Cached at:
06/01/26, 09:41 AM
# A 1B humanizer that matches human writing on an AI detector
Source: [https://mlx-optiq.com/blog/humanizer-stacked-lora](https://mlx-optiq.com/blog/humanizer-stacked-lora)
Engineering · June 1, 2026
**Two LoRA adapters stacked on a 1B model close 100 % of the gap to human writing on the RADAR AI detector\.**Source AI drafts get 0\.51 from RADAR\. EditLens humans get 0\.37\. With the SFT \+ DPO LoRAs applied together on`MiniCPM5\-1B\-OptIQ\-4bit`, the rewrites also come back as 0\.37, on the same 200 held\-out drafts\. Whole stack runs on a 24 GB Mac\.
## The result
200 held\-out AI drafts from the[EditLens](https://huggingface.co/datasets/pangram/editlens_iclr)ICLR 2026 corpus, rewritten by each system, then scored by[RADAR\-Vicuna\-7B](https://huggingface.co/TrustSafeAI/RADAR-Vicuna-7B)\. Lower P\(AI\) means more human\-like\.
PipelineP\(AI\) ↓Δ vs sourceGap closedSource AI draft \(Qwen3\.5\-4B \+ gemma\-4\-e4b\)0\.51——MiniCPM5\-1B \+ SFT humanizer LoRA0\.50\-0\.017 %**MiniCPM5\-1B \+ SFT \+ DPO LoRAs stacked**0\.37\-0\.14100 %Human reference \(target\)0\.37\-0\.14100 %
Slop\-phrase frequency \(boilerplate patterns like "a testament to" and "underscores the importance of"\) drops from 0\.6 per 1K tokens in the source to 0\.0 in the stacked output\. The human reference set has 0\.1\.
The base model takes 875 MB on disk, each adapter another 120 MB\. No 70B model and no API key required\.
## The recipe in three commands
OptIQ 0\.1\.4 ships every piece\. The full pipeline is:
Optional first stop: the Lab's dataset builder\. The Style transfer \+ DPO from preference pairs templates produced the SFT and DPO datasets for this run\.terminal · 1\. quantizebash
```
$ pip install 'mlx-optiq>=0.1.4'
$ optiq convert openbmb/MiniCPM5-1B \
--target-bpw 5.0 --candidate-bits 4,8 \
--output ./optiq_mixed
```
Sensitivity\-aware mixed\-precision quantization\. Most layers land at 4\-bit, the sensitive ones at 8\-bit\. Result is 875 MB and only 1\.06 GB short of the bf16 base on Capability Score \([eval framework](https://mlx-optiq.com/blog/eval-framework)\)\.
terminal · 2\. train SFT, then DPO continuing from itbash
```
$ optiq lora train ./optiq_mixed \
--data ./sft_dataset --method sft \
--preset large --iters 600 \
--output ./adapters/humanizer-sft
$ optiq lora train ./optiq_mixed \
--data ./dpo_dataset --method dpo \
--preset large --iters 300 \
--mount-adapter ./adapters/humanizer-sft \
--output ./adapters/humanizer-dpo
```
`\-\-mount\-adapter`is the standard SFT then DPO continuation recipe\. It stacks a frozen SFT LoRA alongside a trainable DPO LoRA on every adapted layer\. The DPO reference forward zeroes only the trainable scale, so the KL term in the loss is anchored against base \+ SFT, which is the SFT model\. That matches how every modern alignment pipeline defines "DPO continuing from SFT"\. The saved adapter holds only the DPO delta\.
