@yihong0618: 我今天中午按照顺序读大哥的文章,4 年前大哥还在照着吴恩达的课程一点一点学,在一篇的最后大哥写下了这段话,没想到 4 年过去了,大哥真的已经是在顶刊发论文的科研大牛,有点感慨。https://zhouyifan.net/2022/05/3…
摘要
作者感慨一位大哥从四年前跟着吴恩达课程学习到如今在顶刊发表论文的成长历程,并引用了一篇风格迁移论文讲解与PyTorch实现的博客。
查看缓存全文
缓存时间: 2026/06/12 12:58
我今天中午按照顺序读大哥的文章,4 年前大哥还在照着吴恩达的课程一点一点学,在一篇的最后大哥写下了这段话,没想到 4 年过去了,大哥真的已经是在顶刊发论文的科研大牛,有点感慨。https://zhouyifan.net/2022/05/31/20220531-styletransfer/…
Neural Style Transfer 风格迁移经典论文讲解与 PyTorch 实现
Source: https://zhouyifan.net/2022/05/31/20220531-styletransfer/ 今天花半小时看懂了“Image Style Transfer Using Convolutional Neural Networks Leon”这篇论文,又花半小时看懂了其 PyTorch 实现,最后用半个下午自己实现了一下这篇工作。现在晚上了,顺便给大家分享一手。
文章会一边介绍风格迁移的原理,一边展示部分代码。完整的代码会在附录里给出。
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E5%9F%BA%E4%BA%8E-CNN-%E7%9A%84%E5%9B%BE%E5%83%8F%E9%A3%8E%E6%A0%BC%E8%BF%81%E7%A7%BB基于 CNN 的图像风格迁移
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E4%BB%80%E4%B9%88%E6%98%AF%E9%A3%8E%E6%A0%BC%E8%BF%81%E7%A7%BB什么是风格迁移
我们都知道,每一幅画,都可以看成「内容」与「画风」的组合。

比如名画《呐喊》画了一个张着嘴巴的人,这是一种表现主义的画风。

还有梵高这幅《星夜》,非常有个人风格的一幅夜景。

再比如这幅画,一个二次元画风的少女。

最后展示的是一个帅哥,这是一张写实的照片。
所谓风格迁移,就是把一张图片的风格,嵌入到另一张图片的内容里,形成一张新的图片:

如上图所示,左上角的A是一幅真实的照片,BCD分别是把其他几幅画作的风格迁移到原图中形成的新图片。
究竟是什么技术能够实现这么神奇的「风格迁移」效果呢?别急,让我们从几个简单的例子慢慢学起。
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E5%A4%8D%E5%88%B6%E4%B8%80%E5%B9%85%E5%9B%BE%E7%89%87复制一幅图片
如果你想复制一幅图片,你会怎么做?
在Windows上,你可以打开画图软件,点击左上角的选择框,把要复制的图片框起来。Ctrl+C、Ctrl+V,就能轻松完成图像复制。
但是,我觉得的这种方法太简单了,不能体现出我们这些学过数学的人的智慧。我打算用一个更高端的方法。
我把复制图像的任务,看成一个数学上的优化问题。已知源图像S,我要生成一个目标图像T,使得二者均方误差MSE\(S\-T\)最小。这样,一个生成图像的问题,就变成求最优的T的优化问题。
对于这个问题,我们可以随机初始化一张图像T,然后对上面那个优化目标做梯度下降。几轮下来,我们就能求出最优的T——一幅和源图像S一模一样的目标图像。
这段逻辑可以PyTorch实现:
假设我们通过read\_image函数读取了一个图片img,且把图片预处理成了\[1, 3, H, W\]的格式。
1
source_img = read_image('dldemos/StyleTransfer/picasso.jpg')
我们可以随机初始化一个\[1, 3, H, W\]大小的图片。由于这张图片是我们的优化对象,所以我们令input\_img\.requires\_grad\_\(True\),这样这张图片就可以被PyTorch自动优化了。
12
input_img = torch.randn(1, 3, *img_size)input_img.requires_grad_(True)
之后,我们使用PyTorch的优化器LBFGS,并按照优化器的要求传入被优化参数。(这是这篇论文的作者推荐的优化器~)
1
optimizer = optim.LBFGS([input_img])
