Cached at:
06/26/26, 05:10 PM
# LFM2.5-230M: Built to Run Anywhere | Liquid AI
Source: [https://www.liquid.ai/blog/lfm2-5-230m](https://www.liquid.ai/blog/lfm2-5-230m)
Today, we're releasing**LFM2\.5\-230M**, our smallest model yet\. It’s a fast, lightweight foundation for developers to fine\-tune and deploy in agentic workflows\. Built on the LFM2 architecture, it delivers exceptionally fast inference and runs everywhere, from cloud GPUs to low\-cost CPUs \(213 tok/s decode speed on Galaxy S25 Ultra, 42 tok/s on a Raspberry Pi 5\)\. Despite its small size, it’s surprisingly capable at tool use and data extraction tasks\.
The base \(LFM2\.5\-230M\-Base\) and post\-trained \(LFM2\.5\-230M\) models are available today on[Hugging Face](https://huggingface.co/LiquidAI/LFM2.5-230M)\. Check out our[docs](https://docs.liquid.ai/)on how to run and fine\-tune them locally\.
## Training & Fine\-tuning
The model was pre\-trained for 19T tokens, including a 32K context extension phase\. We apply a lightweight post\-training recipe designed to preserve flexibility for developers targeting their own downstream applications\.
The recipe consists of three stages:**\(1\) supervised fine\-tuning with distillation from LFM2\.5\-350M, \(2\) direct preference optimization, and \(3\) multi\-domain reinforcement learning**\. The final checkpoint balances strong out\-of\-the\-box capabilities with adaptability to downstream specialization, while remaining competitive with larger models\.
