Cached at:
06/02/26, 03:41 PM
# Rethinking Search as Code Generation
Source: [https://research.perplexity.ai/articles/rethinking-search-as-code-generation](https://research.perplexity.ai/articles/rethinking-search-as-code-generation)
Search is a core primitive for AI systems\. Frontier models grow more capable by the month, but they still need access to fresh, accurate, and well\-curated knowledge from the wider world\. Search is the primary way that AI systems tap into that knowledge, and thus a foundational component of any product that needs to draw conclusions, take actions, and perform real\-world work\.
We believe that traditional search pipelines are increasingly outdated in the era of agents\. Traditional search answers queries, but today’s agents complete tasks that can take on countless shapes\. These tasks require agents to define task\-specific retrieval strategies directly within their harnesses\. Within Perplexity Computer, we’ve seen single tasks invoke hundreds or even thousands of retrieval operations within a few minutes: a workflow that is impossible for humans but absolutely natural for agents\.
In this world, search itself must become agentic, with its building blocks accessible directly as SDKs within the agent harness\. We are introducing**Search as Code \(SaC**\) as Perplexity’s new reference search architecture\.
## Introduction
Perplexity's search stack serves thousands of queries each second across our applications and API Platform\. In September 2025, we published the first[architectural overview](https://research.perplexity.ai/articles/architecting-and-evaluating-an-ai-first-search-api)of our search systems\. Constant innovation within these systems has supported the launch of new offerings such as[Search API](https://www.perplexity.ai/hub/blog/introducing-the-perplexity-search-api),[Agent API](https://www.perplexity.ai/hub/blog/agent-api-a-managed-runtime-for-agentic-workflows), and[Computer](https://www.perplexity.ai/products/computer), with self\-improvement loops optimizing the search stack to better serve users with each passing day\.
Traditionally, AI systems have treated search as a monolith: an AI model issues a query, the search engine runs its predefined pipeline, and the model consumes the results as context\. For the most part, this worked fine to address the needs of early AI users\. Given the relative simplicity of their requests, there was no reason to worry about exactly how the search pipeline was designed, or whether the pipeline's architecture was optimal for the task at hand\. The defaults were presumed to be good enough, as were the default interfaces \(function calling and MCPs\)\.
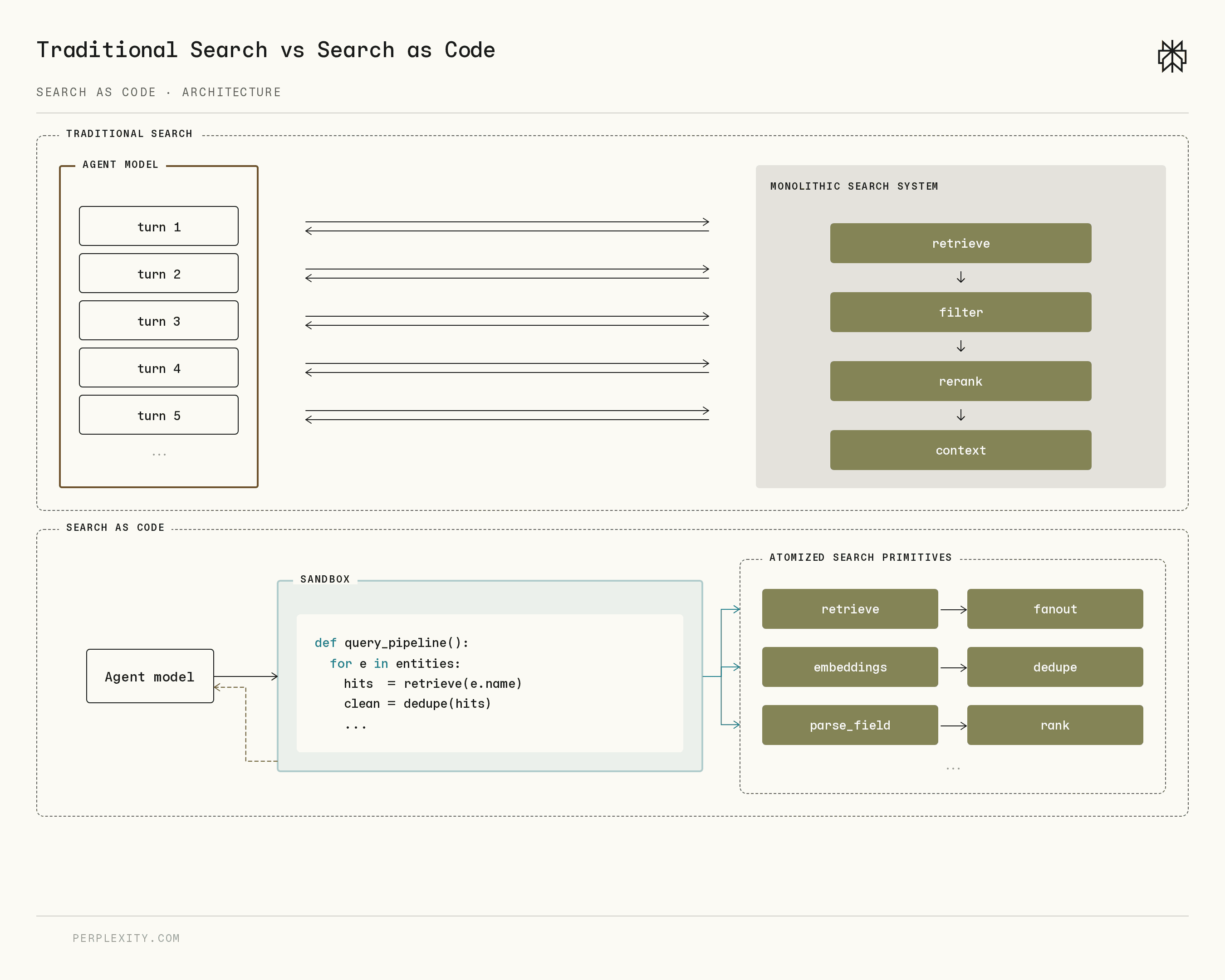
###### Figure 1 \| Traditional search architectures expose a single fixed system that models call serially, while Search as Code exposes atomized search primitives that agents compose through generated code\.
Yet today this approach grows more outdated with each passing month\. Users demand much more than single\-shot analysis from AI\. They expect agents to complete tasks end\-to\-end over hours or even days\. These tasks can be complex, open\-ended, and highly variable in their information needs, and monolithic architectures are buckling under the weight of these demands\.
The key bottleneck is ultimately one of*control\.*Frontier models are already quite good at reasoning over fixed context\. However, the most powerful AI systems will require the ability to steer*how*that context is retrieved, processed, aggregated, and rendered to the model\.
Traditional search systems were not designed with this degree of controllability in mind\. After all, human users cannot be expected to exercise fine\-grained control over search pipeline internals even if it were offered\. Early AI models can control search only through a linear trajectory of function calls and MCPs\. But today's frontier models, driven by code\-capable agent harnesses, can exert fine\-grained control over any computational primitives imaginable through computer code\. Our task becomes to provide the right primitives\.
