Cached at:
05/11/26, 06:33 PM
# Useful Memories Become Faulty When Continuously Updated by LLMs
Source: [https://dylanzsz.github.io/faulty-memory/](https://dylanzsz.github.io/faulty-memory/)
TL;DR
- The popular recipe of**distill experience → store as text → rewrite later**is*not*a reliable engine of self\-improvement\.
- After streaming ground\-truth solutions through a consolidation loop, GPT\-5\.4 fails on**54 %**of ARC\-AGI problems it had previously solved with zero memory\.
- The same trajectories yield different memories under different schedules — the failure is in the*rewrite step*, not the data\.
- An**episodic\-only**agent — one that*selectively*retains and deletes raw rollouts, with abstraction disabled — matches or beats every consolidator we tested\. The point is curated raw evidence, not an unfiltered firehose\.
## The paradigm
A line of recent work gives an LLM agent a notebook\. After it solves a problem, the agent*distills*the trajectory into a textual lesson, drops it in persistent memory, and the next time something similar shows up, retrieves and reuses it\[refs\]\.
The pitch is irresistible: continual self\-improvement*without*parameter updates\. The agent's "weights" are just text it can read and edit\. Memory grows, lessons compound, accuracy goes up\.
We ran this loop end\-to\-end on five agent benchmarks \(ALFWorld, ScienceWorld, WebShop, AppWorld, Mind2Web\) and a controlled stream we built on top of ARC\-AGI\. The story didn't hold\.
Headline result
## The agent regresses on tasks it had already solved\.
Take 19 ARC\-AGI problems that GPT\-5\.4 solves at**100 %**accuracy with no memory\. Stream those exact problems through the consolidation loop, with**ground\-truth solutions**available at every step\.
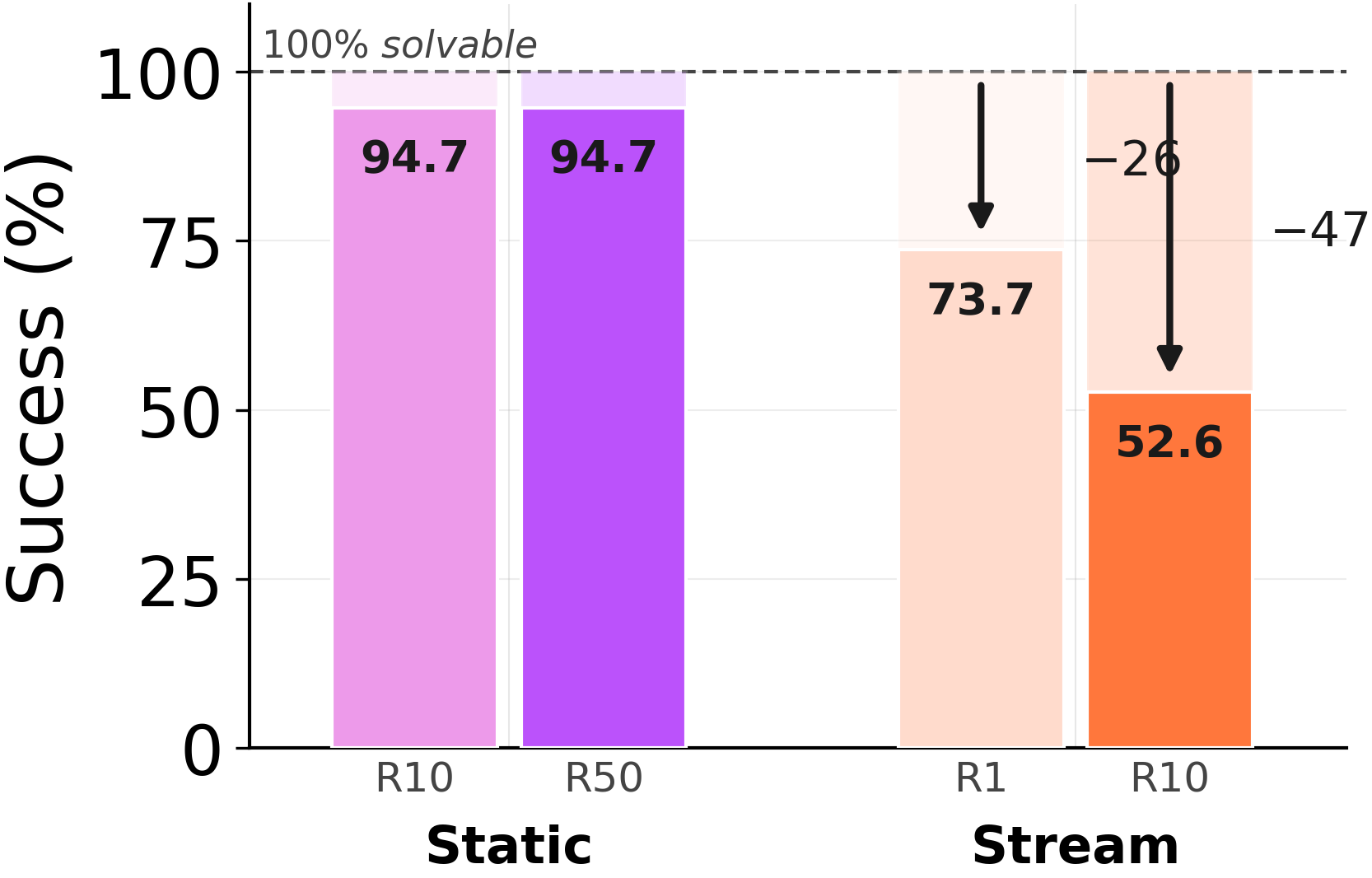**Solving the same problem twice, the second time worse\.**Without memory: 100 %\. After consolidating*from the ground\-truth solutions of those very problems*, GPT\-5\.4 drops to**54 %**\. The trajectories are perfect; the rewrite step is what breaks\."Faulty memory" is not a euphemism for "noisy data\." The data is clean\. The agent saw the right answer\. The act of compressing those right answers into a re\-usable lesson is what made it forget how to solve them\.
