@murage_kibicho: I added a neural sorting algorithm. It builds on the reparametarization trick from Stable diffusion! It's called a Gumb…
Summary
A Python implementation of the Gumbel-Sinkhorn neural network for sorting lists of numbers, based on the 2018 paper by Mena et al.
View Cached Full Text
Cached at: 06/28/26, 06:13 PM
I added a neural sorting algorithm. It builds on the reparametarization trick from Stable diffusion! It’s called a Gumbel-Sinkhorn network. Let’s get this money! https://leetarxiv.substack.com/p/gumbel-sinkhorn-neural-sort…
Python to sort numbers using Gumbel-Sinkhorn architecture.
Source: https://leetarxiv.substack.com/p/gumbel-sinkhorn-neural-sort
Quick Summary
We train a neural network in Python to sort lists of numbers using the Gumbel-Sinkhorn architecture from the original 2018 paper.
 Abstract for the paperLearning Latent Permutations with Gumbel-Sinkhorn Networks(Mena et al., 2018)
The paperLearning Latent Permutations with Gumbel-Sinkhorn Networks(Mena et al., 2018)1introduces a network architecture that learns to sort data without explicit labels.
Abstract for the paperLearning Latent Permutations with Gumbel-Sinkhorn Networks(Mena et al., 2018)
The paperLearning Latent Permutations with Gumbel-Sinkhorn Networks(Mena et al., 2018)1introduces a network architecture that learns to sort data without explicit labels.
Sinkhorn-Knoppis a matrix-balancing algorithm that generates softmax-like probabilities. We covered it in detailearlier:
 Belief propagationalgorithm is a gradient-descent alternative that uses sinkhorn-knopp to solve sudoku with machine learning:
Belief propagationalgorithm is a gradient-descent alternative that uses sinkhorn-knopp to solve sudoku with machine learning:

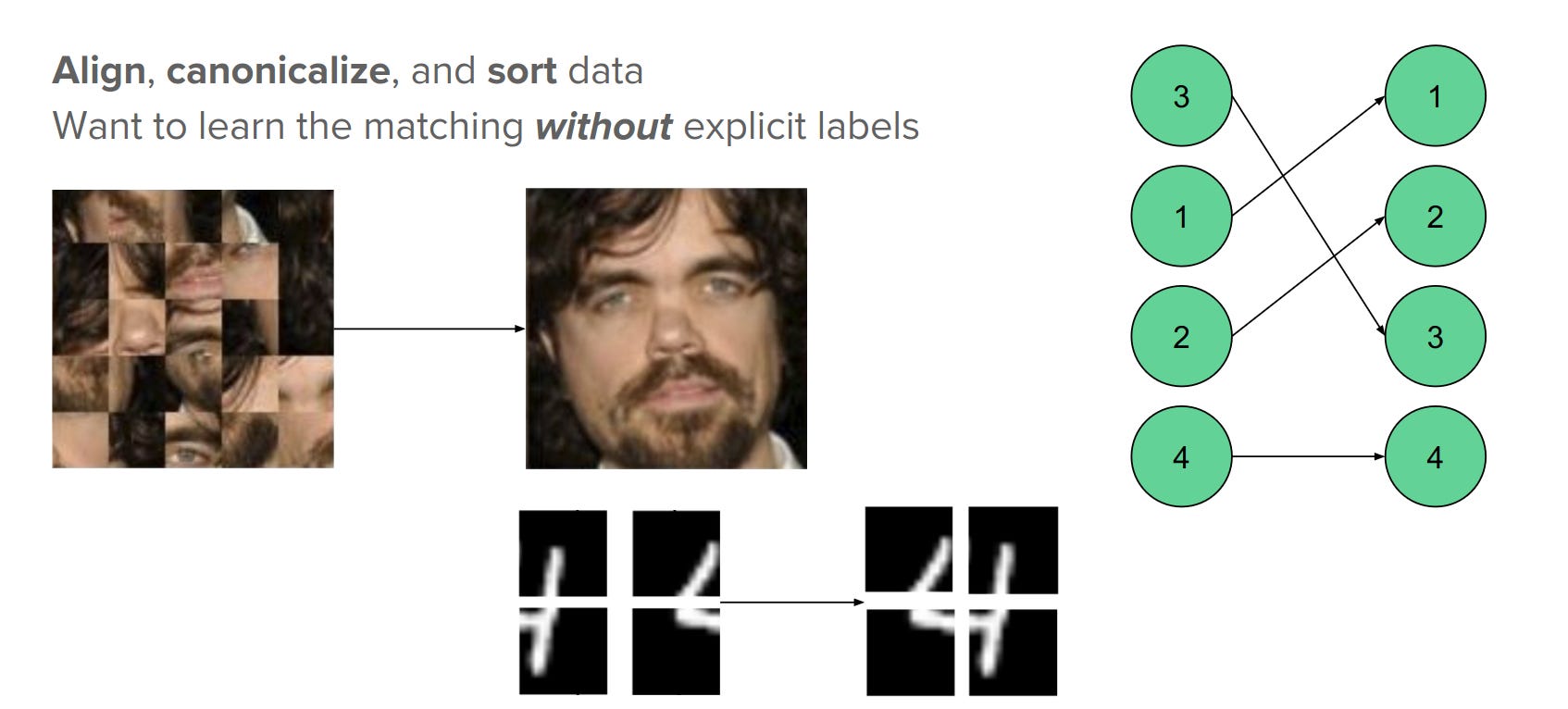 Gumbel-Sinkhorn networks used to solve jigsaw puzzles and find correct permutations. Taken from (Fulton & Evans, 2026)
(Mena et al., 2018) extend these ideas into Gumbel-Sinkhorn networks: neural networks that learn to sort items by differentiation. They build on the fact that permutations can be represented by matrices (Fulton & Evans, 2026)2:
Gumbel-Sinkhorn networks used to solve jigsaw puzzles and find correct permutations. Taken from (Fulton & Evans, 2026)
(Mena et al., 2018) extend these ideas into Gumbel-Sinkhorn networks: neural networks that learn to sort items by differentiation. They build on the fact that permutations can be represented by matrices (Fulton & Evans, 2026)2:
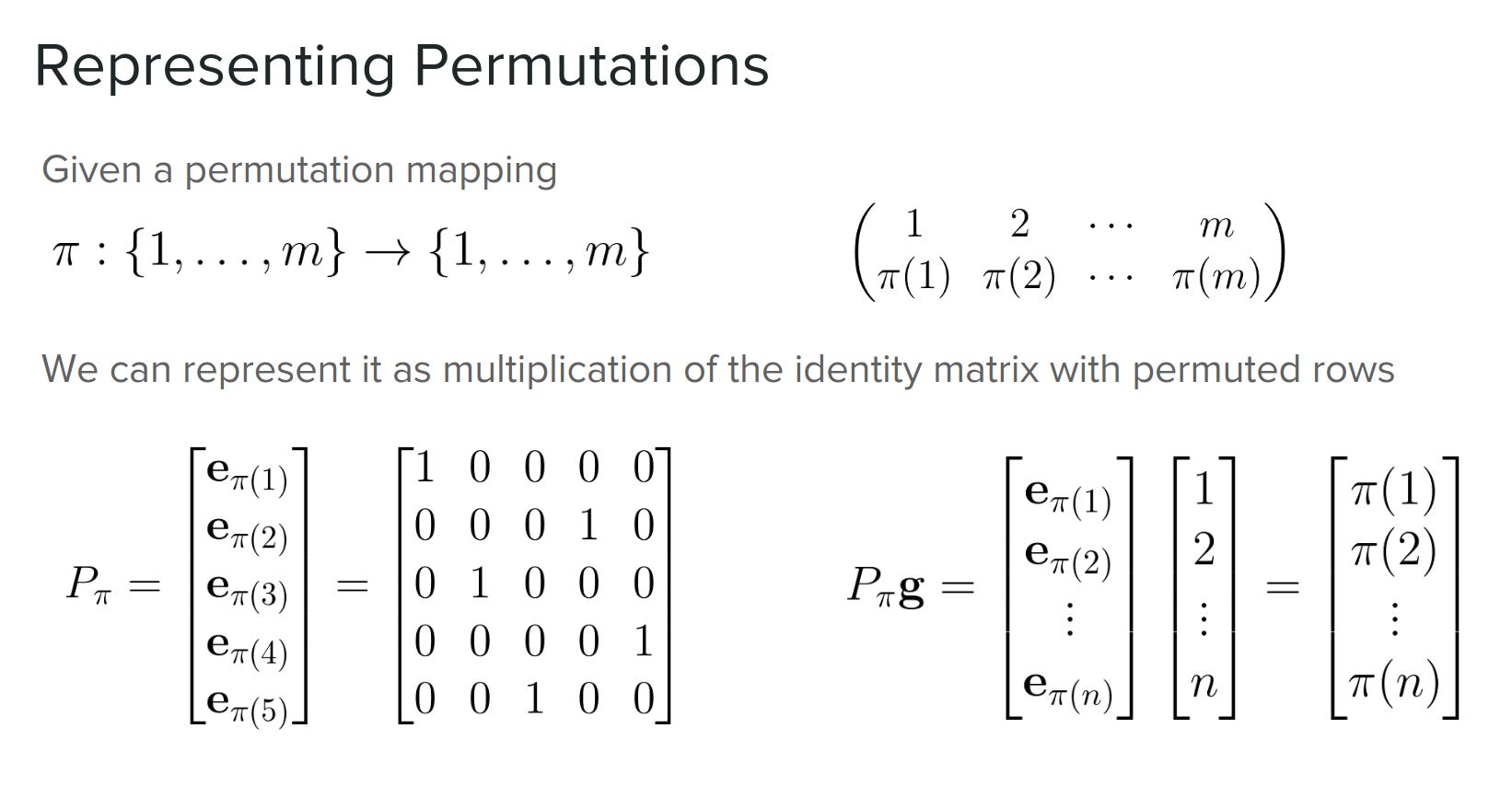 Representing permutations as matrices. Taken from (Fulton & Evans, 2026)
Code is available onGoogle ColabandGitHub.
Representing permutations as matrices. Taken from (Fulton & Evans, 2026)
Code is available onGoogle ColabandGitHub.
First, we’ll code two fundamental concepts introduced in (Mena et al., 2018):
- Sinkhorn operator: a differentiable approximation of a permutation.
- Gumbel-Sinkhorn distribution: an analog of the Gumbel Softmax distribution to permit us perform thereparametarization tricklike in stable diffusion.
 Sinkhorn operator definition. Taken from (Mena et al., 2018)
The Sinkhorn operator is defined over an
Sinkhorn operator definition. Taken from (Mena et al., 2018)
The Sinkhorn operator is defined over anNdimensional square matrixXabove. We went into extreme detailearlier.
Here’s a quick summary (Knigge, 2023)3:
- The Sinkhorn-operator is simply theoriginal 1967 Sinkhorn-knoppalgorithm.
- Inputting an arbitrary matrix into the Sinkhorn-operator should yield adoubly-stochastic matrix: a matrix whose row sums, and column sums equal 1.
- The Sinkhorn-operator is differentiable and permits us approximate a permutation.
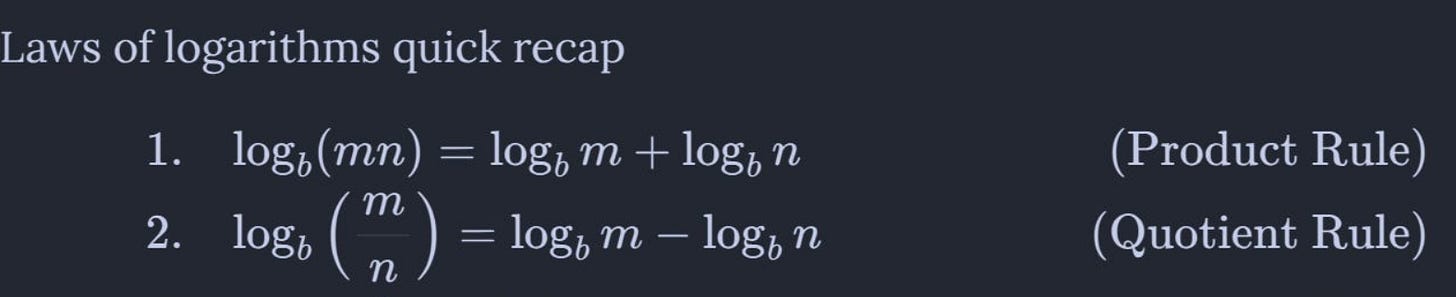 Division is equivalent to subtraction among logarithms. Taken from theFRACTRAN paper.
Division is equivalent to subtraction among logarithms. Taken from theFRACTRAN paper. - Theoriginal 1967 Sinkhorn-knoppalgorithm is unstable due to division, so we tend to use logarithms to subtract instead of divide.
- Theoriginal 1967 Sinkhorn-knoppis analogous to a temperature-dependent softmax. τ is the temperature parameter and when its 0, we obtain a one-hot encoding corresponding to the largest X.
