@dmokafa:大多数开发者不使用代理循环。但这是用AI自动化工作的最佳方式。以下是8个关于如何驾驭…
摘要
本文讨论了利用AI自动化工作的代理循环概念,提供了编写高质量循环的8个技巧,并引入了循环工程作为一种减少开发者瓶颈的方法,通过设计自动提示代理的系统来实现。
查看缓存全文
缓存时间: 2026/06/16 11:53
大多数开发者并没有使用代理循环(agentic loops)。
但它们是利用AI自动完成工作的最佳方式。
以下是编写高质量循环的8个技巧:
- 使用闭环。开环会消耗大量Token和金钱
- 只对可重复且能自动检查“完成“状态的任务使用循环
- 在独立的Git工作树中运行并行代理
- 使用单独的代理来验证工作是否完成
- 通过测试和代码检查器添加质量门,而非依赖LLM输出
- 使用RULES.md记录反复出现的错误
- 自己管理RULES.md。这是人类输入的关键所在
- 使用Claude内置的/goal命令开始入门
要了解更多关于循环的内容,请查看我的最新文章:https://craftbettersoftware.com/p/loop-engineering-101…
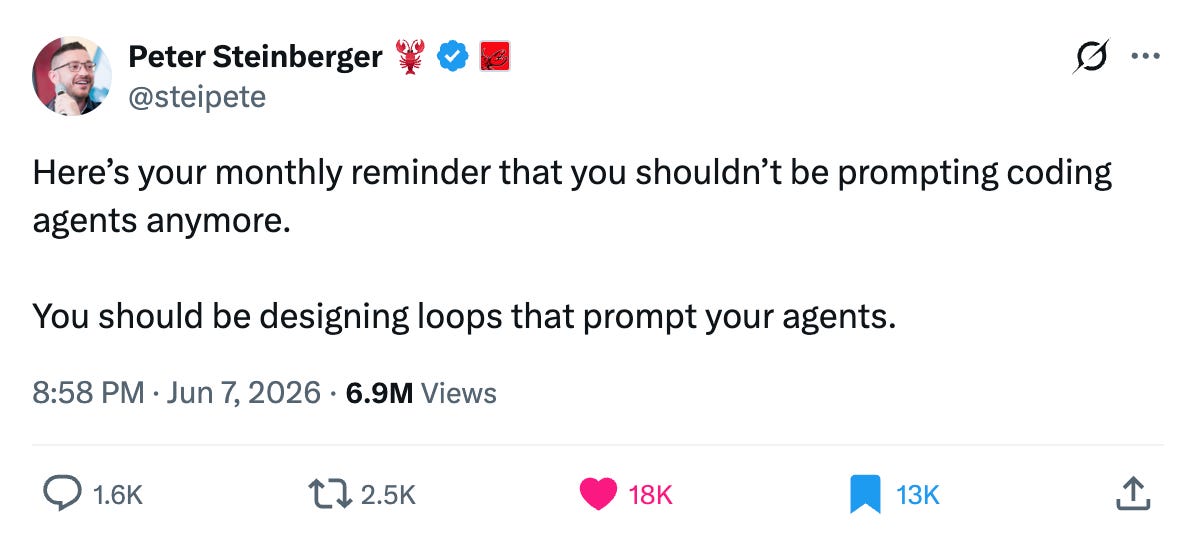
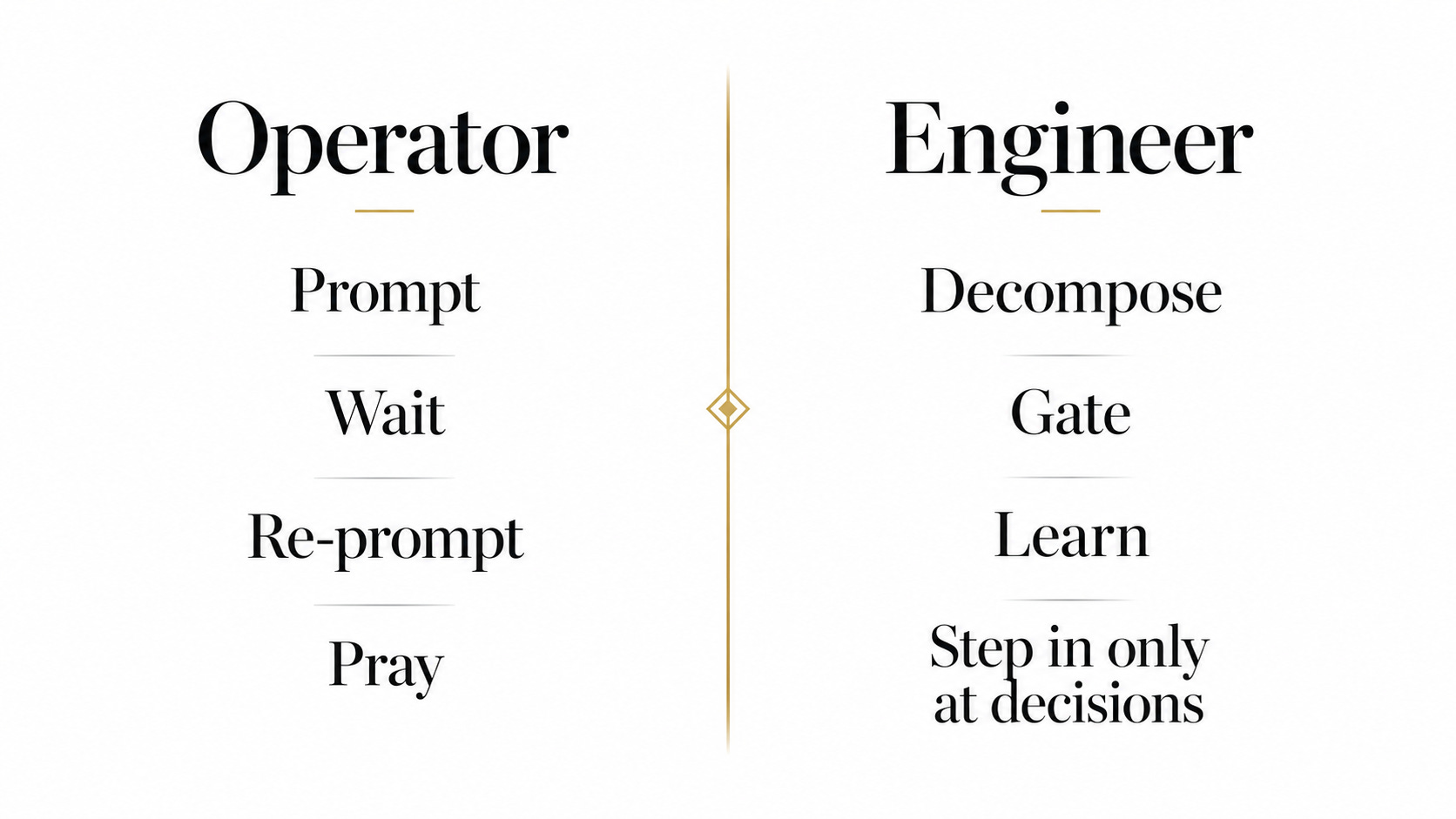
普通开发者编写提示词给代理。
优秀的开发者设计循环来提示代理。
循环工程101
来源:https://craftbettersoftware.com/p/loop-engineering-101 AI编写的代码比以往任何时候都多。审查代码不应该意味着按字母顺序滚动浏览四十个文件。
CodeRabbit Review 将任何拉取请求从扁平的文件列表重新组织为结构化的、逐层的演练——即变更的逻辑阅读顺序,而非平台随意排序的顺序。每个范围都有自己简洁的文字摘要,并在需要直观展示的地方内联生成序列图、状态机和实体关系图。