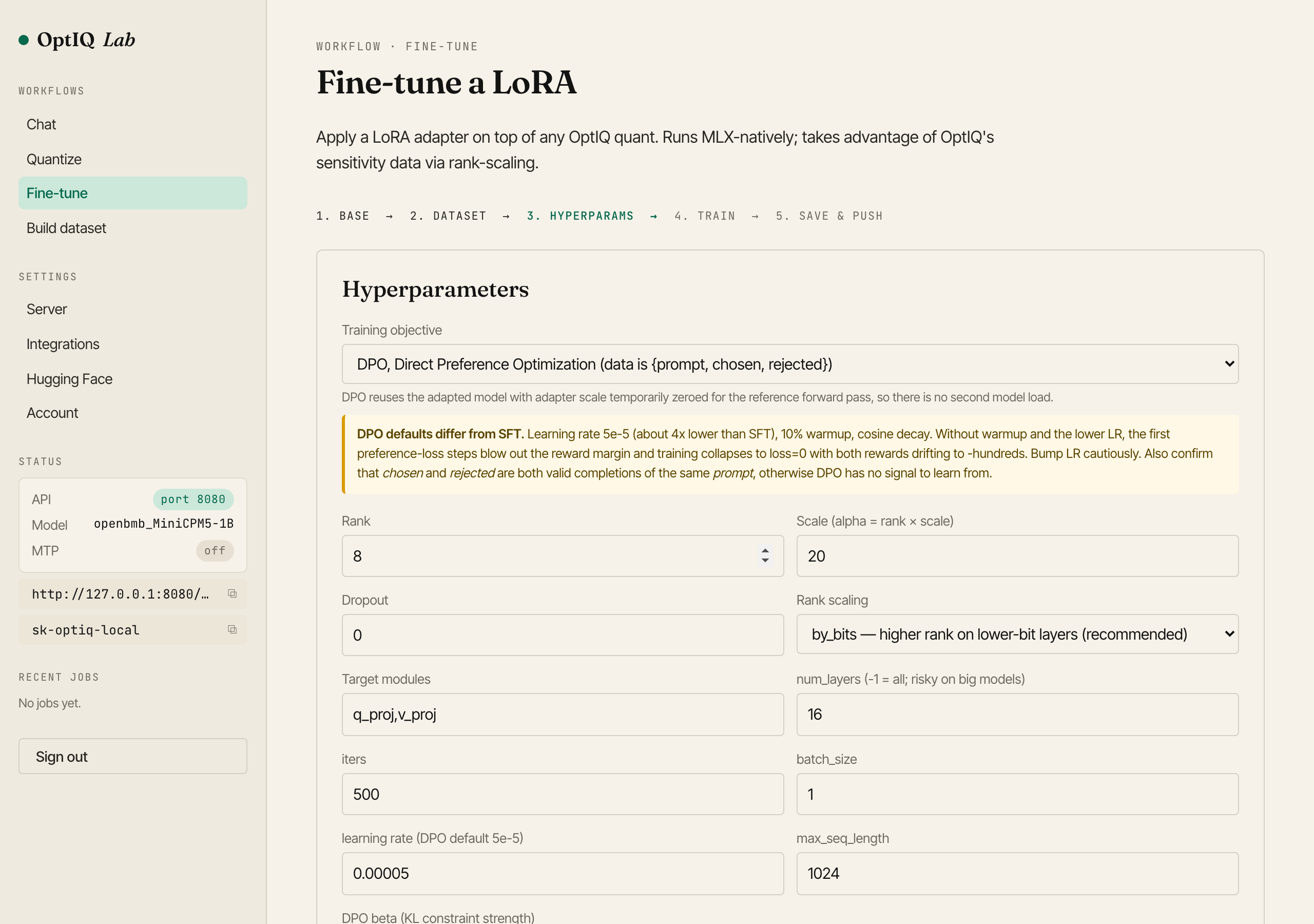OptIQ Lab Fine\-tune wizard, Hyperparameters step\. Picking DPO swaps the learning rate to 5e\-5 and surfaces the DPO defaults banner\.terminal · 3\. serve both, stacked per\-requestbash
```
$ optiq serve --model ./optiq_mixed \
--adapter ./adapters/humanizer-sft \
--adapter ./adapters/humanizer-dpo
# request body activates both with the "+" operator:
$ curl localhost:8080/v1/chat/completions \
-d '{"model":"...","messages":[...],
"adapter":"humanizer-sft+humanizer-dpo"}'
```
`optiq serve`mounts both adapters on the same base model\. The request body's`adapter`field, given an`a\+b`form, applies both LoRA residuals during a single forward pass instead of switching between them, and there is no model reload\. The classic single\-adapter syntax \(`"adapter": "humanizer\-sft"`\) still works\. The sentinel`"adapter": "base"`bypasses adapter activation entirely\. Use it for A/B comparisons from the same served process\.