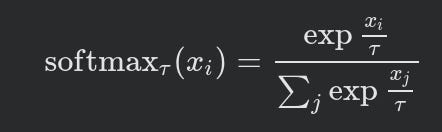 Temperature dependent softmax is equivalent to Sinkhorn-knopp
Temperature dependent softmax is equivalent to Sinkhorn-knopp
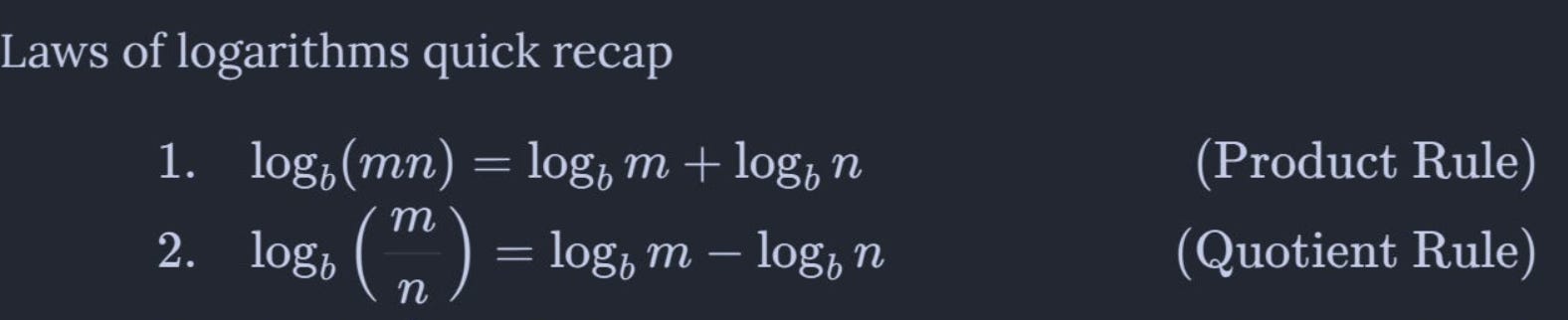
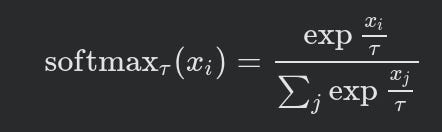
We implement the Sinkhorn-operator in Python, where each iteration is a division (subtraction among logarithms) and use exp to rid us of logs at the end:
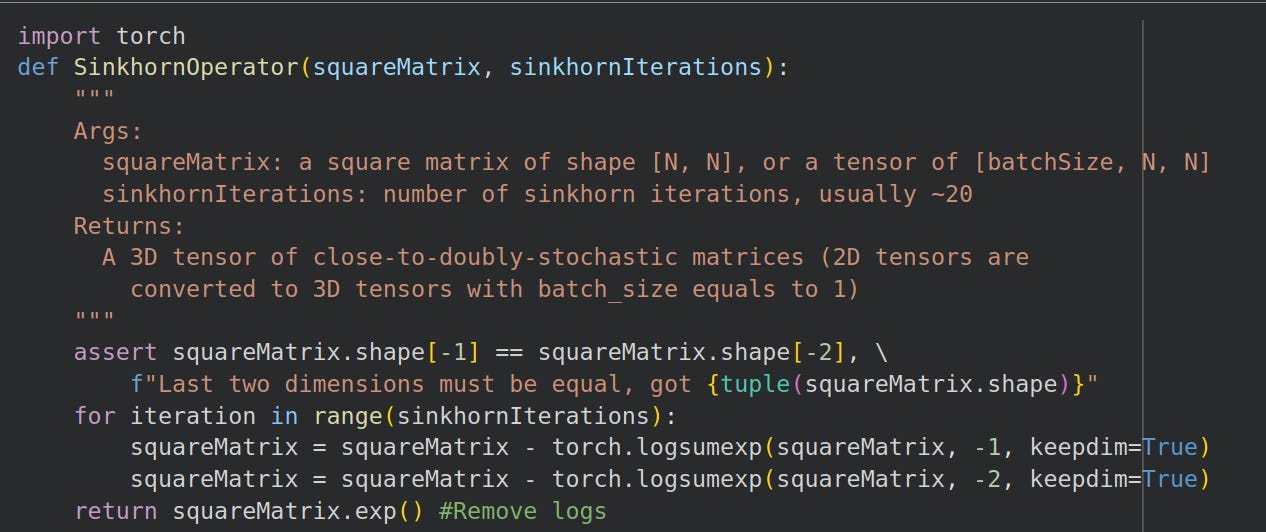 Sinkhorn operator using logarithms.
We write a separate function to verify all row sums and col sums are 1:
Sinkhorn operator using logarithms.
We write a separate function to verify all row sums and col sums are 1:
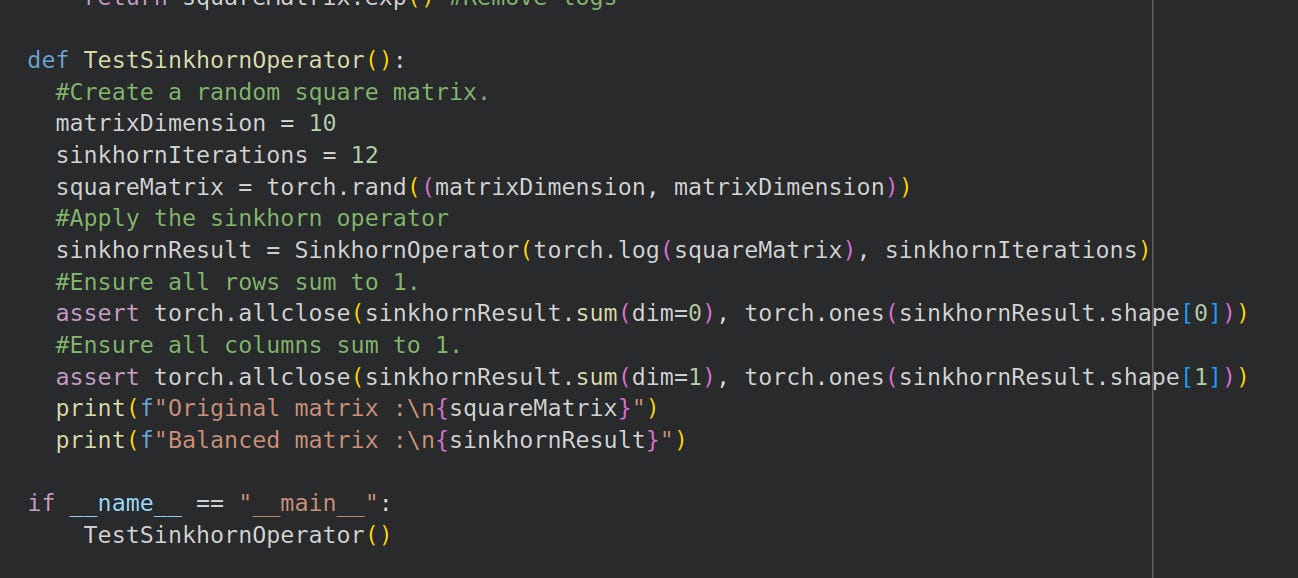 Sinkhorn operator test function
It passes!
Sinkhorn operator test function
It passes!
Thereparameterization trickpermits generating arbitrary noisy input variants during forward diffusion. We saw this in extreme detailearlier:
 (Mena et al., 2018) start from thereparameterization trickand introduce theGumbel-Matchingdistribution: the distribution of permutation matrices we get when applying Gumbel noise to a probability matrix X (Knigge, 2023).
(Mena et al., 2018) start from thereparameterization trickand introduce theGumbel-Matchingdistribution: the distribution of permutation matrices we get when applying Gumbel noise to a probability matrix X (Knigge, 2023).
 Gumbel-Matching distribution. Taken from (Knigge, 2023)
However, (Mena et al., 2018) note that the Gumbel-Matching distribution is undifferentiable due to its discrete nature. So they appeal to Theorem 1:
Gumbel-Matching distribution. Taken from (Knigge, 2023)
However, (Mena et al., 2018) note that the Gumbel-Matching distribution is undifferentiable due to its discrete nature. So they appeal to Theorem 1:
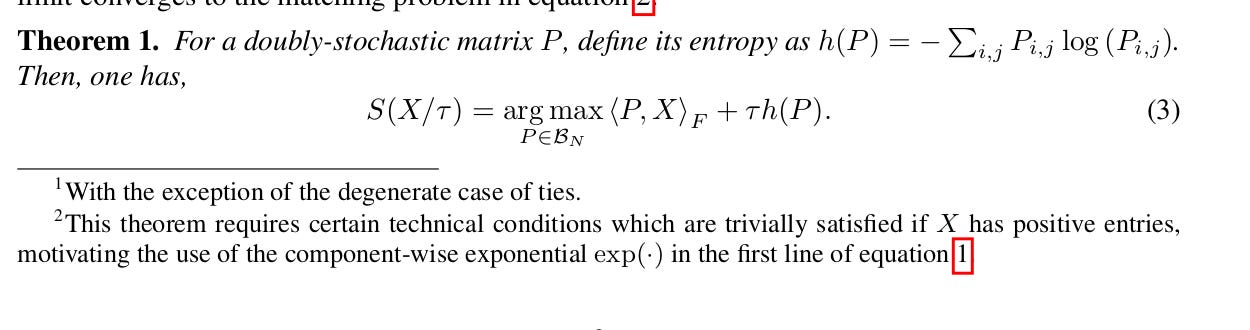 Theorem 1. Taken from (Mena et al., 2018)
Theorem 1 guides one derive the Gumbel-Sinkhorn distribution: a continuous relaxation of the discrete Gumbel-Matching distribution.