To meet this need, we are introducing a new search architecture across our products:**Search as Code \(SaC\)\.**This new architecture empowers models to reach*into*the search stack itself rather than merely consume its final outputs\. The core idea is straightforward: we expose the components of the search stack as primitives within an SDK\. For any request that needs search, a model assembles these primitives on\-demand into a retrieval pipeline tailored to that specific request\.
Assembling this pipeline is done through code generation and execution within a secure sandbox\. Unlike other codegen\-driven approaches to search, we do not simply stick a traditional search API within a shell or language runtime\. Instead, we've carefully engineered an Agentic Search SDK that exposes the individual building blocks of search at the most atomic level possible\.
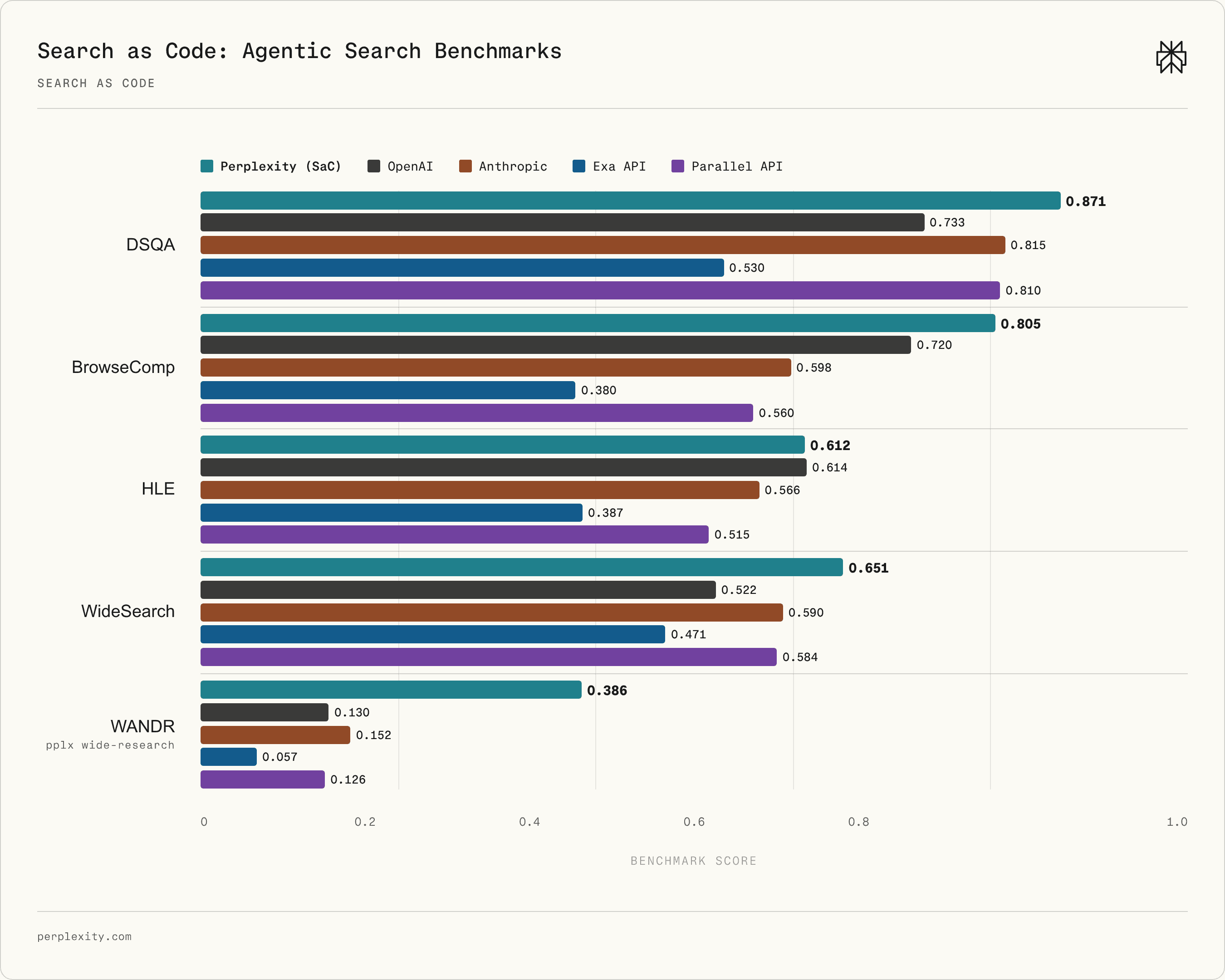
###### Figure 2 \| Search as Code \(SaC\) advances the performance frontier of agentic search across a diverse suite of benchmarks\.
Armed with these building blocks, SaC gives models direct control over each individual search step: retrieval, ranking, filtering, fanouts, rendering, and more\. It also gives the model efficient access to intermediate state such as candidate lists and ranking signals\. Together, these twin levers of control and legibility allow agents to design bespoke search pipelines spanning thousands of retrieval operations, optimize those pipelines in\-flight, and consume only the most useful information as model context\.
This article describes SaC's motivation, design, and implementation, alongside empirical results on both existing and new benchmarks\. SaC establishes a new cost\-performance frontier for agentic search, and we're excited to share it with our users and the broader AI community\.
### The Rigidity of Traditional Search
The world's first search engines were built for human users\. These users came to expect a predictable experience, typically consisting of a fixed number of relevance\-ranked documents\. Users did not want to micromanage the search process; they wanted to enter a query and find a useful result\.
As a result, human\-facing search engines converged on a common monolithic architecture, geared toward producing human\-friendly search engine results pages \(SERPs\) containing the top n hits for an input query\. This pattern has powered decades of progress in consumer search\. It is fast, familiar, and highly effective for human browsing\.
Then came LLMs, and AI systems also became consumers of search\. Perplexity pioneered this shift with the launch of our answer engine in 2022\. Since then, our search engineering efforts have focused on how to optimize the value of search results for AI models\. To build the world's most accurate and reliable AI, we had to engineer a search system focused on making each token as information\-dense as possible\. The resulting innovations in[sub\-document retrieval](https://research.perplexity.ai/articles/query-aware-context-compression-for-better-snippets), context efficiency, semantic understanding, and other key areas led to dramatic improvements in AI systems' ability to retrieve and act on information\.
However, even AI\-optimized systems have largely inherited the same fundamental contract as traditional search engines: accept a query, run a predefined search pipeline, return a fully processed resultset\. For simple requests, this approach works fine\. But for more complex requests, this becomes an increasingly limiting bottleneck that degrades performance, latency, and cost\.
