Cached at:
05/13/26, 12:22 AM
# A²RD: Agentic Autoregressive Diffusion for Long Video Consistency
Source: [https://dxlong2000.github.io/AARD/](https://dxlong2000.github.io/AARD/)
1Google Cloud AI Research2National University of Singapore
## Abstract
Synthesizing consistent and coherent long video remains a fundamental challenge\. Existing methods suffer from semantic drift and narrative collapse over long horizons\. We present**A²RD**\(/ɑːrd/\), an**A**gentic**A**uto\-**R**egressive**D**iffusion architecture that decouples creative synthesis from consistency enforcement\. A²RD formulates long video synthesis as a closed\-loop process that synthesizes and self\-improves video segment\-by\-segment through a Retrieve–Synthesize–Refine–Update cycle\. It comprises three core components:*\(1\) Multimodal Video Memory*that tracks video progression across modalities;*\(2\) Adaptive Segment Generation*that switches among generation modes for natural progression and visual consistency; and*\(3\) Hierarchical Test\-Time Self\-Improvement*that self\-improves each segment at frame and video levels to prevent error propagation\. We further introduce**LVBench\-C**, a challenging benchmark with non\-linear entity and environment transitions to stress\-test long\-horizon consistency\. Across public and LVBench\-C benchmarks spanning one\- to ten\-minute videos, A²RD outperforms state\-of\-the\-art baselines by up to 30% in consistency and 20% in narrative coherence\.
## Terminology
TerminologyDescription**Shot**A continuous sequence of frames captured from a single camera angle without cuts\.**Scene**A narrative unit representing continuous action within a single physical environment or location\.**Segment \(Clip\)**The fundamental generation unit in A²RD, which is flexible and can span one or multiple shots or scenes\.**Segment Context \(𝑆ᵢ\)**The textual description dictating the narrative, actions, and settings for the 𝑖\-th segment\.**Storyline \(𝒮\)**The complete sequential collection of segment contexts \{𝑆₁, …, 𝑆ₙ\} defining the full video narrative\.**Extrapolation**A generation mode that synthesizes a video segment moving forward from only a beginning frame\.**Interpolation**A generation mode that synthesizes a video segment to seamlessly connect a fixed beginning and ending frame\.
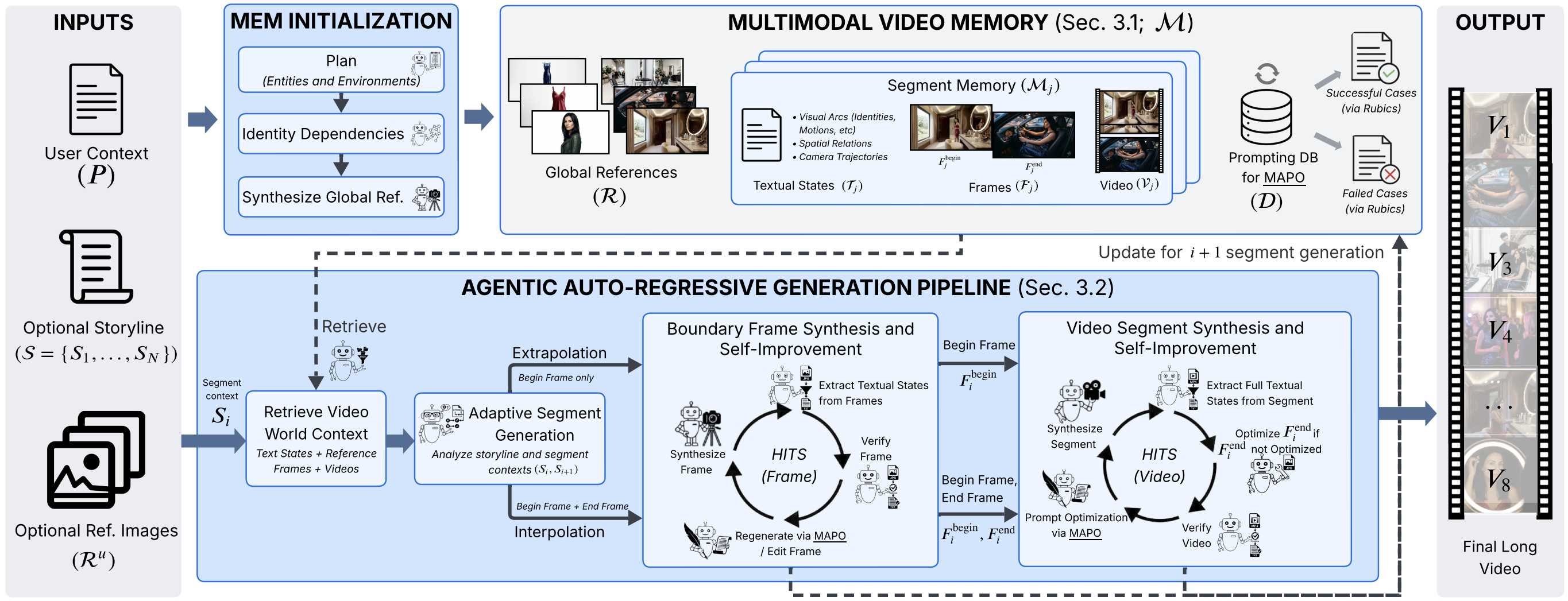
## Method Overview
A²RD enables video diffusion models to synthesize and self\-improve long videos autoregressively, enforcing temporal consistency and narrative coherence\. A²RD is training\-free and built upon three pillars:
- **Multimodal Video Memory**: Existing methods store only visual references, losing narrative context over long horizons\. A²RD stores structured contexts from synthesized segments, disentangling each segment into three modalities:*Textual States*\(entity identities, attribute changes, motions, spatial relations, camera trajectories\),*Frames*\(global references and boundary keyframes\), and*Videos*\(full segments for motion continuity\)\. Online Retrieve and Update operations are enabled for synthesis\.