Theorem 1. Taken from (Mena et al., 2018)
Theorem 1 guides one derive the Gumbel-Sinkhorn distribution: a continuous relaxation of the discrete Gumbel-Matching distribution.
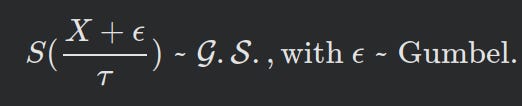 Gumbel-Matching distribution. Taken from (Knigge, 2023)
TheGumbel-Sinkhorn distributionis the distribution obtained by applying the Sinkhorn-operator on an unnormalized assignment probability matrix to which we add Gumbel noise (Knigge, 2023). This is differentiable lol!
Gumbel-Matching distribution. Taken from (Knigge, 2023)
TheGumbel-Sinkhorn distributionis the distribution obtained by applying the Sinkhorn-operator on an unnormalized assignment probability matrix to which we add Gumbel noise (Knigge, 2023). This is differentiable lol!
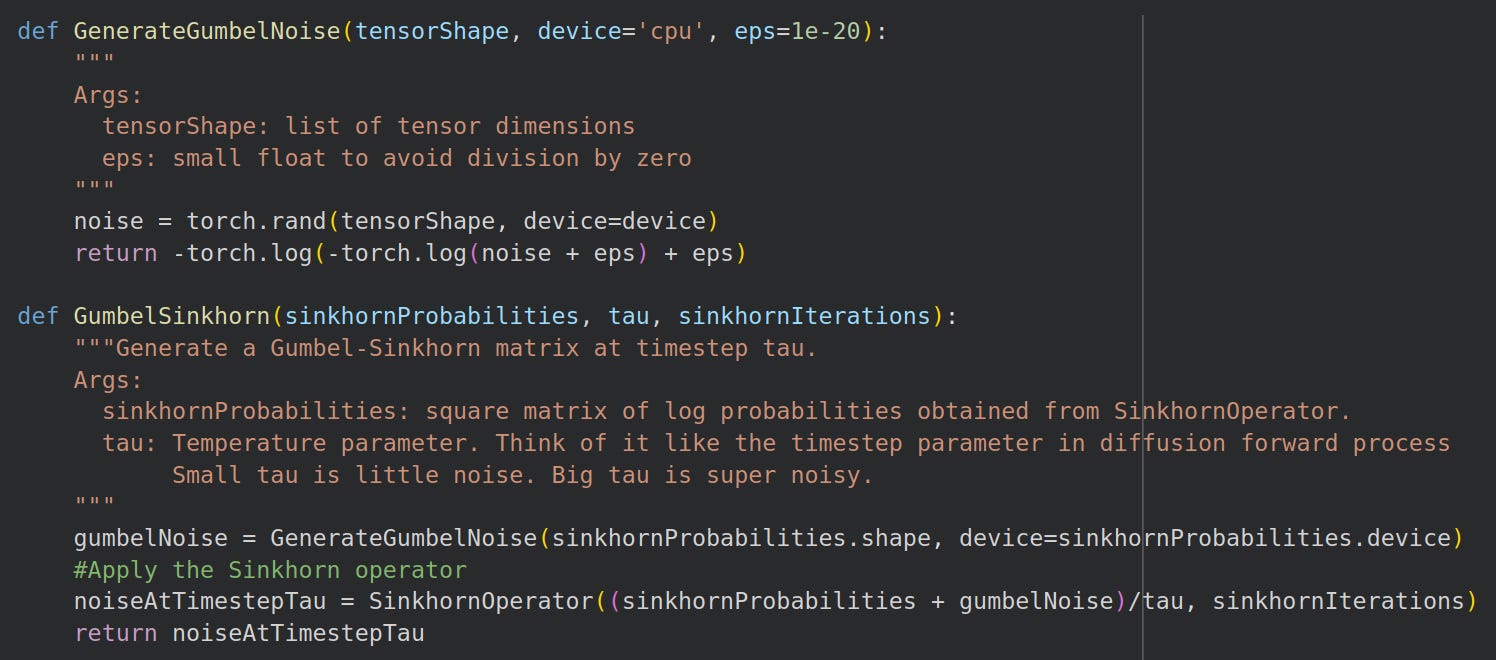
Python code to achieve this is:
 Generate Gumbel noise and draw from a Gumbel-Sinkhorn distribution in Python