The shape of the decline
## Memory utility is non\-monotonic in updates\.
And these aren't bad starting points\. We seeded one ALFWorld memory with the strongest model we tested \(GPT\-5\.4\) on the cleanest "Static\-Group" schedule\. Then continued updating it with smaller models on the same trajectory pool\. Three different solvers \(Qwen3\.5\-\{27B, 9B, 4B\}\)\. Same shape:
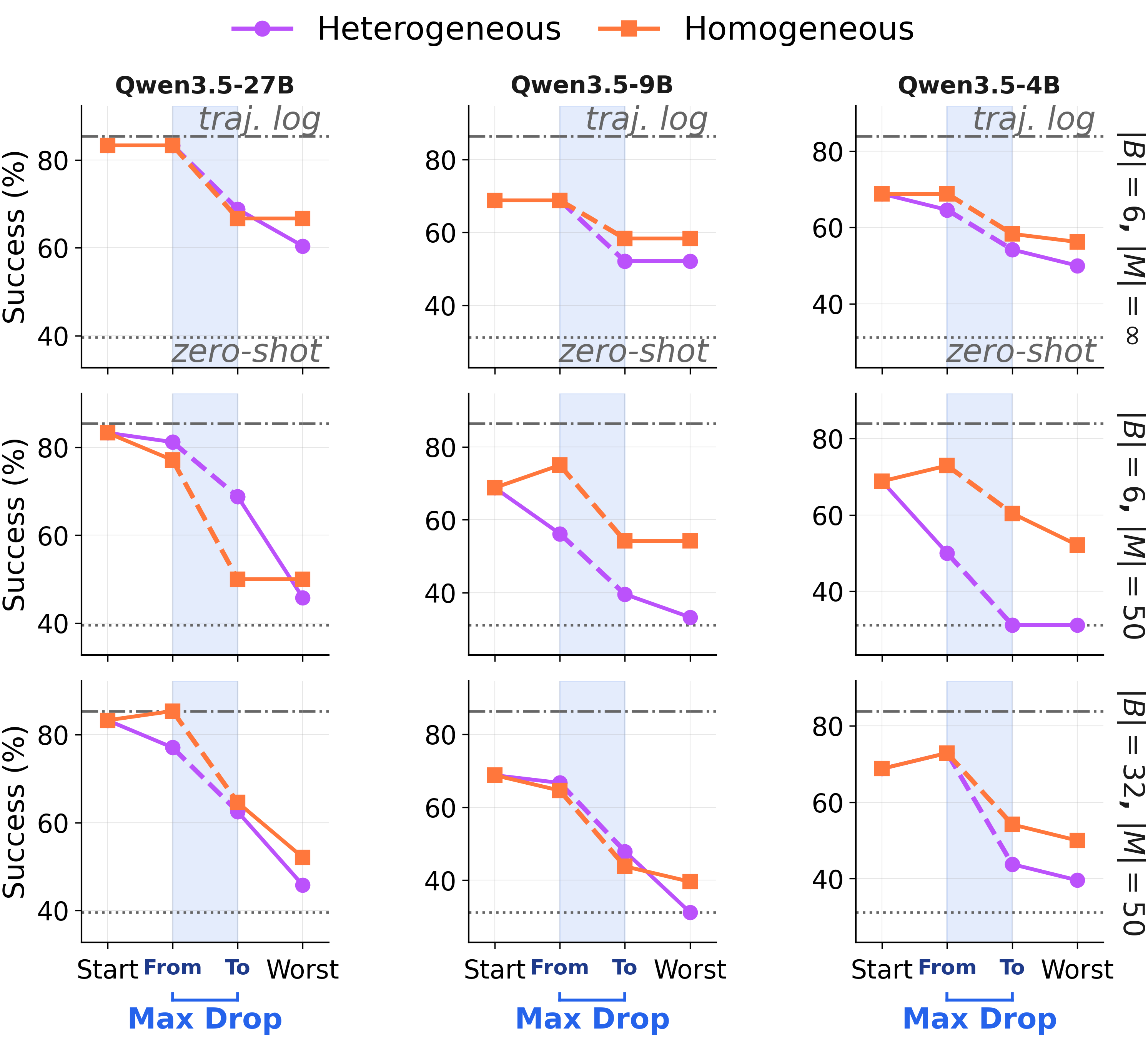**A strong memory is not a fixed point\.**Continued consolidation on the same trajectory pool drags utility down across all three solvers, sometimes catastrophically between consecutive steps\.
It's the rewrite, not the data
## The same trajectories produce different memories depending on how you serve them\.
Hold the trajectory pool fixed\. Vary*only*the consolidation schedule\. The output memory changes qualitatively, and so does downstream score\.
**Best of the three\.**When the consolidator sees a clean batch of one task family at a time, it actually has a chance to extract the latent structure\. This is the cleanest possible offline setting\.