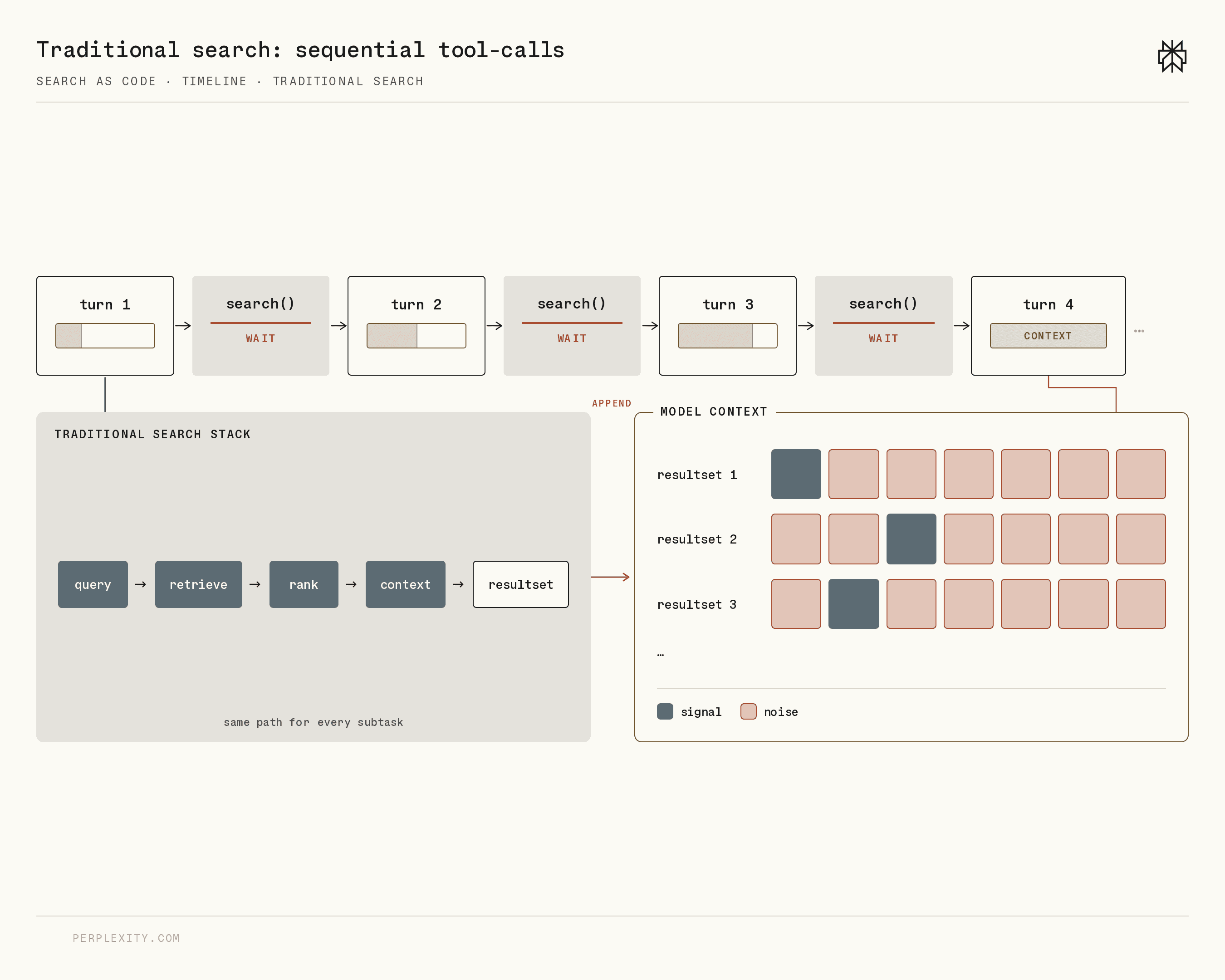
###### Figure 3 \| Traditional search systems force agentic workflows to sequence search through model\-visible turns\. Models must repeatedly call the same search pipelines across different query parameters and introduce all results into model context\.
#### Failure Modes from Rigidity
Traditional search pipelines are designed around a single point of control: the query parameters\. The search engine owns the rest of the pipeline according to its predefined logic, and the model must adapt to it\. To the model, anything downstream of the query parameters is rigid—the shape of the actual computation is outside the model's control\.
This is a sensible boundary when the consumer is a human scanning links\. It is a poor boundary when the consumer is an AI model trying to solve knowledge\-intensive tasks in a closed loop\. In our experience, this rigidity creates three recurring failure modes:
1. **Coarse context\.**AI models are sensitive to the quality and compactness of context\. Both quality and compactness are highly query\-dependent, and monolithic search pipelines are not designed to perform optimally across all queries\. For instance, if a model needs a single, highly surgical piece of information but only has access to an end\-to\-end search endpoint that prioritizes recall, using that endpoint will introduce a large amount of irrelevant information into the model context\. On the other hand, if a model needs many pieces of information that each require different search strategies, it may be forced to serially invoke the same suboptimal pipeline for all of them, resulting in ballooning costs and noisy context\.
2. **Failure to leverage domain knowledge\.**In many cases, the model may have domain knowledge \(from its training, an Agent Skill, memory, or earlier tokens in the LLM trajectory\) that should guide the search strategy\. However, a rigid search interface prevents the model from leveraging that knowledge\. For instance, the model may realize for a specific request that it should blend lexical and semantic signals in a particular way, prioritize certain sources, or aggregate results by a specific key\. Unless those insights happen to be implementable through query parameters, the model cannot actually act on them\.
3. **Inefficient control flow and context pollution\.**Many search workflows are not naturally serial\. They might need fan\-out over query variants, parallel fetching, deduplication, and other operations that require nonlinear and asynchronous control flow\. Forcing these steps through repeated model turns adds latency and makes the workflow harder to optimize\. It also pollutes model context with noisy intermediate state that may not be useful for the model's reasoning, resulting in poorer performance and more frequent compactions\.
Not much could be done about these challenges during the function calling & MCP eras of AI\. When each search operation requires its own roundtrip to LLM inference, developers naturally prefer to get as much done in that roundtrip\. This means end\-to\-end search pipelines that return fully processed resultsets for direct consumption by a model\.
As a result, most AI\-facing search systems today still operate under this monolithic contract\. However, with continued growth in model intelligence and user demands, the shortcomings of that contract become more pronounced\. Today's most advanced AI systems, built atop code\-first harnesses, can compose task\-specific workflows that execute thousands of actions each minute\. Search systems have yet to fully realize this potential\.
We've long suspected that the right boundary for AI\-native search is lower in the stack\. Models should not merely call a search engine\. They should be able to orchestrate the individual pieces of the search stack as the specific task demands\. That requires a fundamentally different architecture\.
### Designing a Programmable Search Architecture
The next generation of search architectures will hinge on a core principle: search should be natively programmable by AI agents\. An agent must not be limited to a set of preordained search pipelines\. Rather, an agent must be able to construct the pipeline that the specific task requires, using composable building blocks designed at varying levels of abstraction\.
Our new Search as Code \(SaC\) architecture embodies this principle\. In SaC, not a single retrieval operation is dispatched through a function calling or MCP interface\. All operations are instead orchestrated via model\-generated Python code\. For the simplest search needs, this code may consist of a handful of requests to a high\-level search endpoint\. But for complex tasks, the code can be as intricate as needed, involving conditional execution, asynchrony, parallelism, and calls to a wide range of low\-level primitives\.