Gumbel-Sinkhorn networks build on the Sinkhorn-operator and Gumbel-Sinkhorn sampler. Our guide trains a simple MLP to sort an array of floating-point numbers in ascending order.
Generate Gumbel noise and draw from a Gumbel-Sinkhorn distribution in Python
Gumbel-Sinkhorn networks build on the Sinkhorn-operator and Gumbel-Sinkhorn sampler. Our guide trains a simple MLP to sort an array of floating-point numbers in ascending order.
 Number generator class
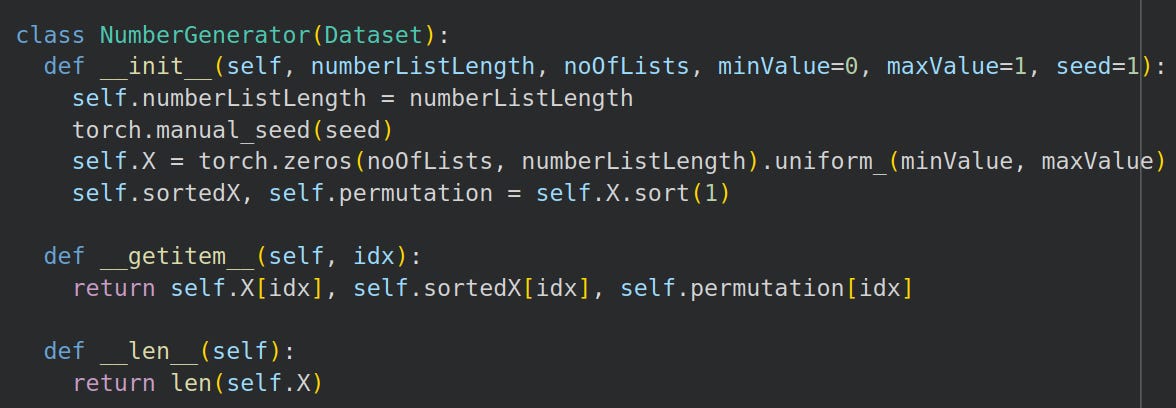
Next, we write a matching function that converts a square matrix of log probabilities into a hard permutation matrix, ie, each row has exactly one 1:
Number generator class
Next, we write a matching function that converts a square matrix of log probabilities into a hard permutation matrix, ie, each row has exactly one 1:
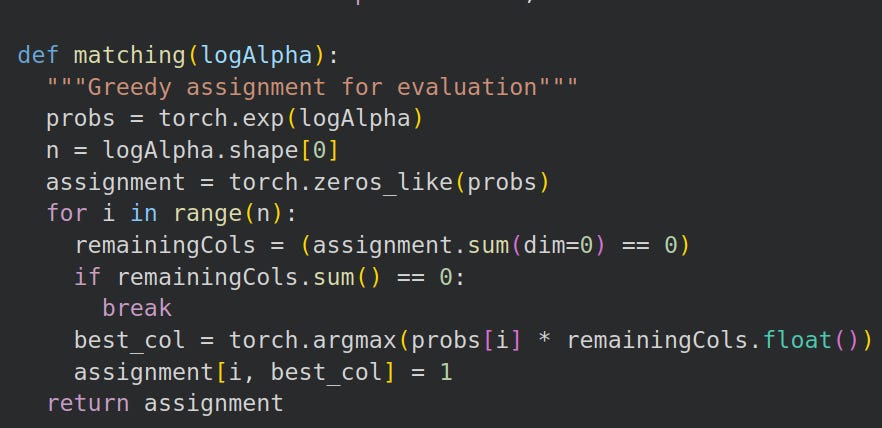 Greedy matching function