As an early look at ongoing work, we deployed LFM2\.5\-230M on a Unitree G1 humanoid robot, running entirely on\-device on its onboard NVIDIA Jetson Orin\. Here the model acts as a skill\-selection layer: it takes a single natural\-language instruction and decomposes it into a sequence of tool calls that invoke pre\-trained low\-level skills provided by NVIDIA's SONIC framework\. After a quick fine\-tune for this task, the model turns a free\-form command such as
> *"Hold still for 2 seconds, then walk forward at 1 meter per second for 3 meters, hold a forward one\-leg kneel for 5 seconds, and walk backward at 0\.5 meters per second for 3 meters"*
into a structured, multi\-step plan, chaining skills like timed walking at a target velocity and a one\-legged kneel\. While the behaviors are deliberately simple at this stage, we think it's a compelling signal: a 230M\-parameter model can be quickly fine\-tuned and deployed on\-device to serve as the natural\-language control interface for a humanoid\.
[https://www\.youtube\.com/shorts/CuMOWa2y1Ho](https://www.youtube.com/shorts/CuMOWa2y1Ho)
## Benchmarks
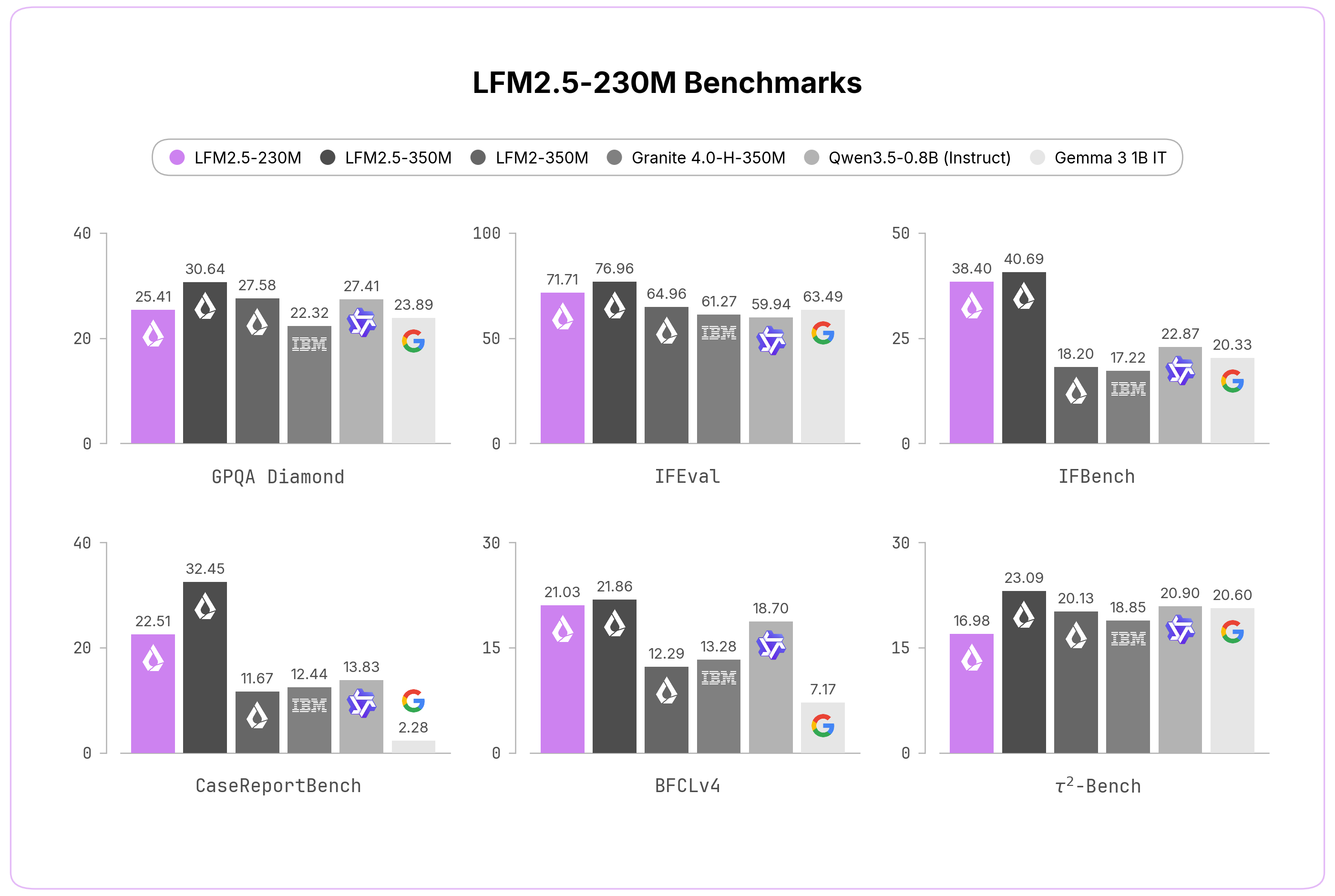
We evaluated LFM2\.5\-230M across ten benchmarks covering both core capabilities and applied tasks\. Despite its size, it**competes with and often beats models more than twice as large**, spanning knowledge \(GPQA Diamond, MMLU\-Pro\), instruction following \(IFEval, IFBench, Multi\-IF\), data extraction \(CaseReportBench\), and tool use \(BFCLv3, BFCLv4, τ²\-Bench Telecom and Retail\)\.