Cohorts 将相关文件和代码块分组,这样你可以一次审查一个想法。Layers 对它们进行排序,使基础变更——数据形状、契约——先于依赖它们的代码出现。Code Peek 让你点击任何变量、函数、类或类型,就能在不离开标签页的情况下查看其定义和用法,而 Semantic Diff 视图则去除了格式噪音,只显示实际变更的内容。
直接从PR演练中的“Review Change Stack“按钮打开即可。使用键盘在分组和层级间导航,针对精确的行范围发表评论,并将原生审查、评论和批准回传给GitHub或GitLab,正好在你团队期望的位置。
早期访问阶段,对所有人免费提供。
来自开创AI代码审查的团队。每周200万次审查。600万个仓库。1.5万客户。专为现代PR实际编写方式打造的审查界面。
立即使用 CodeRabbit Review 审查你的下一个 PR (https://www.coderabbit.ai/?utm_medium=post&utm_source=socials&utm_campaign=coderabbit_agent&utm_term=danielmoka)
“循环工程“是本周的热词。OpenClaw的创建者 Peter Steinberger 发布了一条推文(约2万点赞,700万浏览量),它应该会改变你的工作方式:
他并非孤例。Claude Code的创建者 Boris Cherny 也一直在持同样的观点。
{kind=link}
两年来,我们每次只提示代理执行一个任务:构建页面。现在修复这个问题。现在编写测试。你驱动着每一步,而这也让你成为了瓶颈。
这里用一句话概括转变:循环工程就是用你自己取代那个提示代理的角色。你构建一个系统来执行提示,它持续运行直到目标达成。
在这篇文章中,我将向你展示什么是循环工程、它的最佳实践,以及如何在你的工作流程中使用它。
我们开始吧!
