什么是 MDP?我们该如何求解?
摘要
本文通过一个关于大学生日常决策的教学示例,解释了马尔可夫决策过程(MDP)的基础知识,这是深度强化学习中的核心框架。
<p><em>作者:Surya Vengadesan</em></p><p>随着深度强化学习在围棋、Dota 2 甚至扑克等游戏中击败人类,该领域引发了极大的热情,人们希望从头开始理解其算法。在本博文中,我们将正是如此。我们将探讨深度强化学习的一个基本构建模块:马尔可夫决策过程(Markov Decision Processes, MDP)——这是一个对智能体如何与其环境互动并从中学习进行建模的框架。具体而言,我们将阐述 MDP 的理论,并探索求解它们的近似方法。</p><h3>马尔可夫先生的大学导航</h3><p>现在,让我们通过研究一个特定的智能体来深入了解 MDP。具体来说,智能体是在其环境中互动的实体,并通过迭代学习如何在环境中采取最佳行动。在我们的例子中,马尔可夫先生(Mr. Markov)将是我们的智能体;他是一名数学专业的本科生。马尔可夫在大学(他的环境)期间需要做出许多决定。在典型的一天中,马尔可夫以一小时为单位,要么为概率论课程学习,要么在床上睡觉,要么与朋友社交。马尔可夫面临一个问题。有些日子,因为熬夜完成习题集,他极其疲惫;或者因为连续数小时坐在书桌前而感到焦躁不安。因此,马尔可夫需要一种流程来帮助他应对日常决策,以寻求内心的平静。</p><h3>建模马尔可夫先生的世界</h3><p>在这篇博文中,我们将通过构建一个马尔可夫决策过程来模拟他的世界,从而帮助这位可怜的学生,然后找出符合他最大利益应采取的行动。在任何给定时刻,马尔可夫可能处于有限数量的状态之一。让我们将这些状态定义为一个称为状态空间(state space)的集合:</p><div class="latex-rendered" data-attrs="{"persistentExpression":"\\mathcal{S} = \\{s_1 \\text{ (studying)}, s_2 \\text{ (sleeping)}, s_3 \\text{ (socializing)}\\}","id":"FAFEUMTRQO"}" data-component-name="LatexBlockToDOM"></div><p>此外,在任何给定状态下,他都可以从一组动作中进行选择。让我们将这些动作定义为一个称为动作空间(action space)的集合:</p><div class="latex-rendered" data-attrs="{"persistentExpression":"\\mathcal{A} = \\{a_1 \\text{ (message a friend)}, a_2 \\text{ (read Tolstoy)}, a_3 \\text{ (eat a snack)}\\}","id":"KJWELGPETJ"}" data-component-name="LatexBlockToDOM"></div><p>在我们的模型世界中,在每个小时,马尔可夫可以在任何一种状态下执行这三种动作之一。我们将用变量 t 来标记这些小时。通过在特定时间 <em>t</em> 的特定状态下采取行动,马尔可夫将进入一个新状态 s'∈S。我们还将为每个状态-动作对及其结果动作定义一组非负概率 P(s'|s,a)≥0,并且对于任何概率分布,这些概率之和必须为 1:∑s' P(s'|s,a)=1。</p><p>现在,我们问马尔可夫一个问题:“你的目标是什么?你重视什么?”马尔可夫,作为一名立志成为数学研究生的人,回答说:“有一天向其他学生教授概率论,并在该领域进行原创研究。”为了帮助这位未来的概率论学者,让我们在他的决策框架中添加一些定义,以帮助量化他所重视的东西。对于每个状态-动作对和相关的下一个状态,我们分配一个标量奖励 r(s'|s,a)=c。我们向马尔可夫提出一个后续问题:“你的计划是什么?你打算如何进入研究生院?”他回答说:“我要学习,大量地学习。”现在,为了帮助马尔可夫踏上旅程,我们添加了一些额外的形式化表达。首先,我们将他的<em>计划</em>形式化为一个函数,称之为策略函数 π(a|s),该函数将每个状态映射到要采取的具体动作。</p><p>总结一下,假设他处于状态 <em>s<sub>1</sub></em>=学习,并根据他的策略决定采取动作 <em>a<sub>1</sub></em>=给朋友发消息。