We proceed to write a sorting MLP. Observe that we train from the Gumbel-Sinkhorn distribution but evaluate using the matching algorithm:
Greedy matching function
We proceed to write a sorting MLP. Observe that we train from the Gumbel-Sinkhorn distribution but evaluate using the matching algorithm:
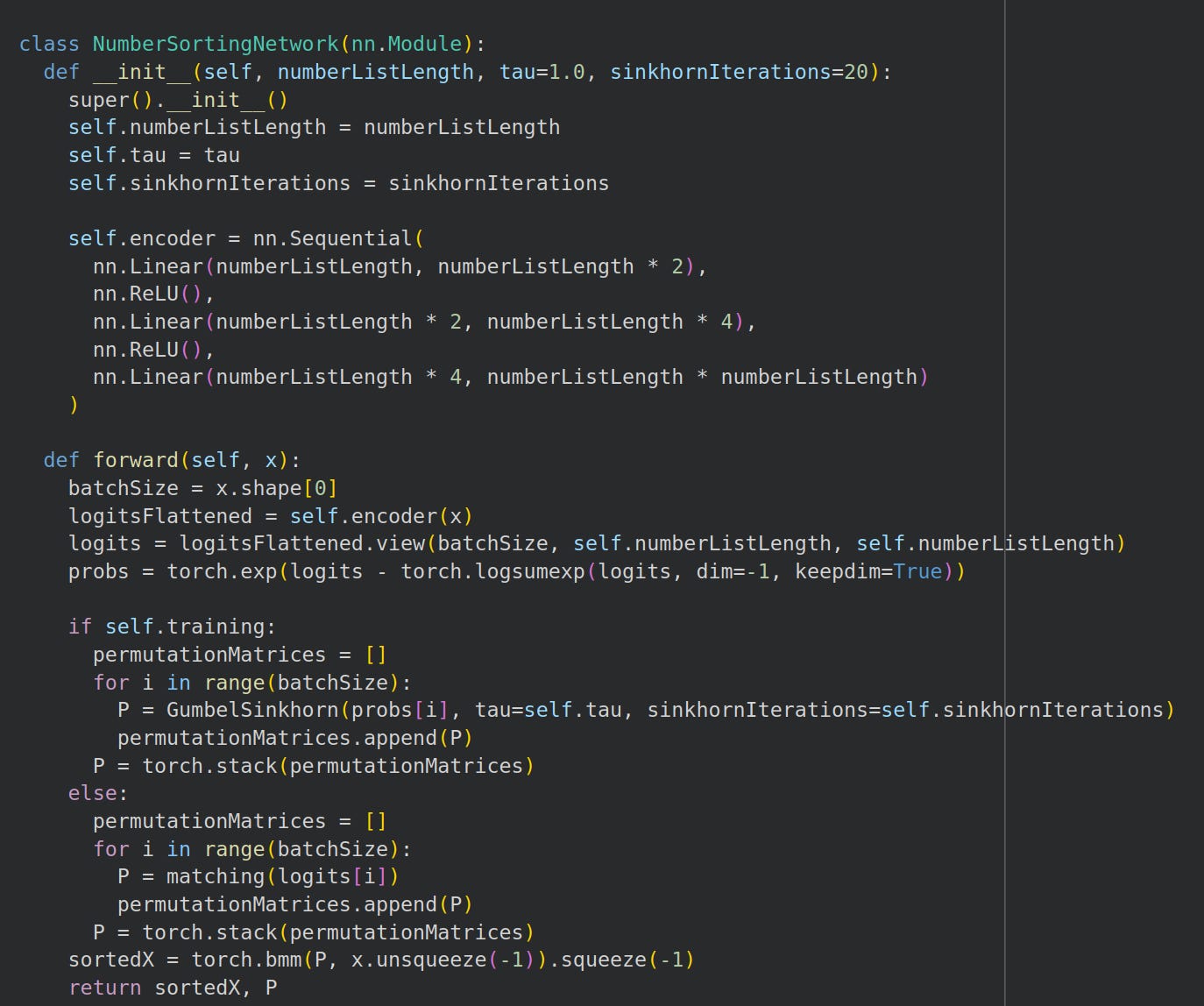 Sorting network with forward pass logic
Finally, we write training and eval code:
Sorting network with forward pass logic
Finally, we write training and eval code:
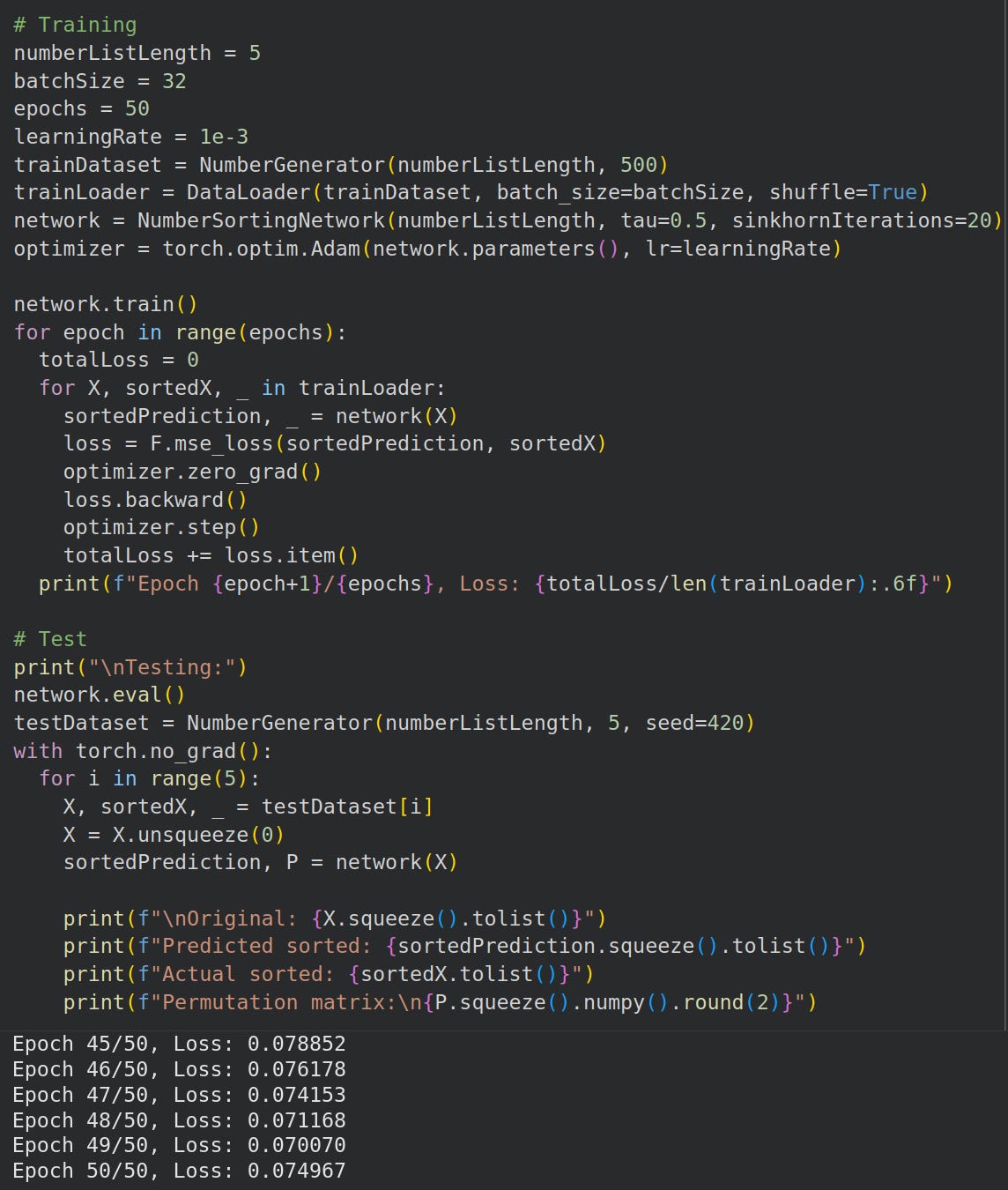 Training and eval code
Let’s observe some results:
Training and eval code
Let’s observe some results:
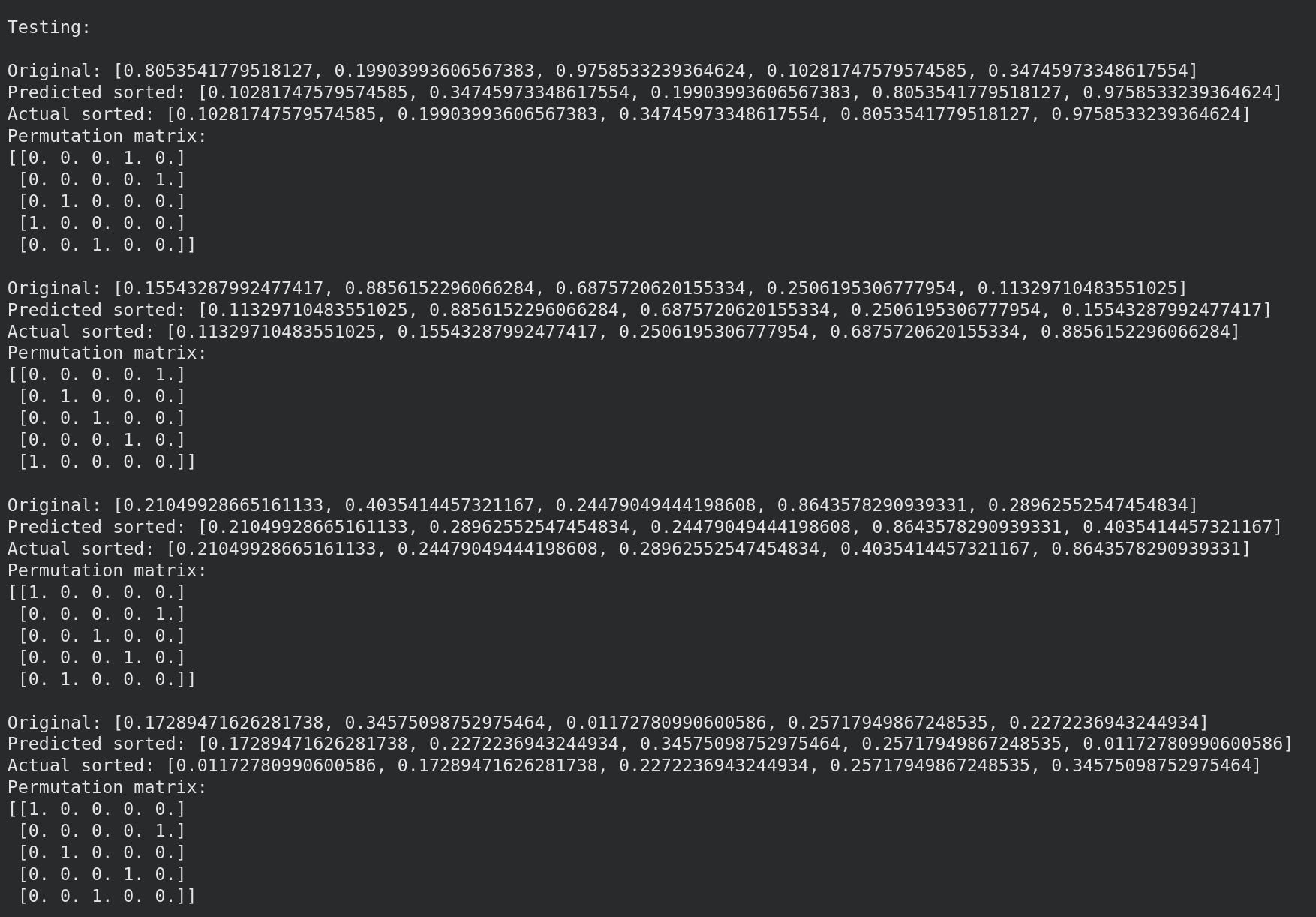 Hurray! Our network learned to sort numbers in ascending order
This section is for the curious. We cover:
Hurray! Our network learned to sort numbers in ascending order
This section is for the curious. We cover:
1. Backprop Sinkhorn iterations without autograd.
