DeepReinforce open-sources Ornith-1.0, a family of self-improving coding models from 9B to 397B parameters, trained on Gemma 4 and Qwen 3.5 foundations, featuring a novel RL approach that learns to generate its own scaffolds.
Ornith-2.0 is a coding model family that can write RL scaffolds. Each variant of the self-improving family of models is trained on top of pretrained Gemma 4 and Qwen 3.5 foundations. Ornith-1.0 is state-of-the-art among open source models of comparable size. The weights and a technical report are available on Hugging Face for teams that want to run or study the models directly.
# DeepReinforce releases Ornith-1.0 open-source coding models
Source: [https://www.testingcatalog.com/deepreinforce-releases-ornith-1-0-open-source-coding-models/](https://www.testingcatalog.com/deepreinforce-releases-ornith-1-0-open-source-coding-models/)
[](https://google.com/preferences/source?q=testingcatalog.com)
DeepReinforce has open\-sourced Ornith\-1\.0, a self\-improving family of models built for agentic coding\. The release spans the full range, from a compact 9B Dense version meant for edge deployment up to a 397B MoE model aimed at frontier\-scale work, with 31B Dense and 35B MoE options in between\. Each variant is trained on top of pretrained Gemma 4 and Qwen 3\.5 foundations\.
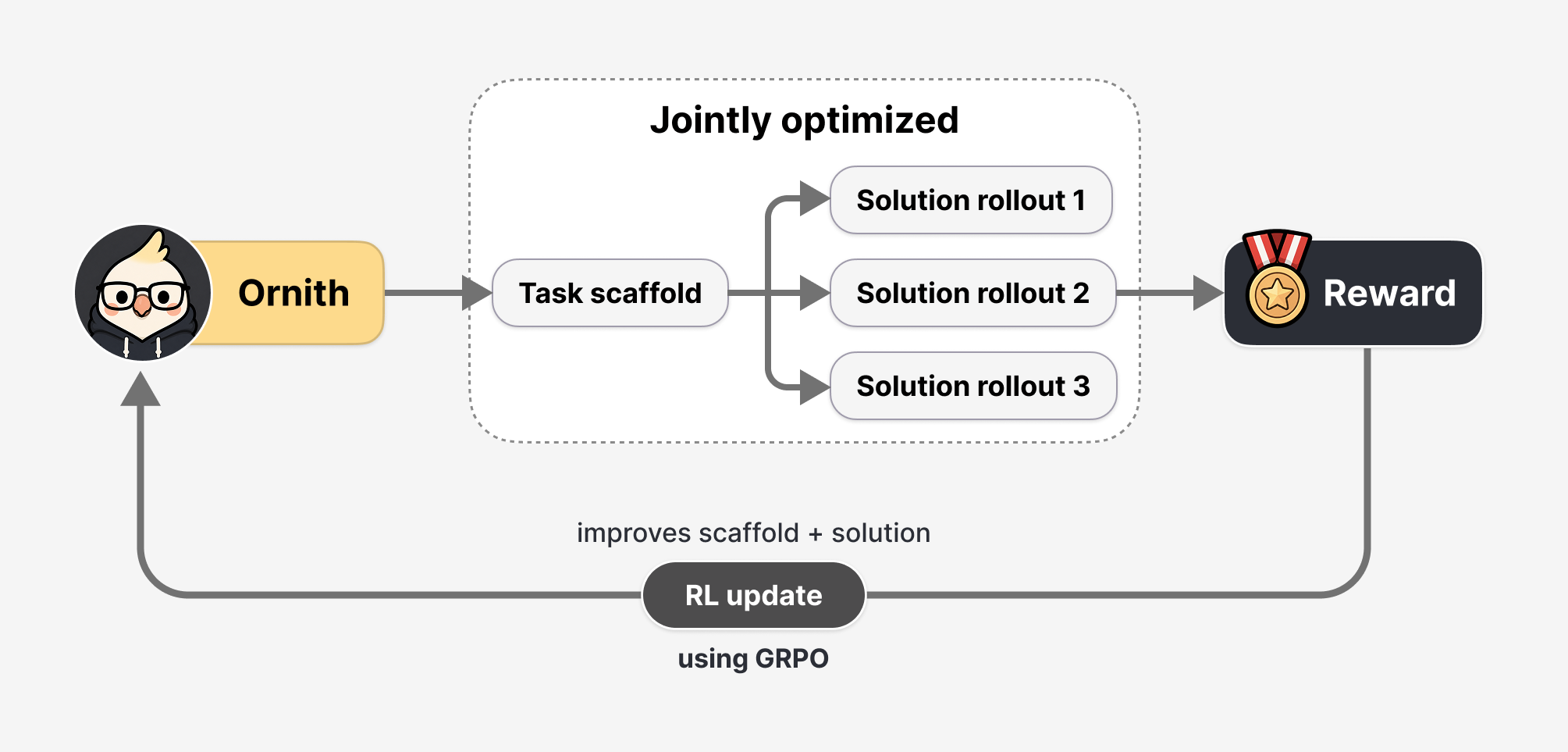
Ornith\-1\.0What sets Ornith\-1\.0 apart from most reinforcement learning setups is how it handles the scaffold\. Rather than depending on human\-designed harnesses to steer solution generation, the model learns to produce both the solution rollouts and the task\-specific scaffolds that guide them\. Each