@volokuleshov: 恭喜谷歌开源Gemma Diffusion!我想特别感谢一组非常有才华的康奈尔大学学生,他们在实验室开发了这个模型中许多新想法:
摘要
谷歌已开源DiffusionGemma,这是一种基于扩散的新型文本生成模型,采用块扩散和高效的编解码器技术,康奈尔大学的研究人员也做出了贡献。
查看缓存全文
缓存时间: 2026/06/12 02:52
祝贺Google开源Gemma Diffusion!
我想特别感谢一群才华横溢的康奈尔学生,他们在实验室中开发了我们在该模型中看到的许多新想法:
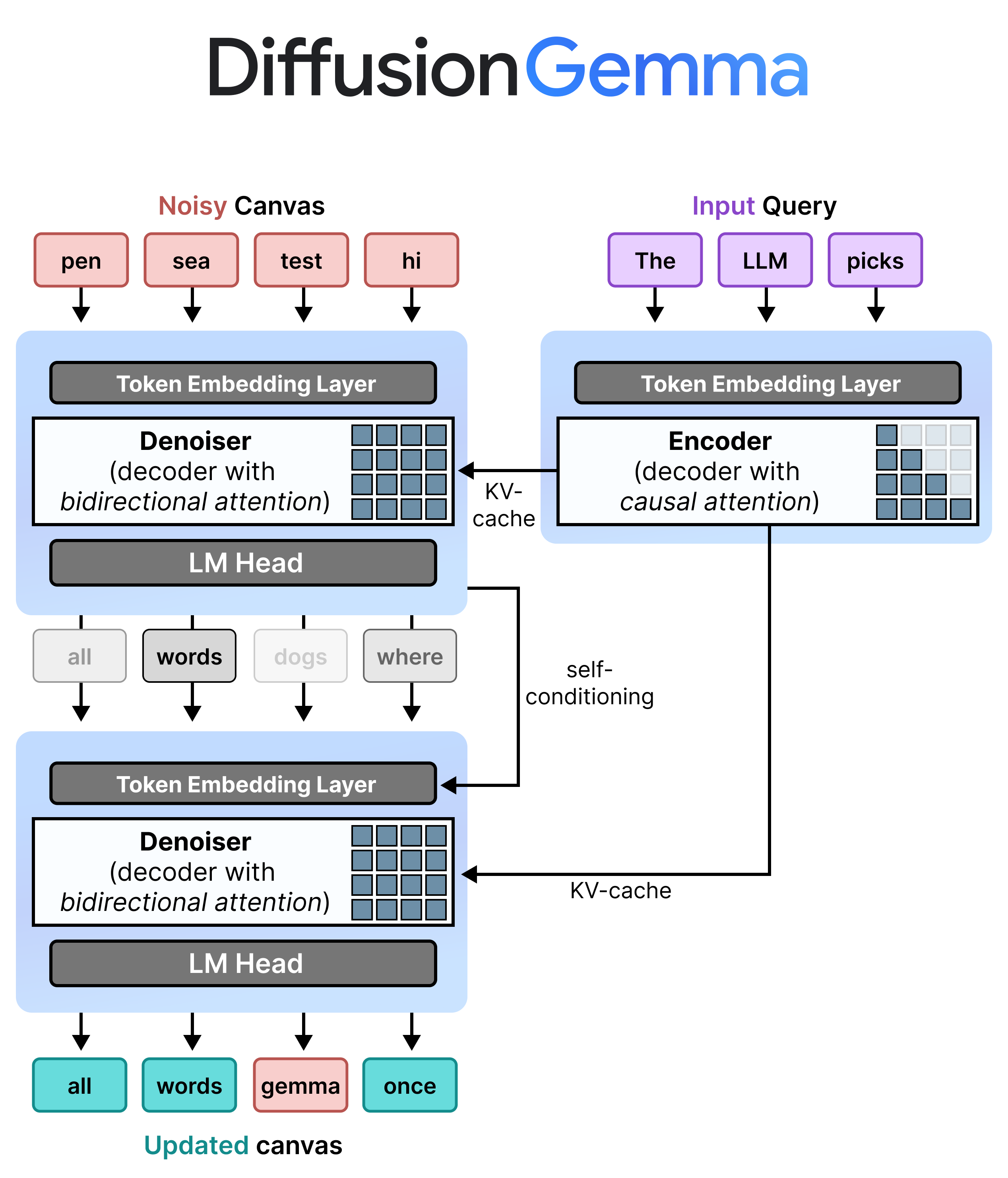
@mariannearr——块扩散(Block diffusion)使Gemma Diffusion能够生成任意长度的序列并支持KV缓存。
@mariannearr @SchiffYair——高效编码器-解码器扩散(E2D2)扩展了块扩散,并且是使Gemma真正快速的部分原因,通过运行更小的解码器模型来加速推理。
@SchiffYair @ssahoo_ @Guanghan__Wang——均匀扩散语言模型(UDLMs)是Gemma底层的一系列离散扩散模型,定义了其噪声过程和训练目标。这项工作建立在我们早期MDLMs中简化损失的基础上。
@ssahoo_——均匀扩散支持内置的错误纠正,并且与Duo中引入的蒸馏快速采样器特别有效。
这是一篇关于Gemma Diffusion的精彩概述:https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-diffusiongemma…
下面是学生们的论文链接:
视觉指南:DiffusionGemma
来源:https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-diffusiongemma 继Gemma 4 12B发布之后,还有另一个创新模型可以介绍给大家,DiffusionGemma!
这是我特别兴奋的一个,因为它是一种不同的文本生成方法,同时使用了现有“常规”大语言模型的许多优秀特性。我们将探讨旧方法、新方法以及它们如何并存。