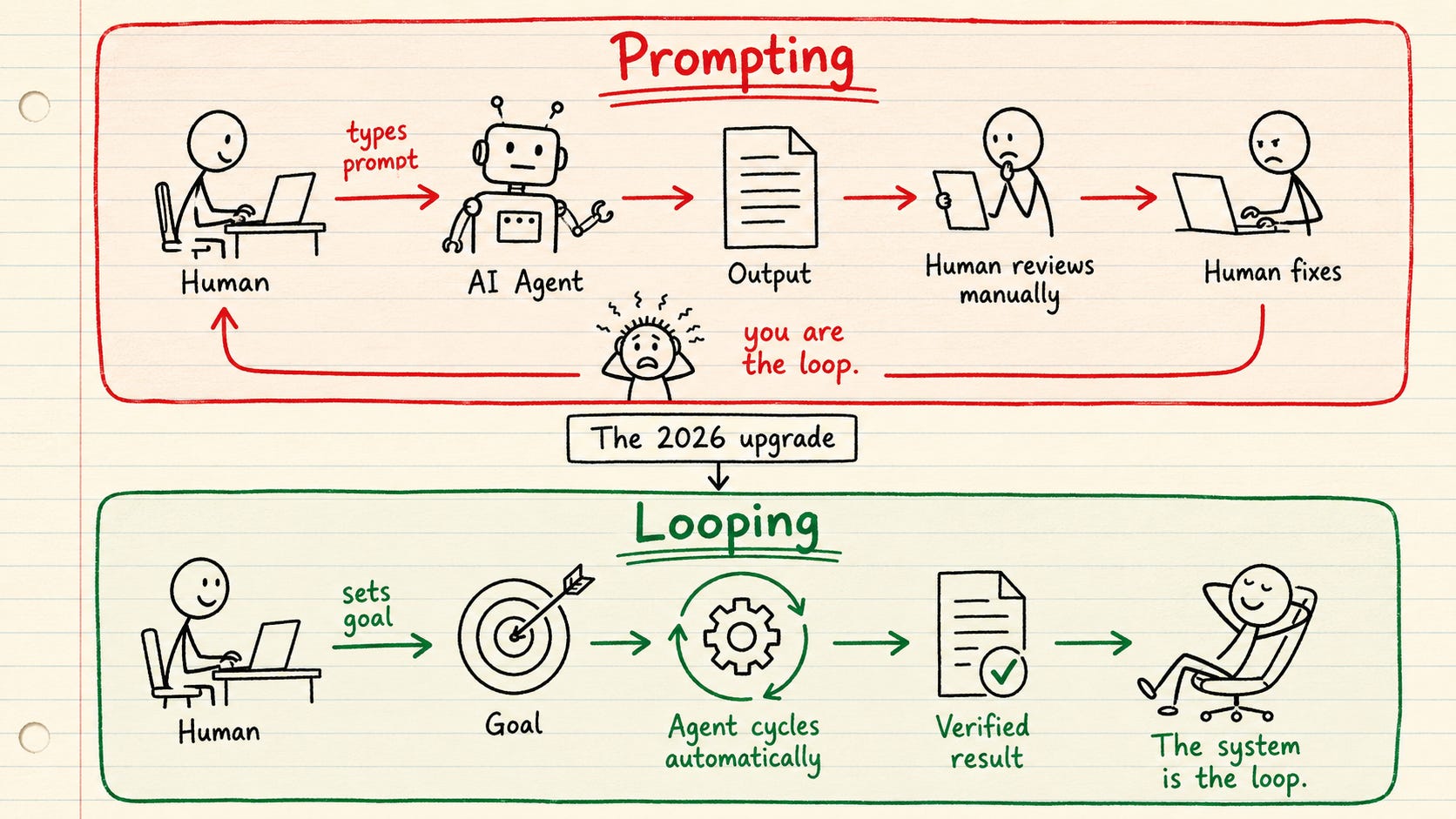
这是一个令人不安的事实:当你每次只提示一个任务时,你就是系统中缓慢的部分。 代理等待你阅读输出、决定下一步、然后输入下一个提示。一切都在你注意力的速度下运行。
{kind=link}
循环将你从这条路径中移除。简单来说,就是一个代理在自身基础上循环工作:
- 发现:找出它需要知道的信息
- 规划:将目标分解为清晰的步骤
- 执行:完成工作
- 验证:对照目标和标准检查结果
- 迭代:修复差距并再次运行
它不断重复,直到工作达到标准。想象一下一个人重写自己的草稿:研究、写作、对照要求重读、修复薄弱部分、重复。你只需设置一次循环,然后就可以放手。
💡 并非每个任务都适合放入循环。一个任务适合循环需满足三个条件:
- 它重复的频率足够高,值得为之设置循环
- 它有可自动检查的“完成“定义
- 错误尝试的代价很低
如果你无法写出判定“完成“的检查,你就还不能构建这个循环。
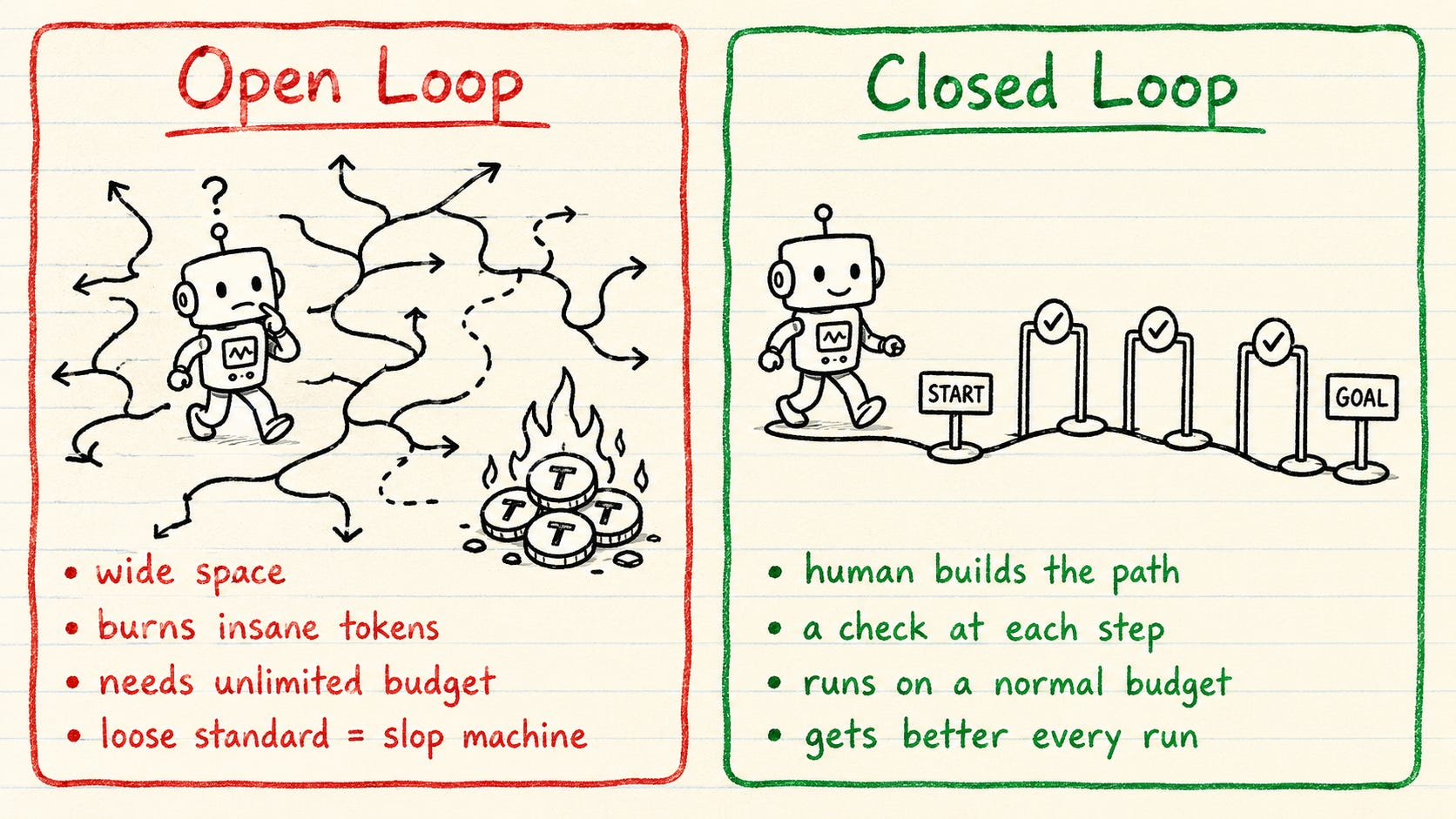
大多数关于循环的热议都跳过了那个决定你是否能在实际预算中运行它的关键问题。
{kind=link}
你给代理一个广阔的空间去漫游、发现、并构建你从未指定的东西。一个单代理循环在一次运行中可能消耗5万到20万Token。将一群代理指向一个开放式的目标,你面对的是50万到200万Token。 在宽松的标准下,它会变成一台快速的“垃圾“制造机。我曾见过一个开环运行整夜,消耗大量Token预算,然后交回一个没人要求的东西。对大多数团队来说,这是错误的起点。