**Model**
**GPQA Diamond**
**MMLU\-Pro**
**IFEval**
**IFBench**
**Multi\-IF**
**LFM2\.5\-230M**
25\.41
20\.25
71\.71
38\.40
37\.70
**LFM2\.5\-350M**
30\.64
20\.01
76\.96
40\.69
44\.92
**LFM2\-350M**
27\.58
19\.29
64\.96
18\.20
32\.92
**Granite 4\.0\-H\-350M**
22\.32
13\.14
61\.27
17\.22
28\.70
**Granite 4\.0\-350M**
25\.91
12\.84
53\.48
15\.98
24\.21
**Qwen3\.5\-0\.8B \(Instruct\)**
27\.41
37\.42
59\.94
22\.87
41\.68
Gemma 3 1B IT
23\.89
14\.04
63\.49
20\.33
44\.25
**Model**
**CaseReportBench**
**BFCLv3**
**BFCLv4**
**𝜏²\-Bench Telecom**
**𝜏²\-Bench Retail**
**LFM2\.5\-230M**
22\.51
43\.26
21\.03
5\.26
13\.68
**LFM2\.5\-350M**
32\.45
44\.11
21\.86
18\.86
17\.84
**LFM2\-350M**
11\.67
22\.95
12\.29
10\.82
5\.56
**Granite 4\.0\-H\-350M**
12\.44
43\.07
13\.28
13\.74
6\.14
**Granite 4\.0\-350M**
0\.84
39\.58
13\.73
2\.92
6\.14
**Qwen3\.5\-0\.8B \(Instruct\)**
13\.83
35\.08
18\.70
12\.57
6\.14
Gemma 3 1B IT
2\.28
16\.61
7\.17
9\.36
6\.43
This makes LFM2\.5\-230M an ideal solution to power large\-scale data extraction pipelines or lightweight on\-device agentic workloads\. However, given its compact size, we do not recommend it for reasoning\-heavy workloads such as advanced math, code generation, or creative writing\.
