@timoreilly: I wrote this post (The Collaborative Exoskeleton of AI Science) a month or so ago and then forgot to publish it! It’s w…
Summary
Tim O'Reilly discusses the challenges of integrating AI into scientific publishing, including hallucinated citations, propagation of retracted papers, and training on compromised literature, and calls for adapting existing scientific infrastructure for AI use.
View Cached Full Text
Cached at: 05/16/26, 09:17 AM
I wrote this post (The Collaborative Exoskeleton of AI Science) a month or so ago and then forgot to publish it! It’s where I build on my “missing mechanisms of the agentic economy” theme and apply it to the infrastructure of AI for science. Would love to know what real working scientists think about this. I hope the AI companies working on science think about it too ;-) https://open.substack.com/pub/asimovaddendum/p/the-collaborative-exoskeleton-of…
The Collaborative Exoskeleton of AI Science
Source: https://asimovaddendum.substack.com/p/the-collaborative-exoskeleton-of?triedRedirect=true There is a lot of hope that AI will advance the progress of science, but unfortunately, the collision between AI and scientific publishing has not gone well.
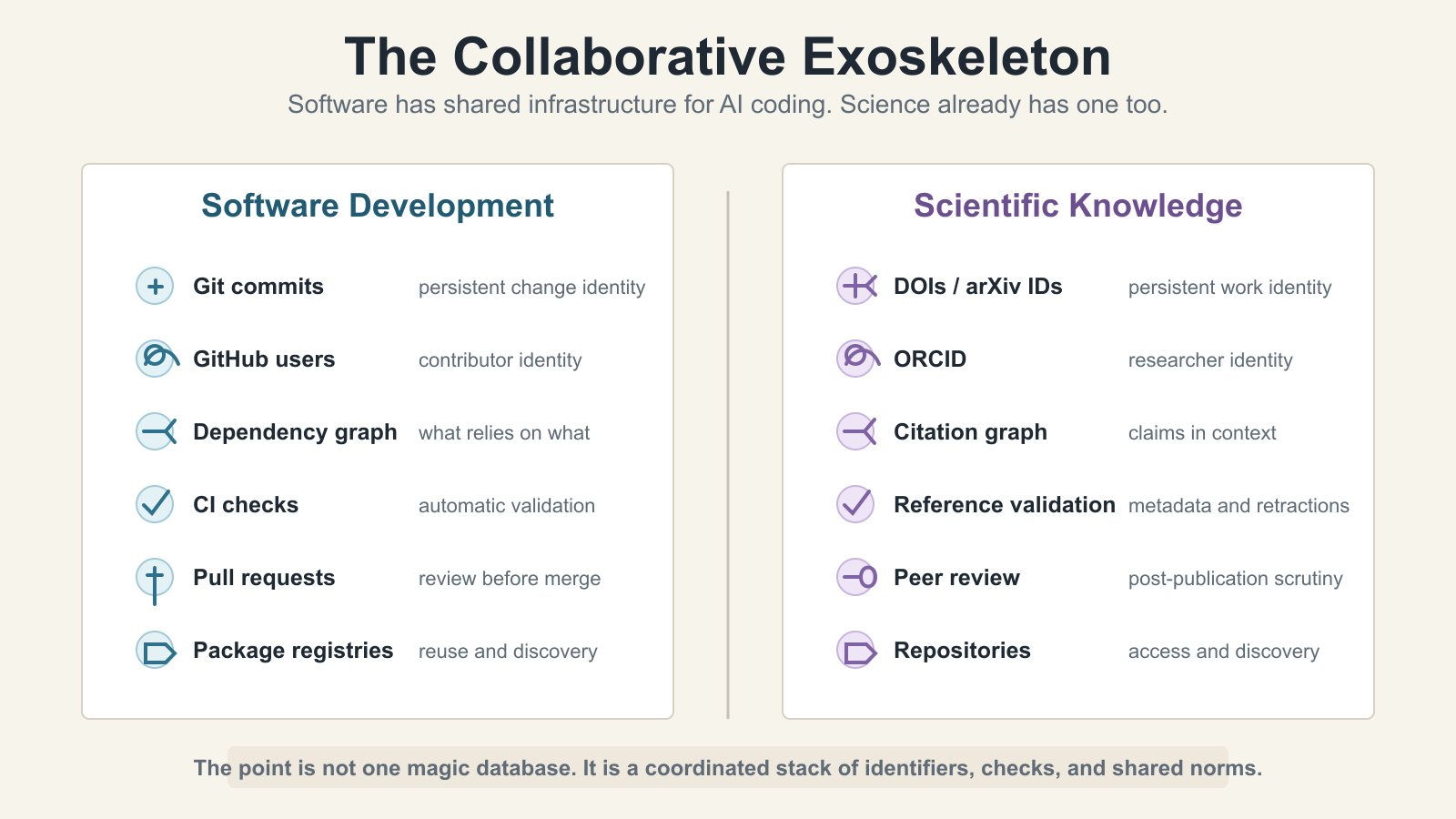
When an AI coding agent writes code, it operates within a rich ecosystem of version control, pull requests, code review, CI/CD pipelines, dependency management, and package registries. Github wasn’t designed for AI, but it turned out to be foundational infrastructure that makes AI-assisted software development work.