在本指南中,我将介绍很多内容,因为DiffusionGemma有很多独特之处!你将了解更多关于扩散的一般知识、它如何用于离散文本、DiffusionGemma的架构,以及所有使用的有趣技术。
{kind=link}
准备好了,这会是一次有趣的探索 ;)
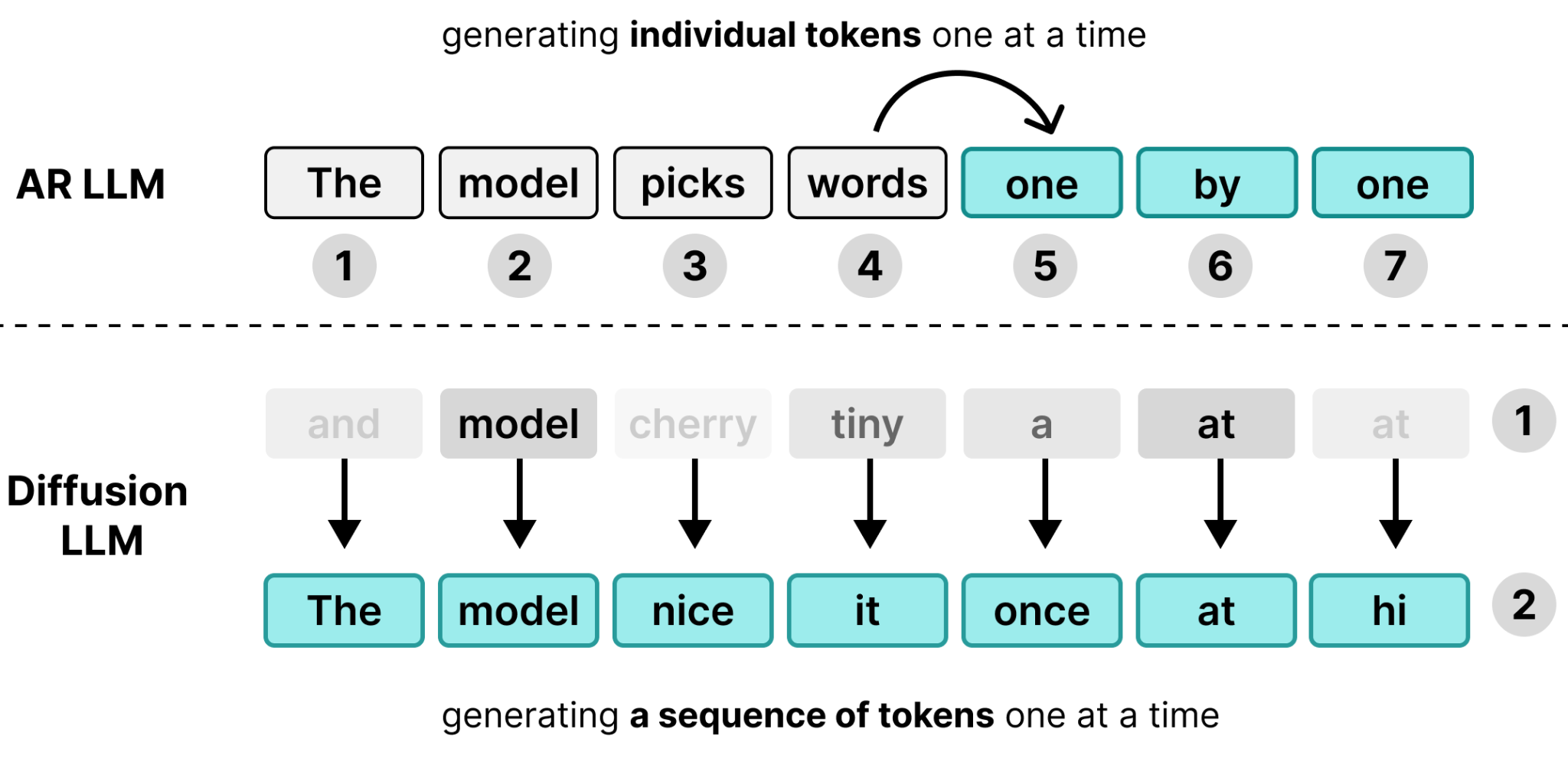
自回归大语言模型一次生成一个 token,并且适合同时服务多个用户。为什么?因为生成单个 token 对于单个用户来说计算成本非常低。在每一步中,生成 token 的时间很大一部分花在从内存加载权重上,而不是实际计算。
在解码过程中,这些常规 Transformer 模型是内存受限的(memory bound)而非计算受限的(compute bound)。这意味着,例如,生成一个 token 所需的时间对于 1 个用户和 256 个用户是一样的。
{kind=link}
原因在于权重只需要在每一步加载一次内存,无论服务多少个用户。也就是说,无论我们是将这些权重与 1 个用户的向量相乘,还是与 256 个用户的向量相乘,将权重移入内存的成本是一样的。通过将所有用户一起批处理,我们以几乎相同的成本完成相同的工作量。
但这并非免费的午餐,在某个点之后(取决于芯片本身),LLM 可能服务了太多用户而缺乏计算能力。你可以用屋顶线图(roofline plot)来可视化这种权衡。它展示了提升芯片性能(生成 token 所需时间)与芯片内存(从内存加载数据的速度)之间的影响。
当只服务一个用户(批大小为 1)时,LLM 是内存受限的,它加载大量权重但实际计算量很小。随着批大小的增加(相同的内存加载但更多的计算),你会接近一个“最佳点”(ride point),此时硬件被充分利用。
因此,虽然批处理适合同时服务多个用户,但对单个用户来说没有任何提升!它仍然以相同的速度接收 token。延迟没有差别。
DiffusionGemma 颠覆了这一局面。
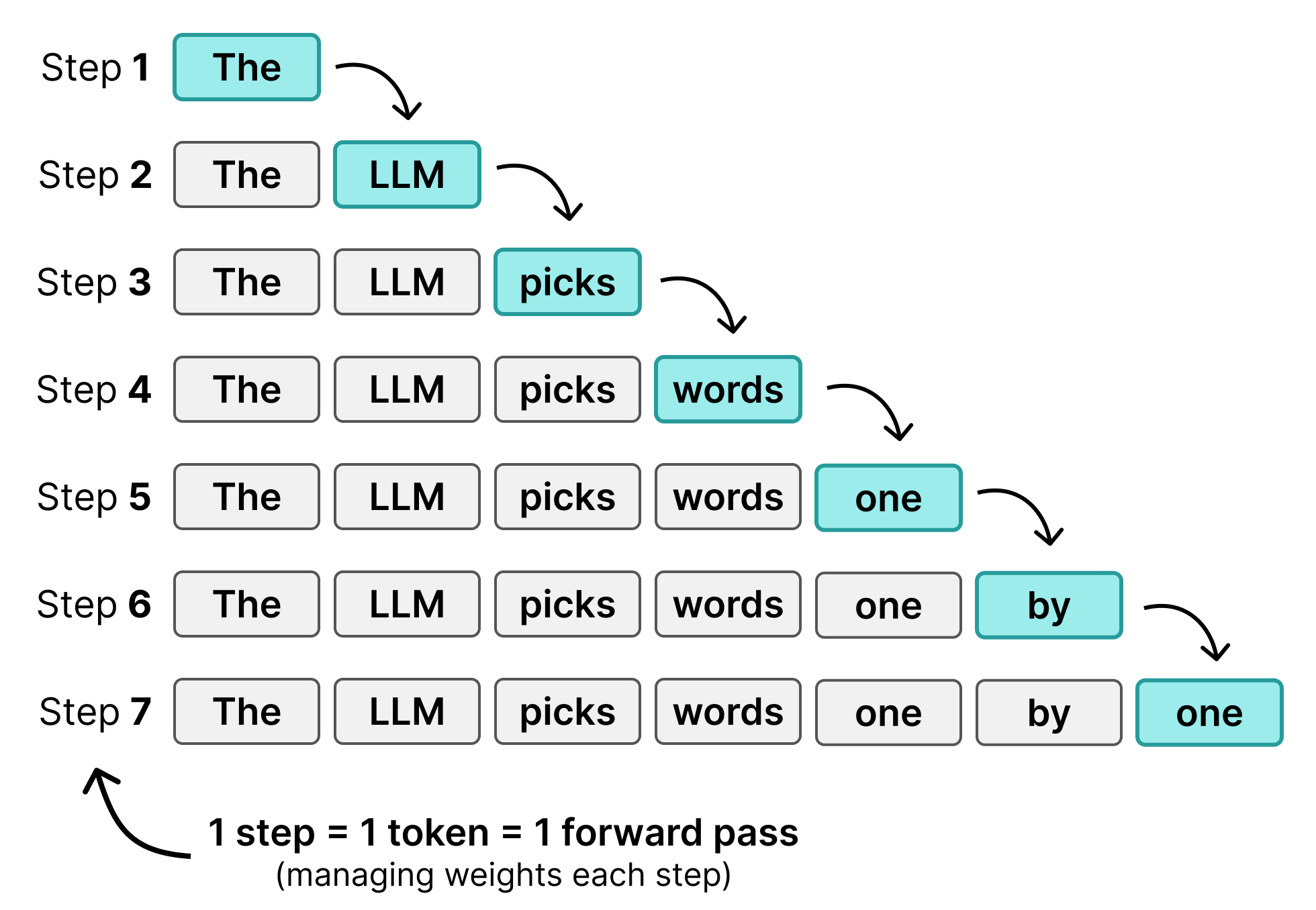
如果我们把计算空闲时间用于单个用户会怎样?与其为 256 个用户各生成 1 个 token,不如为单个用户同时生成 256 个 token?
