Tokenmaxxing 已死,Tokenmaxxing 永存
摘要
对 Meta 等公司的“tokenmaxxing”现象的分析,认为高管们故意鼓励浪费 AI token 使用以推动工具采用,这与意外管理不善的看法相反。
暂无内容
查看缓存全文
缓存时间: 2026/06/28 16:58
# Agentics / Tech Things:Tokenmaxxing 已死,tokenmaxxing 万岁
来源:https://12gramsofcarbon.com/p/agentics-tech-things-tokenmaxxing
一般来说,如果你在某样东西上花了数万美元,你总希望看到点回报。某种*投资回报*。
当然,也不总是这样。我之前说过,面向消费者销售有点好笑,因为**他们喜欢把钱花在浪费时间或主动带来痛苦的事情上**(https://12gramsofcarbon.com/p/the-elegance-of-movement-in-silksong?utm_source=publication-search)。这也是如今赌博应用如此流行的部分原因。没错,我很乐意花 100 美元赌 Wemby 在倒立并用法语唱国歌的同时投进一个三分球。¹(https://12gramsofcarbon.com/p/agentics-tech-things-tokenmaxxing#footnote-1)
但对于企业呢?我几乎从未听过某位企业领袖说他们要烧一大笔钱,因为他们觉得很爽——至少不像那些鲸鱼用户会在《原神》抽卡上花几千块那样。想象一下,如果某位严肃的企业领袖,比如马克·扎克伯格,决定宣布 Meta 要烧钱。他*可以*这么做。他拥有投票权。但这会有点愚蠢,不是吗?我通常认为,如果你已经走到了运营真正庞大、真正重要的公司这一步,你大部分时间不会为了找乐子而做事,但有一个明显的例外。
如果你还没听说,tokenmaxxing 是(曾经是?)一种现象:高管们无意中鼓励员工在无用的任务上消耗大量 token。典型的例子——纯属巧合——是 Meta,它被彻底嘲讽,因为将绩效评估与每个人的 token 使用量挂钩。显然,*显然*这会导致人们只是把 token 浪费在无意义的事情上。我在 Meta 的一个朋友报告说,他们实际上只是让两个 agent 整天互相聊天,以提高她的 token 数量。

这是一个如此明显的结局,以至于许多人将其归结为“这些企业领袖真的很蠢,因为他们决定烧掉一大笔钱在 token 上,却不期望任何回报。”
我理解为什么这是一个诱人的观点,因为这多少有点像很多这些事情公开表现出来的样子。但我将做我最喜欢的事情——稍微反潮流一点。这并非是“高管们无意中鼓励员工在无用的任务上消耗大量 token。” 而是“高管们***有意***鼓励员工在无用的任务上消耗大量 token。”
我与许多团队合作,研究如何有效使用 AI。几个月前,有很多人非常抵制使用 AI 工具。高级人员,在组织内备受尊重的人。说服这些人使用工具非常困难。而当你成功说服他们时,他们常常会无意(或有意?)地以一种明显会导致奇怪或糟糕结果的方式使用工具。²(https://12gramsofcarbon.com/p/agentics-tech-things-tokenmaxxing#footnote-2)
不仅仅是高级人员!