- **Adaptive Segment Generation**: Prior studies adopt either extrapolation or interpolation as a fixed generation mode\. Extrapolation enables natural progression but risks semantic drift; interpolation enforces stronger consistency but risks unnatural video progression when end frames are poorly planned\. A²RD adaptively selects the mode per segment to enable both natural video progression and strong consistency enforcement\.
- **Hierarchical Test\-Time Self\-Improvement \(HITS\)**: A single inconsistent frame can cascade artifacts across the entire horizon\. Existing video refinement methods operate only on short clips\. A²RD introduces HITS to self\-improve long videos hierarchically — first boundary frames, then full segments — focusing on intra\- and inter\-segment coherence, and video quality to combat errors propagate uncorrected\.
The workflow proceeds in two stages:
- **Memory Initialization**: The agent reasons over the narrative to identify entities and environments, constructs a dependency graph, and synthesizes global reference frames as a form of long\-term memory\.
- **Autoregressive Segment Synthesis & Self\-Improvement**: For each segment, the agent retrieves context from memory, selects the generation mode, synthesizes boundary frames and video, applies HITS, and updates memory before advancing\.
## Benchmark: LVBench\-C
We introduce**LVBench\-C**\(Long Video Bench\-Challenge\), a challenging benchmark designed to stress\-test temporal consistency under complex scenarios where**entities and environments appear, disappear, and reappear**across long horizons with optional state changes\. LVBench\-C features multi\-shot stories at 3\-minute, 5\-minute, and 10\-minute scales with rich non\-linear entity and environment transitions\.

## SOTA Segment\-Based Long Video Synthesis Baselines
**Single\-scene \(VBench\-Long\):**A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage\. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse\. She wears sunglasses and red lipstick\. She walks confidently and casually\. The street is damp and reflective, creating a mirror effect of the colorful lights\. Many pedestrians walk about\.
**Multi\-scene \(LVBench\-C, 3 minutes, The Scuba Diver's Reef Exploration\):**Prompt below\.
## A²RDSingle\-Scene/Multi\-SceneLong Video Gallery
## A²RD Multi\-Scene Ultra\-Long Video Gallery
\(a\) 3\-minute: The Master Potter's Creation
Scene 1: In a quiet morning living room, a man with a grey ponytail puts on a clean navy blue apron\.
Scene 2: He walks into his kitchen and packs a small wooden crate with various carving tools\.
Scene 3: He exits his house and walks down a cobblestone alleyway toward his art studio\.
Scene 4: Inside the bright studio, he approaches a large bag of wet, grey clay and cuts a large chunk with a wire\.
Scene 5: He carries the heavy clay to a pottery wheel and slams it down onto the center of the bat\.
Scene 6: The man sits at the wheel and begins centering the clay, his hands quickly becoming coated in thick, wet slip\.
Scene 7: As the wheel spins, he pulls the clay upward, forming a tall, elegant vase shape\.
Scene 8: He picks up a wet sponge and smooths the exterior of the vase, grey water dripping onto his apron\.
Scene 9: He uses a metal rib tool to shave the sides, creating a pile of clay shavings around the base\.
Scene 10: The man stops the wheel and uses a thin wire to carefully slice the vase off the spinning head\.
Scene 11: He carries the wet vase into a drying room filled with wooden shelves and sets it down gently\.
Scene 12: He walks to a workbench and picks up a leather\-hard bowl from the previous day to begin carving\.