你需要首先构建路径:一个清晰的目标,定义的步骤,每一步的检查,以及它停止或交回给你的节点。 代理仍然循环,但在你设定的框架内。
闭环在最关键的事情上胜出:它不断改进。每次通过都会为下一次提供输入,所以一个月后你运行的循环会比今天启动的更加锐利。
一个循环包含6个部分:
{kind=link}
- 自动化:心跳。循环按计划或事件运行,而不是靠你。比如夜间运行、新Issue、构建失败。
- 工作树:每个代理拥有自己独立的分支,这样并行代理永远不会在相同文件上冲突。
- 技能:项目知识一次写入,每次循环读取。目标和规则存放在VISION.md和RULES.md这样的文件中,而不是在代理每次会话间都会忘记的聊天中。
- 插件和连接器:循环连接到你的真实工具:PR、工单、CI、数据库、Slack。它自行创建PR并更新工单。
- 子代理:一个制造者编写代码,一个单独的检查者进行验证。编写代码的代理永远不是批准它的那个,否则循环就是在给自己的作业打分。
- 记忆:状态存在于对话之外,存储在磁盘上。循环从不从零开始,也永远不会忘记学到的内容。
{kind=link}
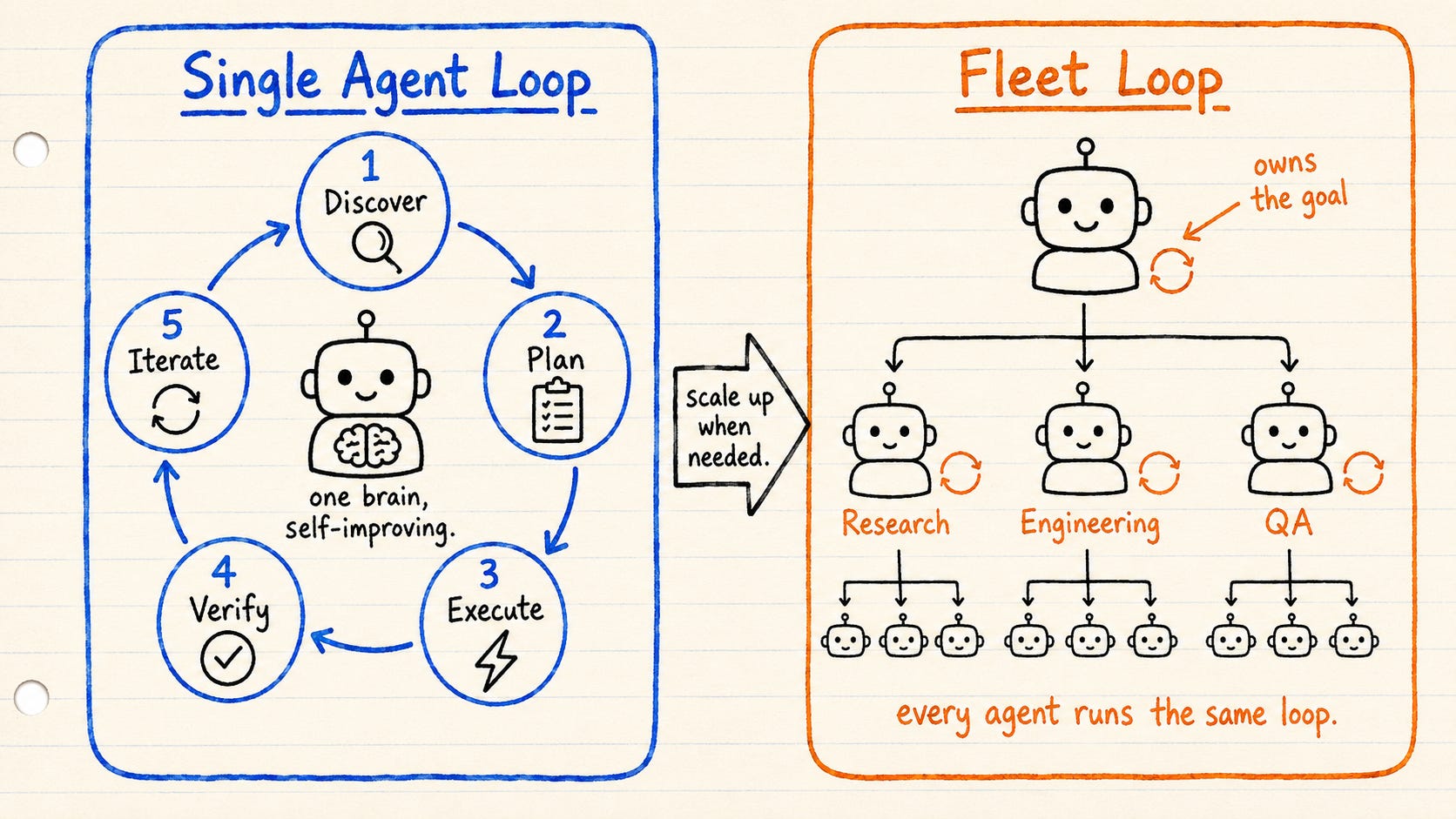
单代理循环是一个大脑改进自己的工作。代理自行运行整个周期:从发现到迭代,然后再次循环,直到工作质量达标。 成本低、简单,适用于大多数任务。
集群循环则是将其扩展。一个编排器负责目标,并将任务分配给专家:研究员、工程师、审查者。 每个专家可以将细化的工作交给自己的子代理。树中的每个代理都运行相同的五步循环。只有当单个大脑不够用时,你才需要集群。