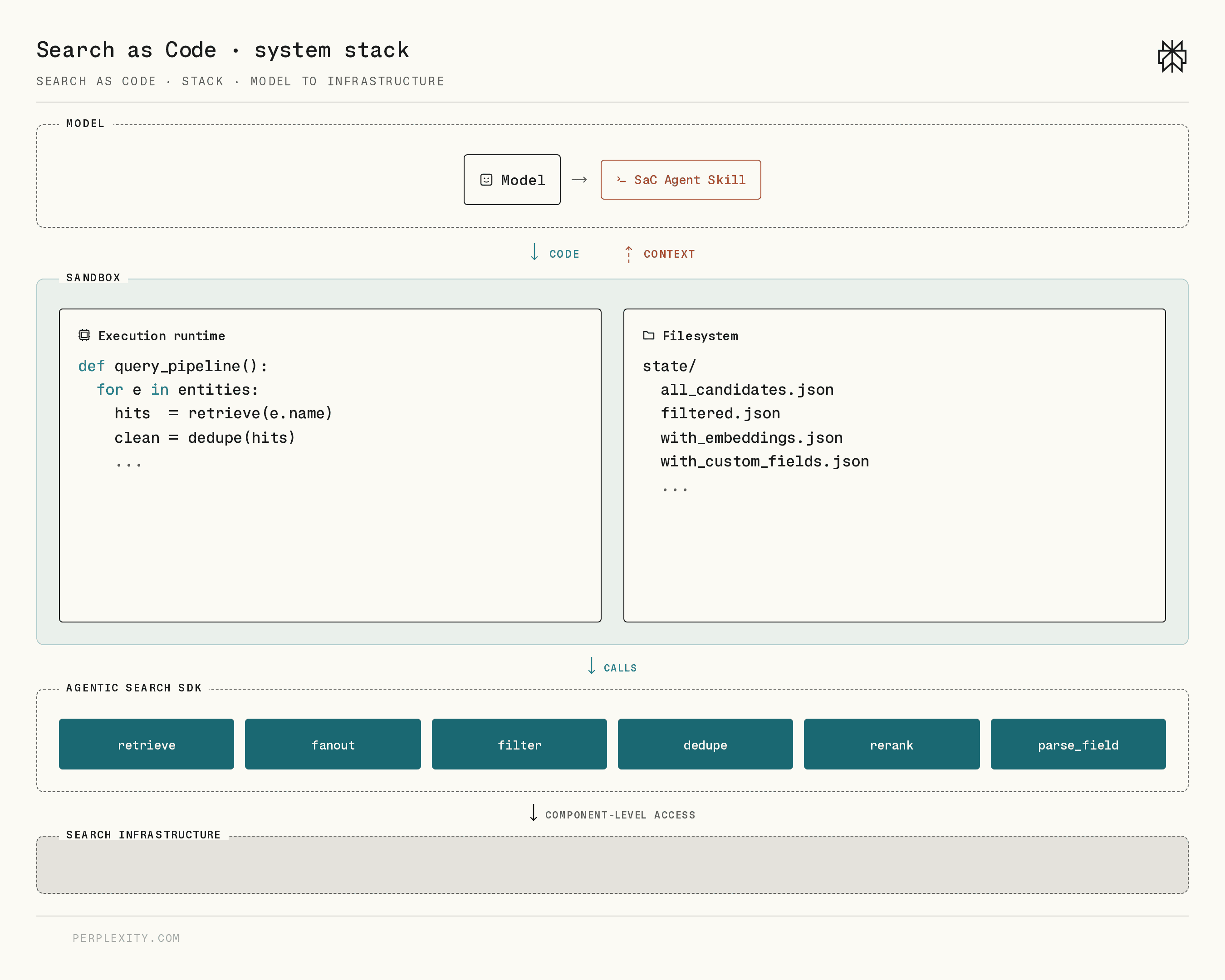
###### Figure 4 \| The Search as Code \(SaC\) architecture relies on a stack comprising models, compute sandboxes, and an Agentic Search SDK sitting atop Perplexity's search infrastructure\.
SaC involves three tightly coupled layers:
1. **Models**serve as the control plane\. They reason about the user's \(or parent agent's\) directive, decompose the directive into tasks, decide which retrieval and processing pipelines are needed for each task, and generate code to implement those pipelines\.
2. **Compute sandboxes**provide deterministic compute through a secure code execution runtime\. They provide a canvas for models to implement control flow, batching, retries, filtering, joining, aggregation, and other deterministic operations\.
3. Our**Agentic Search SDK**exposes Perplexity's search stack as composable primitives\. It provides building blocks from low\-level retrieval operations to high\-level semantic parsing\. The SDK is embedded within the sandboxes' execution runtimes, allowing models to orchestrate up to thousands of operations within a single inference turn\. Below, we discuss our design decisions for each layer\.
#### The Agentic Search SDK
The Agentic Search SDK defines the building blocks for programmable search\. Importantly, our SDK is not a preexisting search API packaged as a library\. Over the past few months, our engineering team has rearchitected our search stack into modular, composable primitives\. We've built the Agentic Search SDK to provide direct access to these primitives, making for a much more powerful canvas on which the model can orchestrate task\-specific retrieval pipelines\.
High\-level, end\-to\-end search pipelines are still available within the SDK, but they are no longer the only option\. Rather, they serve as a form of shorthand for common search patterns\. The model is free to use or bypass them as the task demands\.
**Choice of runtime:**We considered Python, Rust, TypeScript, and Bash as the SDK runtime\. We suspected that Python would be the most natural fit given its ubiquity and ecosystem of data processing libraries\. Internal testing confirmed this to be the case, and the version of the SDK being rolled out today is Python\-based\. We expect to periodically reevaluate the choice of runtime to ensure that it continues to provide the best agent experience\.
**Continual improvement via autoresearch:**We have also optimized the SDK's consumability for frontier LLMs through an iterative autoresearch loop\. This loop, running continuously over weeks, proposes and validates SDK improvements against metrics including latency, codegen quality, and overall task performance\. The autoresearch loop has already made numerous changes to both the structure and aesthetics of the SDK, with significant gains across all dimensions\. We plan to further refine the SDK via autoresearch as new frontier models and search components emerge\.
#### Sandboxes
Sandboxes provide secure environments for defining and running SaC pipelines\. They execute model\-generated code, providing access to the Agentic Search SDK to facilitate interaction with individual search primitives\.
We've made significant investments in optimizing and hardening our sandboxes, and their overarching system design merits an article of its own\. Here, we focus on the design consideration most relevant to SaC: managing intermediate states\.
SaC empowers agents to orchestrate complex pipelines within a single inference turn\. However, certain intermediate states need to be conveyed across turns\. For instance, a model may want to fetch some documents in turn 1, inspect a subsample of those documents in turn 2 to decide what to do next, and then develop a downstream search pipeline to further investigate those documents from turn 3 onwards\. As discussed above, passing intermediate states through token space is not an effective strategy\.
We considered two approaches for managing intermediate states across turns:
**Persistent filesystem \+ explicit serde:**Sandboxes can expose persistent filesystems for models to use across turns\. Models wishing to persist intermediate state can include a serialization step within the generated code for a turn, along with a deserialization step within a subsequent turn \(either for the models' own inspection or for downstream use\)\. The filesystem approach allows models to directly and explicitly control how intermediate state is conveyed across turns\. It also ensures traceability by enforcing explicit identification and persistence of information used by the model\. One downside is the latency & context overhead incurred from generating the serde code, though well\-designed utility functions can mitigate this overhead\.