给定 <em>(s<sub>1</sub>,a<sub>1</sub>)</em>,在完成该动作后,他处于以下状态的概率如下:</p><div class="latex-rendered" data-attrs="{"persistentExpression":"t(s_1 (\\text{studying})| s_1, a_1) = 0.2","id":"MKQMTTSVIK"}" data-component-name="LatexBlockToDOM"></div><div class="latex-rendered" data-attrs="{"persistentExpression":"t(s_2 (\\text{sleeping})|s_1, a_1) = 0.2","id":"KTNFJQIPRL"}" data-component-name="LatexBlockToDOM"></div><div class="latex-rendered" data-attrs="{"persistentExpression":"t(s_3 (\\text{socializing})|s_1, a_1) = 0.6","id":"WYYONKJWUQ"}" data-component-name="LatexBlockToDOM"></div><p>正如之前定义的那样,这些概率之和为 1。我们还定义了一组奖励,我们认为这些奖励最符合马尔可夫所说的价值观。我们可以为他在状态 <em>s<sub>1</sub></em> 执行动作 <em>a<sub>1</sub></em> 后最终进入的每个状态分配实数奖励:</p><div class="latex-rendered" data-attrs="{"persistentExpression":"r(s_1(\\text{studying})|s_1, a_1) = 10","id":"HCYIOZNUTP"}" data-component-name="LatexBlockToDOM"></div><div class="latex-rendered" data-attrs="{"persistentExpression":"r(s_2(\\text{sleeping})|s_1, a_1) = 5","id":"YRHARZVITC"}" data-component-name="LatexBlockToDOM"></div><div class="latex-rendered" data-attrs="{"persistentExpression":"r(s_3(\\text{socializing})|a_1, s_1) = 3","id":"MCATMIJIVQ"}" data-component-name="LatexBlockToDOM"></div><p>总之,我们已将随机行为和价值度量纳入框架,因为现在每个状态-动作对都映射到一个概率分布和一组奖励,这些奖励唯一地确定了每个可能的下一个状态。本质上,我们刚刚阐述了 MDP 的数学形式化,这不仅有助于马尔可夫,而且更广泛地说,它存在于许多控制理论应用的核心,包括强化学习。</p><h3>定义回顾</h3><p>我们定义了组成元组 <S,A,T,R> 的四个量,其中包括状态空间、动作空间、转移函数和奖励函数。在我们与马尔可夫的具体例子中,我们有 3 个状态、3 个奖励,以及一个将所有状态-动作转移对 (s'|a, s) 映射到相关概率奖励的转移和奖励函数,每个总共 27 个标量。我们刚刚在上面定义的被称为<em>有限</em> MDP,因为元组的元素由有限集组成。下面是任意状态动作对 (s<sub>i</sub>,a<sub>i</sub>) 上 MDP 的子集。</p><div class="captioned-image-container"><figure><a class="image-link image2 is-viewable-img" target="_blank" href="https://substackcdn.com/image/fetch/$s_!z7ER!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc1fb9784-e12a-45eb-bf9e-c28ce1a9bf6e_547x354.png" data-component-name="Image2ToDOM"><div class="image2-inset"><picture><source type="image/webp" srcset="https://substackcdn.com/image/fetch/$s_!z7ER!,w_424,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc1fb9784-e12a-45eb-bf9e-c28ce1a9bf6e_547x354.png 424w, https://substackcdn.com/image/fetch/$s_!z7ER!,w_848,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc1fb9784-e12a-45eb-bf9e-c28ce1a9bf6e_547x354.png 848w, https://substackcdn.com/image/fetch/$s_!z7ER!,w_1272,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsu
查看缓存全文
缓存时间: 2026/05/08 08:49
# 什么是 MDP?以及如何求解它们?来源:https://mlberkeley.substack.com/p/mdps *作者:Surya Vengadesan*
随着深度强化学习在围棋、Dota 2 甚至扑克等游戏中击败人类,该领域引发了巨大的热情,人们希望从头开始理解其算法。在本博客文章中,我们将做到这一点。我们将探索深度强化学习的一个基本构建块:马尔可夫决策过程(Markov Decision Processes, MDPs)——这是一个建模智能体如何在其环境中行为并从中学习的框架。特别是,我们将阐述 MDP 的理论,并探索求解它们的近似方法。
现在,让我们通过研究一个特定的智能体来逐步了解 MDP。具体来说,智能体是一个在其环境中交互并迭代学习如何在环境中最佳行事的实体。在我们的例子中,马克夫先生(Mr. Markov)将是我们的智能体;他是一名数学专业的本科生。马克夫在大学期间(他的环境)需要做出许多决定。在典型的一天中,马克夫会为他的概率论课程学习、在床上睡觉或与朋友社交,以一小时为单位。马克夫面临着一个问题。有些日子,马克夫因为熬夜完成习题集而极度疲惫,或者因为长时间坐在书桌前而感到烦躁不安。因此,马克夫需要一个过程来帮助他应对日常决策,希望能带来内心的平静。
在本博客文章中,我们将通过为这个世界建立一个马尔可夫决策过程来模型化这个可怜学生的世界,然后弄清楚他为了自身最大利益应该采取什么行动。
在任何给定时间,马克夫可能处于有限数量的状态之一。让我们将这些状态表示为一个集合,称为状态空间:
$$\mathcal{S} = \{s_1 \text{ (学习)}, s_2 \text{ (睡觉)}, s_3 \text{ (社交)}\}$$
此外,在任何给定状态下,他都可以从一组动作中进行选择。让我们将这些动作表示为一个集合,称为动作空间:
$$\mathcal{A} = \{a_1 \text{ (给朋友发消息)}, a_2 \text{ (读托尔斯泰)}, a_3 \text{ (吃零食)}\}$$
在我们的模型世界中,在每个小时,马克夫可以从三个状态中的任何一个执行这三个动作之一。我们将用变量 $t$ 来标记这些小时。通过在特定时间 $t$ 的特定状态下采取动作,马克夫最终会进入一个新状态 $s' \in S$。我们还将为每个状态-动作对及其结果动作定义一组非负概率 $P(s'|s,a) \ge 0$,并且对于任何概率分布,这些概率之和必须为 1:$\sum_{s'} P(s'|s,a) = 1$。
现在,我们问马克夫一个问题:“你的目的是什么?你重视什么?” 马克夫,一位有志于成为未来数学研究生的人回答:“总有一天要教其他学生概率论,并在该领域进行原创研究。” 为了帮助这位有志成为未来概率论学家的人,让我们在它的决策框架中添加一些定义,以帮助量化他所看重的东西。
对于每个状态-动作对和关联的下一个状态,我们分配一个标量奖励 $r(s'|s,a) = c$。我们追问马克夫:“你的计划是什么?你打算如何进入研究生院?” 他回答:“我要学习,大量学习。”
现在,为了帮助马克夫踏上旅程,我们添加了一些额外的形式化描述。首先,我们将他的*计划*形式化为一个函数,称为策略函数 $\pi(a|s)$,它将每个状态映射到要采取的具体动作。简而言之,假设他处于状态 $s_1$=学习,并根据他的策略决定采取动作 $a_1$=给朋友发消息。给定 $(s_1, a_1)$,他在完成动作后处于以下状态的概率如下:
$$P(s_1 \text{ (学习)} | s_1, a_1) = 0.2$$
$$P(s_2 \text{ (睡觉)} | s_1, a_1) = 0.2$$
$$P(s_3 \text{ (社交)} | s_1, a_1) = 0.6$$
正如之前定义的那样,这些概率之和为 1。
我们还定义了一组我们认为最能符合马克夫所重视的奖励值。我们可以为他执行动作 $a_1$ 后处于的每个状态分配实数奖励:
$$r(s_1 \text{ (学习)} | s_1, a_1) = 10$$
$$r(s_2 \text{ (睡觉)} | s_1, a_1) = 5$$
$$r(s_3 \text{ (社交)} | a_1, s_1) = 3$$
通过这种方式,我们在框架中结合了随机行为和价值度量,因为每个状态-动作对现在都映射到一个概率分布和一组奖励,这些奖励唯一地确定了每个可能的下一个状态。本质上,我们刚刚为 MDP 奠定了数学形式化基础,这不仅有助于马克夫,更普遍地存在于许多控制理论应用的核心,包括强化学习。