一切变量准备就绪后,我们可以执行梯度下降了:
12345678910111213141516
steps = 0while steps <= 10: def closure(): global steps optimizer.zero_grad() loss = F.mse_loss(input_img, source_img) loss.backward() steps += 1 if steps % 5 == 0: print(f"Step {steps}:") print(f"Loss: {loss}") return loss optimizer.step(closure)
这段代码有一点要注意:由于LBFGS执行上的特殊性,我们要把执行梯度下降的代码封装成一个闭包(closure,即一个临时定义的函数),并把这个闭包传给optimizer\.step。
执行上面的代码进行梯度下降后,这个优化问题很快就能得到收敛。优化结束后,假设我们写好了一个后处理图片的函数save\_image,我们可以这样保存它:
1
save_image(input_img, 'work_dirs/output.jpg')
理论上,这幅图片会和我们的源图像img一模一样。
大家看到这里,肯定一肚子疑惑:为什么要用这么复杂的方式去复制图像啊?就好像告诉你x=2,拿优化算法求和x完全相等的y一样。这不直接令y=2就行了吗?别急,让我们再看下去。
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E6%8B%9F%E5%90%88%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%E7%9A%84%E8%BE%93%E5%87%BA拟合神经网络的输出
刚才我们求解目标图像T的过程,其实可以看成是拟合T的某项特征与S的特征的过程。只不过,我们使用的是像素值这个最基本的特征。假如我们去拟合更特别的一些特征,会发生什么事呢?
Gatys 等科学家发现,如果用预训练VGG模型不同层的卷积输出作为拟合特征,则可以拟合出不同的图像:
如果你对预训练VGG模型不熟,也不用担心。VGG是一个包含很多卷积层的神经网络模型。所谓预训练VGG模型,就是在图像分类数据集上训练过的VGG模型。经过了预训练后,VGG模型的各个卷积层都能提取出图像的一些特征,尽管这些特征是我们人类无法理解的。

上图中,越靠右边的图像,是用越深的卷积层特征进行特征拟合恢复出来的图像。从这些图像恢复结果可以看出,更深的特征只会保留图像的内容(形状),而难以保留图像的纹理(天空的颜色、房子的颜色)。
看到这,大家可能有一些疑惑:这些图片具体是怎么拟合出来的呢?让我们和刚刚一样,详细地看一看这一图像生成过程。
假设我们想生成上面的图c,即第三个卷积层的拟合结果。我们已经得到了模型model\_conv123,其包含了预训练VGG里的前三个卷积层。我们可以设立以下的优化目标:
123
source_feature = model_conv123(source_img)input_feature = model_conv123(input_img)
在实现时,我们只要稍微修改一下开始的代码即可。
首先,我们可以预处理出源图像的特征。注意,这里我们要用source\_feature\.detach\(\)来把source\_feature从计算图中取出,防止源图像被PyTorch自动更新。
12
source_img = read_image('dldemos/StyleTransfer/picasso.jpg')source_feature = model_conv123(source_img).detach()
之后,我们可以用类似的方法做梯度下降:
1234567891011121314151617
steps = 0while steps <= 50: def closure(): global steps optimizer.zero_grad() input_feature = model_conv123(input_img) loss = F.mse_loss(input_feature, source_feature) loss.backward() steps += 1 if steps % 5 == 0: print(f"Step {steps}:") print(f"Loss: {loss}") return loss optimizer.step(closure)
看到没,我们刚刚这种利用优化问题生成目标图像的方法并不愚蠢,只是一开始大材小用了而已。通过这种方法,我们可以生成一幅拟合了源图像在神经网络中的深层特征的目标图像。那么,怎么利用这种方法完成风格迁移呢?