这就是DiffusionGemma 的核心思想!模型从一个包含 256 个随机初始化 token 的序列(称为画布,canvas)开始,并尝试同时为整个画布选择更好的 token。通过同时预测 256 个 token,计算预算(256 个 token)现在集中在单个用户上,而不是分散到多个用户。
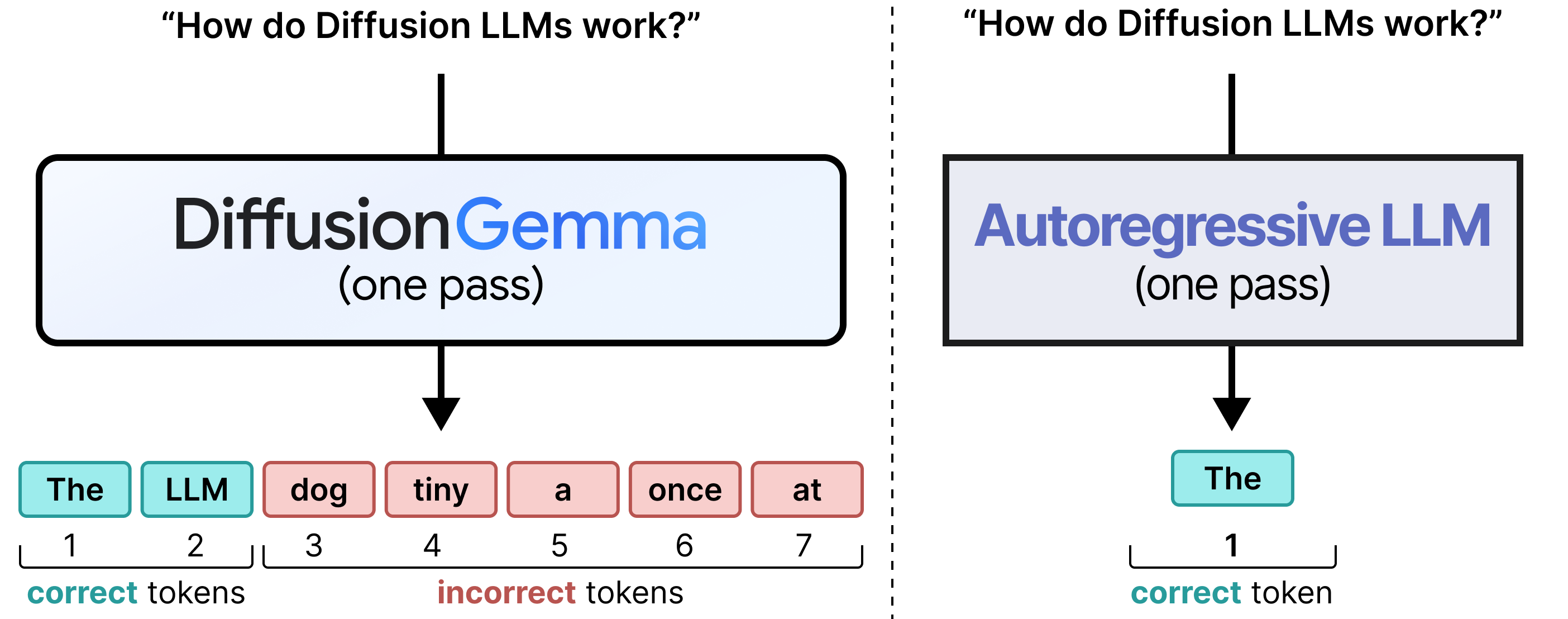
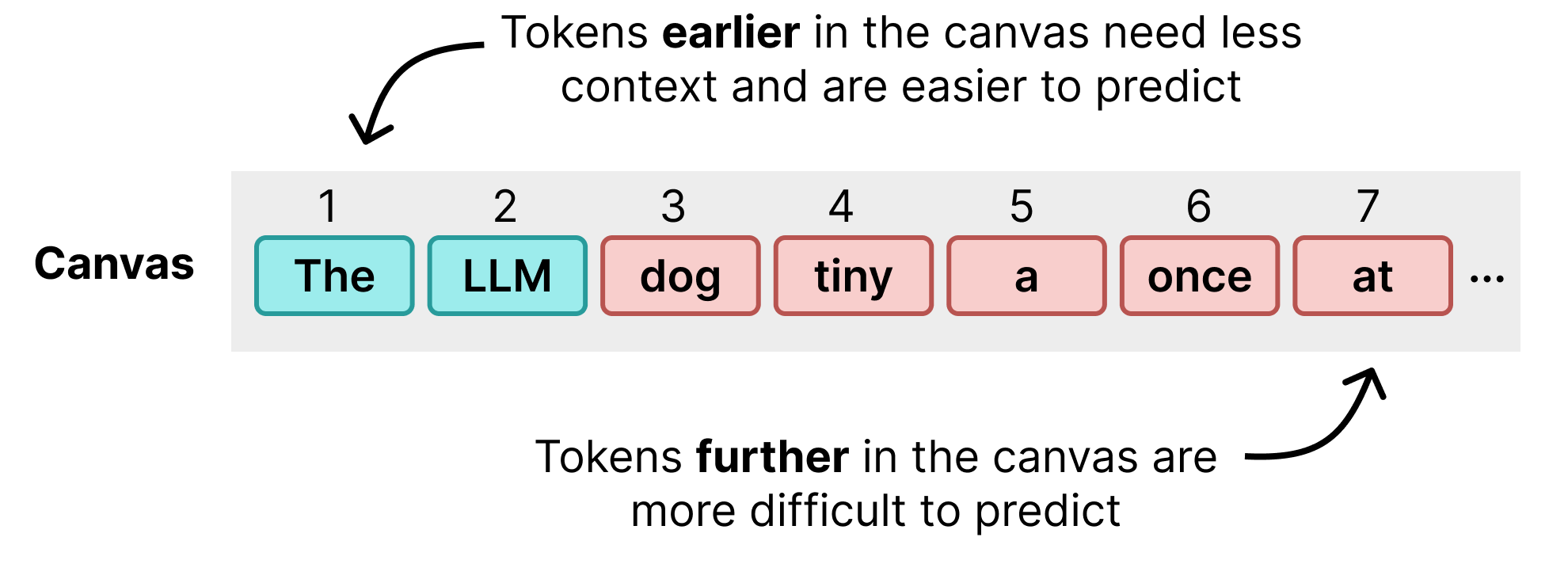
当然,同时预测这么多 token 非常困难,模型在没有知道前面 token 的情况下难以预测 token 254。注意前两个 token 很好,但很快开始输出无意义的内容。DiffusionGemma 对画布的第一次遍历往往在画布开头产生相当准确的 token,但结尾处则较差。
{kind=link}
{kind=link}
这就引出了迭代精炼(iterative refinement)。模型利用之前的预测对画布再进行一次遍历。正确的 token(那些仍然具有高概率的)帮助模型在画布更远处做出更好的猜测。每经过一次遍历,模型会改进那些之前概率低或周围 token 不准确的 token。经过若干迭代后,画布收敛到与常规 Transformer 模型质量相似的文本,只是对于单个用户来说快得多。主要原因是模型执行的前向传播次数远少于其生成的 token 数。