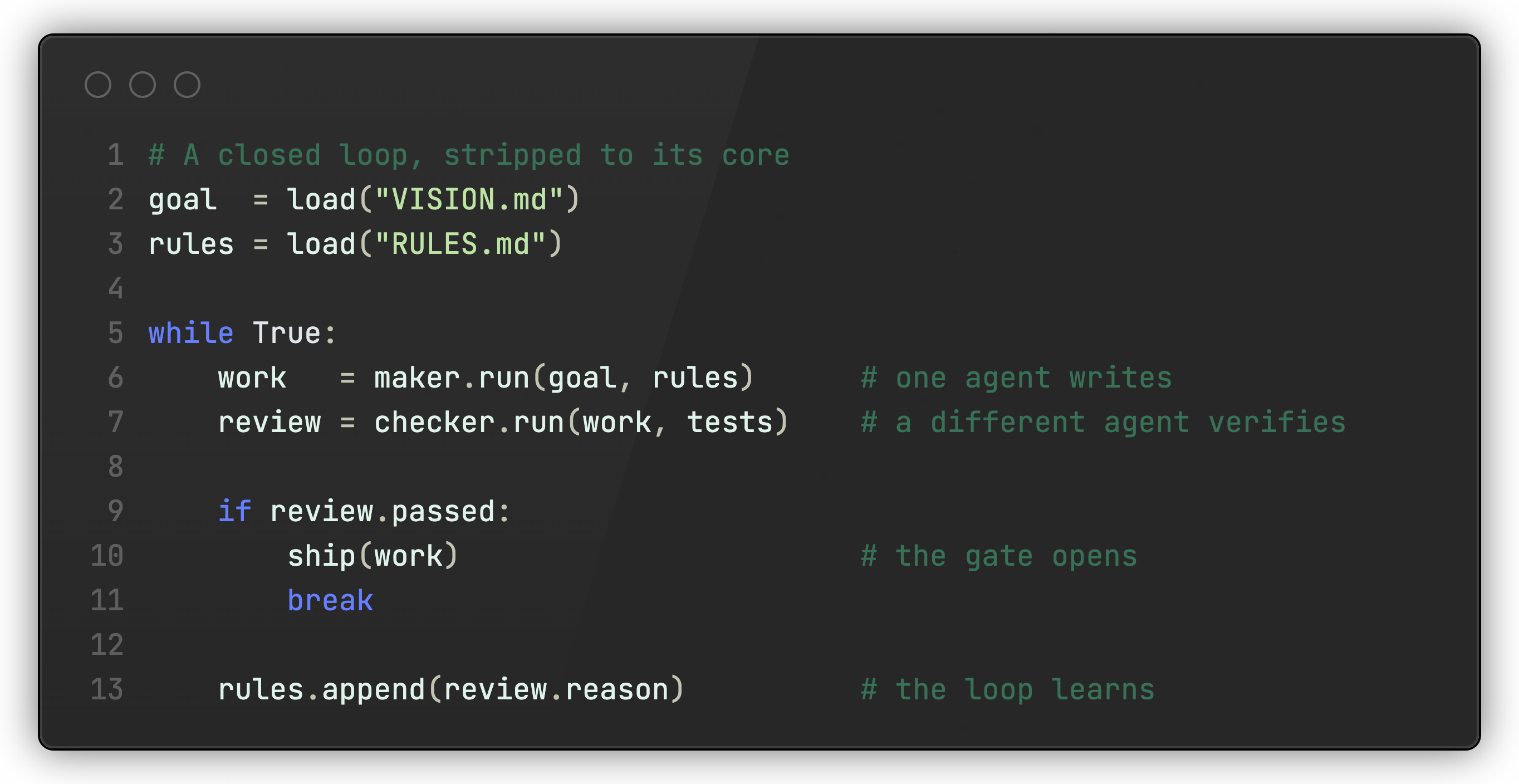
闭环的伪代码表示如下:
你可以在一个地方看到整体结构:从磁盘加载的目标和规则、制造者、检查者、门控,以及将失败转化为新规则的那一行代码。
{kind=link}
这里有一个我实际会运行的完整闭环。称之为分析监控器:
- 监控器每五分钟轮询分析数据,当错误激增时唤醒循环
- 循环将bug重现为一个失败的集成测试
- 制造者代理在全新的工作树中修复代码,直到测试通过
- 检查者代理运行完整的测试套件
- 门控决定:绿灯则创建PR并在Slack上通知我,红灯则返回原因
- 如果无法修复,它保留重现的测试,并在Slack上@我
- 如果代理在修复过程中犯下可避免的错误,我将其添加到规则中,以便下次运行更顺利
没什么特别的。一个目标、一个门控和一段记忆,良好地组合在一起。
Claude Code的 /goal (https://code.claude.com/docs/en/goal) 和 Codex Goals (https://developers.openai.com/cookbook/examples/codex/using_goals_in_codex) 已经为你运行循环。
你设置一个完成条件,代理持续工作,轮复一轮,一个单独的模型每轮检查目标是否达到,然后才停止。
一个注意事项:Codex根据真实的测试和日志进行验证,而Claude的 /goal 仅根据代理在对话中报告的内容做出判断。