**REPL:**Alternatively, a sandbox can persist the execution runtime itself across turns in a REPL\-style environment\. This allows models to maintain intermediate state in\-memory without having to serialize it at all, since variables defined or modified in previous turns can simply be referenced by name in subsequent turns\. The REPL approach is more token\-efficient since it avoids the need to generate serde code\. However, the lack of an explicit serialization step may hurt downstream performance for reasons familiar to anyone who's worked with a 100\-cell Jupyter notebook: as the variable namespace becomes cluttered, it becomes more difficult to keep track of what precisely is persisted across turns and why\.
We tested both approaches and found that while they perform similarly in ordinary use, filesystem\-based serde provides better reliability on particularly long trajectories\. We therefore adopt filesystem\-based serde as our solution\. We conjecture that requiring models to convey state declaratively rather than implicitly helps them manage that state more effectively\. This is a tentative finding and we will continue to iterate on both approaches\.
#### Models
The models powering agent harnesses serve as SaC's control plane: dynamically assembling search pipelines from the Agentic Search SDK's building blocks to meet the needs of each task, then dispatching those pipelines as code for sandbox execution\.
Perplexity employs a variety of models within our agent harnesses, and we've found the latest frontier models to be quite effective across the board at general\-purpose code generation\. The main challenge is to induce effective code generation specifically for the Agentic Search SDK\. That is, how can we make models effectively weave together our SDK's building blocks into task\-optimized pipelines?
Unlike a language's standard library, a custom\-built SDK is unlikely to be represented in pretraining data\. Even with the SDK consumability improvements from autoresearch, many models are still trained to interact with search systems through function calls and direct MCP invocation\. These models are unlikely to expertly wield the SDK with source code and autogenerated docs alone\.
To solve this challenge, we've developed highly\-tuned Agent Skills to teach models to effectively harness our SDK\. The initial versions were developed according to Perplexity's design principles for Skills, and then optimized through a dedicated autoresearch loop focused on the same metrics used in SDK optimization\. We also constrain skill size to guard against context bloat, and our final versions have fewer than 2000 tokens in their root`SKILL\.md`files\.
The optimized Skills go beyond listing the SDK's available building blocks \(something that can just as easily be obtained via runtime reflection\)\. The bulk of the tokens are spent providing concise, generalizable guidance and few\-shot examples for composing these blocks into complex patterns\. Armed with these Skills, we observe models effectively leverage the SDK to orchestrate search pipelines that scale to thousands of discrete operations\.
#### Code as Orchestrator and Gap Filler
By combining these layers, SaC changes the relationship between models and the search stack\. In fixed\-pipeline search systems, the model sits above search and interacts with it through a narrow serial caller interface\. In SaC, the model becomes an active participant in orchestrating the search process itself\. All elements of the search stack become directly programmable by the model, with the sandbox and Agentic Search SDK providing the necessary interfaces to those elements\.
But what about capabilities that don't exist natively? Code is a powerful medium for orchestrating preexisting capabilities\. Yet code's power goes beyond orchestration\. It can also serve as a gap\-filler for capabilities that aren't present in the search stack or SDK\. Agents benefit from parsimony, and it would be inefficient for the SDK to cover every potential operation with a dedicated function\. Instead, the SDK provides the most fundamental primitives, and the model can build any additional components on the fly with code\.
Consider, for instance, a complex regex that is not efficiently implementable via the search system's own query syntax\. Without coding capabilities, the model would be forced to generate its best approximation, make a query, and perform token\-space filtering on a very noisy resultset\. With SaC, the model can instead generate a program that makes parallel SDK calls to collect a superset of the desired regex's resultset\. After deduping via the SDK, the model can then write additional code to deterministically narrow the results to the exact regex\. In this way, agents can implement custom search capabilities without bloating the SDK with overly niche subroutines\.
### Case Study: CVE Vendor Advisories
We present a case study based on a real\-world task within our testing suite\. This task asks an agent to identify and characterize over 200 high\-severity CVEs from 2023–2025\. Each record must cite the affected vendor's own advisory, name the product and fix version, and show that the fix version is tied to the specific CVE\.
SaC's answer scored 100% on accuracy, with total token usage dropping 85\.1% relative to the non\-SaC baseline \(from 288\.7K tokens to 42\.9K tokens\)\. The tested non\-Perplexity systems, discussed in more detail in Section 4, all scored lower than 25%\.
We present three stylized code blocks from the trajectory to illustrate how SaC's programmability allows the model to implement effective strategies\.
This first block is pure orchestration\. The generated program starts by encoding the source\-class rule directly into the query plan: only vendor\-owned advisory formats are relevant\. Non\-vendor sources including NVD, MITRE, CVE Details, news stories, CERT pages, and third\-party databases are structurally out of scope\. The exact\-phrase constraints also push search toward pages whose indexed text already contains the precise CVE details needed downstream\.
The second block uses an LLM as an intermediate planning subroutine\. The code summarizes which vendor\-year pairs are producing enough candidate pages, asks for targeted refinements, and validates each proposed query before execution\. This preserves useful patterns from the trajectory, such as site\-scoped exact\-phrase probes and adaptive backfilling, without hardcoding a bespoke CVE\-advisory crawler into the SDK\.
The final block is a result verifier whose logic is entirely defined by the agent via codegen\. While search subroutines can find plausible advisory pages, the task requires a stricter relation: the advisory must bind one CVE to one affected product and one fix version in vendor\-authored text\. The schema makes that relation explicit, so downstream code can dedupe by CVE, reject aggregator URLs, discard weak version evidence, and continue backfilling until the record\-count floor is met\.
### Evaluation Results
We evaluate SaC's effectiveness on a comprehensive benchmark suite, focusing on both absolute performance and the cost\-performance frontier\.
#### Benchmarks and Systems
Our benchmark suite comprises five benchmarks in total, designed to stress test search\-dependent AI workflows across a range of domains, task formats, and complexity levels\. We use four preexisting benchmarks:[DeepSearchQA \(DSQA\)](https://arxiv.org/abs/2601.20975),[BrowseComp](https://arxiv.org/abs/2504.12516),[Humanity's Last Exam \(HLE\)](https://arxiv.org/abs/2501.14249), and[WideSearch](https://arxiv.org/abs/2508.07999)\. For the first three benchmarks \(DSQA, BrowseComp, and HLE\), we report accuracy as the topline metric\. For WideSearch, we report F1 score by row\.
We also use the newly\-developed WANDR benchmark, which focuses on difficult “wide research” tasks requiring careful orchestration of search, compute, and model reasoning\. WANDR is inspired by the knowledge\-intensive professional tasks that Perplexity Computer handles for users\. It iterates on WideSearch and similar benchmarks, but emphasizes more complex tasks and task structures\. We will publish the WANDR benchmark in the coming weeks\.