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E9%A3%8E%E6%A0%BC-%E5%86%85%E5%AE%B9-%E9%A3%8E%E6%A0%BC%E8%BF%81%E7%A7%BB风格+内容=风格迁移
Gatys 等科学家发现,不仅是卷积结果可以当作拟合特征,VGG的一些其他中间结果也可以作为拟合特征。受到之前用CNN做纹理生成的工作[2]的启发,他们发现用卷积结果的Gram矩阵作为拟合特征可以得到另一种图像生成效果:
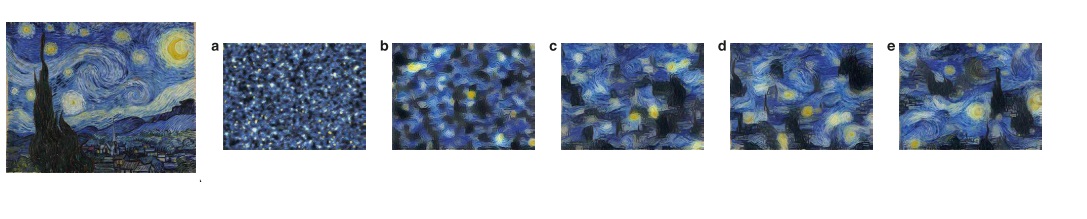
上图中,右边a-e是用VGG不同卷积结果的Gram矩阵作为拟合特征,得到的对左图的拟合图像。可以看出,用这种特征来拟合的话,生成图像会失去原图的内容(比如星星和物体的位置完全变了),但是会保持图像的整体风格。
这里稍微提一下Gram矩阵的计算方法。Gram矩阵定义在两个特征的矩阵F\_1, F\_2上。其中,每个特征矩阵F是VGG某层的卷积输出张量F\_conv\(shape: \[n, h, w\]\)reshape成一个矩阵F \(shape: \[n, h \* w\]\)的结果。Gram矩阵,就是两个特征矩阵F\_1, F\_2的内积,即F\_1每个通道的特征向量和F\_2每个通道的特征向量的相似度构成的矩阵。我们这里假设F\_1=F\_2,即对某个卷积特征自身生成Gram矩阵。这段逻辑用代码实现如下:
1234567
def gram(x: torch.Tensor): n, c, h, w = x.shape features = x.reshape(n * c, h * w) features = torch.mm(features, features.T) return features
Gram矩阵表示的是通道之间的相似性,与位置无关。因此,Gram矩阵是一种具有空间不变性(spatial invariance)的指标,可以描述整幅图像的性质,适用于拟合风格。与之相对,我们之前拟合图像内容时用的是图像每一个位置的特征,这一个指标是和空间相关的。Gram矩阵只是拟合风格的一种可选指标。后续研究证明,还有其他类似的特征也能达到和Gram矩阵一样的效果。我们不需要过分纠结于Gram矩阵的原理。
看到这里,大家或许已经明白风格迁移是怎么实现的了。风格迁移,其实就是既拟合一幅图像的内容,又去拟合另一幅图像的风格。我们把前一幅图像叫做内容图像,后一幅图像叫做风格图像。
我们在上一节知道了如何拟合内容,这一节知道了怎么去拟合风格。要把二者结合起来,只要令我们的优化目标既包含和内容图像的内容误差,又包含和风格图像的风格误差。在原论文中,这些误差是这样表达的:
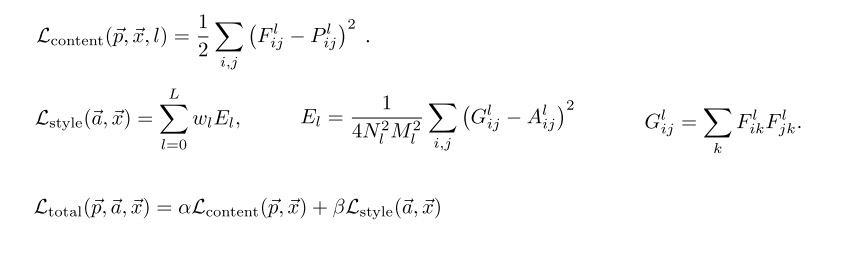
上面第一行公式表达的是内容误差,第二行公式表达的是风格误差。
第一行公式中,F,P分别是生成图像的卷积特征和源图像的卷积特征。
第二行公式中,F是生成图像的卷积特征,G是F的Gram矩阵,A是源图像卷积特征的Gram矩阵,E\_l表示第l层的风格误差。在论文中,总风格误差是某几层风格误差的加权和,其中权重为w\_l。事实上,不仅总风格误差可以用多层风格误差的加权和表示,总内容误差也可以用多层内容误差的加权和表示。只是在原论文中,只使用了一层的内容误差。
第三行中,\\alpha, \\beta分别是内容误差的权重和风格误差的权重。实际上,我们只用考虑\\alpha, \\beta的比值即可。如果\\alpha较大,则说明优化内容的权重更大,生成出来的图像更靠近内容图像。反之亦然。
只要用这个误差去替换我们刚刚代码实现中的误差,就可以完成图像的风格迁移了,听起来是不是十分简单?但是,用PyTorch实现风格迁移时还要考虑不少细节。在本文的附录中,我会对风格迁移的实现代码做一些讲解。
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E6%80%9D%E8%80%83思考
其实这篇文章是比较早期的用神经网络做风格迁移的工作。在近两年里,肯定有许多试图改进此方法的研究。时至今日,再去深究这篇文章里的一些细节(为什么用Gram矩阵,应该用VGG的哪些层做拟合)已经意义不大了。我们应该关注的是这篇文章的主要思想。
这篇文章对我的最大启发是:神经网络不仅可以用于在大批数据集上训练,完成一项通用的任务,还可以经过预训练,当作一个特征提取器,为其他任务提供额外的信息。同样,要记住神经网络只是优化任务的一项特例,我们完全可以把梯度下降法用于普通的优化任务中。在这种利用了神经网络的参数,而不去更新神经网络参数的优化任务中,梯度下降法也是适用的。
此外,这篇文章中提到的「风格」也是很有趣的一项属性。这篇文章算是首次利用了神经网络中的信息,用于提取内容、风格等图像属性。这种提取属性(尤其是提取风格)的想法被运用到了很多的后续研究中,比如大名鼎鼎的StyleGAN。
长期以来,人们总是把神经网络当成黑盒。但是,这篇文章给了我们一个掀开黑盒的思路:通过拟合神经网络中卷积核的特征,我们能够窥见神经网络每一层保留了哪些信息。相信在之后的研究中,人们能够更细致地去研究神经网络的内在原理。