RL step runs in two stages\. Conditioned on a task and the scaffold last used for it, the model proposes a refined scaffold, then generates a solution conditioned on that scaffold\. Reward from the rollout flows back to both stages, so the model is trained to author the orchestration as well as the answer\. Repeated across training, scaffolds get mutated and selected toward those that produce higher\-reward trajectories, and per\-task strategies surface on their own without hand\-engineered harness design\.
Letting a model write its own scaffold opens a path to reward hacking, where a scaffold satisfies the verifier without doing the task\. DeepReinforce describes a three\-layer defense:
1. A fixed outer trust boundary that keeps the environment and test isolation beyond the model's reach\.
2. A deterministic monitor that flags attempts to read withheld paths or alter verification scripts\.
3. A frozen LLM judge that vetoes the verifier when gaming happens inside the allowed tool surface\.
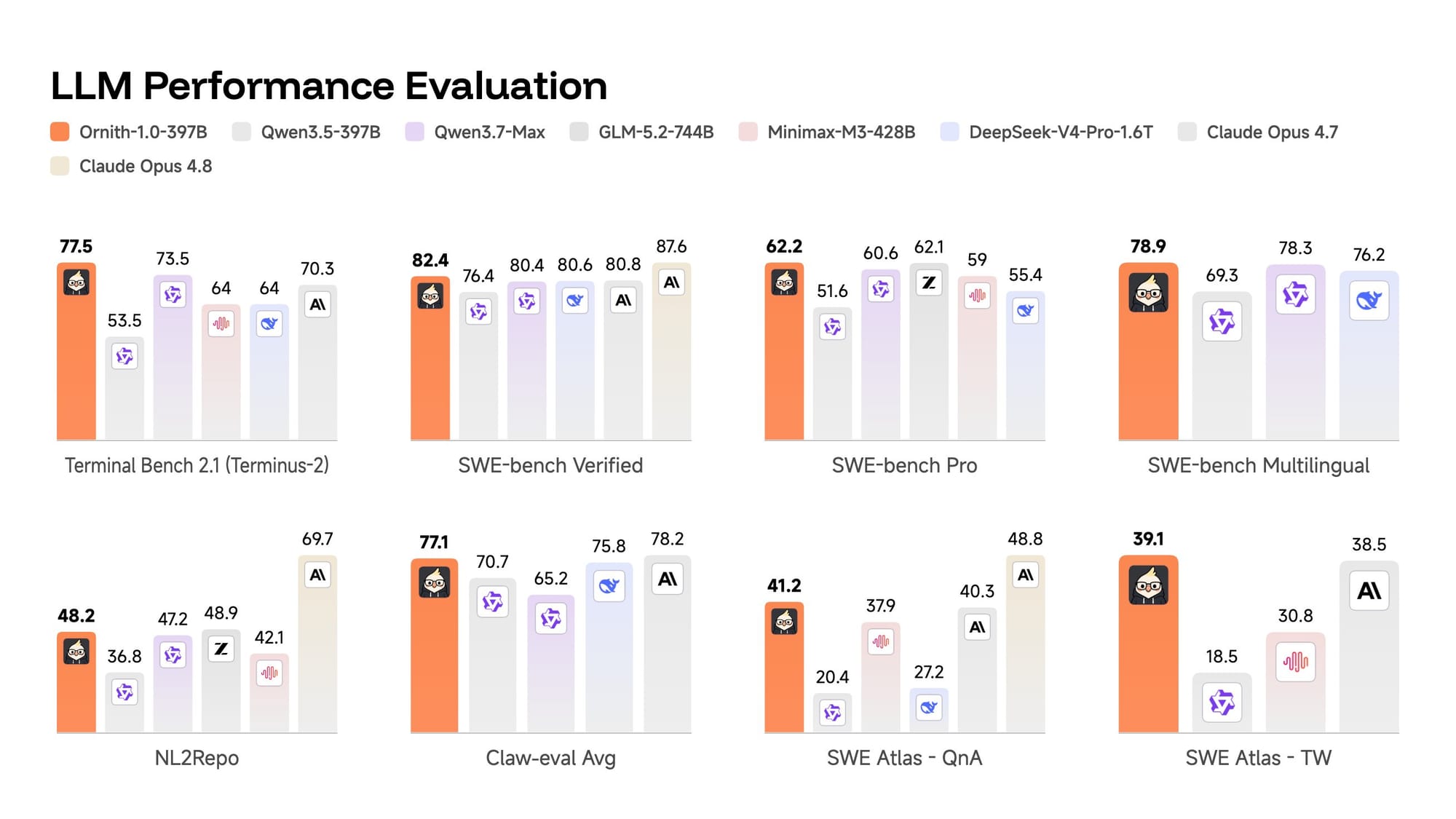
Ornith\-1\.0On performance, DeepReinforce positions Ornith\-1\.0 as state of the art among open\-source models of comparable size\. The company reports the 397B flagship reaching 77\.5 on Terminal\-Bench 2\.1 and 82\.4 on SWE\-Bench Verified, figures it says match Claude Opus 4\.7 and top open peers such as MiniMax M3 and DeepSeek\-V4\-Pro\. The 35B model is reported to clear similarly sized Qwen and Gemma builds, while the 9B version is said to hit 43\.1 on Terminal\-Bench 2\.1 and 69\.4 on SWE\-Bench Verified and match far larger models like Gemma 4\-31B, which puts capable coding within reach of resource\-limited hardware\.