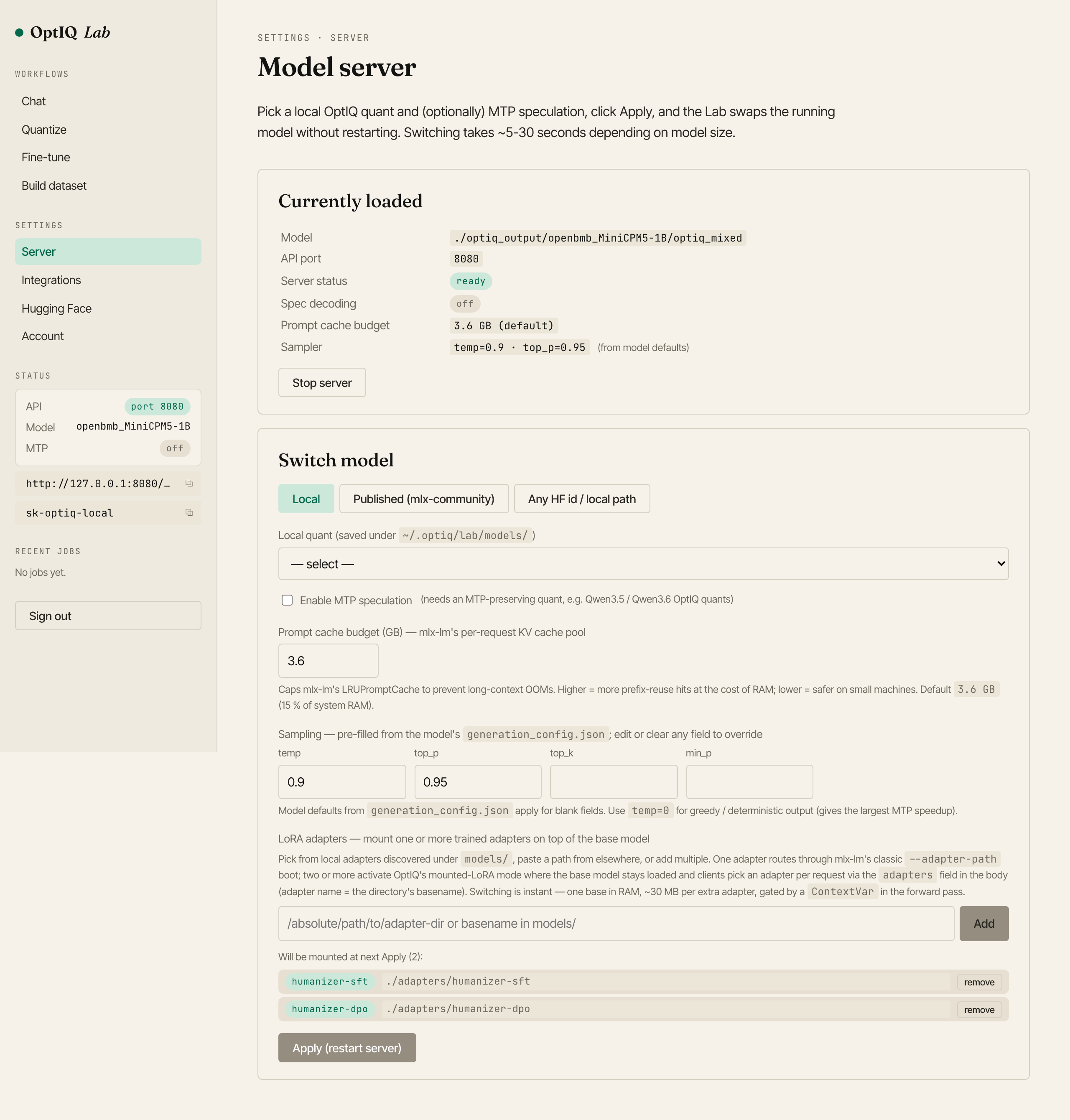The same multi\-adapter mount, surfaced in the Lab\. Settings → Server lists the registered adapters; once mounted they are picked per\-request from the Chat surface\.## Why the stack beats either adapter alone
The SFT adapter alone scores P\(AI\) = 0\.50, barely better than the source\. The DPO adapter on its own is meaningless\. It was trained as a delta from SFT, not an absolute LoRA\. Without SFT active, you're applying a small perturbation to the base model that doesn't recover the SFT distribution at all\.