所以,将你的条件绑定到硬性指标上,比如一个必须干净退出的测试套件,而不是一个模糊的代理响应“它工作了“。
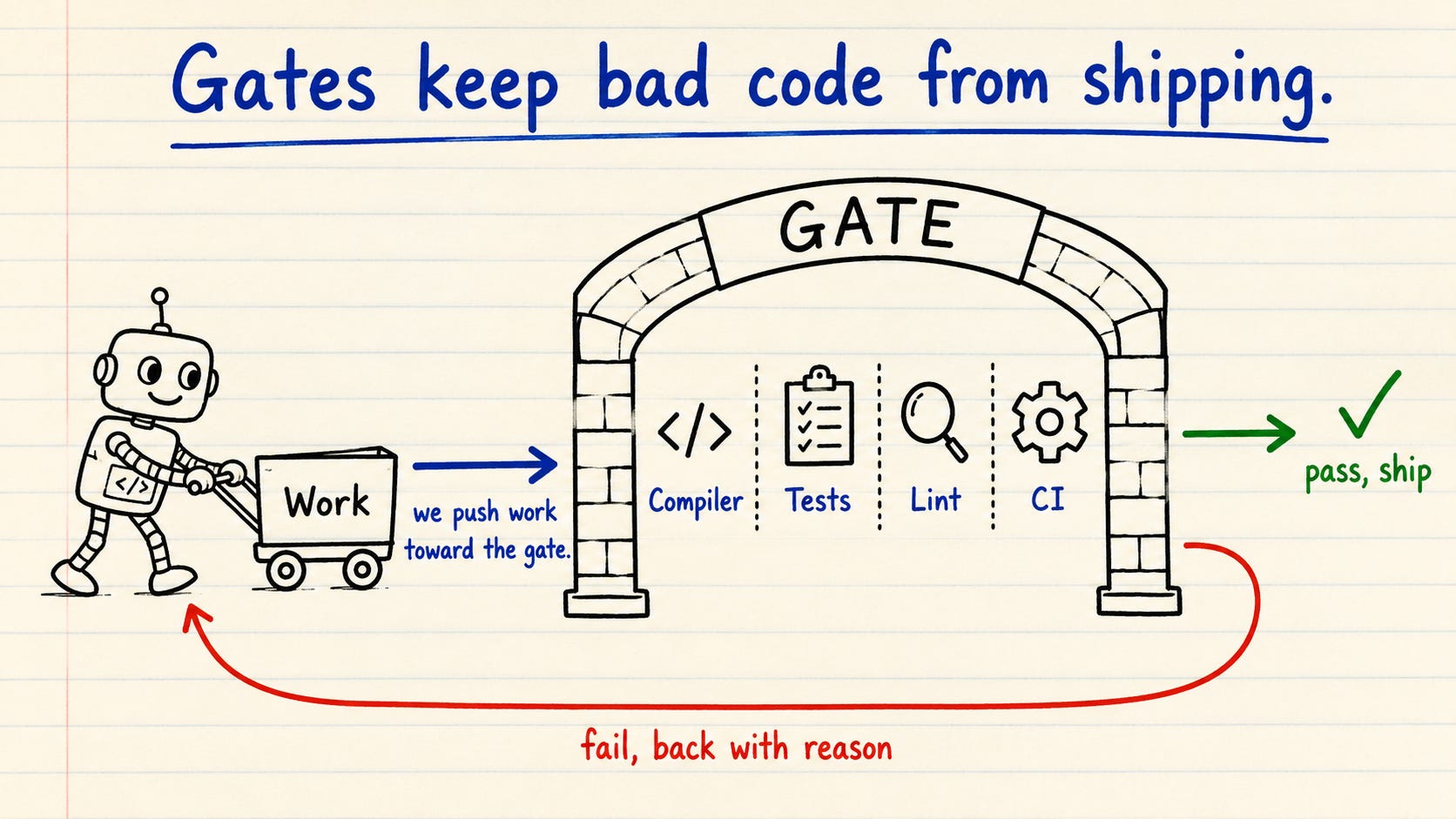
没有门控的循环产生“垃圾“的速度更快。门控是工作在发布前必须通过的检查,也是唯一能让循环保持诚实的东西。
这一步是人们跳过的,也是他们的循环偏离正轨的原因。如果没有东西用硬性标准检查工作,代理就会在循环中自信地输出错误结果,然后声称完成了。
你的门控不能是一句礼貌的审查评论。代理可以绕过评论。但它无法绕过编译失败、测试红色或CI作业被阻塞。所以用代理无法争辩的东西构建门控:编译器、类型系统、集成测试、变异测试、基于属性的测试、代码检查器、分析器和CI。
{kind=link}
这与我上一篇文章 (https://craftbettersoftware.com/p/how-to-catch-ai-mistakes-in-your) 中提到的确定性护栏是同一个理念。循环完成工作,而护栏决定工作是否允许通过。
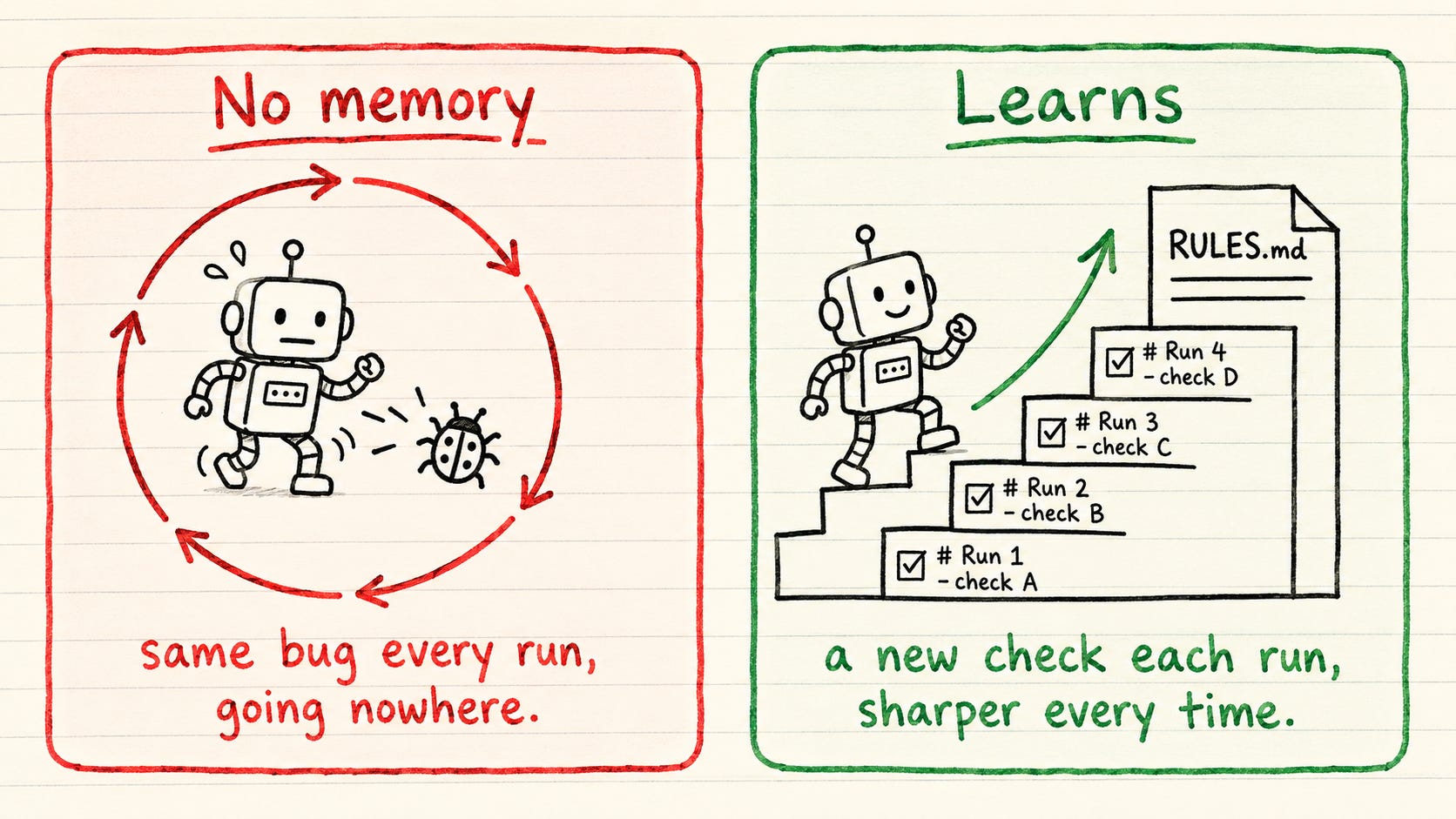
你的代理今天修复了一个bug,明天又把它重新引入。不是因为它笨,而是因为它忘了。一个循环只有将其经验教训带向未来并坚持执行,才能不断改进。 但模型在运行之间会清空记忆。所以一个裸循环每次运行都从零开始冷启动,重新推导整个项目,并且很可能重复昨天的bug。
解决方案是运行之间幸存下来的记忆,存储在你拥有的磁盘文件中:RULES.md
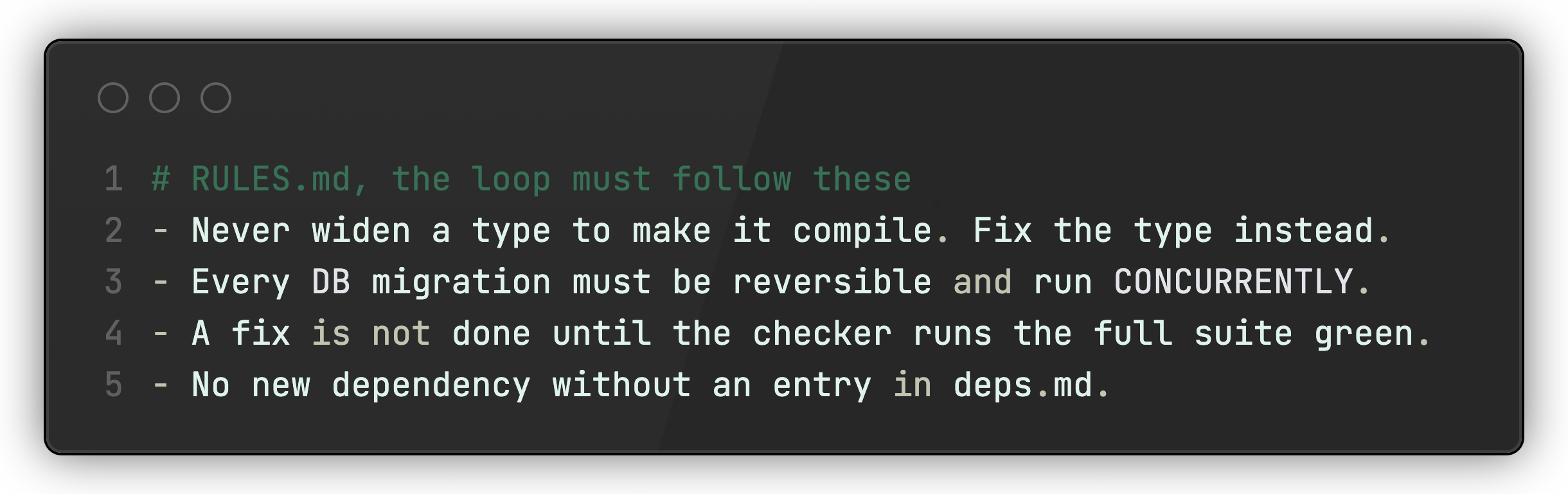