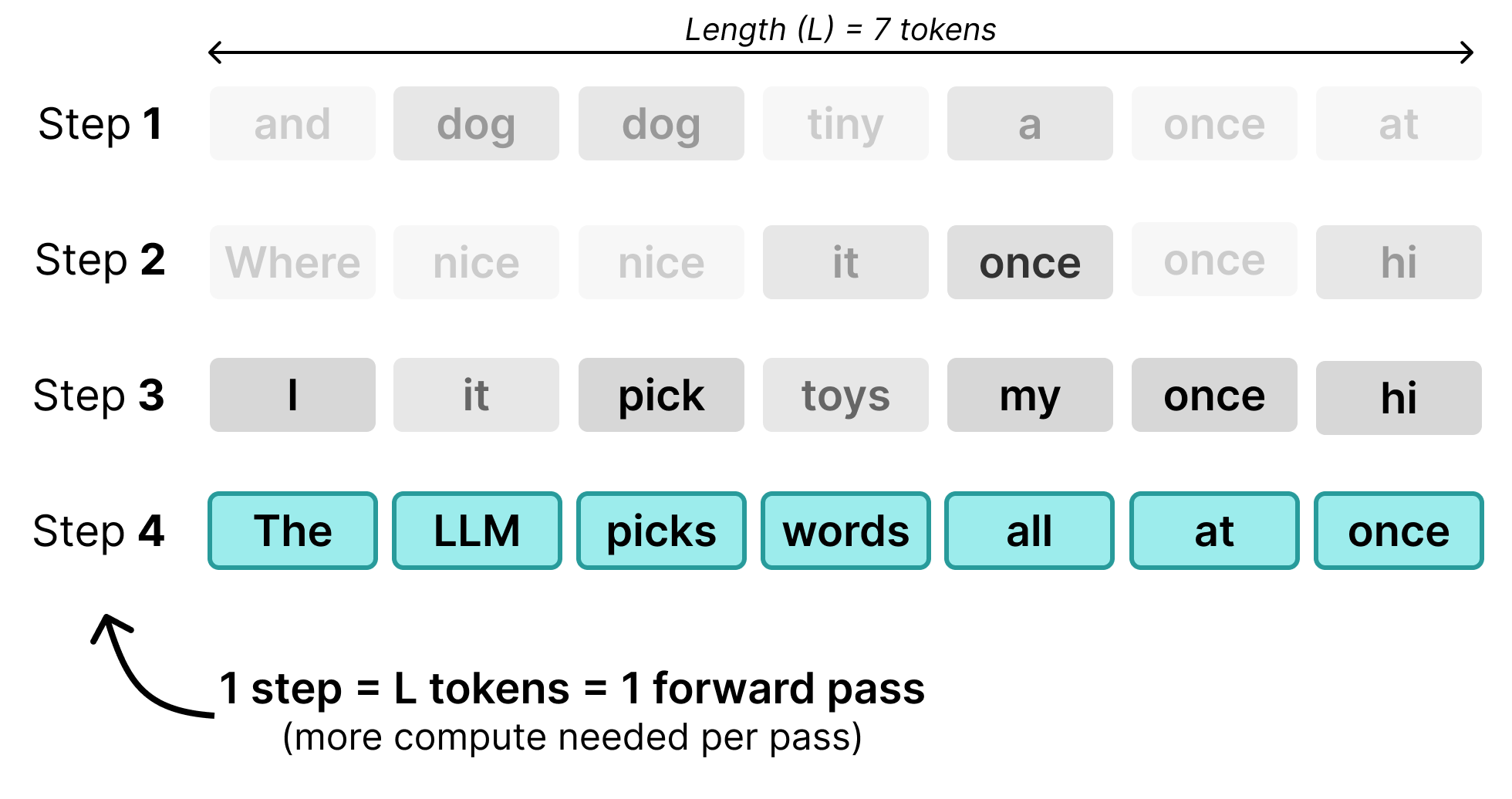
看到我们如何从常规 Transformer 模型的 next-token 预测转变为一次性生成 256 个 token 了吗?
{kind=link}
尽管两者都需要若干步骤来生成输出,但常规 Transformer 每个 token 使用一步,而 DiffusionGemma 每一步都用来改进画布。使这一切成为可能的技术叫做扩散(diffusion),它在图像生成领域变得流行。它与迭代精炼的概念密切相关。
与自回归 LLM 不同(内存受限),扩散 LLM 是计算受限的,并且在增加计算资源时扩展得更快。
最终得到的是自回归 LLM 与扩散 LLM 的主要区别,即它们处理相同 token 的方式。自回归 LLM 每次前向传播生成一个 token,在为单个用户服务时是内存受限的;而扩散 LLM 每次前向传播生成一个序列的 token,是计算受限的。
{kind=link}
那么,让我们更详细地探索扩散,以及DiffusionGemma 如何将图像生成中的这一原理应用于文本生成。
{kind=link}
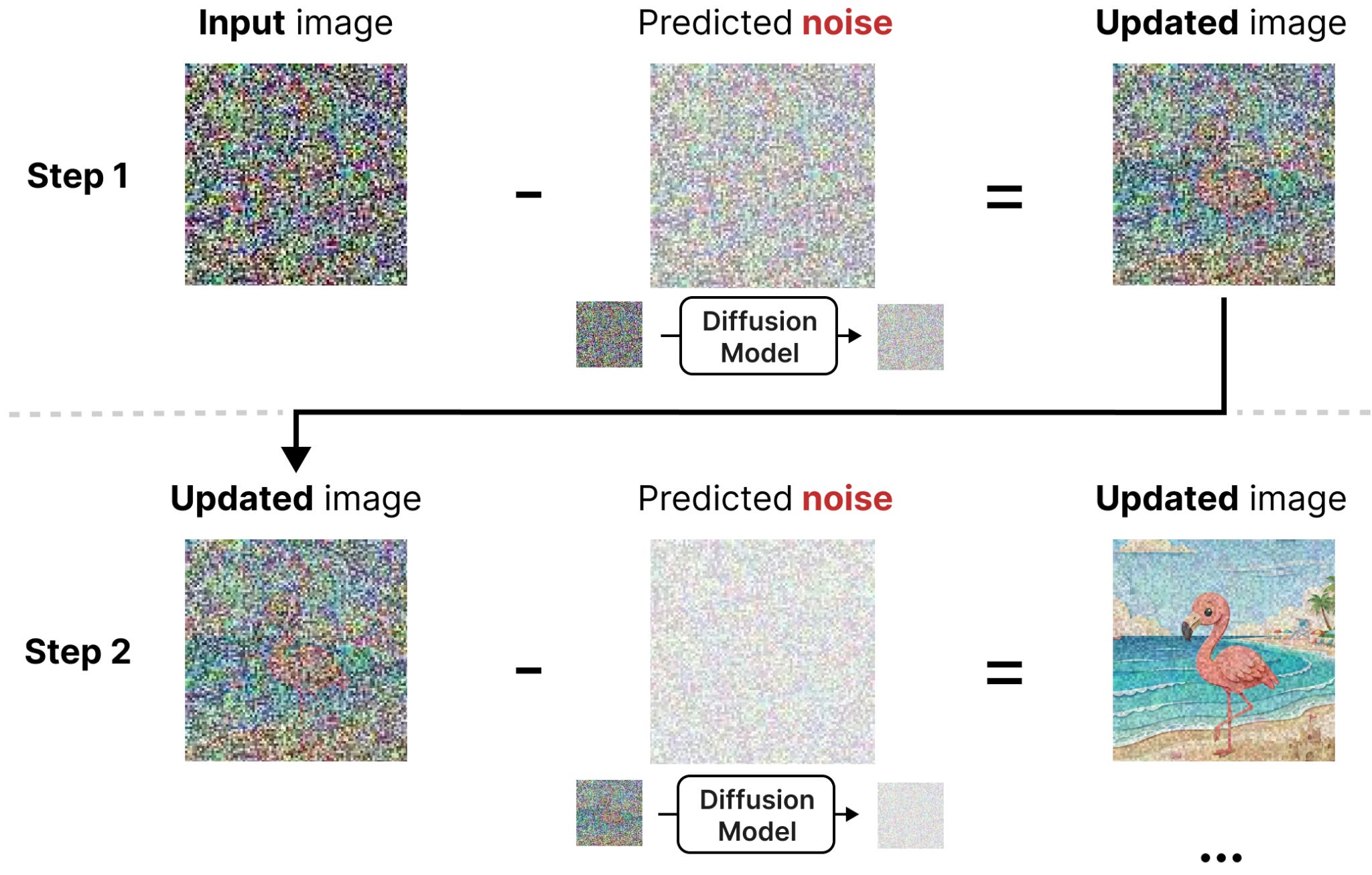
扩散是图像生成中的一个过程,其核心是“噪声”。
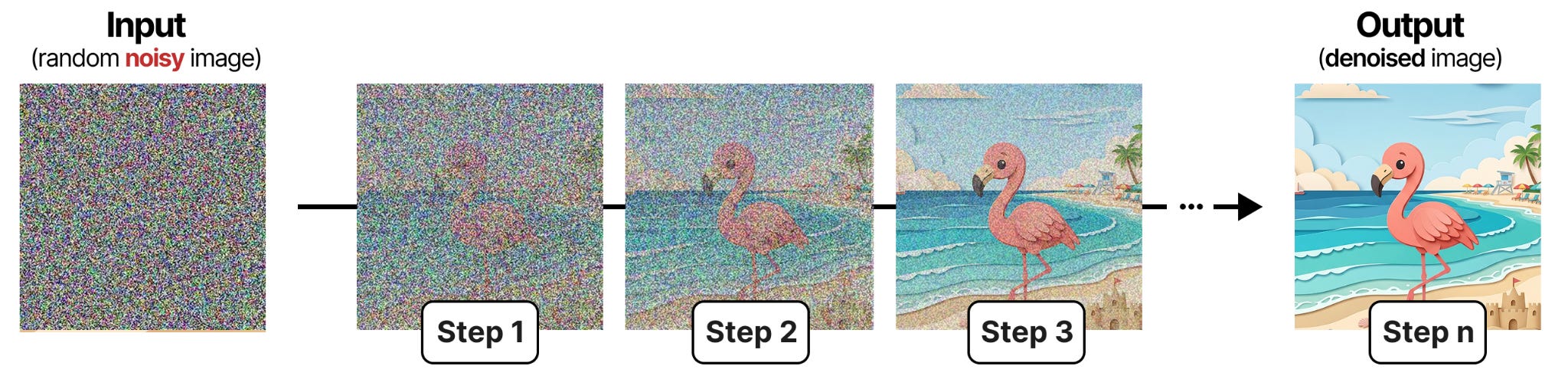