The stack reproduces the training\-time forward pass:
StackedLoRALinear · trainingpython
```
# during training (frozen SFT + trainable DPO):
y = base(x) + sft_scale * (x @ sft_a @ sft_b)
+ dpo_scale * ((dropout(x) @ lora_a) @ lora_b)
# at serve time (both mounted, "a+b" syntax):
y = base(x) + sft_scale * (x @ sft_a @ sft_b)
+ dpo_scale * (x @ lora_a @ lora_b)
```
So the math at training time and the math at inference time work out to the same expression with the same weights, which is why the held\-out P\(AI\) lines up with what the training trajectory predicted\.
## The same flow in OptIQ Lab
If the CLI isn't your thing, the Lab UI walks through the same pipeline\. After training finishes, the wizard's last step exposes adapter combine \+ model export \+ push\-to\-Hugging\-Face as three optional checkboxes\.
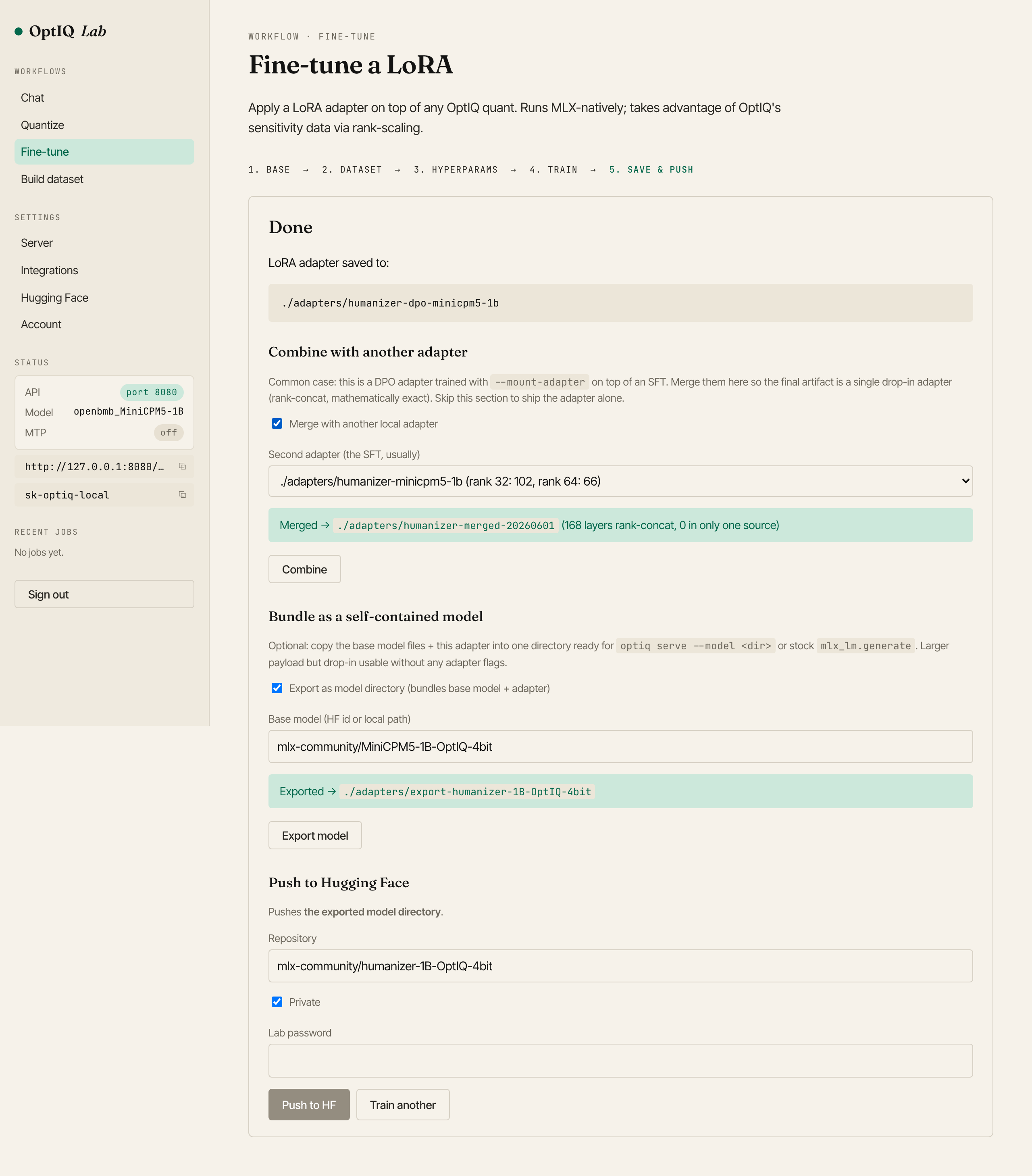Step 5 of the Fine\-tune wizard\. Combine merges two adapters, Bundle exports a model directory, Push ships it to the Hub\.## Try it
Everything \(base, both adapters, model card, held\-out eval\) is bundled into a single Hugging Face repo:[`mlx\-community/humanizer\-1B\-OptIQ\-4bit`](https://huggingface.co/mlx-community/humanizer-1B-OptIQ-4bit)\(~1\.1 GB\)\. Download once, serve with both adapters stacked:
terminal · use the published artifactbash
```
$ pip install 'mlx-optiq>=0.1.4'
$ huggingface-cli download mlx-community/humanizer-1B-OptIQ-4bit \
--local-dir ./humanizer-1B-OptIQ-4bit
$ optiq serve \
--model ./humanizer-1B-OptIQ-4bit \
--adapter ./humanizer-1B-OptIQ-4bit/adapters/humanizer-sft \