看待这种自上而下的 tokenmaxxing 政策的一种方式是,这是高管们用来打破僵局的一种手段。是的,这显然是一种粗暴的政策,但有时你需要用粗暴的力量来突破一堵墙。
当然,那是几个月前的情况,当时还存在着抵制者。现在几个月过去了,tokenmaxxing 政策达到了预期效果:每个人都在使用 AI 编程,至少用了一些。大多数团队还没有弄清楚如何构建自己的 Ramp Inspect 或 Stripe Minions(如果你也是,请联系我们——我们可以帮忙!),但基本上每个人至少都在侧边栏中使用 cursor。当然,这意味着 token 支出大幅上升。不幸的是,但可能并不意外,token 支出的增加正逢 OpenAI 和 Anthropic 试图上市。两家公司都限制了其订阅提供的“果汁”量,同时提高了 API 定价。Token 补贴正逐渐消失。
所以现在激励措施基本消失了,成本大幅上升,当然,团队开始取消他们的无限 token 支出政策。综上所述,tokenmaxxing 已死。
除非……也许并没有。
AI 工具的普遍承诺是,你可以让它们在无人监督的情况下运行,以完成真正困难且真正烦人但仍需完成的任务。大型代码迁移、每天早上研究所有竞争对手、跟上入站和出站的流量——这些都是人们大多讨厌做并希望 AI 来做的事情。
然而,直到最近,你还无法可靠地让 AI 长时间运行。如果你尝试过,你会注意到模型引入的小错误(包括幻觉)会自行发展,并最终不可逆转地嵌入项目中。在行业中,我们称之为“复合错误”。这不仅需要相当多的人工监督,而且*还*使 token 成本保持在低位,因为一开始让 agent 24/7 运行也没什么好处。比方说,如果那个东西只会毁掉你所有的辛勤工作,那么让你的电脑里的小恶魔过夜运行有什么意义呢?如果花更多的 token 会导致*更糟*的结果,你显然不会花更多的 token!
现在情况已不再如此。我们已经进入了一个不同的阶段,花更多的 token 通常会导致更好的结果。我们称之为“复合正确性”——花在纠正任务上的 token 越多,得到好结果的可能性就越大。我们在上次的 Agentics 线下聚会上讨论过这一点(https://agenticsnyc.com/events/may-2026-speaker-series.html):
复合正确性颠覆了计算方式。如果更多的 token 支出带来更好的结果,那么你会想花大量时间运行 token。这听起来当然就像 tokenmaxxing 对我来说!最初的 tokenmax 激励已经消失,但最终人们会意识到,一个新的、更强大的激励已经取而代之。
我们已经在网络安全领域看到了一些这种情况(https://www.dbreunig.com/2026/04/14/cybersecurity-is-proof-of-work-now.html):
> 上周我们了解到 Anthropic 的 Mythos,这是一个新的 LLM,其“在计算机安全任务上的能力惊人(https://red.anthropic.com/2026/mythos-preview/)”,以至于 Anthropic 没有公开发布它。相反,**只有关键软件制造商获得了访问权限**(https://www.anthropic.com/glasswing),以便他们有时间加固系统。……这张图表暗示了一种有趣的安全经济学:**要加固一个系统,我们需要花费比攻击者利用漏洞更多的 token 来发现漏洞**。AISI 为每次尝试预算了 1 亿 token。那是每次 Mythos 尝试花费 12,500 美元,十次运行花费 12.5 万美元。令人担忧的是,所有给予 1 亿 token 预算的模型都没有显示出收益递减的迹象。“模型在测试的 token 预算范围内继续取得进展,”AISI 指出。如果只要继续投入资金,Mythos 就会持续发现漏洞,那么安全就简化为一个残酷的等式:**要加固一个系统,你需要花费比攻击者利用漏洞更多的 token 来发现漏洞**。你不会因为聪明而得分。你通过支付更多而获胜。这是一个呼应加密货币工作量证明系统(https://en.wikipedia.org/wiki/Proof_of_work)的系统,其成功与原始计算工作挂钩。这是一个**低温彩票**(https://x.com/lateinteraction/status/2042025859003920574):购买 token,你也许会找到一个漏洞。希望你比攻击者坚持得更久。
Fable 现在已经不幸消失了(https://12gramsofcarbon.com/p/tech-things-there-is-a-massive-shadow?utm_source=publication-search)。但其底层概念仍然存在。
这也是为什么人们突然对“循环”如此兴奋的部分原因。Claude Code 的创建者 Boris Cherny 上台说了“循环”,所有人都疯了。循环的基本思想是,你运行一个 agent 直到它完成任务,当它完成时,你只需重新启动相同的提示。通过一点巧思,你可以将一个相当复杂的规范拆分成多个部分,并让 agent 随时间的推移自动解决。无需人工监督。
这是新东西吗?不,并不是。循环概念实际上从去年七月就有了。它以前被称为“Ralph Wiggum 循环”,但随着行业的成熟,我们的幽默感也成熟了,“Ralph Wiggum”部分被去掉了。
r/TheSimpsons - 哪个场景或时刻让你对一个角色感到最痛苦的同情?