We evaluate five agent\-based systems\. We consider individual runs rather than “best\-of\-N” scores in order to isolate the performance of the underlying architecture rather than the benefits of parallelization\. Each system's configuration is described below:
**Perplexity \(SaC\):**We evaluate the SaC architecture within Perplexity's production Agent API\. GPT 5\.5 \(high reasoning\) serves as the underlying model\.
**OpenAI:**We evaluate the OpenAI Responses API with both search`\(web\_search\)`and Python runtime`\(code\_interpreter\)`enabled\. GPT 5\.5 \(high reasoning\) serves as the underlying model\.
**Anthropic:**We evaluate Anthropic Managed Agents with the 20260401 agent toolset and auto\-allowed commands\. Opus 4\.7 \(high reasoning\) serves as the underlying model\.
**Exa:**We evaluate Exa Agent via the production API, with effort set to high\.
**Parallel:**We evaluate Parallel Tasks via the production API, with the processor set to ultra4x\.
#### Comparative Performance
Table 1 reports benchmark scores for each system\. SaC outperforms all other systems on four of the five benchmarks\. On the remaining benchmark \(HLE\), SaC is essentially tied for first place with OpenAI Responses\. Figure 2 from the Introduction visualizes these scores in graphical form\.
Benchmark
Perplexity \(SaC\)
OpenAI
Anthropic
Exa
Parallel
DSQA
**0\.871**
0\.733
0\.815
0\.530
0\.810
BrowseComp
**0\.805**
0\.720
0\.598
0\.380
0\.560
HLE
0\.612
**0\.614**
0\.566
0\.387
0\.515
WideSearch
**0\.651**
0\.522
0\.590
0\.471
0\.584
WANDR
**0\.386**
0\.130
0\.152
0\.057
0\.126
###### Table 1 \| Benchmark scores for each evaluated system\. Best score per row in bold\.
Although SaC achieves state\-of\-the\-art performance across the benchmark suite, its advantage is particularly pronounced on WANDR\. Figure 5 breaks down the WANDR scores, showing that Perplexity's SaC implementation outperforms the next\-best system by a factor of 2\.5×\. Despite this large margin, WANDR remains unsaturated and proves challenging even for SaC\. We believe the complex, highly horizontal search workflows required by WANDR's tasks will require additional advances in research and search engineering to achieve consistently high performance\.
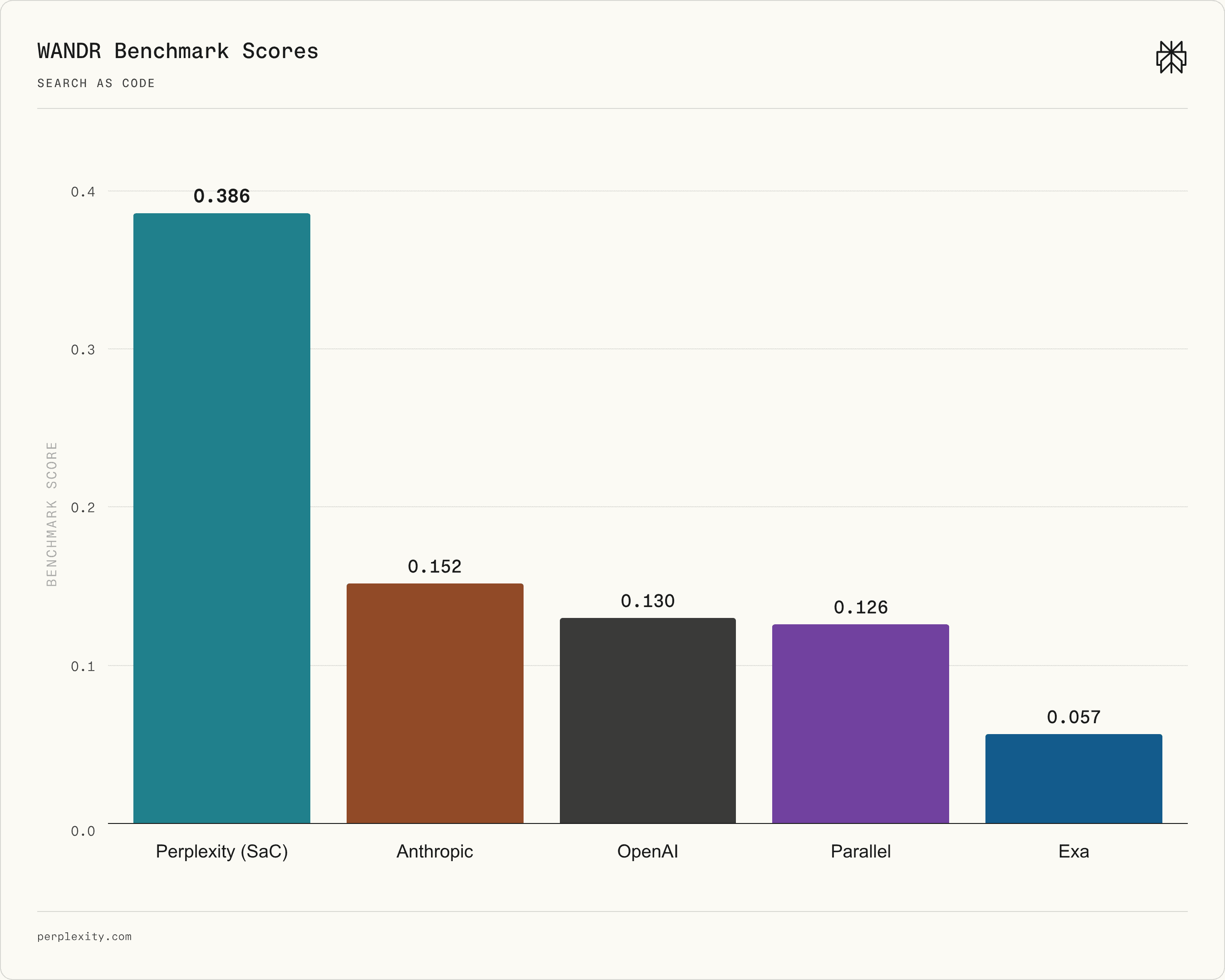
###### Figure 5 \| WANDR scores across evaluated systems\. Perplexity Agent API leads the next\-best system by a factor of 2\.5×\.
Finally, we measure the relative gains of SaC versus a more traditional search pipeline that leverages the same Perplexity search infrastructure\. Figure 6 reports the difference in scores between the SaC and non\-SaC architectures across each benchmark\. Across the board, SaC provides a substantial boost in performance, with the largest absolute gain on DSQA \(\+19\.77 pp, 29%\) and the largest relative gain on WANDR \(\+12\.00 pp, 45%\)\.