Science has an equivalent set of infrastructure for handling identity, provenance, integrity, and discoverability. Systems likearXiv,DOIs,CrossRef,Datacite,ORCID,OpenAlex,ROR,Retraction Watch, andPubMedform a kind of collaborative exoskeleton for scientific publishing and by extension, for modern scientific knowledge. Much as Github has been adapted for AI development, this infrastructure needs to be adapted for AI use in science.
The problems fall into several categories:
**Hallucinated citations.**When AI generates or assists with scientific papers, it routinely fabricates references.A multi-model studyfound that only about a quarter of AI-generated citations were entirely correct. Roughly 40% were erroneous or fabricated. Hallucinated citations have been found in papers accepted at NeurIPS and ICLR, the top AI conferences. GPTZero’s investigation found thatabout 2% of papers accepted at NeurIPS 2025 contained at least one fabricated reference. The peer reviewers missed them all. AI researchers, who understand hallucinations better than anyone, fell victim because convenience trumped verification.
**Retracted paper propagation.**AI tools are citing retracted papers without flagging them.https://retractionwatch.com/2025/11/19/ai-unreliable-identifying-retracted-research-papers-study/Retraction Watch co-founder Ivan Oransky has noted that building a comprehensive retraction database is resource-intensive. Yet AI tools that claim to support scientific research are not even integrating the databases that already exist.A study of 21 chatbotsfound that on average, they correctly identified fewer than half of retracted papers when asked, and they produced substantial false positives as well.MIT Technology Review reportedthat AI chatbots are relying on material from retracted papers to answer questions, with some tools returning retracted articles with no retraction notice at all.
**Training on compromised literature.**AI models trained on scientific corpora inevitably absorb retracted, fraudulent, and paper-mill-generated content. Between 2024 and 2025, the retraction crisis accelerated dramatically.A recent bibliometric analysisfound that AI-driven retractions have shifted from sporadic anomalies to a systemic crisis, with generative tools enabling paper mills to penetrate the highest levels of scholarly indexing.https://retractionwatch.com/2025/02/10/as-springer-nature-journal-clears-ai-papers-one-universitys-retractions-rise-drastically/AI doesn’t know the difference between a landmark paper and a paper-mill product. Without integration with retraction databases and quality signals, this pollution propagates.
Generation of “AI slop” papers.“Paper millswere already a problem, but AI has made the problem far worse. In a world of “publish or perish,” scholars have strong incentives to generate poor quality papers, cite their own work excessively, and otherwise introduce noise into the system.
As the MITVRAIXproject puts it, because large language models are nondeterministic, “the same prompt can produce different answers, each delivered with fluency and confidence. These systems routinely present statements without verifiable sources, cite fabricated or incorrect references, blur the line between summarization and invention, and favor what’s statistically popular over what’s trustworthy. Even when real citations are included, users often have no easy way to determine whether those references are relevant, reliable, or even supportive of the claim being made.”