我们定义了构成元组 $(S, A, P, R)$ 的 4 个量,包括状态空间、动作空间、转移函数和奖励函数。在我们关于马克夫的具体示例中,我们有 3 个状态,3 个奖励,以及一个转移和奖励函数,它们将所有状态-动作转移对 $(s'|a, s)$ 映射到关联的概率奖励,总共每个有 27 个标量。
我们上面所定义的内容被称为*有限* MDP,因为元组的元素由有限集组成。下面是任意状态动作对 $(s_i, a_i)$ 上的 MDP 的子集。
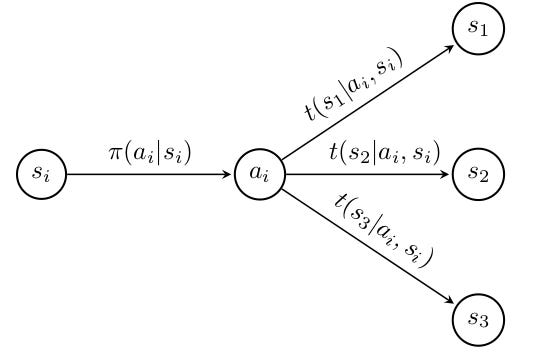
使用这种结构,我们希望弄清楚应该采取什么行动以获得最高的奖励;幸运的是,存在经过验证的算法可以精确做到这一点。我们将很快尝试在马克夫的世界中使用这些算法求解最优策略函数 $\pi(\cdot)$。通过我们的具体示例,我们试图解决一个古老且出奇相关的梗图(下图),但由于有限 MDP 的美妙之处,我们达到了极高的精度。
然而,在得出解决方案之前,我们需要在下面定义几个工具。
给定马克夫模型世界中明确定义的转移动态和奖励,我们可以定义另外两个函数。第一个是状态价值函数。这是由马克夫当前所处的状态以及他当前的策略函数决定的:
$$v_\pi(s) = \mathbb{E}_\pi[\sum_{k=0}^\infty \gamma^k R_{t+k+1} | S_t=s]$$
这可以解释为马克夫从当前处于状态 $s$ 并根据他的计划行动所获得的长期预期奖励。这里,我们有两个随机变量 $S_t$ 和 $R_t$,它们建模了如果遵循由 $\pi(\cdot)$ 定义的策略,智能体在时间步 $t$ 将处于的状态和将获得的奖励。我们还引入了一个新变量 $\gamma$,我们称之为折扣率,它可以是 $0 \le \gamma \le 1$ 之间的任何值。期望中的项展开为这种形式:
$$\gamma^k R_{t+k+1} = \gamma^0 R_1 + \gamma^1 R_2 + \gamma^2 R_3 + \cdots$$
本质上,通过采取行动并落入未来新状态所获得的奖励价值,随着每个时间步的经过,被 $\gamma$ 的倍数减少。这回答了在获得之前,给定奖励在未来每个时间步 $t$ 贬值多少的问题。
总而言之,状态价值函数 $v_\pi(\cdot)$ 使我们能够帮助马克夫衡量他从通过策略函数 $\pi(\cdot)$ 形式化的试探性*计划*中获得的*价值*。
现在,好奇的马克夫问我们:“好吧,假设我正在做概率论习题集,决定去读列夫·托尔斯泰的《战争与和平》,这是个好主意吗?” 为了回答这个问题,让我们添加最后一个函数以让马克夫放心。我们称之为动作价值函数 $q_\pi(s,a)$,这是他获得的预期回报奖励,计算方式与状态价值函数类似,但结合了来自初始动作 $a$ 而不是动作 $\pi(s)$ 的奖励:
$$q_\pi(s, a) = \mathbb{E}_\pi[\sum_{k=0}^\infty \gamma^k R_{t+k+1} | S_t = s, A_t = a]$$
这个看似微不足道的区别将在计算最优策略 $\pi^*(\cdot)$ 时帮助我们。状态价值函数和动作价值函数一起被称为贝尔曼方程。现在,我们将使用两种基本算法求解每个状态或状态-动作对处的这些贝尔曼方程的值。
求解有限 MDP 的第一个主要算法称为策略迭代(Policy Iteration)。该算法在两个步骤之间迭代。第一步是评估给定任意策略下 MDP 所有状态的价值函数。这通常称为*策略评估*。第二步是考虑对于每个状态,采取动作 $a \ne \pi(s)$(不属于策略)是否可以改善整体预期回报。这通常称为*策略改进*。该算法循环执行这些步骤,在每次迭代中找到更好的策略,直到收敛。
现在,我们将使用 Python 和 NumPy 实现马克夫的模型世界。我们遵循 Richard Sutton 的强化学习教科书(http://incompleteideas.net/book/first/ebook/node40.html)中概述的标准算法实现。然而,为了快速构建,我们做了一些简化:
(1) 我们的模型每个 $(s', s, a)$ 对只有一个奖励,而其他模型允许奖励分布
(2) 我们正在求解确定性策略,而其他模型可以求解随机策略
(3) 我们没有定义 56 个精心设计的奖励和转移,而是分配固定值
(4) 为了确保预期长期奖励的收敛性(避免值趋于无穷大),我们包含 0.85 的折扣率。
我们首先需要导入一些库并初始化我们的有限 MDP。
```python
import numpy as np
import matplotlib.pyplot as plt
import math
states = 3 # 状态数量
actions = 3 # 动作数量
rewards = 3 # 每个状态-动作对的奖励数量
g = 0.85 # 折扣率 - gamma
v_s = [0, 0, 0] # 状态价值函数
pi = [0, 0, 0] # 确定性策略函数