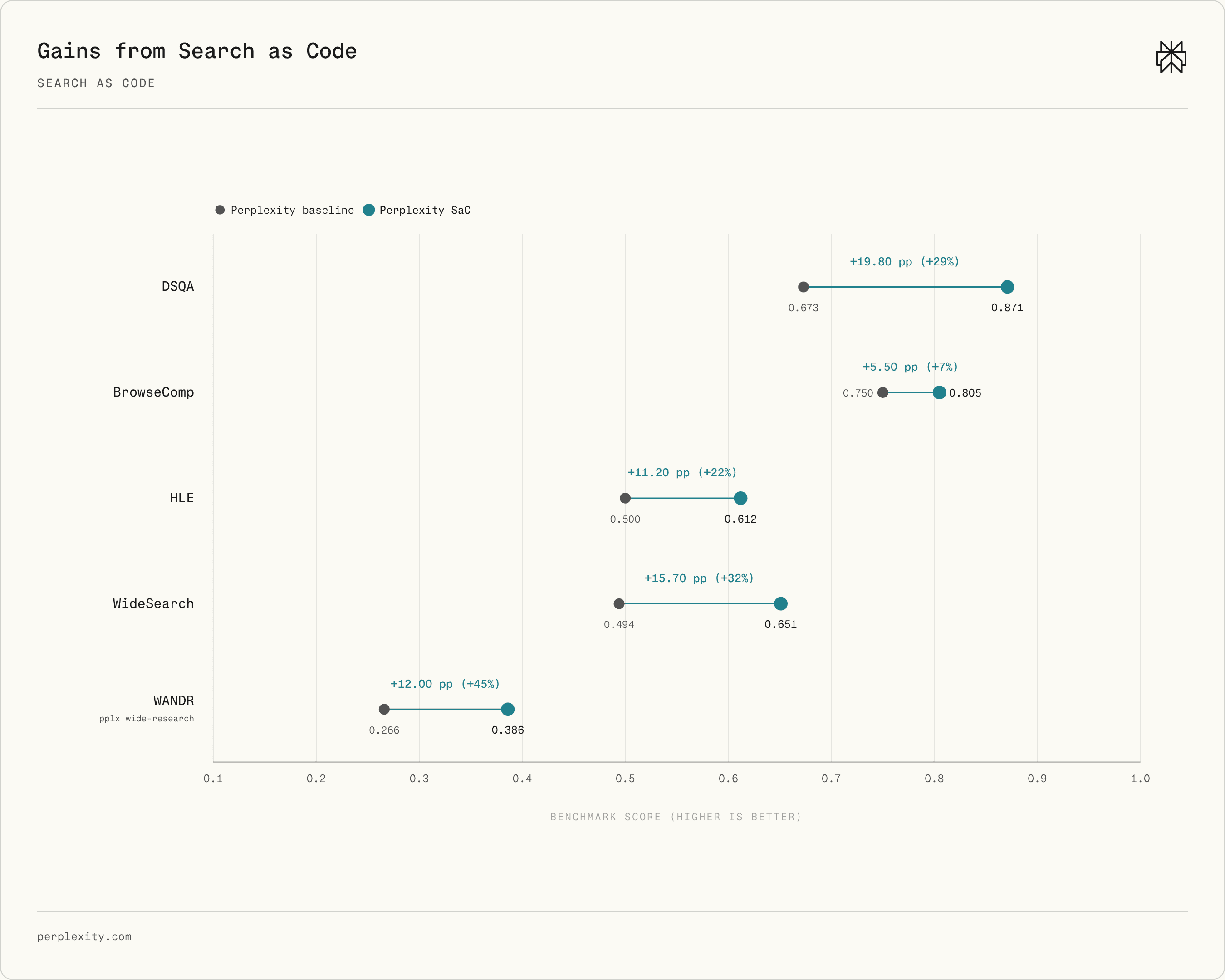
###### Figure 6 \| Perplexity baseline vs\. SaC score on each benchmark, with absolute and relative deltas annotated\.
#### Cost\-Performance Frontier
In practice, users care about performance relative to cost\. We therefore evaluate the cost\-performance frontier on DSQA and WideSearch\. We measure the cost and performance of SaC across low, medium, and high model reasoning levels, alongside the other systems\. Figures 7 and 8 plot benchmark score against per\-task price, with the x\-axis reversed so points farther right are cheaper and points higher represent better performance\.
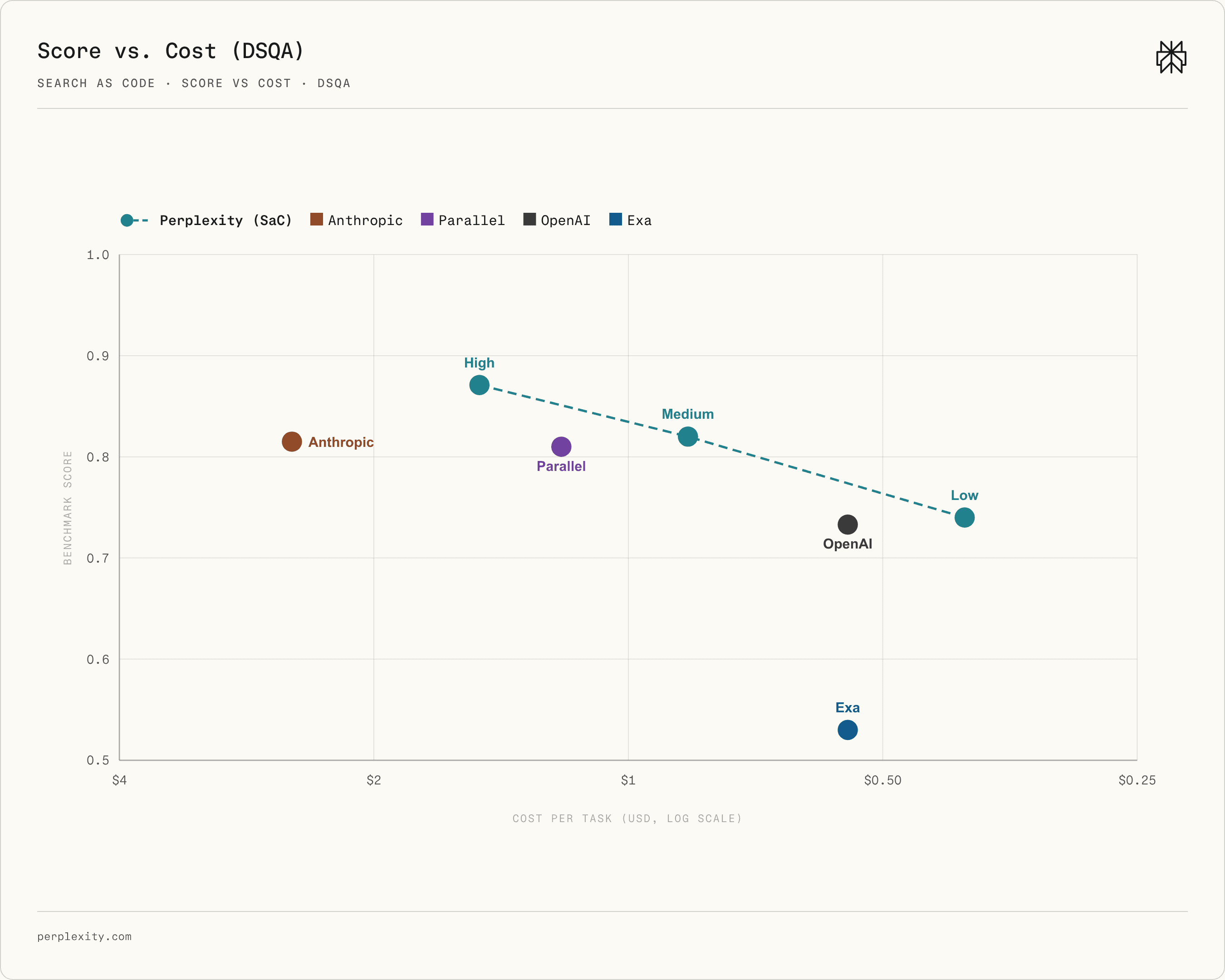
###### Figure 7 \| DSQA score versus per\-task price\. The dashed line connects the SaC model reasoning configurations\.
On DSQA, all three SaC settings lie on the upper\-right frontier\. The low reasoning setting is cheaper than all other systems while performing better than two of them\. The medium reasoning setting outperforms all non\-SaC systems at under $1 per task\. The high reasoning setting achieves top performance with a competitive cost\.