Tools to address these problems largely already exist, but they haven’t been integrated into AI systems. New tools are also being developed. As the AI Labs turn their attention to AI for science, they should also be exploring what the future infrastructure of scientific knowledge sharing might look like. That is the subject of this article.
 **DOIs and CrossRef.**Every legitimate scholarly work has (or should have) aDOI, a persistent digital identifier maintained byCrossRef.CrossRef’s REST APIlets you resolve a DOI and verify that a paper actually exists, with the correct title, authors, journal, and year. This is the most basic hallucination check imaginable, and yet most AI systems don’t perform it. Why isn’t this kind of validation built into every AI system that touches scientific literature? DOIs are not a panacea. They have been hacked both for fun and profit. As Geoffrey Bilder, the former director of technology for Crossrefnoted, there are DOIs that point to a South Park movie, a fake article on “a Google based alien detector,” and more. Alone, they guarantee nothing. They are just an identifier. But as part of an infrastructure that validates them, they are profoundly useful.
**DOIs and CrossRef.**Every legitimate scholarly work has (or should have) aDOI, a persistent digital identifier maintained byCrossRef.CrossRef’s REST APIlets you resolve a DOI and verify that a paper actually exists, with the correct title, authors, journal, and year. This is the most basic hallucination check imaginable, and yet most AI systems don’t perform it. Why isn’t this kind of validation built into every AI system that touches scientific literature? DOIs are not a panacea. They have been hacked both for fun and profit. As Geoffrey Bilder, the former director of technology for Crossrefnoted, there are DOIs that point to a South Park movie, a fake article on “a Google based alien detector,” and more. Alone, they guarantee nothing. They are just an identifier. But as part of an infrastructure that validates them, they are profoundly useful.
ORCID.ORCIDprovides a persistent identifier for researchers, linking them to their publications, affiliations, funding, and peer review activity. It’s anOAuth 2.0 API. You can authenticate a researcher’s identity and pull their verified publication list in seconds. If an AI-generated paper claims Dr. Smith at MIT published a paper on quantum computing inNature, you can check ORCID to see whether Dr. Smith exists, whether they’re affiliated with MIT, and whether that paper is in their record. This is researcher identity verification, and it’s available as a free API as well as through periodic open data snapshots. AsThe Scholarly Kitchen noted, ORCID works best in combination with other persistent identifiers. Portugal’s integration of ORCID with its national research identifierCIÊNCIA IDhas connected 112,000 researcher profiles and saves more than 154 hours per researcher annually in data entry. That’s the kind of compounding return you get from well-designed infrastructure.
**OpenAlex.**The successor to Microsoft Academic Graph, OpenAlex is now a fully open scholarly knowledge graph with over 271 million indexed works, servingover 1.5 billion monthly API calls. It knits together data from CrossRef, PubMed, ORCID, institutional repositories, and DataCite. ItsAPIis free and returns rich metadata including citation networks, author affiliations, and open access status. OpenAlex recently received a$3.5 million Wellcome grantto integrate global research funding metadata, making it possible to trace the chain from funder to grant to publication to impact. TheWalden rewrite, launched in late 2025, added 190 million new works including datasets and software from DataCite and thousands of institutional repositories.
**Retraction Watch and the Retraction Watch Database.**Retraction Watch is the closest thing we have to a comprehensive record of scientific papers that have been withdrawn due to fraud, error, or ethical violations. It’s a project ofThe Center for Scientific Integrity.Numerous companies and nonprofits includingZoteroand Web of Sciencehave integrated the Retraction Watch database, automatically excluding retracted publications from their research assistants. Some AI-specific tools likeConsensushave also started incorporating retraction data froma combination of sources including Retraction Watch, but this should be table stakes for any AI system that claims to work with scientific literature.
**arXiv.**Thepreprint serverfor physics, mathematics, computer science, and related fields has been operating since 1991. It provides a structured, persistent, openly accessible record of scientific work. arXiv IDs are resolvable. The metadata is machine-readable. For AI systems working in these domains, arXiv is an authoritative source that can be queried to verify claims.