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E5%8F%82%E8%80%83%E6%96%87%E7%8C%AE参考文献
[1] Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2414-2423.
[2] Gatys L, Ecker A S, Bethge M. Texture synthesis using convolutional neural networks[J]. Advances in neural information processing systems, 2015, 28.
[3] 代码实现:https://pytorch.org/tutorials/advanced/neural_style_tutorial.html
这段代码实现是基于PyTorch 官方教程编写的。
本文的代码仓库链接:https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/StyleTransfer
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E5%87%86%E5%A4%87%E5%B7%A5%E4%BD%9C准备工作
首先,导入我们需要的库。我们要导入PyTorch的基本库,并导入torchvision做图像变换和初始化预训练模型。此外,我们用PIL读写图像。我们还可以顺手设置一下运算设备(cpu或gpu)。
12345678
import torchimport torch.nn.functional as Fimport torch.optim as optimimport torchvision.models as modelsimport torchvision.transforms as transformsfrom PIL import Imagedevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
之后是图像读取。为了正确计算误差,所有图像的形状必须是统一的。因此,在读取图像后,我们要对图像做Resize的预处理。预处理之后,我们得到的图像是c, h, w格式的,别忘了用unsqueeze加上batch那一维。
这里
torchvision中的transforms表示一些预处理操作。部分操作只能对PIL图像进行,而不能对np\.ndaray进行。所以,这里用PIL存取图像比用cv2更方便。
1234567891011
img_size = (256, 256)def read_image(image_path): pipeline = transforms.Compose( [transforms.Resize((img_size)), transforms.ToTensor()]) img = Image.open(image_path).convert('RGB') img = pipeline(img).unsqueeze(0) return img.to(device, torch.float)
保存图像时,只要调用PIL的API即可:
123456
def save_image(tensor, image_path): toPIL = transforms.ToPILImage() img = tensor.detach().cpu().clone() img = img.squeeze(0) img = toPIL(img) img.save(image_path)
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E8%AF%AF%E5%B7%AE%E8%AE%A1%E7%AE%97误差计算
在 PyTorch 中定义误差时,比较优雅的做法是定义一个torch\.autograd\.Function。但是这样做比较麻烦,需要手写反向传播。由于本文中新介绍的误差全部都是基于MSE均方误差的,我们可以基于torch\.nn\.Module编写一些“虚假的”误差函数。
首先,编写内容误差:
123456789
class ContentLoss(torch.nn.Module): def __init__(self, target: torch.Tensor): super().__init__() self.target = target.detach() def forward(self, input): self.loss = F.mse_loss(input, self.target) return input
在神经网络中,这个类其实没有做任何运算(forward直接把input返回了)。但是,这个类缓存了内容误差值。我们稍后可以取出这个类实例的loss,丢进最终的误差计算公式里。这种通过插入一个不进行计算的torch\.nn\.Module来保存中间计算结果的方法,算是使用PyTorch的一个小技巧。
之后,编写gram矩阵的计算方法及风格误差的计算“函数”:
12345678910111213141516171819