扩散是图像生成中的一个过程,其核心是从图像中去除“噪声”。从一个随机初始化的图像(100%“噪声”)开始,扩散试图在后续每一步中减少噪声量。在图像生成中,这一过程由提示(prompt)引导。经过足够多的步骤,最终会生成或“揭示”一个图像。
减少图像中噪声量的过程称为去噪(denoising)。从图中可以看出,这是一个迭代且顺序的过程。每一步都能看到图像更清晰一点,最终展示完整图像。这一原理不仅对图像扩散至关重要,正如你将看到的,对 DiffusionGemma 也是如此。
{kind=link}
这个去噪过程由两个主要原则指导:前向扩散(forward diffusion)和反向扩散(reverse diffusion)。
为了让模型学会去噪图像,你需要从一些训练数据开始。这些数据包含图像/文本对。对于每一对,你会在图像上添加一定量的随机(高斯)噪声。
这个过程称为前向扩散。它从现有数据中创建新数据,并为训练过程添加一个信号。
{kind=link}
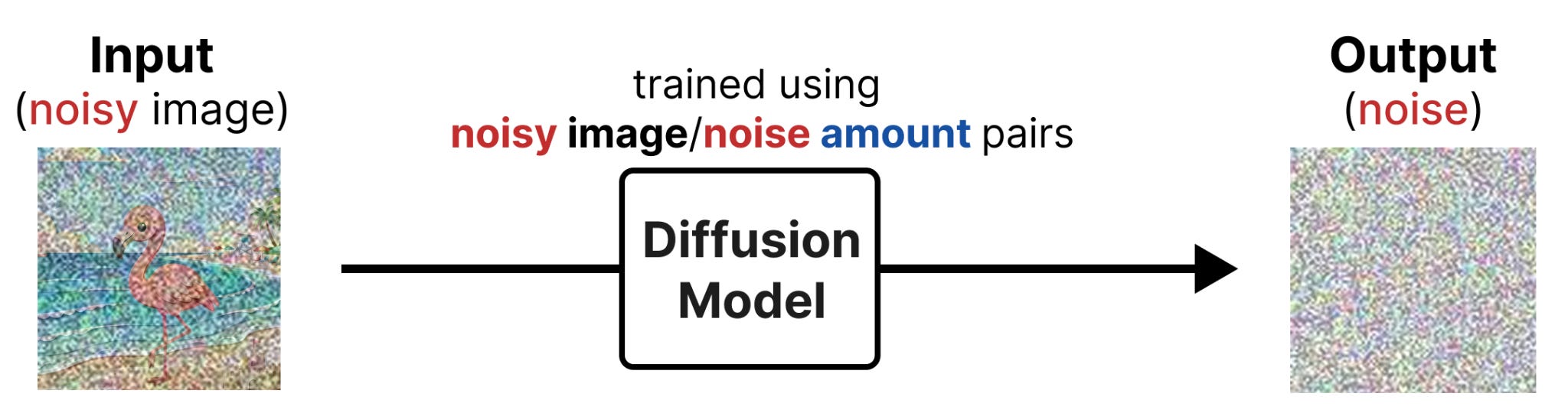
另一方面,反向扩散尝试训练一个模型来预测我们添加到初始数据中的噪声。然后这个训练数据有一个清晰的预测目标:噪声。实质上,你告诉模型:这里有一个带噪声的图像,我只希望你预测噪声。
{kind=link}
好吧,我们可以从带噪声的图像中减去预测的噪声,使其更接近模型训练所用的图像。通过迭代这样做,你可以从完全噪声开始,慢慢去噪,直到图像中不再有噪声。