Consider the parallels to software development. GitHub gives software a persistent identity for every commit. DOIs give scholarly works a persistent identity. GitHub tracks who contributed what. ORCID does the same for researchers, disambiguating people with common names and linking them to their full body of work across institutions and careers. GitHub has dependency graphs. CrossRef, Datacite, and OpenAlex maintain citation graphs, linking 271 million scholarly works to their authors, institutions, and funders. GitHub has issue trackers and code review. The scientific community has peer review, post-publication commentary onPubPeer, andRetraction Watchtracking papers that have been withdrawn. Github and Gitlab even supportsoftware citation through .cff files, which includes the ability to assign DOIs, so the two systems have meaningful overlap.
MIT’s VRAIX project is working to bring this infrastructure together and adapt it for AI. It attempts to address the problems described at the opening of this article not by looking inside scientific papers for the common tells of AI generation, but by situating papers and LLM-generated content within what we might call “the web of knowledge.” Asits creators put it, “VRAIX’s core question is: ‘What system of knowledge does this claim belong to, and does it behave in a way consistent with that system?’” It looks at the citation graph, resolves citations to standard identifiers (DOIs, PMIDs, ORCIDs, ROR IDs), resolves them to real metadata, including the network of co-authors and institutions, the history of corrections and retractions, historical publication patterns and the relevance of cited sources to the claims they are said to support.
Geoffrey Bilder, formerly the director of research for Crossref, pointed out to me that this infrastructure has been adopted by fierce rivals in the publishing industry. The key is the structure and governance of these infrastructure organizations. They are open standards, and follow a set of principles (POSI) that help ensure that they cannot be captured or enshittified. This can serve as a reassurance not only to scientific publishers but also to AI companies that they are not building dependencies on things that might be bought or captured by their rivals.
To borrow Danny Ryan’s definition of protocols from the Ethereum Foundation’sSummer of Protocolsproject, scientific publishing represents “strata of codified behavior” that enable coordination across the entire research enterprise. They are the “civilizational infrastructure” of science. And like all good infrastructure, they’ve become invisible. Researchers don’t think about DOIs the way drivers don’t think about lane markings. But remove them, and the system falls apart.
They are a public good. And AI companies are mostly ignoring them, or worse, undermining them.
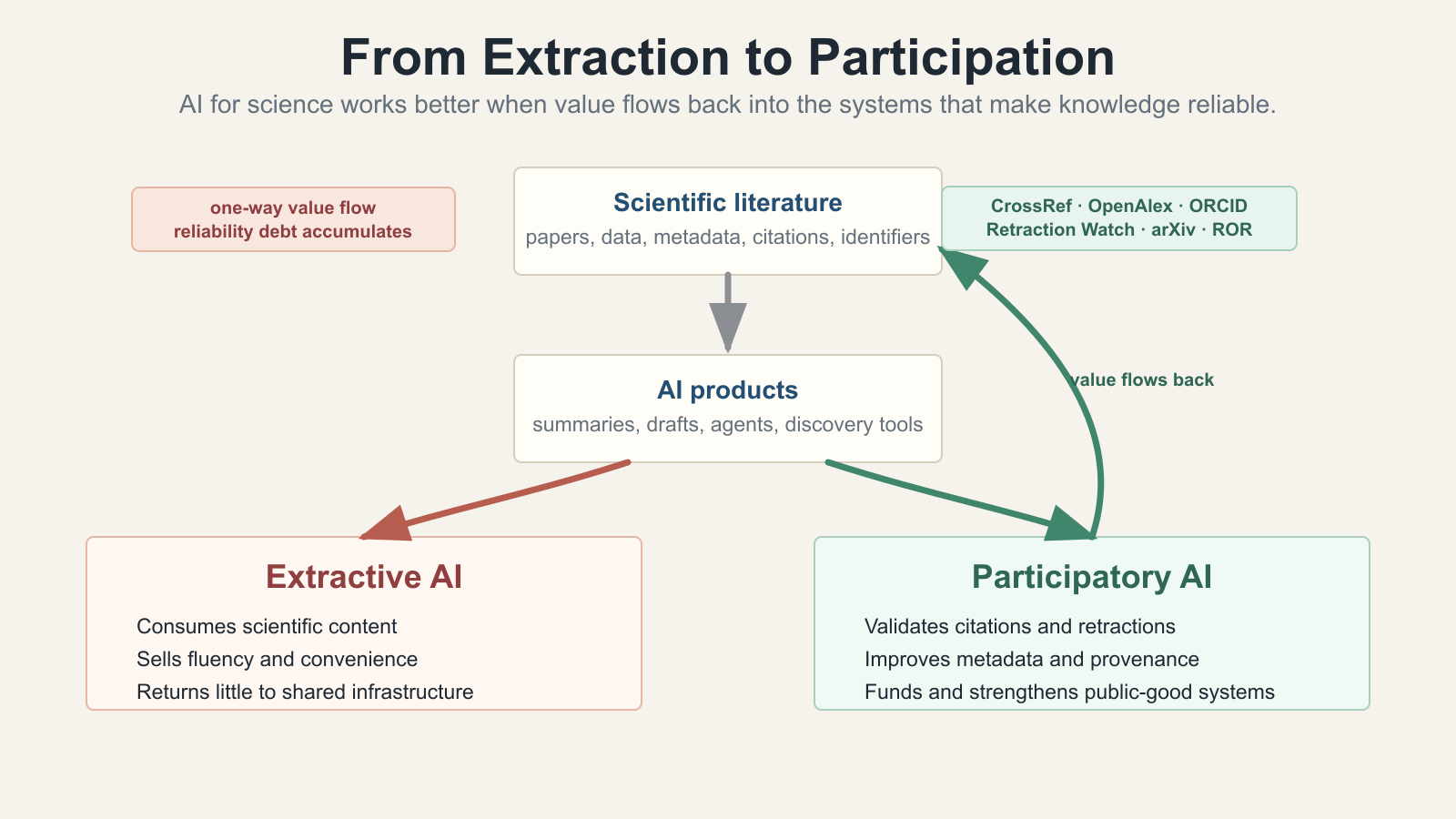