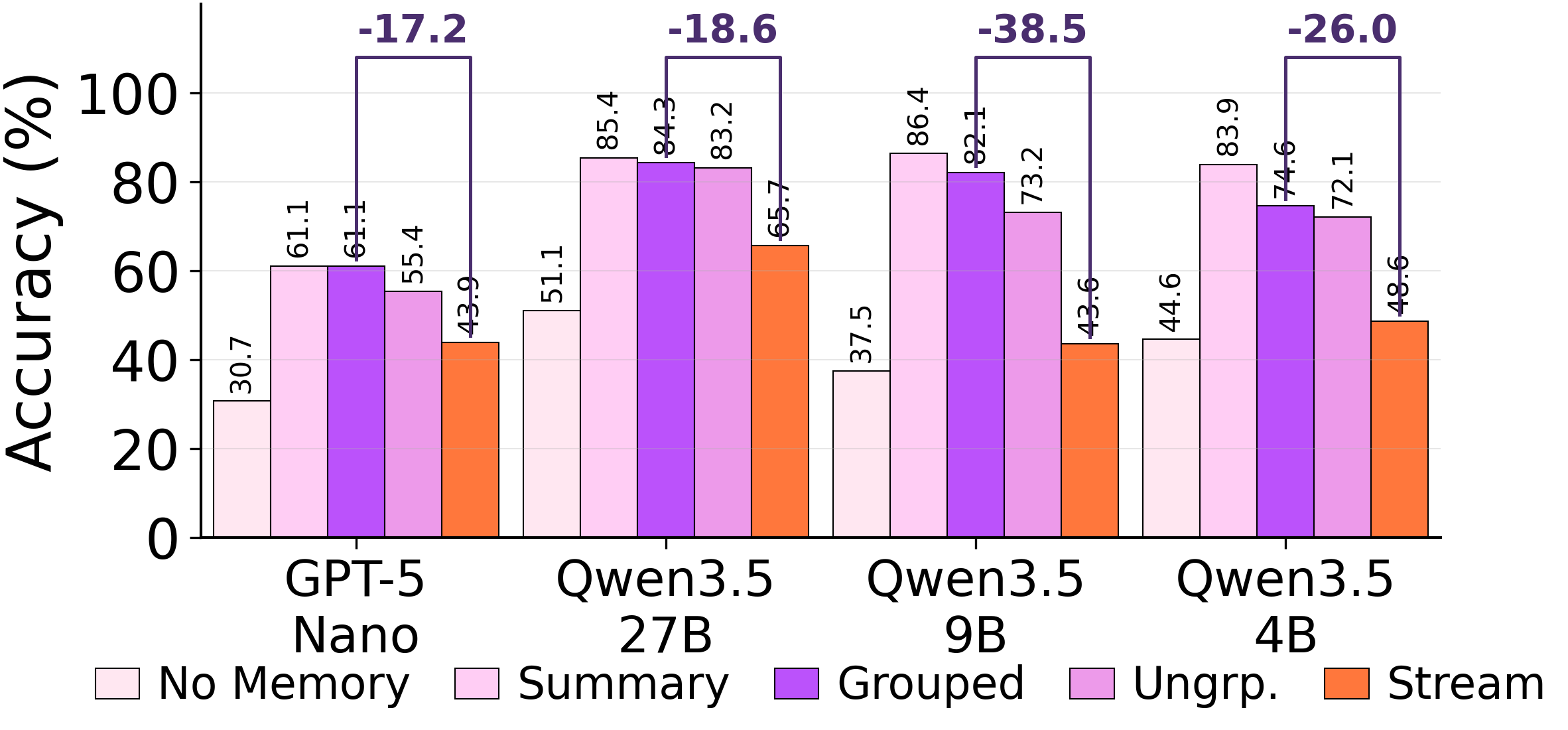**Same trajectories, three schedules, three different memories\.**Streaming — the schedule a continually\-deployed agent actually has — is the worst\.Why this matters
The trajectory pool is*identical*across these three runs\. Whatever's wrong with the resulting memory cannot be blamed on the data the agent collected\. It has to be in the consolidation step itself\.
Three failure modes
## Why does the rewrite go wrong?
We isolate three mechanisms\. Each one turns the consolidation loop from accumulation into lossy rewriting\.
01### Misgrouping
Before abstracting, the consolidator decides*which episodes belong together*\. When forced to consolidate every step, it pools episodes that share little underlying structure\.
Under forced consolidation on ARC\-AGI Stream, the model frequently combines memory entries across distinct problem classes\. When given autonomy, it eventually converges to a clean episodic store covering each of the 6 problem types — but only after 568 examples have elapsed\.*The capacity to segment is there\. The forced rewrite overrides it\.*
Verbatim memory entryGPT\-5\.4 · forced consolidation · ARC\-AGI Stream
**When to use:**A large hollow rectangular frame encloses some objects while other objects lie outside it …In the kept interior objects, a single distinguished cell is changed based on a relation to a matching object outside the frame, often when an outside object has the same shape as an inside object\.