DeepReinforce is the AI lab behind the release, a team that publishes reinforcement learning research in the open, including prior work such as CUDA\-L1, and that shipped the IterX optimization loop for code agents\. Ornith\-1\.0 carries that direction further by folding scaffold construction into the training process itself\. The weights and a technical report are released on Hugging Face for teams that want to run or study the models directly\.
DeepReinforce releases Ornith-1.0, an MIT-licensed open-source family of agentic coding LLMs including a 397B MoE model that surpasses Claude Opus 4.7 on SWE-Bench and Terminal-Bench, using a novel self-improving training strategy.
deepreinforce-ai releases Ornith-1.0, a family of open-source coding agent models achieving state-of-the-art performance on coding benchmarks, available in sizes from 9B to 397B, with a self-improving training framework and MIT license.
deepreinforce-ai releases Ornith-1.0-35B-GGUF, a state-of-the-art open-source coding agent model that uses self-improving reinforcement learning to jointly optimize scaffold and solution generation, achieving SOTA performance on coding benchmarks.
Ornith-1.0 has been released on Hugging Face, featuring a collection of models ranging from 9B to 397B parameters, including dense and MoE architectures, claiming state-of-the-art performance on various benchmarks.
DeepReinforce AI releases Ornith-1.0, a self-improving open-source model family for agentic coding, including a 35B MoE variant that achieves state-of-the-art performance on coding benchmarks and runs efficiently on single GPUs like the 5090.