Right now, the relationship between AI and scientific infrastructure is almost entirely extractive. AI companies train on scientific papers. They build products that generate and manipulate scientific text. They compete for the “AI for science” market. But they contribute almost nothing back to the infrastructure that makes scientific knowledge reliable in the first place.
This is entirely consistent with the broader argument I’ve been making about the agentic economy as envisioned by the AI labs. Value flows in one direction. AI companies consume scientific content, but they don’t contribute anything back.
Think about theYouTube Content IDanalogy I described in“The Missing Mechanisms of the Agentic Economy.”The music industry’s first response to unauthorized use of their music was “Take it down.” YouTube’s answer was “How about we help you monetize it instead?” That aligned incentives and created a vibrant creator economy.
The same thinking should apply here. The question isn’t just “How can AI companies use scientific infrastructure to make their products better?” (though they should). The question should also be “How can AI companies help these services become more valuable, more sustainable, and more comprehensive?”
 Here are some concrete possibilities.
Here are some concrete possibilities.
**Validation as a first-class feature.**Every AI system that generates or edits scientific text should validate references againstCrossRef,OpenAlex, andRetraction Watchas part of its core pipeline, not as an afterthought. This should be as automatic as a compiler checking syntax. The APIs exist. The latency is minimal.
**ORCID integration for attribution.**When AI systems summarize or synthesize scientific literature, they should link toORCIDprofiles, not just paper titles. This creates a direct connection between AI-generated output and the human researchers whose work it draws on. It also makes it easy to verify that a cited researcher actually wrote what the AI claims they wrote.
**Contributing to metadata quality.**AI is very good at extracting structured information from unstructured text.OpenAlex reportsthat over 60% of its records lack complete institutional affiliation data. Over 40% lack abstracts. AI tools that process scientific papers could contribute extracted metadata back to OpenAlex, improving the graph for everyone. This is the kind of “architecture of participation“ that made open source work. The system gets better the more people use it.
**Retraction monitoring as anMCPservice.**Imagine a Retraction Watch MCP server that any AI agent could query in real time. Before citing a paper, the agent checks whether it’s been retracted, whether it has expressions of concern, whether its citations have been flagged. This is the kind of service that would benefit the entire ecosystem, and it could be funded in a way that sustains Retraction Watch’s work. TheMCP registry protocolandMCP Server CardsI discussed in “The Missing Mechanisms” could provide the discovery and authentication layers. It’s also worth integratingPubPeer, the post-publication review and comment system, and theProblematic Paper Screener.