**Strategy:**… \(5\) For each interior object,look for an exterior object with the same shape signature… \(6\)If an interior object has such a matching exterior counterpart, mark the center cell of the interior object's bounding box with the exterior object's color\.
The highlighted spans are*foreign\-family injections*: a shape\-signature lookup belongs to the*group\-by\-shape*family, the marker color\-write belongs to*key\-marker*\. Neither is part of the inside\-frame source task\. The consolidator stitched together a composite no actual family prescribes\.
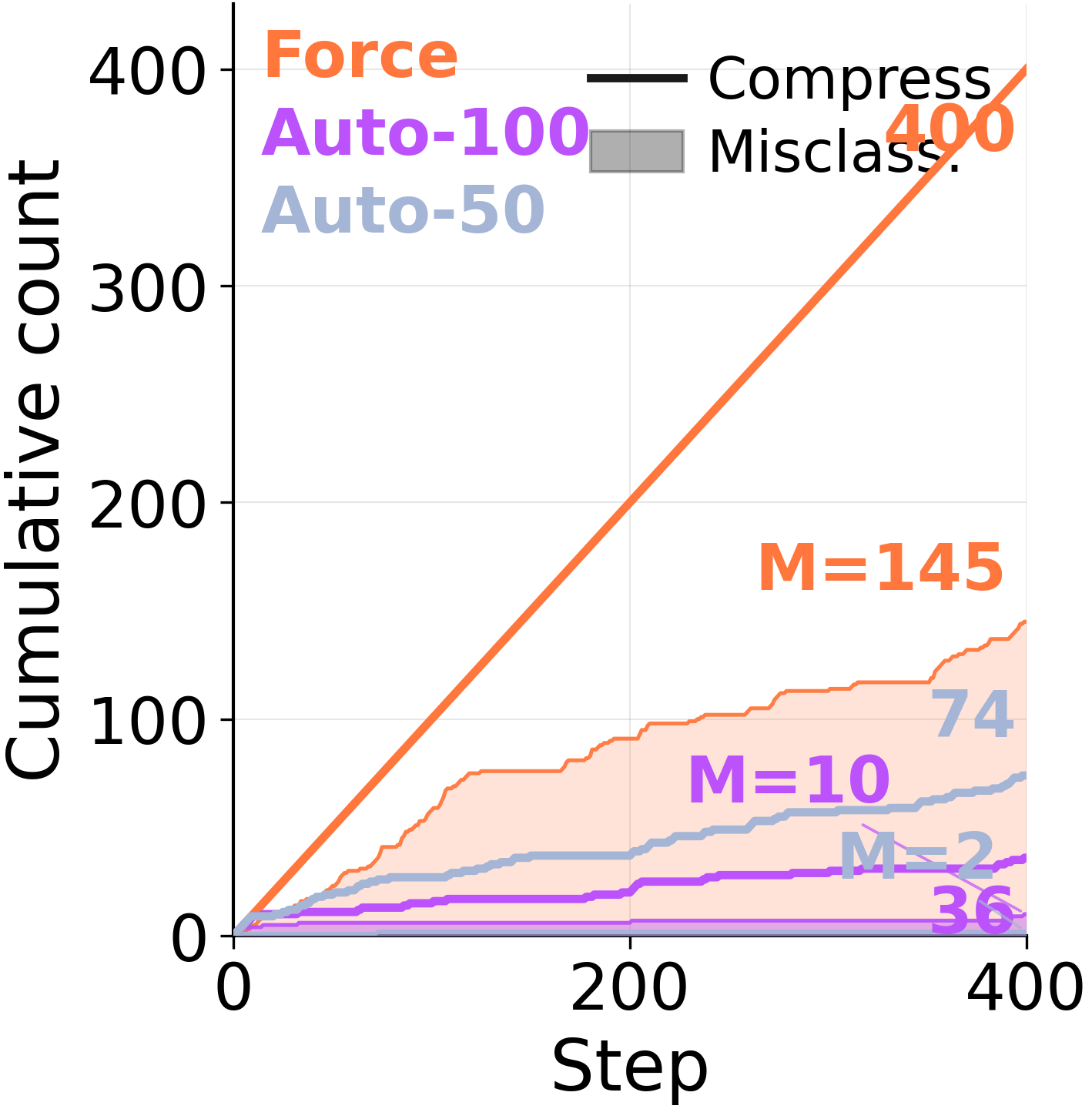Misclassification count under Force: episodes from different families merged into one entry\.