theta = 1 # 超参数
np.random.seed(0) # 用于初始化奖励函数的随机种子
# 奖励函数:初始化一个从 0 到 100 的随机值的 3x3x3 张量
R = 100 * np.random.rand(3, 3, 3)
# 转移函数:初始化一个全为 1/3 的 3x3x3 张量
T = np.full((3,3,3), 1/3)
PI = [] # 列表,用于跟踪策略迭代的价值函数
VI = [] # 列表,用于跟踪价值迭代的价值函数
print(R) # 我们的具体奖励函数
# 随机初始化的奖励函数
[[[54.88135039 71.51893664 60.27633761]
[54.4883183 42.36547993 64.58941131]
[43.75872113 89.17730008 96.36627605]]
[[38.34415188 79.17250381 52.88949198]
[56.80445611 92.55966383 7.10360582]
[ 8.71292997 2.02183974 83.26198455]]
[[77.81567509 87.00121482 97.86183422]
[79.91585642 46.14793623 78.05291763]
[11.82744259 63.99210213 14.33532874]]]
```
现在是策略迭代的实现,它初始化任意策略和状态价值函数,然后在策略评估和策略改进阶段之间迭代。
```python
def policy_iteration(pol, val, thres):
# 初始化策略和价值函数
policy = pol
threshold = thres
v_s_init = val
PI.append(v_s_init.copy())
# 运行第一次策略评估 (PE) 以评估你的任意策略
value = policy_evaluation(pi, v_s_init, threshold)
PI.append(value.copy())
# 运行第一次策略改进 (PI) 以找到可能证明其有效的动作
policy_stable, policy = policy_improvement(pi, value)
# 重复 PE 和 PI,直到策略不再改变以提高性能 (即 policy_stable = True)
while policy_stable == False:
value = policy_evaluation(policy, value, threshold)
PI.append(value.copy())
policy_stable, policy = policy_improvement(policy, value)
return policy, value
def policy_evaluation(pol, val, thres):
policy = pol
threshold = thres
v_s_init = val
delta = math.inf # 评估准确性,直到 Delta 降至指定阈值以下
while delta >= threshold:
delta = 0
# 计算每个状态的预期回报,给定当前策略
for s in range(states):
v = v_s_init[s]
E_r = 0
for s_p in range(states):
E_r += T[s, policy[s], s_p] * (R[s, policy[s], s_p] + g * v_s_init[s_p])
v_s_init[s] = E_r
delta = max(delta, abs(v - v_s_init[s]))
return v_s_init
def policy_improvement(pol, val):
policy_stable = True
policy = pol.copy()
v_s_init = val
for s in range(states):
old_a = pol[s]
v = v_s_init[s]
E_r = []
# 评估每个状态和动作对的预期价值
for a in range(actions):
e_r = 0
for s_p in range(states):
e_r += T[s, a, s_p] * (R[s, a, s_p] + g * v_s_init[s_p])
E_r.append(e_r)
# 选择最大化预期价值的动作
new_a = E_r.index(max(E_r))
# 比较最大化预期价值的动作是否是当前策略指定的动作
if (old_a != new_a):
# 如果不是,修改策略并将稳定性报告为 false,以确保 PI 评估新策略
policy[s] = new_a
policy_stable = False