这个文件在机器和人类之间清晰分开。循环捕获失败并报告失败原因。你来决定它是否值得成为一个永久规则,并将其写入RULES.md。 循环可以自行起草规则,但你拥有这个文件并保持其诚实。那部分判断仍然是人类的职责。
{kind=link}
每次出现问题时,文件都会增长:
但书面规则仍然只是一个代理可以忽略的建议。在可能的情况下,用确定性检查、代码检查器或测试来支持它,这样门控就能强制执行它,代理无法跳过。所以一次被捕获的错误永远成为一道墙。
{kind=link}
你的工作不是设计循环来提示你的代理,而是设计能从经验中学习的循环。
每次只提示一个任务让你成为了操作员。设计循环让你成为了工程师。你只在决策点介入,而循环负责分解、执行、门控和学习。
{kind=link}
但不要完全沉迷于循环!如今,网上每个与AI相关的观点都被推向了极端:要么你运行一群代理全天候燃烧Token,要么你拒绝一切循环并手动提示所有事情。
真相在中间。
循环值得用于那些重复且可检查的工作。手动提示对于其余工作仍然很好,而且由于循环会消耗真实的Token,通常少即是多。
务实,而非教条。这就是我们如何用心打造更好的软件。
关于这篇文章的讨论
准备了解更多内容?
相似文章
@akshay_pachaar:关于循环工程。这周大家都在说同一件事。你不再提示代理,而是设计循环来提示它们……
这篇文章讨论了AI代理的循环工程,并介绍了Opik——一个来自Comet ML的开源工具,用于生成式AI应用的调试、评估和优化,重点在于自动化失败处理以及根据真实失败构建回归测试。