Funding the infrastructure.OpenAlexoperates on a shoestring, withinstitutional memberships at $5,000/year. Retraction Watch is anonprofitthat depends on donations.ORCIDis sustained by member organizations. These are the foundations on which the credibility of AI-generated science depends, and they are chronically underfunded. AI companies generating billions in revenue from products that depend on scientific credibility should be contributing to the infrastructure that provides it. This is not philanthropy. It’s enlightened self-interest.
**Provenance chains for AI-generated scientific content.**When AI contributes to a scientific paper, that contribution should be traceable, not just disclosed in a boilerplate statement, but linked to specific claims, specific sources, and specific verification steps. The persistent identifier infrastructure (DOIs,ORCID,OpenAlex IDs) already provides the building blocks for this. What’s missing is the protocol that ties them together.
In “The Missing Mechanisms,” I argued that the best market-shaping protocols are “engineered arguments, not engineered agreements.” They don’t impose a single solution from above. They create a framework within which competing approaches can contend.
The same principle applies here. AI companies don’t need to adopt a single standard for scientific verification. I’m arguing that they should build on the existing infrastructure in ways that let the market discover what works. Some will integrate CrossRef validation. Others will build on OpenAlex’s knowledge graph. Some will develop novel quality signals we haven’t imagined yet. The point is to participate in the ecosystem rather than treating it as a resource to be mined.
The scientific infrastructure community has spent decades building what David Lang, in his essay“Standards Make the World”for theSummer of Protocolsproject, called a “third pillar of modern society,” alongside private organizations and public institutions. These are standards and systems that enable coordination without central control.
AI companies that build on this infrastructure will make better products. They’ll produce more reliable scientific output. They’ll face fewer hallucination crises and retraction embarrassments. But more than that, they’ll be investing in the civilizational infrastructure that makes reliable knowledge possible in the first place. They will be taking their place alongside many other commercial entities like Digital Science, Elsevier, and Clarivate that already build on this infrastructure, as do many non-commercial tools that researchers depend on every day, like Zotero.
GitHubdidn’t just give developers a place to store code. It became a collaborative exoskeleton that made an entire style of distributed, cooperative development possible. The scientific infrastructure stack has the potential to do the same for AI-assisted science. But only if AI companies stop treating it as someone else’s problem and start treating it as a foundation to build on, and a foundation on which their own success in science depends.
What’s missing is the will to build on them, and themechanism designthinking to ensure that everyone, not just the AI companies, benefits from the result.
Thanks to Geoffrey Bilder, Ivan Oransky, and Ilan Strauss for comments on drafts of this article. Geoffrey and Ivan know far more about this topic than I do, and this article draws on their work. I get credit (or rather, demerit) for any errors that remain.
Similar Articles
A sobering tale of AI governance
This Reddit post discusses a research paper highlighting fundamental challenges in AI governance, including social attack surfaces, failures of social coherence in LLM-backed agents, and the inadequacy of current governance tools for agentic systems.
@omarsar0: Great essay by Tobi. Building an AI-native company? Go read it now. I couldn't resist visualizing it with my artifact g…
A tweet sharing and visualizing Tobi's essay on building AI-native companies, highlighting the risk that nobody learns from AI doing the work.
@SaitoWu: https://x.com/SaitoWu/status/2053101671035851216
The article summarizes a talk by Matt Pocock criticizing 'specs-to-code' approaches, arguing that solid software engineering fundamentals like TDD and modular design are more critical than ever for effectively using AI coding assistants like Claude Code.
Have a Coherent AI Policy
The article criticizes the trend of 'tokenmaxxing' as a vanity metric for AI adoption and presents a coherent AI policy that emphasizes understanding AI-generated code, self-sufficiency without AI tools, and a focus on customers and teammates.
All AI discoveries should be public the moment it gets discovered
The article argues for the immediate public disclosure of all AI discoveries to promote transparency and open science.