(https://substackcdn.com/image/fetch/$s_!WZWz!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F597774da-0817-4f0f-9777-eeeb27fd7aff_260x194.jpeg)
有一些方法可以让循环工作,但很难。你必须大量思考如何提示 agent,这反过来需要对这些东西的工作原理有相当深入的熟悉。但现在,这很容易。复合正确性使它变得容易。你基本上可以按照你想要的任何方式提示 LLM,在第一次近似中,它在每次循环迭代中都会变得更好。
那么 tokenmaxxing 真的死了吗?也许是暂时的,但从长远来看,我不这么认为。处于最前沿的团队目前正在构建或已经构建了必要的 infrastructure 来让 agent 24/7 运行。大型公司意识到成本效益已再次发生转变只是时间问题。
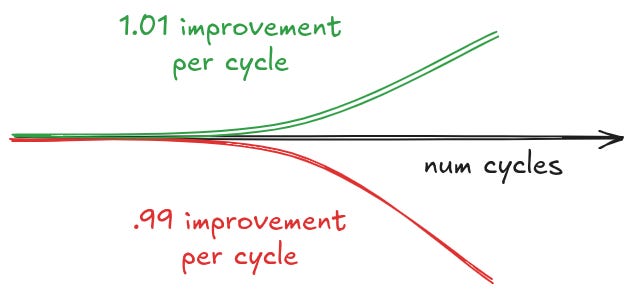
这里真正的赢家是开放模型平台。Tokenmaxxing 顶级实验室永远无法经受任何 CFO 的审视。随着开放模型越来越好,简单地在循环中运行*那些*模型会变得更加流行。这正是 Rohan 上面演讲的核心论点。如果 Claude 每次迭代给你 1.1 倍的提升,而 GLM 5.2 每次迭代给你 1.05 倍的提升但成本低约 5 倍,那么你可以将第二个循环运行 5x 次,它会更好。
最后我想提到的是,一些荒谬的 token 支出源于对使用这些工具最佳方式的严重误解。在编程 agent 真正起飞之前(很大程度上要归功于像 Claude Code 这样更好的 harness),很多人都在构建自己的自定义 agent。那确实是正经工作!你必须像……对待软件一样思考这些东西。找出工具和提示是一门艺术,但其核心仍然是软件,即使它由像 Pydantic 或 Langchain 这样的“AI 原生”框架支持。
你不能把方形的钉子打进圆形的孔里。各地的高管们看到了这种构建 agent 的方式,心想“哦,这只是一个更灵活的 zapier 工作流”,然后要求构建能够完成一次性任务的‘agentic’数据处理管道,而不是用老式确定性代码构建相同的管道。“我需要做数据标注,所以我要构建一个数据标注 agent。”诸如此类。
现在,依赖 agent 来做这些事情已经比仅仅做一个工作流自动化要昂贵得多。但更大的问题是准确性:这些‘agent’从未真正起飞,因为它们永远不会像确定性管道那样准确。
如果你坚持使用 agent 但想降低幻觉等成本,你会怎么做?为什么,再构建一个 agent!一个‘质量检查’agent,或者类似的东西。如果那个 agent 给你错误怎么办?好吧,你再建一个!这样你现在就有了 3x 的 token 成本,好好享受吧!