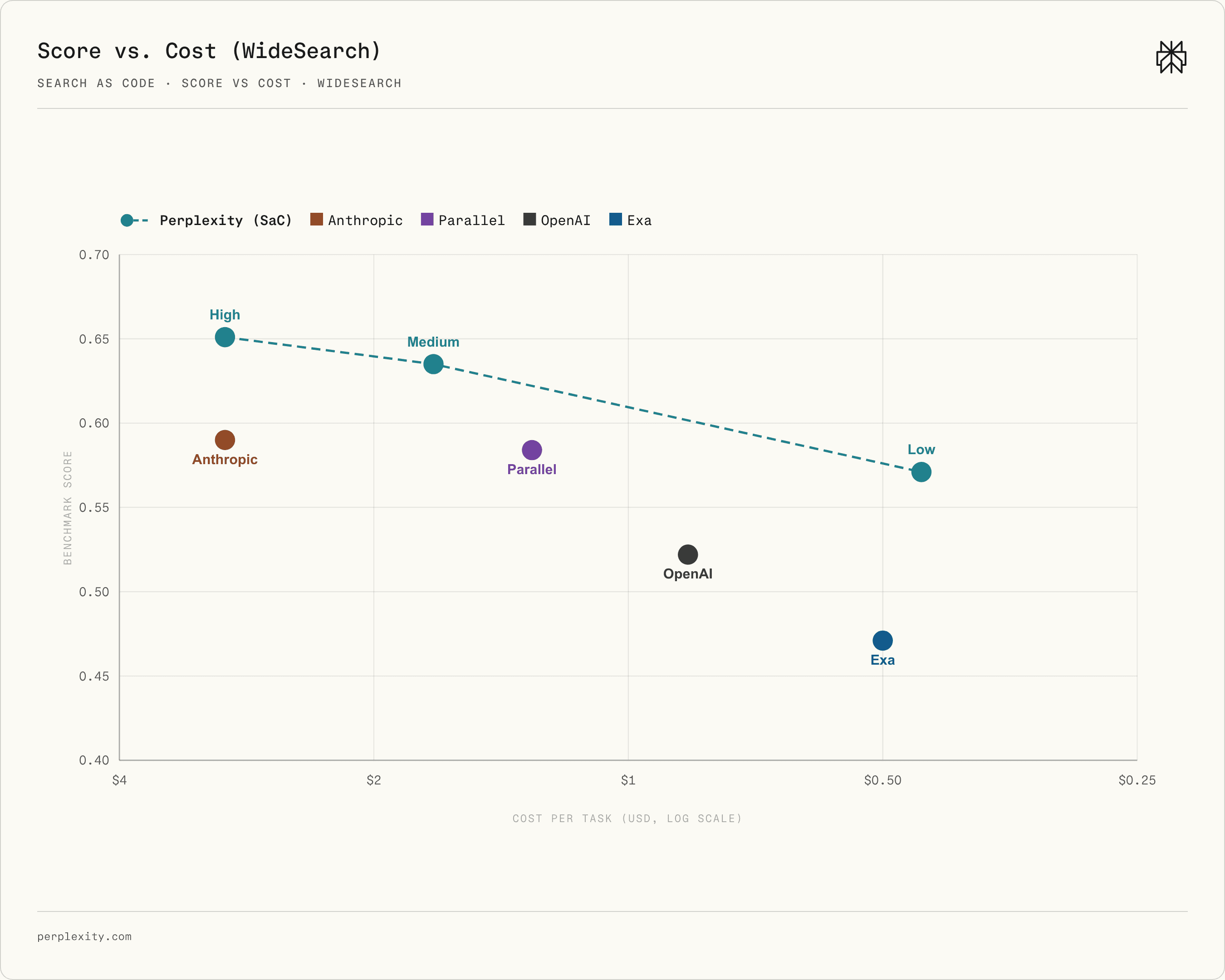
###### Figure 8 \| WideSearch score versus per\-task price\. The dashed line connects the SaC model reasoning configurations\.
WideSearch shows a similarly shaped frontier\. As with DSQA, the low reasoning setting achieves competitive performance at lower cost than all non\-SaC systems, while both medium and high reasoning outperform non\-SaC systems in task performance\.
### Toward a New Architecture of Computing
Search as Code reflects a broader change in software design\. For decades, software systems were organized around deterministic instructions executed by traditional runtimes on CPUs\. Frontier models introduce a new form of compute: token\-space reasoning that can both follow and generate instructions\. The most capable computational systems will combine these two forms of compute rather than choosing between them\.
Search is a natural proving ground for this hybrid architecture\. Models are well\-suited to deciding what evidence is needed and how uncertainty should be resolved\. Deterministic runtimes are well\-suited to batching, parallelism, filtering, ranking, and aggregation\. Search infrastructure serves as a universal I/O layer, providing the runtime with useful handles into the world's information that can sustain thousands of operations per minute\. When these pieces are integrated, the resulting system is much more powerful and efficient in accomplishing real\-world tasks\.
Every part of this architecture is necessary to unlock these capabilities\. Without intelligent models, the system cannot reason over search strategy\. Without sandboxes, models are forced into serial I/O and inefficient token\-space processing\. And without an atomized search stack, the model has nothing to orchestrate\. SaC works because reasoning, deterministic compute, and I/O are jointly designed to accentuate each layer's strengths\.
This codesign can be taken even further through the development of continual improvement loops\. For instance, the Agentic Search SDK and SaC Agent Skills could be jointly optimized in a common autoresearch loop\. More ambitiously, models can be trained to take advantage of low\-level search primitives exposed as an SDK\. One might even try coevolving SDK design during the model training process itself\. We look forward to pursuing more aggressive codesign strategies in future work\.
We built SaC to allow models to control the search process, rather than merely consume its results\. Our results prove the power of this control: SaC advances both absolute performance and the cost\-performance frontier on knowledge\-intensive agent benchmarks\. We're excited to bring SaC's capabilities to our users, starting today with Perplexity Computer and Agent API\. We will continue to optimize the SaC architecture across all layers of the stack to ensure our users \(and the agents serving them\) have the most powerful and efficient search capabilities possible\.