## Fast Inference Everywhere
LFM2\.5\-230M ships with day\-one support across the inference ecosystem:
- **llama\.cpp**— GGUF checkpoints for efficient edge inference
- **MLX**— Optimized inference for Apple Silicon
- **vLLM**— GPU\-accelerated serving for production throughput
- **SGLang**— GPU\-accelerated serving for production throughput
- **ONNX**— Cross\-platform inference across diverse accelerators
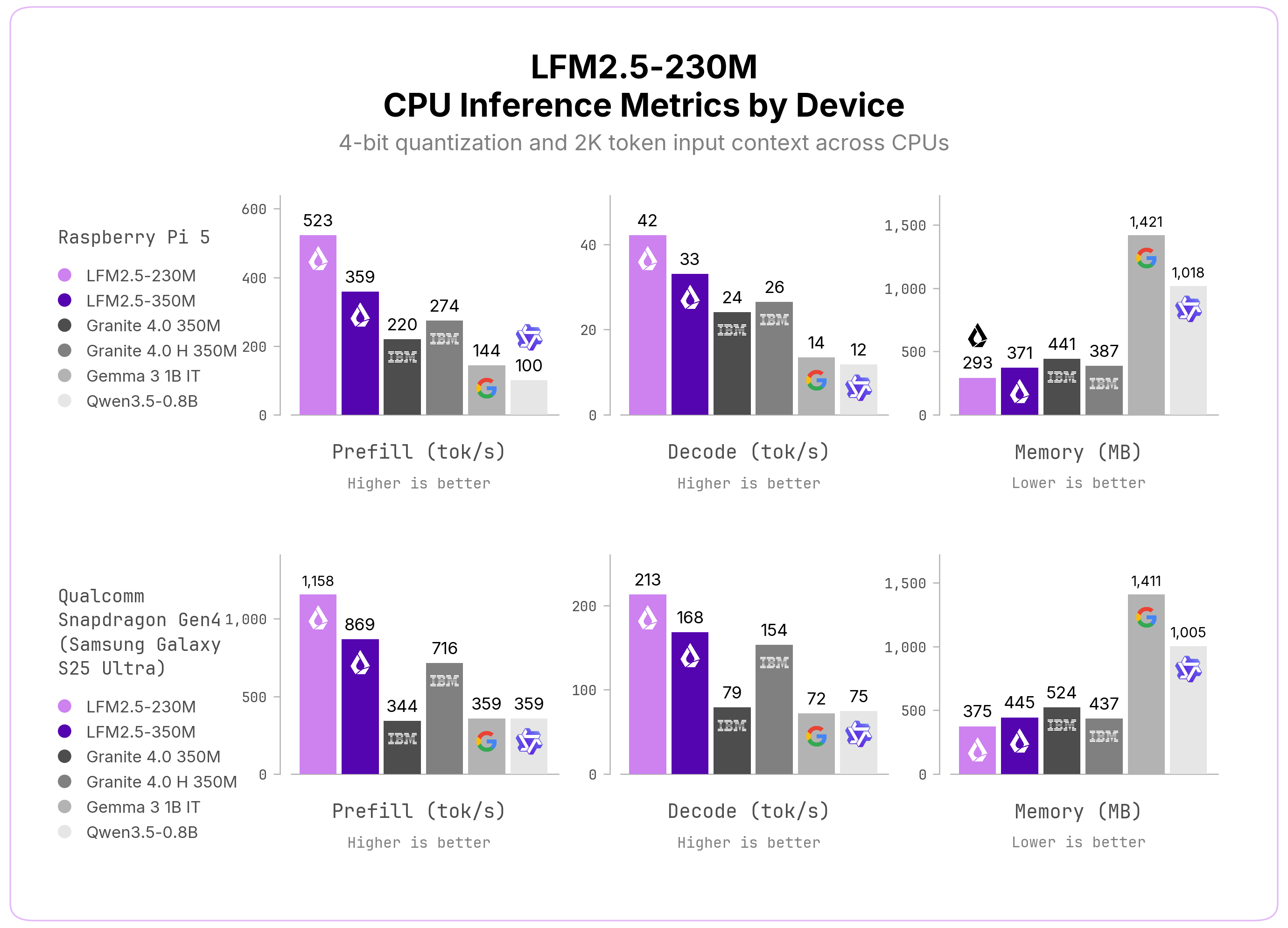
**CPU inference\.**Thanks to the efficient LFM2 architecture, LFM2\.5\-230M is considerably faster than similar\-sized models, including SSM hybrids and Gated Delta Networks\. On both a Raspberry Pi 5 and a Qualcomm Snapdragon Gen4 \(Samsung Galaxy S25 Ultra\), it delivers the highest prefill and decode throughput in its class while keeping the smallest memory footprint\. We tune the flash\-attention flag per device to maximize prefill on each platform: enabled \(\-fa 1\) on the Raspberry Pi 5 and disabled \(\-fa 0\) on the Snapdragon Gen4\.
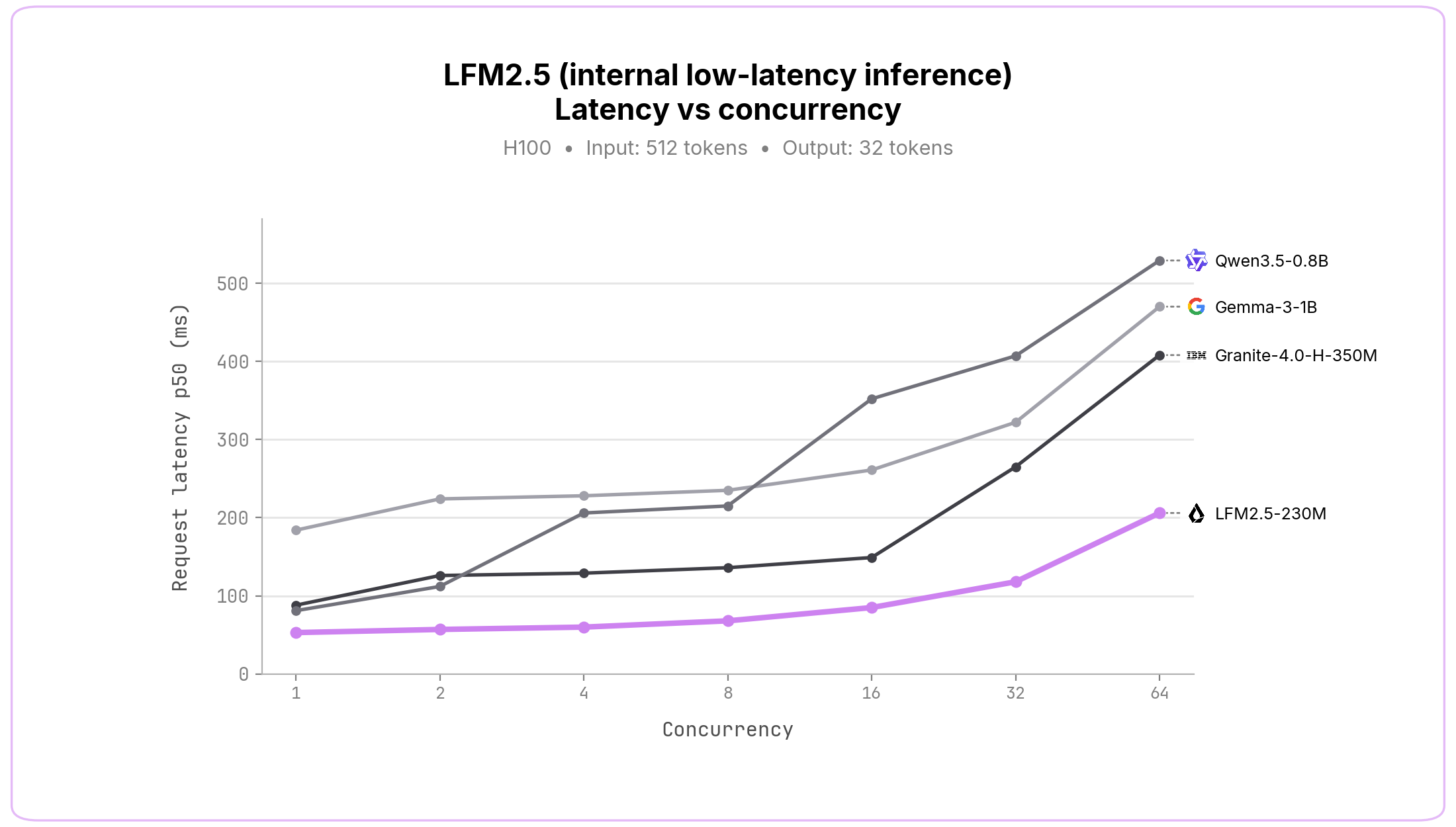