2. Converting a doubly stochastic matrix into a permutation matrix.
Backprop is super straight forward. We simply subtract the exponent of the output from the gradient sum:
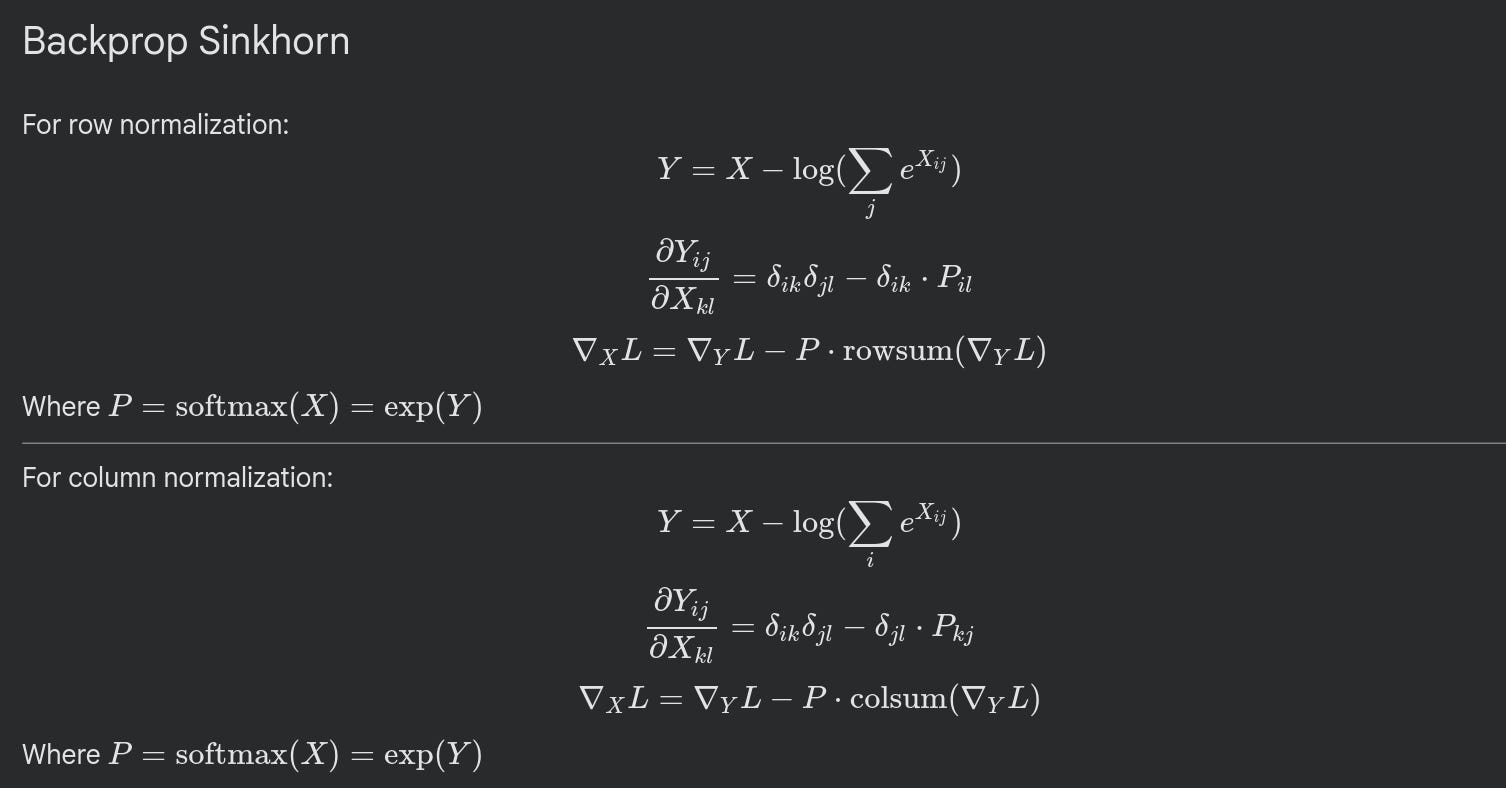 Backprop derivation
We need to save each normalized row and col to achieve this however. So training’s forward and backward pass resemble:
Backprop derivation
We need to save each normalized row and col to achieve this however. So training’s forward and backward pass resemble:
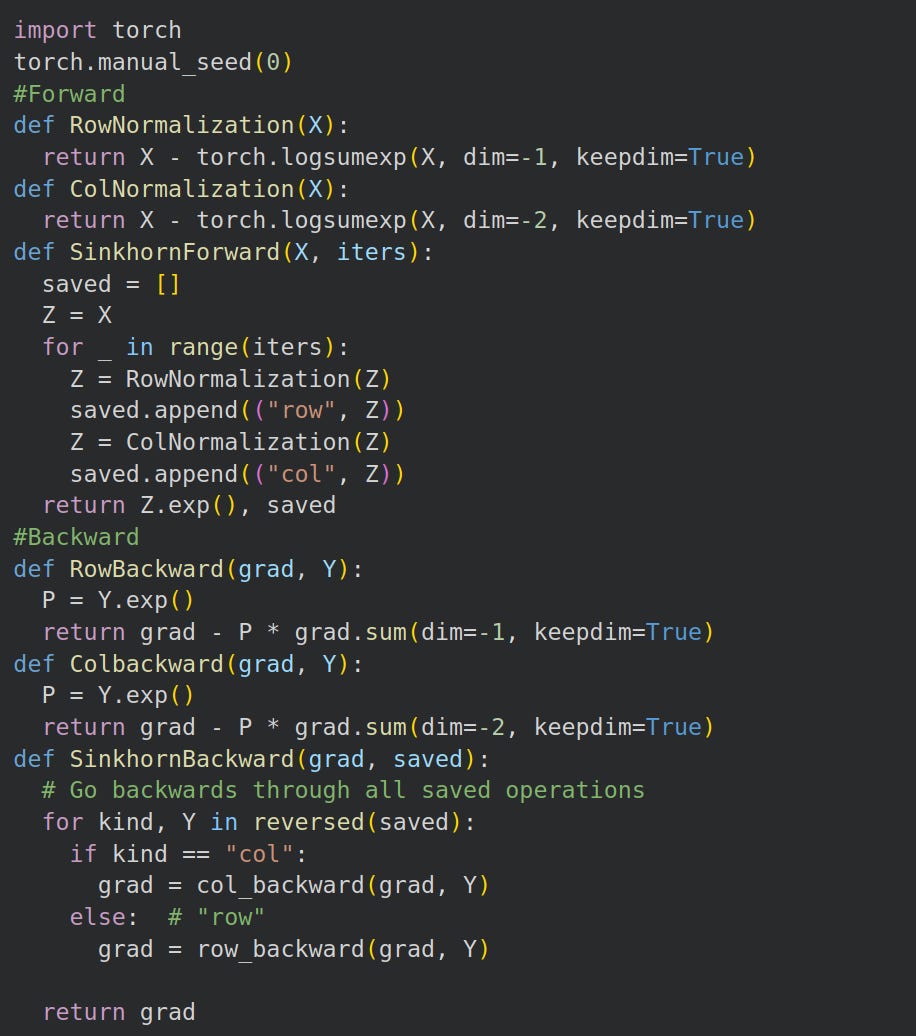 Training Forward and Backward
Our hardcoded backprop matches Pytorch’s autograd:
Training Forward and Backward
Our hardcoded backprop matches Pytorch’s autograd:
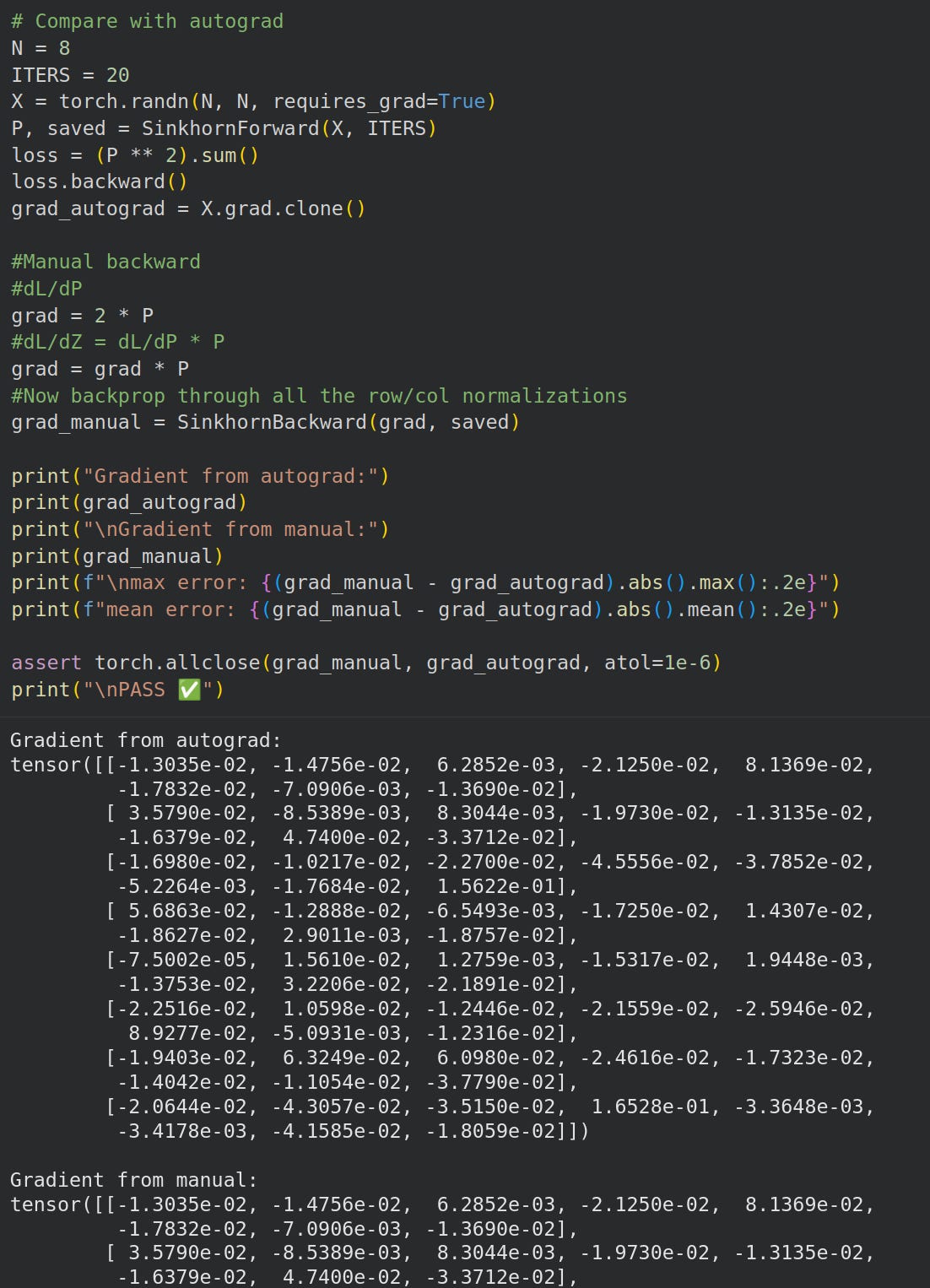 Hardcoded gradients match Pytorch
(Mena et al., 2018) draw a parallel between linear assignment problems and and the choice of a permutation matrix P given a doubly stochastic square matrix (Knigge, 2018).