Tokenmaxxing 的故事,再次是关于 RoI 的。这个故事*不仅仅*发生在大型科技公司。它也以不太先进的规模发生在全国各地的公司——这些公司向由独立顾问构建的随机 agent 管道投入了数十亿美元,而这些管道不幸地从未真正很好地工作过。
请注意,这实际上是两种不同类型的 tokenmaxxing。
- 第一种是‘*为你的开发者*在 token 上花很多钱’。在这里,开发者使用像 Claude Code 这样的工具,想出如何运行循环,并使用大量 token 来做这件事。表面上看,这是对金钱的良好使用,因为它让工程师本身更有效率。
- 第二种是‘*为你的管道*在 token 上花很多钱’。在这里,开发者仍然在手动编写代码!他们用这些代码创建一次性 agent 来做非常具体的任务,通常是非确定性和脆弱的,而正是*那些*agent 吞噬了大量 token。只有当管道有效时,这才是一种对金钱的良好使用,但它们并不有效。
但在这里,我们也看到了转变。越来越多地,这种一次性的基于管道的工具,最好由针对特定任务进行皮肤化的通用平台来完成,而不是专门为那一个任务设计的“agent”。这里存在一些市场套利。一些买家还没有意识到通用 agent 已经变得非常好,所以他们会去找顾问,要求“为我构建一个 agent”,而顾问基本上会写一个技能文件,然后说“请付 200 万美元”。
幸运的是,这一切也都会过去。通用模型平台对于任何使用过它们的人来说显然是未来(如果你还没用过,再次,请联系我们!)而这,又会再一次导致市场这一部分的 tokenmaxxing 行为上升。
这一切的自然终点是“软件工厂”,或者更进一步,“黑暗工厂”——一个能自动生成代码、审查代码、修复 bug、编写测试等等而无需任何人工监督的代码库。人类只需输入一个规格说明,然后一个应用就出来了。StrongDM 的那帮人(https://www.strongdm.com/blog/the-strongdm-software-factory-building-software-with-ai)已经将其推到了最极端的程度,主张工程师应该以*每天花费 1000 美元 token*(https://simonwillison.net/2026/Feb/7/software-factory/)为目标。这几乎肯定是炒作,是长期趋势的一部分,即通过说离谱的话来获得关注和热度。我们有一个软件工厂,我们每月大约花 600 美元。但炒作和热度之所以出现,是因为尽管目前每个工程师在 token 上花费相当于一名高级谷歌工程师的薪资是荒谬的,但其中确实有一丝真相。花费荒谬金额在 token 上的激励是存在的,潜在的,等待着扩散。
旧物换新颜,已死之物永不灭。Tokenmaxxing 已死,但我们还没有看到 tokenmaxxing 的最后一面。
- GPT 5.6 发布了,算是吧。来自公告(https://openai.com/index/previewing-gpt-5-6-sol/):> 我们正在开始一个有限的预览,关
相似文章
Tokenmaxing已过时 - 节约型AI成新趋势
Tokenmaxing(无限AI令牌使用)的时代正在结束,因为企业面临高昂成本和生态破坏,取而代之的是tokenminimizing——注重效率并为任务选择合适的AI模型。
@sdianahu: tokenmaxxing 并不是‘花费更多 tokens’,而是相反:tokenmaxxing = 选择要最大化正确指标,然后让其他一切尽可能……
一条推文解释,‘tokenmaxxing’ 是关于在最小化成本的同时优化正确指标,利用智能成本下降的趋势,并指出品味才是稀缺的输入。
@dabit3: Tokenmaxxing 已死。大家都意识到用token使用量来衡量生产力是个糟糕的方法。那么接下来我们该怎么做……
讨论AI采用中从基于token的生产力指标转向产出、影响和价值衡量,重点介绍Cognition的解决方案:自适应路由、支出归因、自动化以及生产力保障。
Token消耗狂飙正成为一类生产事故。你如何为AI代理费用设置上限?
AI代理导致Token消耗失控,使超支成为一类生产事故。文章列举了诸如一位工程师130万美元的OpenAI账单以及Uber在四个月内烧掉全年AI预算等案例,并向社区询问如何为代理费用设置上限。
@LinusEkenstam: ROT — 代币回报(Return on Tokens)。我们都知道终有一天会走到这一步。从一开始,Tokenmaxxing 就是个愚蠢的主意。它……
作者批评了在LLM使用中追求token最大化的趋势,并主张通过优化和路由转向代币回报(ROT),以实现可持续的AI部署。