def gram(x: torch.Tensor): n, c, h, w = x.shape features = x.reshape(n * c, h * w) features = torch.mm(features, features.T) / n / c / h / w return featuresclass StyleLoss(torch.nn.Module): def __init__(self, target: torch.Tensor): super().__init__() self.target = gram(target.detach()).detach() def forward(self, input): G = gram(input) self.loss = F.mse_loss(G, self.target) return input
这里实现风格误差的思路与内容误差同理。
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E8%8E%B7%E5%8F%96%E9%A2%84%E8%AE%AD%E7%BB%83%E6%A8%A1%E5%9E%8B获取预训练模型
VGG模型对输入数据的分布有要求(即对输入数据均值、标准差有要求)。为了方便起见,我们可以写一个归一化分布的层,作为最终模型的第一层:
123456789
class Normalization(torch.nn.Module): def __init__(self, mean, std): super().__init__() self.mean = torch.tensor(mean).to(device).reshape(-1, 1, 1) self.std = torch.tensor(std).to(device).reshape(-1, 1, 1) def forward(self, img): return (img - self.mean) / self.std
接下来,我们可以利用torchvision中的预训练VGG,提取出其中我们需要的模块。我们还需要获取刚刚编写的误差类的实例的引用,以计算最终的误差。
这段代码的实现思路是:我们不直接把VGG拿过来用,而是新建一个用torch\.nn\.Sequential表示的序列模型。我们先把标准化层加入这个序列,再把原VGG中的计算层逐个加入我们的新序列模型中。一旦我们发现某个计算层的计算结果要用作计算误差,我们就在这个层后面加一个用于捕获误差的误差模块。
整段逻辑用文字难以说清,大家可以直接看代码理解:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849
default_content_layers = ['conv_4']default_style_layers = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']def get_model_and_losses(content_img, style_img, content_layers, style_layers): num_loss = 0 expected_num_loss = len(content_layers) + len(style_layers) content_losses = [] style_losses = [] model = torch.nn.Sequential( Normalization([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])) cnn = models.vgg19(pretrained=True).features.to(device).eval() i = 0 for layer in cnn.children(): if isinstance(layer, torch.nn.Conv2d): i += 1 name = f'conv_{i}' elif isinstance(layer, torch.nn.ReLU): name = f'relu_{i}' layer = torch.nn.ReLU(inplace=False) elif isinstance(layer, torch.nn.MaxPool2d): name = f'pool_{i}' elif isinstance(layer, torch.nn.BatchNorm2d): name = f'bn_{i}' else: raise RuntimeError( f'Unrecognized layer: {layer.__class__.__name__}') model.add_module(name, layer) if name in content_layers: target = model(content_img) content_loss = ContentLoss(target) model.add_module(f'content_loss_{i}', content_loss) content_losses.append(content_loss) num_loss += 1 if name in style_layers: target_feature = model(style_img) style_loss = StyleLoss(target_feature) model.add_module(f'style_loss_{i}', style_loss) style_losses.append(style_loss) num_loss += 1 if num_loss >= expected_num_loss: break return model, content_losses, style_losses