@mvanhorn: https://x.com/mvanhorn/status/2063865685558903149
本文解释了AI编程中'循环'的概念,即开发者编写程序来提示编码代理,而不是手动提示,这一概念由Peter Steinberger和Boris Cherny推广开来,并讨论了这种转变如何代表了AI辅助开发中的新抽象层。
@Aurimas_Gr: 作为AI工程师,你必须了解这些𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗦𝘆𝘀𝘁𝗲𝗺 𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀。如果你……
文章描述了在企业环境中构建代理式AI系统的五种关键工作流模式,由Anthropic总结:提示链、路由、并行化、编排器以及评估器-优化器,并建议在使用完整Agent之前优先采用更简单的工作流。
@rohit4verse: 构建可交付的“弱智”AI 循环是目前智能体系统的核心护城河。88% 的代理试点项目采用这种模式,但……
文章讨论了智能体 AI 系统中的常见失败模式,特别是“弱智 AI 循环”,并引用了在 Claude Code 部署中观察到的状态污染和数据泄露等问题。
AI正在吞噬AI工程循环(5分钟阅读)
文章讨论了AI工程循环如何能够完全自动化,但认为将整个循环交给AI会产生'agent slop'(智能体垃圾),因为评估不完善。它建议自动执行某些步骤,同时保留人类判断以处理细微差别。