Scene 13: He uses a fine needle tool to etch intricate patterns into the bowl, clay dust settling on his arms\.
Scene 14: The man carries the carved bowl into a kiln room and carefully places it inside the large industrial kiln\.
Scene 15: He adjusts the digital settings on the kiln and presses the start button to begin the firing process\.
Scene 16: He walks to a glazing station and stirs a bucket of deep blue glaze with a wooden stick\.
Scene 17: He dips a finished, fired plate into the blue liquid, his fingers getting stained with the pigment\.
Scene 18: He sets the glazed plate on a rack to dry, looking at the transformation of the surface\.
Scene 19: The man walks to a large utility sink and begins scrubbing the thick clay from his hands and forearms\.
Scene 20: He removes the navy blue apron, which is now heavily stained with grey clay and blue glaze spots\.
Scene 21: He hangs the apron on a wall hook and picks up his wooden crate of tools\.
Scene 22: He walks back through the cobblestone alley as the evening streetlamps flicker on\.
Scene 23: Entering his home, he places the tool crate on the table and sighs with satisfaction\.
Scene 24: He stands in his living room stretching leisurely, a look of deep satisfaction on his face\.
\(a\) 3\-minute: The Scuba Diver's Reef Exploration
Scene 1: A diver stands on the deck of a boat in the ocean\.
Scene 2: The diver is wearing a black neoprene wetsuit\.
Scene 3: The diver puts on a heavy air tank and harness\.
Scene 4: The diver fastens a weight belt around their waist\.
Scene 5: The diver sits on the edge of the boat deck\.
Scene 6: The diver pulls a rubber mask over their eyes\.
Scene 7: The diver puts a regulator mouthpiece in their mouth\.
Scene 8: The diver falls backward into the blue water\.
Scene 9: The diver sinks beneath the surface of the ocean\.
Scene 10: Bubbles rise from the diver's regulator as they breathe\.
Scene 11: The diver swims down toward a colorful coral reef\.
Scene 12: The diver sees a school of bright tropical fish\.
Scene 13: The diver hovers near a large sea turtle\.
Scene 14: The diver checks the air pressure gauge on their tank\.
Scene 15: The diver begins to swim slowly back to the surface\.
Scene 16: The diver breaks the surface of the water\.
Scene 17: The diver swims to the ladder on the side of the boat\.
Scene 18: The diver climbs up the ladder onto the deck\.
Scene 19: The diver removes the rubber mask from their face\.
Scene 20: The diver takes the regulator out of their mouth\.
Scene 21: The diver removes the heavy air tank and harness\.
Scene 22: The diver enters the boat's cabin and changes into dry clothes\.
Scene 23: The diver hangs the wet wetsuit on a drying rack\.
Scene 24: The boat begins to drive back toward the harbor\.
\(b\) 5\-minute: The Stage Fright \(Clara\)
Scene 1: Clara, wearing an oversized wool sweater and glasses, sits at a piano in a dusty attic\.
Scene 2: Her hair is messy and tied back with a simple rubber band as she hums a melody\.
Scene 3: She stops to scribble notes onto a piece of crumpled sheet music with a pencil\.
Scene 4: Clara wipes a layer of dust off the piano keys, her fingers trembling slightly\.
Scene 5: The grand theater lobby is filled with socialites in tuxedos and evening gowns\.
Scene 6: Ushers in gold\-trimmed uniforms hand out glossy programs to the arriving guests\.
Scene 7: A large poster in the lobby features a silhouette of a pianist with the name 'CLARA' in bold\.
Scene 8: Stagehands move a massive black grand piano into the center of the stage\.
Scene 9: The conductor of the orchestra adjusts his baton, looking at his pocket watch\.
Scene 10: The audience begins to file into the rows of red velvet seats, whispering in anticipation\.
Scene 11\-40: \[Full 40\-scene narrative continues\.\.\.\]
\(c\) 10\-minute: The Great Museum Heist
Scene 1: Victor and Saffron sit in a dim basement, wearing casual hoodies and jeans\.
Scene 2: They study a holographic blueprint of the Royal Museum, glowing blue on the table\.
Scene 3: Saffron points to the laser grid in the North Gallery, her eyes narrow and focused\.
Scene 4: Victor checks the internal mechanism of a miniature glass\-cutting device\.
Scene 5: They clink two mugs of cold coffee together, finalizing their silent pact\.
Scene 6: The Royal Museum stands majestic under the moonlight, guarded by tall stone lions\.
Scene 7: A security guard walks his patrol, the beam of his flashlight cutting through the dark\.
Scene 8: The museum's grand clock strikes midnight, the sound echoing through the empty streets\.
Scene 9\-80: \[Full 80\-scene narrative continues\.\.\.\]
## Citation \(BibTeX\)