02### Interference
Each abstraction pass smooths existing entries\. When the chunks are imprecisely bounded, the rewrite**strips the applicability conditions**: a lesson that was true for Pick&Place reads as broadly relevant and misleads Pick\-Clean\-Place\.
On a 15\-task ScienceWorld switch sequence, distilling memories*only*on the current task \("Fresh"\) beats jointly consolidating across all prior tasks \("Cumulative"\) by**\+203 points**\. An LLM judge labels each entry: Cumulative accumulates over\-generalized memories at**~5×**Fresh's rate, and outright garbage at**~20×**\.
Verbatim memory entryScienceWorld · over\-generalized
Using a lighter, fire source, or oven MAY BE NECESSARYtochange the stateof a food or substance instate\-change tasks\.
Reads as broadly applicable\. But many state\-change tasks need cooling, freezing, or melting\. The applicability conditions have been stripped: the lesson now biases the agent toward heat sources for tasks where heat is irrelevant or harmful\.
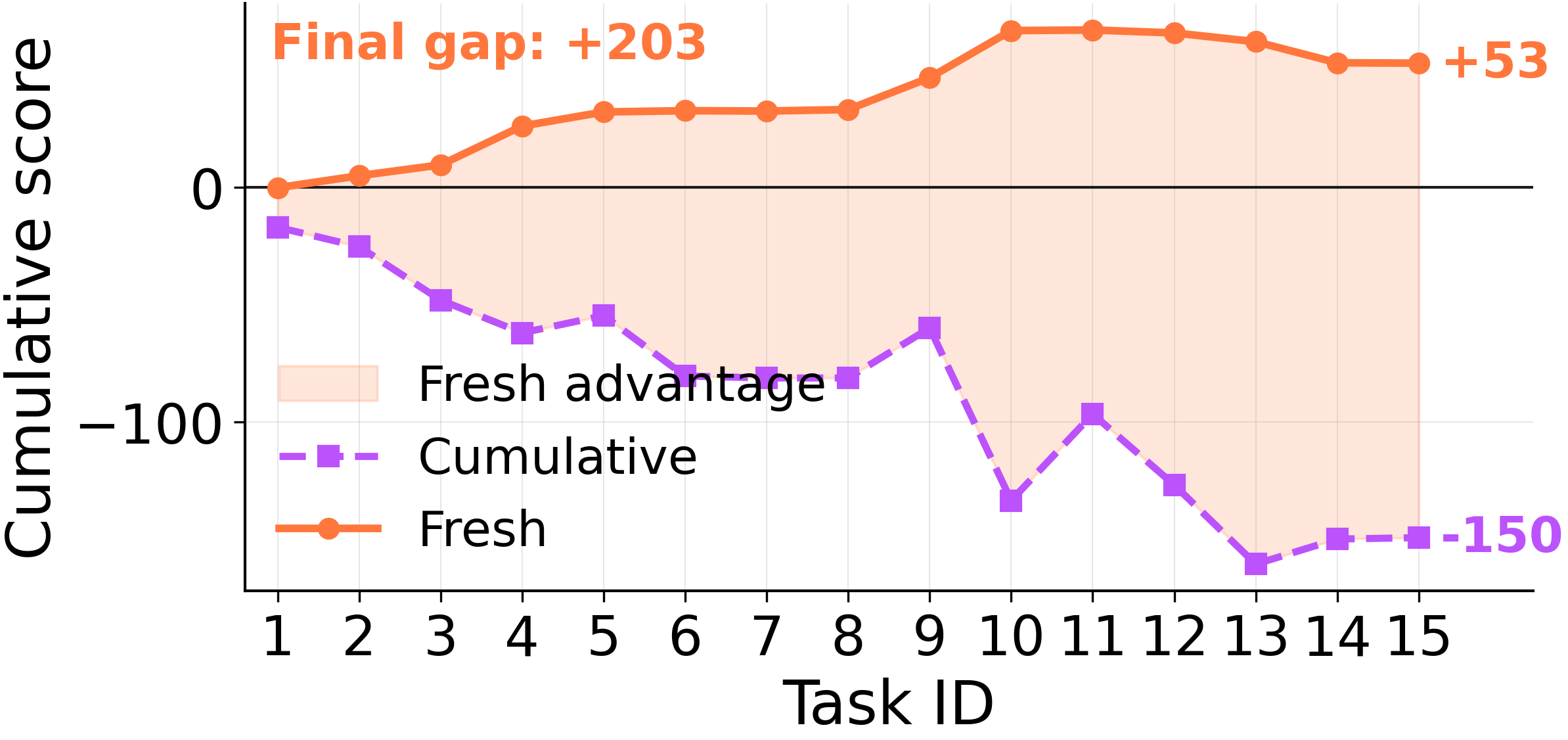Fresh vs Cumulative: identical trajectories, different consolidation scope, \+203 point gap\.