这里有些地方要注意:VGG有多个模块,其中我们只需要包含卷积层的vgg19\(\)\.features模块。另外,我们只需要那些用于计算误差的层,当我们发现所有和误差相关的层都放入了新模型后,就可以停止新建模块了。
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E7%94%A8%E6%A2%AF%E5%BA%A6%E4%B8%8B%E9%99%8D%E7%94%9F%E6%88%90%E5%9B%BE%E5%83%8F用梯度下降生成图像
这里的步骤和正文中的类似,我们先准备好输入的噪声图像、模型、误差类实例的引用,并设置好哪些参数需要优化,哪些不需要。
123456
input_img = torch.randn(1, 3, *img_size, device=device)model, content_losses, style_losses = get_model_and_losses( content_img, style_img, default_content_layers, default_style_layers)input_img.requires_grad_(True)model.requires_grad_(False)
之后,我们声明好用到的超参数。这两个超参数能够控制图像是更靠近内容图像还是风格图像。
12
style_img = read_image('dldemos/StyleTransfer/picasso.jpg')content_img = read_image('dldemos/StyleTransfer/dancing.jpg')
这两张图片来自官方教程。链接分别为picasso,dancing。
{kind=link}
{kind=link}
最后,执行熟悉的梯度下降即可:
123456789101112131415161718192021222324252627282930
optimizer = optim.LBFGS([input_img])steps = 0prev_loss = 0while steps <= 1000 and prev_loss < 100: def closure(): with torch.no_grad(): input_img.clamp_(0, 1) global steps global prev_loss optimizer.zero_grad() model(input_img) content_loss = 0 style_loss = 0 for l in content_losses: content_loss += l.loss for l in style_losses: style_loss += l.loss loss = content_weight * content_loss + style_weight * style_loss loss.backward() steps += 1 if steps % 50 == 0: print(f'Step {steps}:') print(f'Loss: {loss}') prev_loss = loss return loss optimizer.step(closure)
由于我们有先验知识,知道图像位于(0, 1)之间,每一轮优化前我们可以手动约束一下图像的数值以加速训练。
运行程序的时候会有一些特殊情况。有些时候,任务的误差loss会突然涨到一个很高的值,过几轮才会恢复正常。为了保证输出的loss总是不那么大,我加了一个prev\_loss < 100的要求。
这里steps的值是可以调的,误差究竟多小才算小也取决于实际任务以及content\_weight, style\_weight的大小。这些超参数都是可以去调试的。
最后,我们可以保存最终输出的图像:
123
with torch.no_grad(): input_img.clamp_(0, 1)save_image(input_img, 'work_dirs/output.jpg')
正常情况下,运行上面这些的代码,可以得到下面的运行结果(我的style\_weight/content\_weight=1e6)
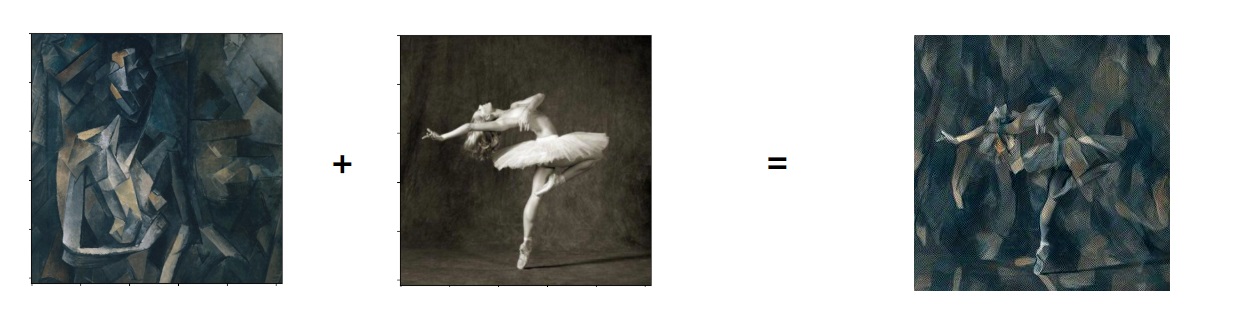
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E5%BD%A9%E8%9B%8B彩蛋
在理解了风格迁移是在做什么后,我就立刻想到:可不可以用风格迁移,把照片渲染成二次元风格呢?