**GPU inference\.**For production\-grade enterprise deployments, we have also developed an internal GPU inference stack that delivers extremely low\-latency serving\. We benchmark it against other small models running on SGLang, and across all concurrency levels, LFM2\.5 models achieve considerably lower end\-to\-end latency\.
## Get Started
Start building today with LFM2\.5\-230M and LFM2\.5\-230M\-Base, available on[Hugging Face\.](https://huggingface.co/LiquidAI/LFM2.5-230M)
With LFM2\.5, we're delivering on our vision of AI that runs anywhere\. These models are:
- **Open\-weight**— Download, fine\-tune, and deploy without restrictions
- **Fast from day one**— Native support for llama\.cpp, NexaSDK, MLX, and vLLM across Apple, AMD, Qualcomm, and Nvidia hardware
- **A complete family**— From base models for customization to specialized audio and vision variants, one architecture covers diverse use cases
The edge AI future is here\. We can't wait to see what you build\.
### Citation
Please cite this article as:
> Liquid AI, "LFM2\.5\-230M: Built to Run Anywhere",*Liquid AI Blog*, Jun 2026\.
Or use the BibTeX citation:
```
@article{liquidAI2026230M,
author = {Liquid AI},
title = {LFM2.5-230M:
Built to Run Anywhere},
journal = {Liquid AI Blog},
year = {2026},
note = {www.liquid.ai/blog/lfm2-5-230m}
}
```