Hardcoded gradients match Pytorch
(Mena et al., 2018) draw a parallel between linear assignment problems and and the choice of a permutation matrix P given a doubly stochastic square matrix (Knigge, 2018).
 Motivation for the matching function
It builds on three important ideas:
Motivation for the matching function
It builds on three important ideas:
- Permutation matrices are orthogonal.
- The inverse of an orthogonal matrix is its transpose.
- The best-corresponding permutation matrix
Pfor a doubly-stochastic matrixXis the permutation that maximizes trace* of(PTX). *Trace is the sum of eigenvalues of a matrix.
In Python, using Scipy, this resembles:
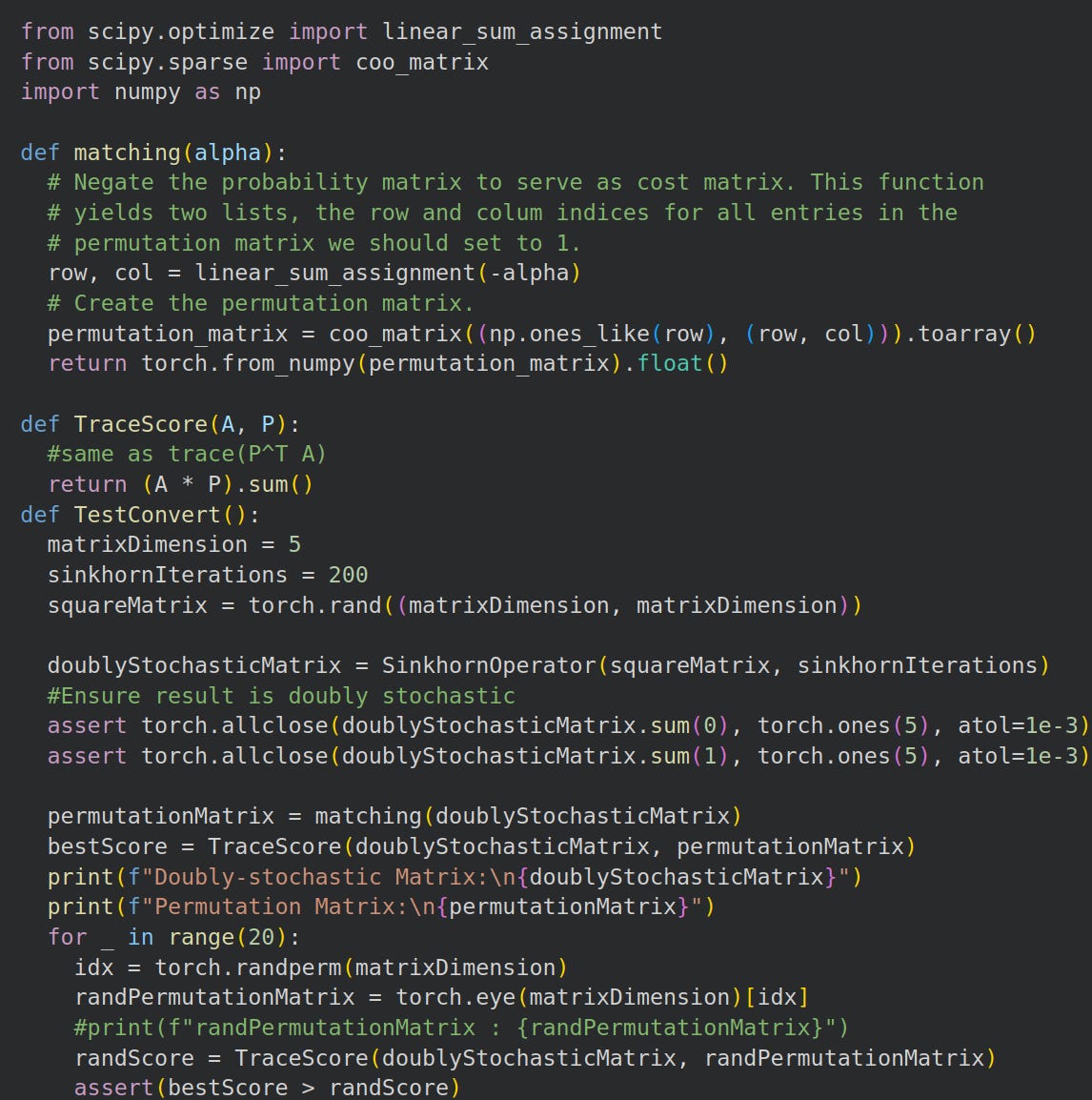 Linear assignment with Trace score tests
Linear assignment with Trace score tests
אגי-e/acc (@murage_kibicho): My weekend sideproject is turning a text diffusion model into a data compressor lol. I don’t think it’ll work but then again ?
Similar Articles
Number-aware embeddings
A technique to make embedding models aware of number ordering by overriding tokenizer and MLM fine-tuning, achieving 59% accuracy on number sorting benchmarks.
15 sorting algorithms in 6 minutes (2013) [video]
A 2013 video visualizing and audibilizing 15 sorting algorithms in 6 minutes, including selection sort, quick sort, and bogo sort.
Geometry-Aware Tabular Diffusion
Introduces Geometry-Aware Tabular Diffusion (GATD), which augments tabular diffusion denoisers with explicit pairwise geometric features. Achieves state-of-the-art performance on ten benchmarks while using significantly fewer parameters.
@JeanRemiKing: Introducing NeuralSet: a simple, fast, scalable Python package for Neuro-AI pip install neuralset https://kingjr.github…
NeuralSet is a new Python package that provides fast, scalable preprocessing and embedding tools for multimodal neuro-AI data including fMRI, EEG, MEG, ECoG, spikes, plus text, audio, video and images.
Graph Mamba Survival Analysis Based on Topology-Aware ordering
This paper proposes TopoMamSurv, a Graph Mamba framework for whole-slide image survival analysis that uses topology-aware ordering to address Mamba's sensitivity to input order, and incorporates bidirectional Mamba and GCN for spatial context modeling.