成功完成代码实现后,我立马尝试把动漫风格迁移到我的照片上:

这效果也太差了吧?!我不服气,多输出了几幅中间结果。这下好了,结果更诡异了:

我都搞不清楚,这是进入了二次元,还是进入了显像管电视机。
可以看出,这种算法生成出来的二次元图像,还是保留了二次元图片中的一些风格:线条分明,颜色是一块一块的。但是整体效果太差了。
只能说,这种算法的局限性还是太强了。想进入二次元,任重而道远啊。
https://zhouyifan.net/2022/05/31/20220531-styletransfer/#%E5%90%90%E6%A7%BD吐槽
我的智力和效率已经到达了一个可怕的地步。一天时间内,我在正常生活的同时,完成了论文阅读、复现、写文章、吹牛。这种执行能力太强了。如果我每天以这样的效率学东西,成为科研大牛指日可待。
可惜,搞科研并不是我的归宿。其实写这篇文章的时候,我也在想是什么东西在支持我一直做下去。写文章对现在的我来说是没有任何收益的。想高效获取金钱上的收益,也不该写这种类型的文章。但是我就是想写。不知道究竟是为了完成我的一些个人目标,还是为了向他人展示我修炼多年的表达能力、学习能力,还是纯粹以吹牛为乐。我已经搞不太清楚了。只要觉得好玩,就一直做下去吧。
最近,我玩视频游戏的时间越来越少了。因为,生活,对我来说,就是一场最具难度、最有挑战性的游戏。
相似文章
@AYi_AInotes: 说个暴论,在AI时代最值钱的技能已经不是写代码了, 怎么把代码讲清楚将会变得越来越重要!怎么把代码讲清楚将会变得越来越重要! Anthropic Claude Code团队的@trq212 大神用不到两年时间,把自己的技术文章做到了稳定的…
文章探讨在AI时代技术写作的重要性,引用Anthropic员工@trq212通过“先种后收”的写作方法论实现百万浏览量的案例,强调分享真实经验和保持个人声音的价值。
@feng11ai: 我靠一个 Skill,把公众号文章干到了 10 万+。 不是标题党。 强推 don 哥的 DBS Skill。用了一个月,最大的感受是:我不再是一个人在写公众号。 我的做法是: 先写一篇初稿; 丢给 DBS 做诊断; 按它的建议改标题、开…
作者分享了使用Don哥的DBS Skill辅助公众号写作的经验,通过AI诊断和优化标题、结构等,最终取得了10万+阅读量的成果。
@Honcia13: 科研的门槛,正在被彻底重新定义! 以前做研究: 熬夜刷论文、反复跑代码、写一周综述。 现在: 一句话指令就够了。 开源AI代理 Feynman 把博士级研究流程压缩成全自动执行: 一句话就能完成 arXiv 深度调研、文献综述、代码验证 …
开源AI代理Feynman通过四大智能体协同,将博士级研究流程(包括arXiv调研、文献综述、代码验证)压缩成全自动执行,用户只需一句话指令即可完成。
@Moting284: https://x.com/Moting284/status/2064564715645530329
文章介绍了如何利用Codex工具将文章高效转化为个人笔记和推文,核心是三层处理法:提炼主线、记录个人反应、产出可输出观点,并提供了可复用的提示词模板。
@wsl8297: 在 GitHub 上发现一个深度学习论文精读项目:paper-reading。作者沐神逐段精读深度学习经典和新论文,录成视频讲解,已更新 3 年多。 GitHub:https://github.com/mli/paper-reading……
沐神的深度学习论文精读项目在GitHub上收录了GPT-4、Llama 3.1、Sora等重磅论文的精读视频,每个视频1小时左右,适合AI研究者和开发者深入理解经典论文。