scenarios; and \(4\) learnable parameter selection, by using few\-shot meta\-learning or Bayesian optimization to automatically select optimal parameters according to the temporal characteristics of datasets\.
## References
- \[1\]A\. Ghorbani and J\. Zou, “Data Shapley: Equitable valuation of data for machine learning,” in*Proc\. Int\. Conf\. Mach\. Learn\. \(ICML\)*, 2019, pp\. 2242–2251\.
- \[2\]R\. Jia, D\. Dao, B\. Wang, F\. A\. Hubis*et al\.*, “Towards efficient data valuation based on the Shapley value,” in*Proc\. Int\. Conf\. Artif\. Intell\. Statist\. \(AISTATS\)*, 2019, pp\. 1167–1176\.
- \[3\]J\. Gama, I\. Zliobaite, A\. Bifet, M\. Pechenizkiy, and A\. Bouchachia, “A survey on concept drift adaptation,”*ACM Comput\. Surv\.*, vol\. 46, no\. 4, pp\. 1–37, 2014\.
- \[4\]G\. I\. Webb, R\. Hyde, H\. Cao, H\. L\. Nguyen, and F\. Petitjean, “Characterizing concept drift,”*Data Min\. Knowl\. Discov\.*, vol\. 30, no\. 4, pp\. 964–994, 2016\.
- \[5\]L\. S\. Shapley, “A value for N\-person games,” in*Contributions to the Theory of Games*\. Princeton Univ\. Press, 1953, vol\. 2, pp\. 307–317\.
- \[6\]J\. Castro, D\. Gomez, and J\. Tejada, “Polynomial calculation of the Shapley value based on sampling,”*Comput\. Oper\. Res\.*, vol\. 36, no\. 5, pp\. 1726–1730, 2009\.
- \[7\]D\. Kifer, S\. Ben\-David, and J\. Gehrke, “Detecting change in data streams,” in*Proc\. VLDB*, 2004, pp\. 180–191\.
- \[8\]A\. Tsymbal, “The problem of concept drift: Definitions and related work,” Trinity College Dublin, Comput\. Sci\. Dept\., Tech\. Rep\., 2004\.
- \[9\]Y\. Kwon and J\. Zou, “Beta Shapley: A fair and robust data valuation framework for machine learning,” in*Proc\. AAAI Conf\. Artif\. Intell\.*, vol\. 36, no\. 7, 2022, pp\. 7940–7948\.
- \[10\]W\. Xia, W\. Li, and H\. Wang, “P\-Shapley: Shapley values on probabilistic classifiers,” in*Adv\. Neural Inf\. Process\. Syst\. \(NeurIPS\)*, 2024\.
- \[11\]S\. G\. Mallat, “A theory for multiresolution signal decomposition: The wavelet representation,”*IEEE Trans\. Pattern Anal\. Mach\. Intell\.*, vol\. 11, no\. 7, pp\. 674–693, 1989\.
- \[12\]E\. Štrumbelj and I\. Kononenko, “Explaining prediction models and individual predictions with feature contributions,”*Knowl\. Inf\. Syst\.*, vol\. 41, no\. 3, pp\. 647–665, 2014\.
- \[13\]——, “An efficient explanation of individual classifications using game theory,”*J\. Mach\. Learn\. Res\.*, vol\. 11, pp\. 1–18, 2010\.
- \[14\]S\. M\. Lundberg and S\.\-I\. Lee, “A unified approach to interpreting model predictions,” in*Adv\. Neural Inf\. Process\. Syst\.*, vol\. 30, 2017, pp\. 4765–4774\.
- \[15\]M\. Ancona, E\. Ceolini, C\. Öztireli, and M\. Gross, “Explaining deep neural networks with a polynomial time algorithm for Shapley value approximation,” in*Proc\. Int\. Conf\. Mach\. Learn\. \(ICML\)*, 2019, pp\. 272–281\.
- \[16\]C\. Frye, C\. Rowat, and I\. Feige, “Asymmetric Shapley values: Incorporating causal knowledge into model\-agnostic explainability,” in*Adv\. Neural Inf\. Process\. Syst\.*, vol\. 33, 2020, pp\. 1229–1239\.
- \[17\]G\. E\. P\. Box and G\. M\. Jenkins,*Time Series Analysis: Forecasting and Control*\. Holden\-Day, 1970\.
- \[18\]S\. Hochreiter and J\. Schmidhuber, “Long short\-term memory,”*Neural Comput\.*, vol\. 9, no\. 8, pp\. 1735–1780, 1997\.
- \[19\]K\. Cho, B\. van Merriënboer, D\. Bahdanau, and Y\. Bengio, “Learning phrase representations using RNN encoder\-decoder for statistical machine translation,” in*Proc\. Conf\. Empirical Methods Natural Lang\. Process\.*, 2014, pp\. 1724–1734\.
- \[20\]A\. Vaswani, N\. Shazeer, N\. Parmar*et al\.*, “Attention is all you need,” in*Adv\. Neural Inf\. Process\. Syst\.*, vol\. 30, 2017, pp\. 5998–6008\.
- \[21\]H\. Zhou, S\. Zhang, J\. Peng, S\. Zhang, J\. Li, H\. Xiong, and W\. Zhang, “Informer: Beyond efficient transformer for long sequence time\-series forecasting,” in*Proc\. AAAI Conf\. Artif\. Intell\.*, vol\. 35, no\. 12, 2021, pp\. 11 106–11 115\.Similar Articles
TTCD:Transformer Integrated Temporal Causal Discovery from Non-Stationary Time Series Data
The paper introduces TTCD, a novel framework for temporal causal discovery from non-stationary time series data using transformer-based feature learning and reconstruction-guided signal distillation.
A decoder-only foundation model for time-series forecasting
This article presents a research paper on Time-Series Foundation Model (TimeFM), a decoder-only model that achieves near-optimal zero-shot performance across diverse time-series datasets by adapting large language model techniques.
SDFlow: Similarity-Driven Flow Matching for Time Series Generation
This paper introduces SDFlow, a similarity-driven flow matching framework for time series generation that addresses exposure bias in autoregressive models. It achieves state-of-the-art performance and inference speedups by operating in the frozen VQ latent space with low-rank manifold decomposition.
Retrieval Mechanisms Surpass Long-Context Scaling in Time Series Forecasting
This academic paper challenges the effectiveness of long-context scaling in time series forecasting, demonstrating that retrieval-based methods outperform standard architectures like PatchTST and foundation models such as Chronos and Moirai.
Detecting Time Series Anomalies Like an Expert: A Multi-Agent LLM Framework with Specialized Analyzers
The article introduces SAGE, a multi-agent LLM framework for time-series anomaly detection that uses specialized analyzers to improve interpretability and reliability. It demonstrates superior performance over baselines on three benchmarks and enhances diagnostic reporting through structured evidence consolidation.