--adapter ./humanizer-1B-OptIQ-4bit/adapters/humanizer-dpo
```
OpenAI\-compatible endpoint on`localhost:8080`\. Point any client \(Open WebUI, Continue, your own scripts\) at it, send`"adapter": "humanizer\-sft\+humanizer\-dpo"`in the request body, and you have a local humanizer\.
A note on what we measuredRADAR\-Vicuna\-7B is one AI detector out of many\. Hitting P\(AI\) = 0\.37 means our rewrites land at the same place on RADAR's scale as the EditLens human reference set, on 200 held\-out drafts\. Other detectors will give different absolute numbers, and detector arms races mean any specific score has a shelf life\. The reproducible claim is the delta from source and the gap closure against a fixed human reference\. Both held up across our entire held\-out set\.
## Where to next
The piece of OptIQ that unlocked this is`\-\-mount\-adapter`plus the multi\-adapter serve, both shipped in v0\.1\.4\. They also work for any other SFT then DPO continuation, not just humanization\. If you have an SFT recipe and a preference dataset for any task \(code style, brand voice, refusal behavior, anything\), the same two commands give you a DPO LoRA that continues from your SFT instead of starting from scratch\.
Reference for the trainer, every`\-\-preset`option, and the dataset format is in the[LoRA fine\-tuning guide](https://mlx-optiq.com/docs/finetune)\. The multi\-adapter serve and the`"a\+b"`stacking syntax are in the[serve docs](https://mlx-optiq.com/docs/serve#adapters)\.
the mlx\-optiq team