03### Overfit
When the input distribution*narrows*instead of widening, abstraction overfits to surface regularities of the seen instances rather than the underlying strategy\. The memory recognizes exact repetitions and fails on close variants of the same family\.
We feed the agent tasks drawn from a single ARC\-AGI strategy family across consolidation cycles\. Performance stays stable on exact repeats, then collapses on small variations within the same family\. The "lesson" turned into a description of the example\.
Same lineage, 50 rewrites apartGPT\-5\-mini · "recolor the largest object"
Round 1
identify and extract structured elements from input → compute a global metric \(e\.g\., max size\) → iterate elements and selectively apply targeted edits
Round 50
Find themaximum value of a derived per\-object numeric attributeand apply a uniform transformation to every object whose attribute equals that maximum\.
Round 1 names the actual selector, "max size" — a property a solver can compute\. Round 50, after 49 rewrites of the same lineage on the same task, has erased it: the entry no longer records*which*attribute to maximize\.
Narrow streams produce memories that recognize seen cases and fail on neighbors\.
An aside, for the cognitive\-science minded
## This is exactly what dual\-system memory was built to prevent\.
Complementary Learning Systems theory\[refs\]says the brain keeps a fast episodic store and a slow schema\-forming store*architecturally distinct*, with consolidation*gated*by schema fit rather than triggered on every event\. Collapse the two into one mandatory rewrite loop and you get exactly the interference catastrophe the dual system was designed to avoid\.
Today's agentic\-memory designs collapse the two\. The same LLM that solves the task also rewrites its own memory of that task at every turn, with no gating\. Our findings are what that prediction looks like in practice\.
Examples
## Faulty memory in the wild\.
Three real artifacts from real consolidation runs\. Verbatim, no edits, just selective highlighting\.
Case 1### 19 ARC tasks collapsed into a single playbook
GPT\-5\.4 · 19 tasks spanning 6 families · 10 passes \(190 steps\) · ground\-truth code at every step
After ten passes, the entire memory store contained*one*entry\. Not a library\. Not even five entries\. One\.
The only entry left in memoryAfter 190 consolidation steps
Extract connected objects, choose the largest as a frame, classify other objects by whether their bounding boxes lie strictly inside that frame, erase the frame and all outside objects, then hollow out each inside object in place by turning its interior to color 0 while preserving its boundary\.
Internally consistent\. Reads like a sensible lesson\. The problem: the source pool spans*six*families, and this entry describes*one*\. Five families are now invisible to the agent\.