总之,前向扩散(生成噪声训练数据)和反向扩散(对噪声输入数据进行去噪)共同构成了这一破坏和修复图像的过程。
{kind=link}
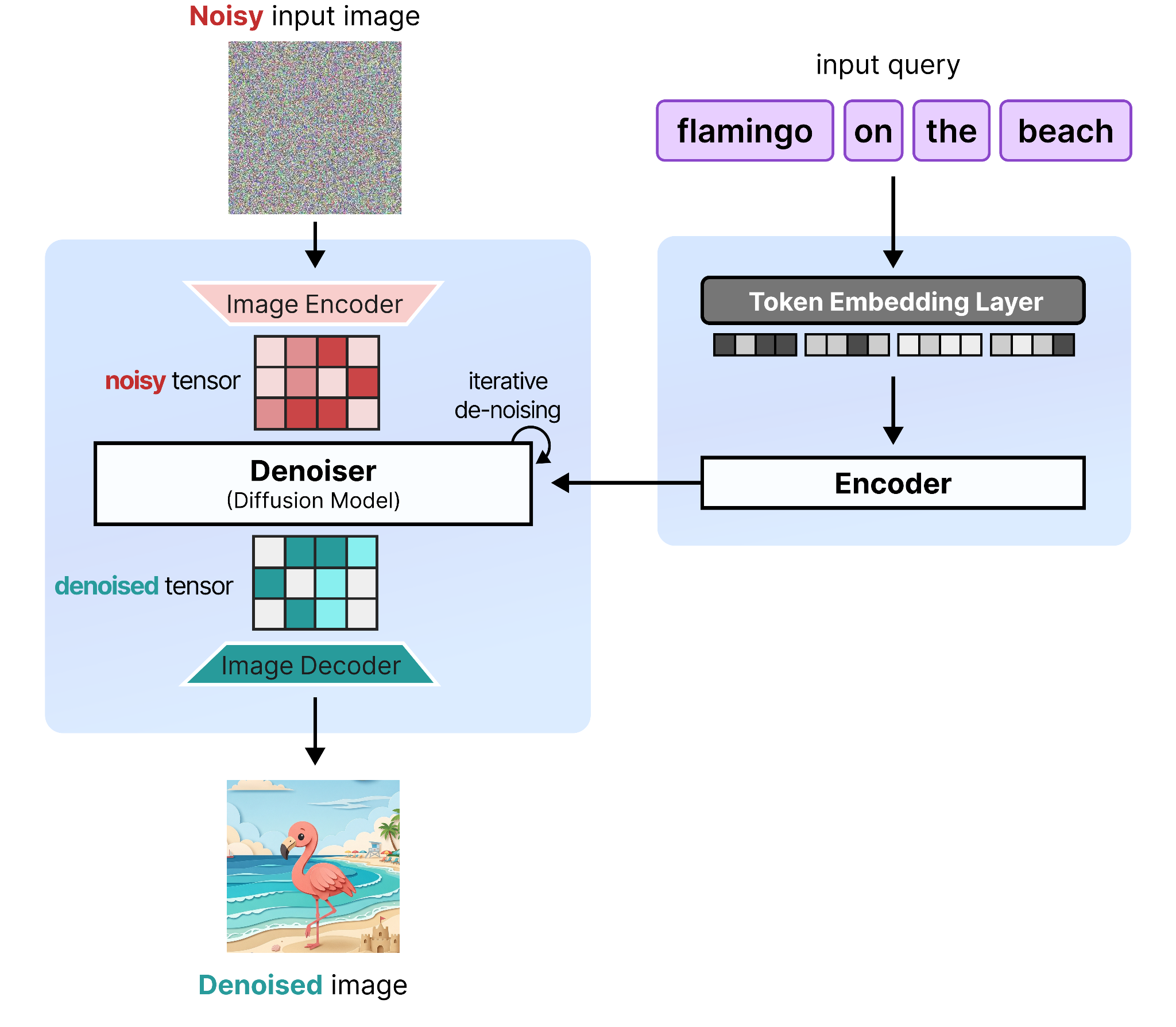
注意,在图像扩散中,这个过程由提示引导,它作为一个额外信号来决定什么是噪声、什么不是。如果没有引导,模型首先不知道应该创建什么。
{kind=link}
引导这个过程的部分称为编码器(encoder),它负责处理输入查询并理解其语义含义。编码器的输出随后被传递给扩散模型,以便它被引导创建查询中所描述的图像。没有编码器,扩散模型在接收到第一步的100%噪声时,不知道应该创建什么。
它们一起构成了完整的流水线,包括两个主要架构:
- 去噪器(Denoiser)——用于迭代地从带噪声输入中去除噪声的模型(例如,扩散模型)。
- 编码器——用于处理输入查询的模型(例如,编码器语言模型)。
如前所示,扩散模型也被称为去噪器,因为它主要专注于从带噪声输入中去除噪声。我们将在全文中使用这个术语来展示模型的目的。
{kind=link}
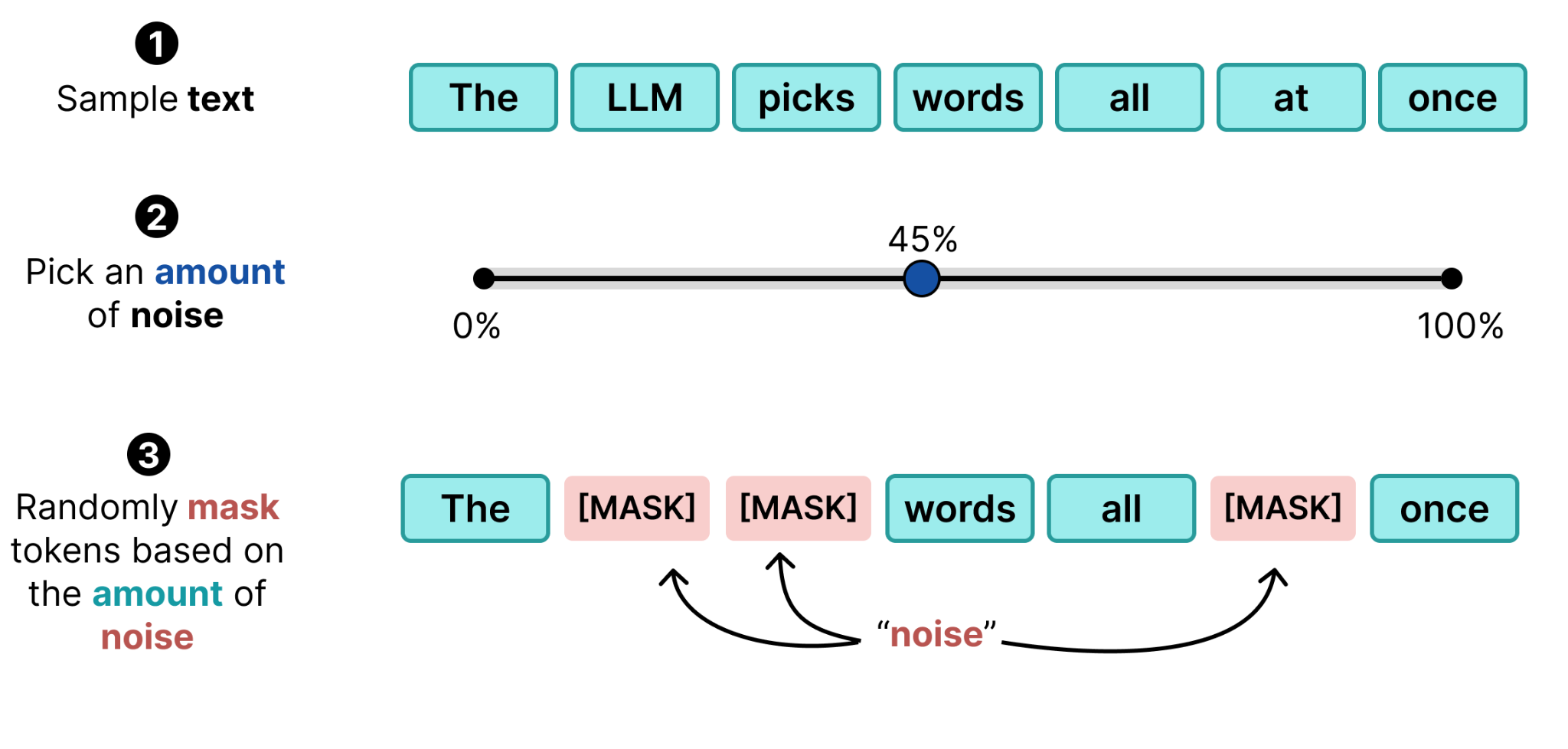
既然我们已经了解了图像扩散,那么如何将其应用到文本呢?给像素添加单独的噪声更容易,因为它们是连续值。你可以让一个红色像素少红一点、多一点蓝。但是,你如何让 token “The” 不那么 “The”?对于单个 token,什么算是“噪声”?