return policy_stable, policy
# 运行算法
new_pi, new_v = policy_iteration(pi, v_s, theta)
```
**算法输出:**
$$v_{\pi^*}(s_1, s_2, s_3) = [489.98445020171096, 470.622736297478, 501.629766335168]$$
$$\pi^*(s_1, s_2, s_3) = [2, 0, 0]$$
通过运行此算法,我们获得了上述的最优状态价值函数和最优策略。
现在这个例子显然过于理想化,我们被给定了状态、动作和奖励。在现实世界中,我们没有这些,而且现实世界的问题通常要复杂得多。弄清楚如何解决更复杂、更模糊的问题是该领域至今面临的开放挑战。简而言之,MDP 只能根据你最初建模问题的能力来最好地解决现实世界的问题。因此,虽然我们可能无法保证我们的策略能在现实世界中帮助马克夫,但我们希望理论上的启示能为他的决策提供见解。
现在,让我们尝试使用价值迭代(Value Iteration)找到我们学生马克夫工作的最优策略。该算法的结构与策略迭代非常相似,但略有不同。策略迭代在改进和评估之间来回迭代,而价值迭代执行伪策略评估的单一迭代,其中它额外遍历动作空间并执行最大操作,以在完成时返回最优状态价值函数和策略函数。
```python
def value_iteration(pol, val, thres):
# 初始化策略和价值函数
policy = pol
threshold = thres
v_s_init = val
VI.append(v_s_init.copy())
delta = math.inf # 循环直到 delta 达到指定阈值
while delta >= threshold:
delta = 0
# 评估每个状态和动作对的预期价值
for s in range(states):
v = v_s_init[s]
E_r = []
for a in range(actions):
e_r = 0
for s_p in range(states):
e_r += T[s, a, s_p] * (R[s, a, s_p] + g * v_s_init[s_p])
E_r.append(e_r)
# 更新策略,使用最大化回报的动作
policy[s] = E_r.index(max(E_r))
# 相应地更新新的状态价值函数
v_s_init[s] = max(E_r)
delta = max(delta, abs(v - v_s_init[s]))
VI.append(v_s_init.copy()) # 注意:原文代码此处为 I.append,推测应为 VI.append
return policy, v_s_init
# 运行算法
new_pi, new_v = value_iteration(pi, v_s, theta)
```
**算法输出:**
$$v_{\pi^*}(s_1, s_2, s_3) = [490.2756261387957, 470.8914747627405, 501.8777964782847]$$
$$\pi^*(s_1, s_2, s_3) = [2, 0, 0]$$
通过运行此算法,我们获得了上述的最优状态价值函数和最优策略。
总体而言,这两种方法遵循不同的路径到达相同的解决方案,每种方法都经过精心设计,利用贝尔曼方程来更好地理解 MDP。这篇博客仅涵盖了基础知识,还有更多...
相似文章
面向安全强化学习的鲁棒防护
提出了一种新颖的防护框架,用于鲁棒马尔可夫决策过程(RMDP),该框架在不确定的转移动态下正式保证安全性,并证明了其正确性和最优性。该方法结合了学习模型的PAC保证,使得在未知环境中实现安全强化学习成为可能。
基础模型体的模拟-现实差距:统一的MDP视角
本文将基础模型体的模拟-现实差距形式化为马尔可夫决策过程问题,提出了统一的研究议程,以适应如领域随机化等经典解决方案,从而提升智能体在真实部署中的鲁棒性和可靠性。
@RohOnChain: 这堂关于马尔可夫决策过程的斯坦福一小时讲座将让你更深入地了解系统化交易背后的数学原理……
文章推荐斯坦福大学关于马尔可夫决策过程的讲座作为理解系统化交易数学基础的宝贵资源,声称其提供的洞察力胜过在主要金融机构进行的短期实习。
学习合作、竞争和沟通
OpenAI 展示了多智能体强化学习环境的研究,其中智能体学习合作、竞争和沟通。该论文介绍了 MADDPG(Multi-Agent DDPG),这是一种集中式评论家方法,能够让智能体比传统的分散式方法更有效地学习协作策略和沟通协议。
面向可扩展多任务强化学习的大决策模型
本文介绍了LDM-v0,一个在来自数千个多样强化学习环境的轨迹上离线训练的大决策模型,证明了单一的Transformer策略可以在机器人、自动驾驶、库存管理、网络安全、交易和视频游戏等领域匹配特定任务策略的性能。