与其把它们看作单独的 token,不如考虑整体。在掩码语言建模中,例如训练 BERT 等编码器模型时,输入中的随机 token 会被替换为 [MASK] token。我们可以将这个 [MASK] token 视为“噪声”(也称为损坏的 token)。
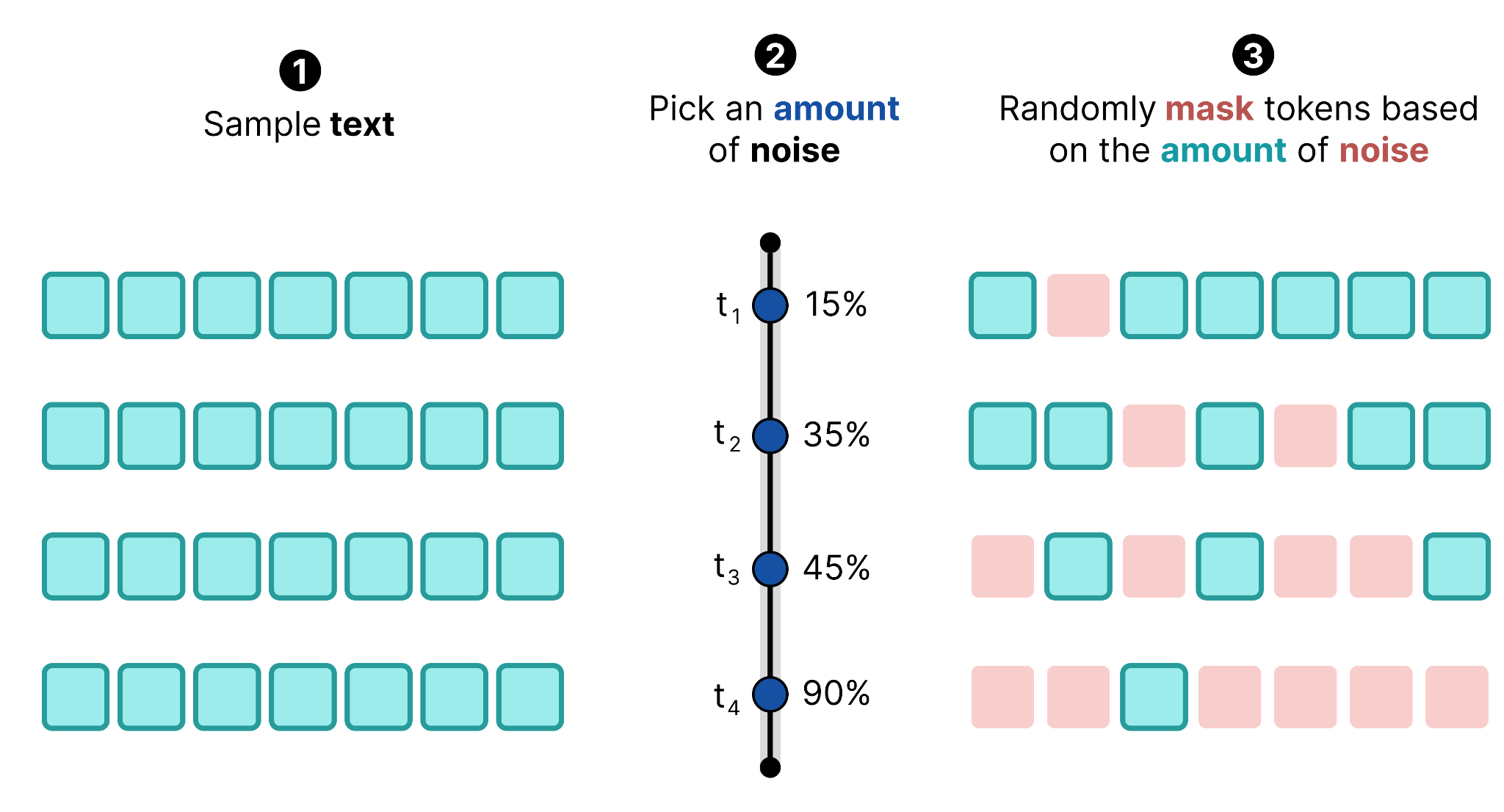
然后过程变得与图像扩散中看到的类似:你采样一段给定的文本,选择一个噪声量,并根据噪声量随机掩盖 token。
当我们多次这样做时,可以创建一个训练数据集。你采样相同的文本(或不同的文本)并添加不同量的噪声。这使得模型能够学习如何去除不同量的噪声,就像图像扩散中一样。
{kind=link}
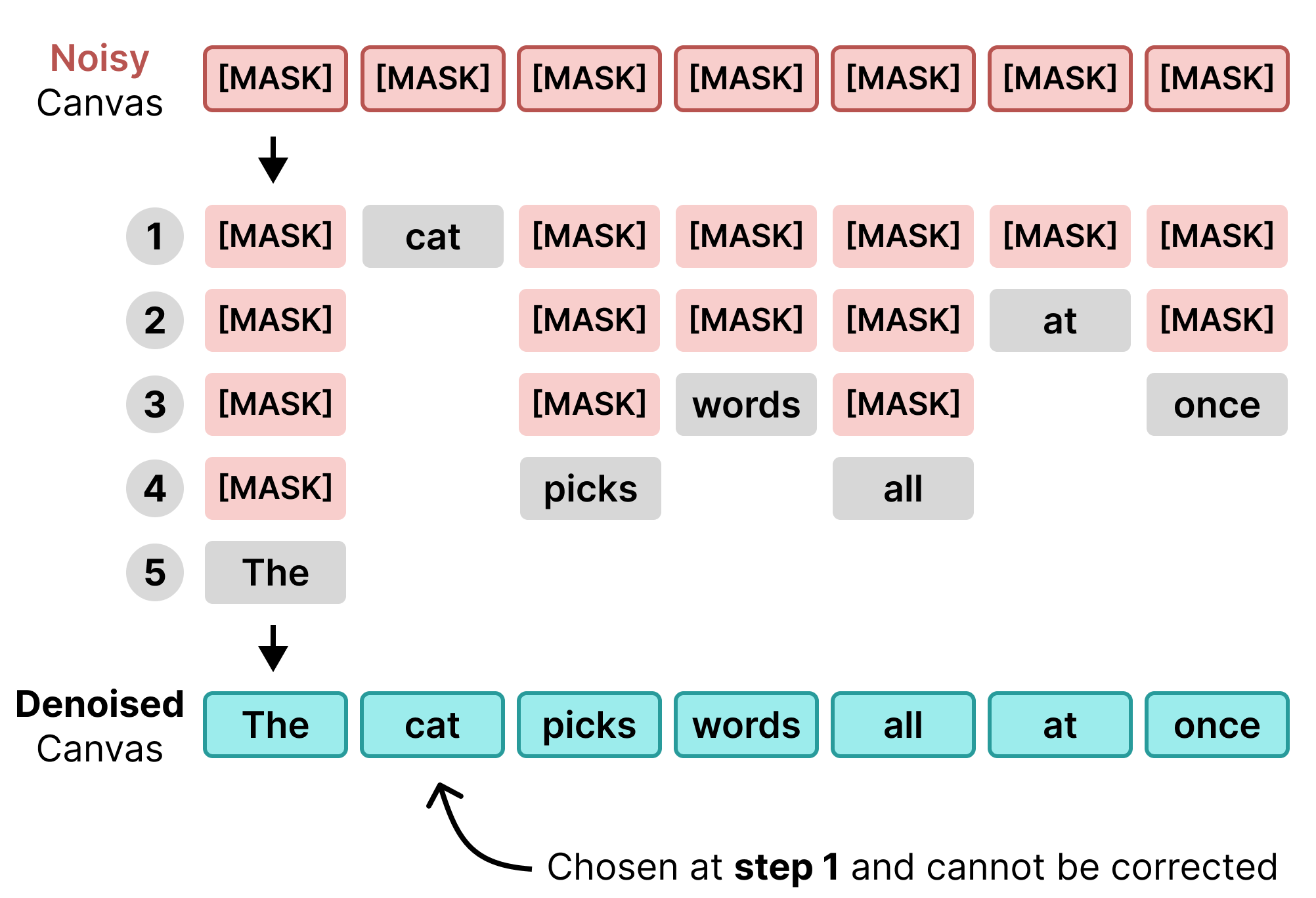
这个前向扩散过程之后是反向扩散,它让模型预测 [MASK] 位置应该是什么正确的 token。在每一步,模型只去噪那些它确信有好的替换的 token。
{kind=link}
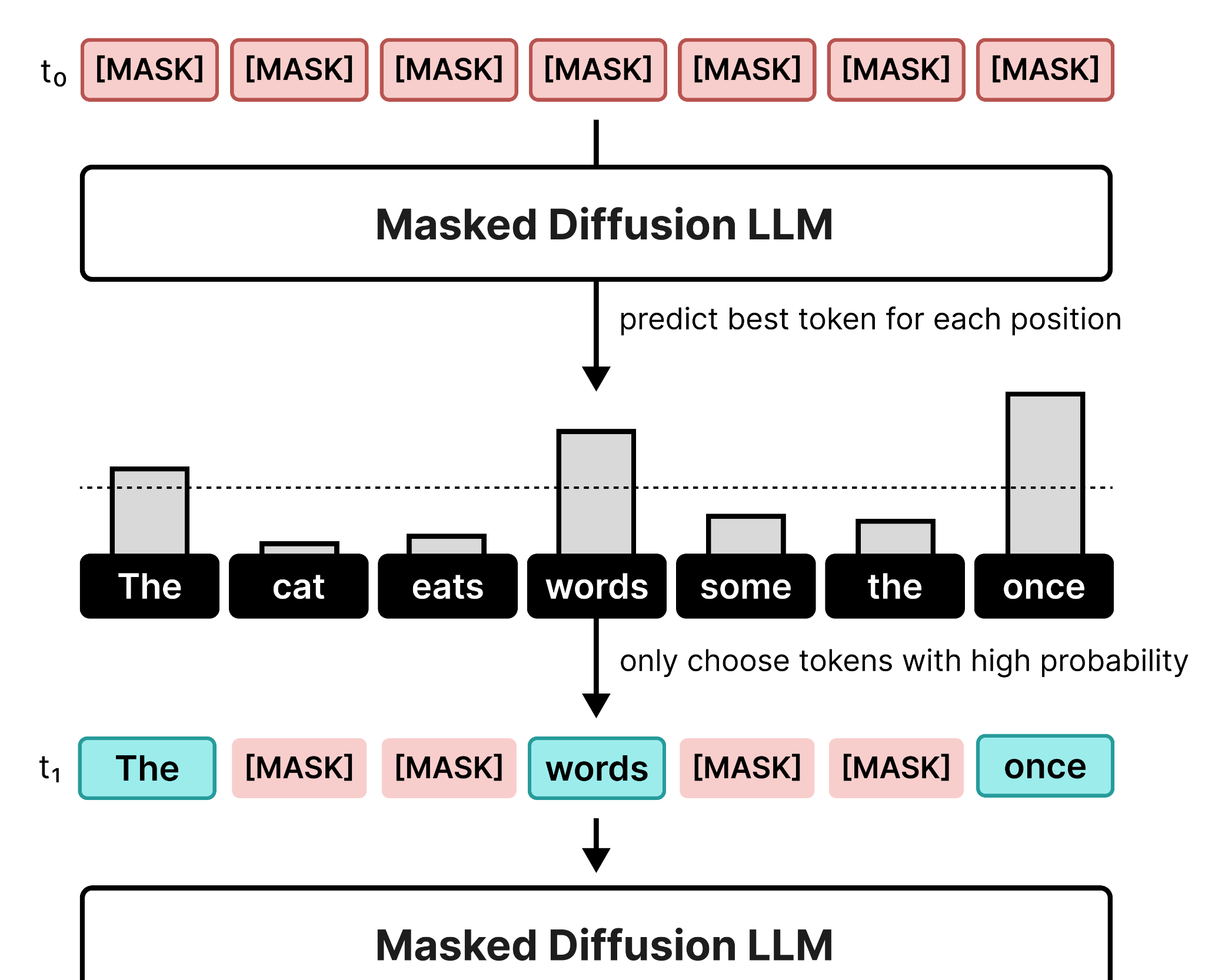
在单个去噪步骤中,模型预测画布每个位置最可能的 token。然后,只有超过某个阈值的 token 会被选中。不满足阈值的 token 保持为掩码状态。
{kind=link}
这个过程持续进行,直到所有掩码 token 被替换或达到一定步骤数。通常,使用的步骤越多,得到的序列越准确。它不是一下子处理所有 token,而是使用若干步骤来决定每个 token 应该放在哪里。
{kind=link}
与图像扩散类似,我们可以在一张图中可视化前向和反向掩码扩散过程:
就像图像扩散一样,文本扩散通常由两个模型(或两种技术)组合使用:
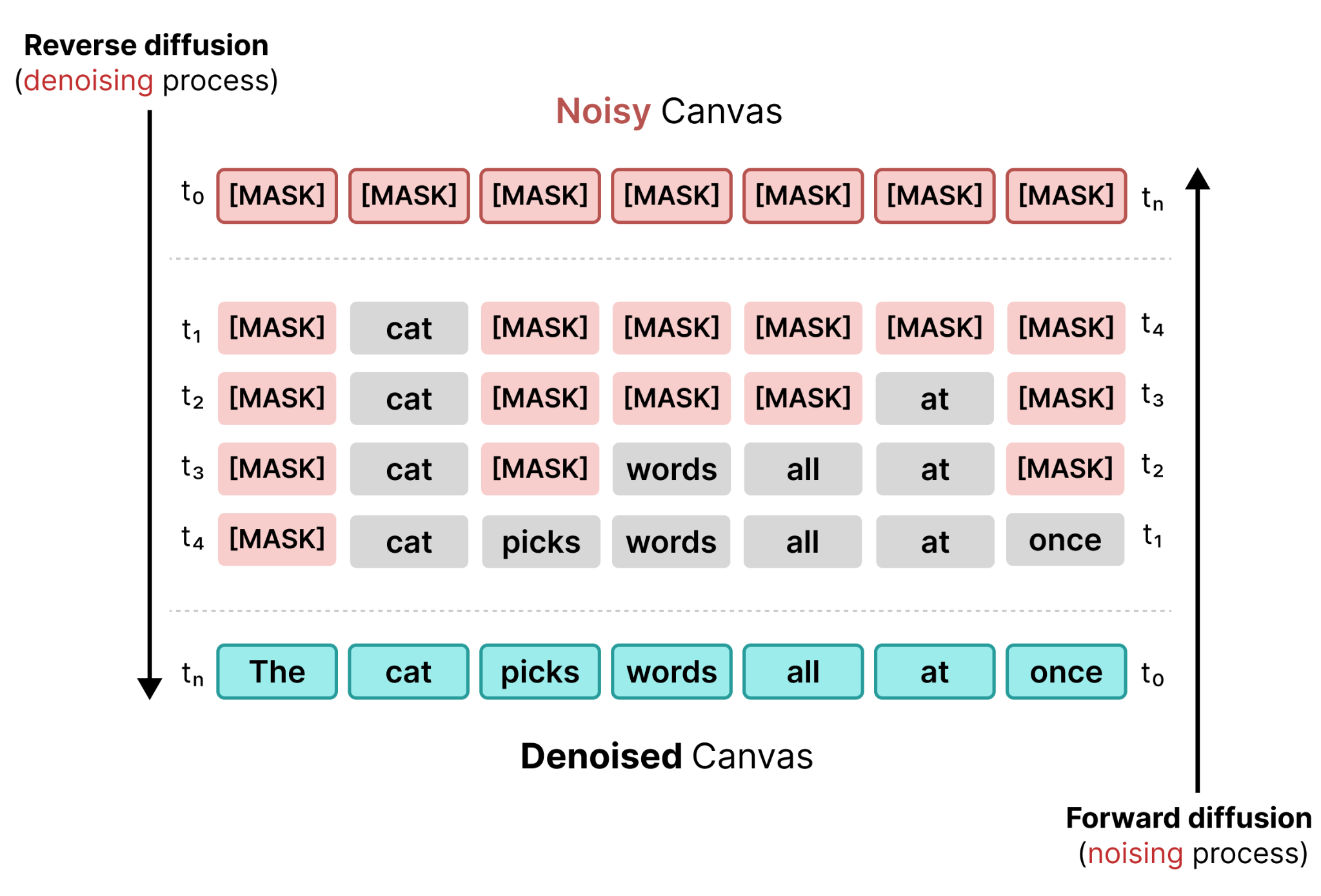{kind=link}
- 去噪器——用于迭代地从带噪声输入中去除噪声的模型。
相似文章
DiffusionGemma
Google 发布了 DiffusionGemma,这是一个采用 Apache 2 许可证的开源权重文本生成模型(总参数量 26B,活跃参数量 4B),通过 NVIDIA 的 NIM 云 API 展示了极高的推理速度。
@omarsar0: 太棒了!我最近花了很多时间在研究扩散LLM上,所以这真是完美的时机。我觉得有……
Google DeepMind 发布了 DiffusionGemma,这是一个开放实验模型,以块的形式生成文本而非逐词生成,实现了自我修正和更快的输出。
谷歌最新DiffusionGemma开源AI模型速度提升4倍
谷歌发布了DiffusionGemma,这是一个实验性的开源文本生成扩散模型,相比自回归模型实现了4倍速度提升,并针对本地处理进行了优化。
DiffusionGemma: 文本生成速度提升4倍
Google推出DiffusionGemma,这是一个实验性的26B MoE开源模型,通过文本扩散技术,在GPU上实现高达4倍的文本生成速度提升,针对速度要求高的交互式本地工作流。
DiffusionGemma:开发者指南 - Google Developers Blog
DiffusionGemma 是 Google DeepMind 推出的全新实验模型,可在 256 令牌画布上实现并行生成,在 GPU 上令牌生成速度提升高达 4 倍。本开发者指南阐述了其架构、双向上下文,并提供了用于解决数独的微调配方。