Now hand the agent a held\-out task whose true rule is "erase every object of color 6\." Unrelated to inside\-frame logic\. Without memory, the same model solves it 10/10:
Without memory10 / 10
```
def solve(grid):
# The transformation removes every connected
# component of color 6.
out = [row[:] for row in grid]
for obj in extract_objects(grid):
if obj["color"] == 6:
for r, c in obj["cells"]:
out[r][c] = 0
return out
```
With memory0 / 10
```
def solve(grid):
# Keep only non-frame objects; frames are the
# largest connected components.
h = len(grid); w = len(grid[0]) if h else 0
objs = extract_objects(grid)
if not objs:
return [row[:] for row in grid]
frame = max(objs, key=lambda o: o["size"])
fb = frame["bbox"]
out = [[0] * w for _ in range(h)]
for obj in objs:
if obj is frame: continue
bb = obj["bbox"]
inside = (bb["top"] > fb["top"]
and bb["bottom"] < fb["bottom"]
and bb["left"] > fb["left"]
and bb["right"] < fb["right"])
if inside:
for r, c in obj["cells"]:
out[r][c] = obj["color"]
for obj in extract_objects(out):
apply_hollow(out, obj, fill_color=0)
return out
```
The first comment of the with\-memory solver reproduces the entry verbatim\. The code follows the entry's frame\-and\-hollow recipe: pick a frame by size, copy interior objects, hollow them\. On this input, no marker passes the strict\-inside check and the canvas stays empty\.**The memory turned a 10/10 solver into a 0/10 solver\.**
Case 2### Collapse by accretion: 8 workflows become 16 redundant ones
AWM on WebShop · 128 expert trajectories · gpt\-5\.4\-mini · 3 epochs
After epoch 1 the memory file held 8 abstract workflow templates\. By epoch 3 it held 16\. The new 8 \(highlighted\) are not new patterns\. They're the same templates, restated with one product category pinned in:
AWM workflow titles, epoch 3~8\.2k chars · verbatim
1. W1\.Search by attribute\-rich query\.
2. W2\.Open candidate item to inspect options\.
3. W3\.Select required attributes before buying\.
4. W4\.Select required size, color, and other variant options before buying\.
5. W5\.Search and select clothing variants with fit type\.
6. W6\.Search and select home decor variants\.
7. W7\.Search and select multi\-part apparel sizing variants\.
8. W8\.Search across pages when the first results do not match\.
9. W9\.Select apparel color, size, and fit/order\-specific variants before buying\.
10. W10\.Select non\-apparel flavor and size variants before buying\.
11. W11\.Select pack\-count and color variants before buying\.
12. W12\.Search and select color, size, and shape variants for home goods\.
13. W13\.Search and select shoes with color and size\.
14. W14\.Search and select apparel color, size, and purchase\.
15. W15\.Search and select electronics memory/storage variants\.
16. W16\.Search and select activewear or performance tops variants\.
W9 is just W3 \+ W4 \+ W5 stitched together\. W10–W16 are the same search\-then\-variant\-select template \(W1–W4\) with one product category pinned in \(food, pack\-count, home goods, shoes, apparel, electronics, activewear\)\. No new control flow, no new guard, no new stop criterion\.*Eight new entries that compete for retrieval bandwidth without adding any generality\.*
And it's not benign\. Removing just**one**workflow \(W8, "Search across pages when the first results do not match"\) raises wins from 7/50 to 14/50 on gpt\-5\.4\-mini and from 18/50 to 23/50 on gpt\-5\-mini — because W8 biases the agent toward dead\-loop`click\[Next \>\]`sequences at the expense of`click\[Buy Now\]`\.
Case 3### ScienceWorld: three flavors of memory rot
An LLM judge labels every entry in the store as*over\-generalized*,*over\-specialized*, or*useless garbage*\. Click a tab to see verbatim entries from each\.
Observing all life stages in orderMAY BE NECESSARY to complete a turtle\-stage task\.
Observing all life stages in orderMAY BE NECESSARY to complete a moth\-stage task\.
Using a lighter, fire source, or ovenMAY BE NECESSARY to change the state of a food or substance in state\-change tasks\.
Focusing on the target substanceSHOULD BE NECESSARY to change its state\.
The first two entries are paraphrases of each other — the consolidator wrote the same lesson twice with different task labels glued on\. None of these names a property a solver can actually use to pick an action\.
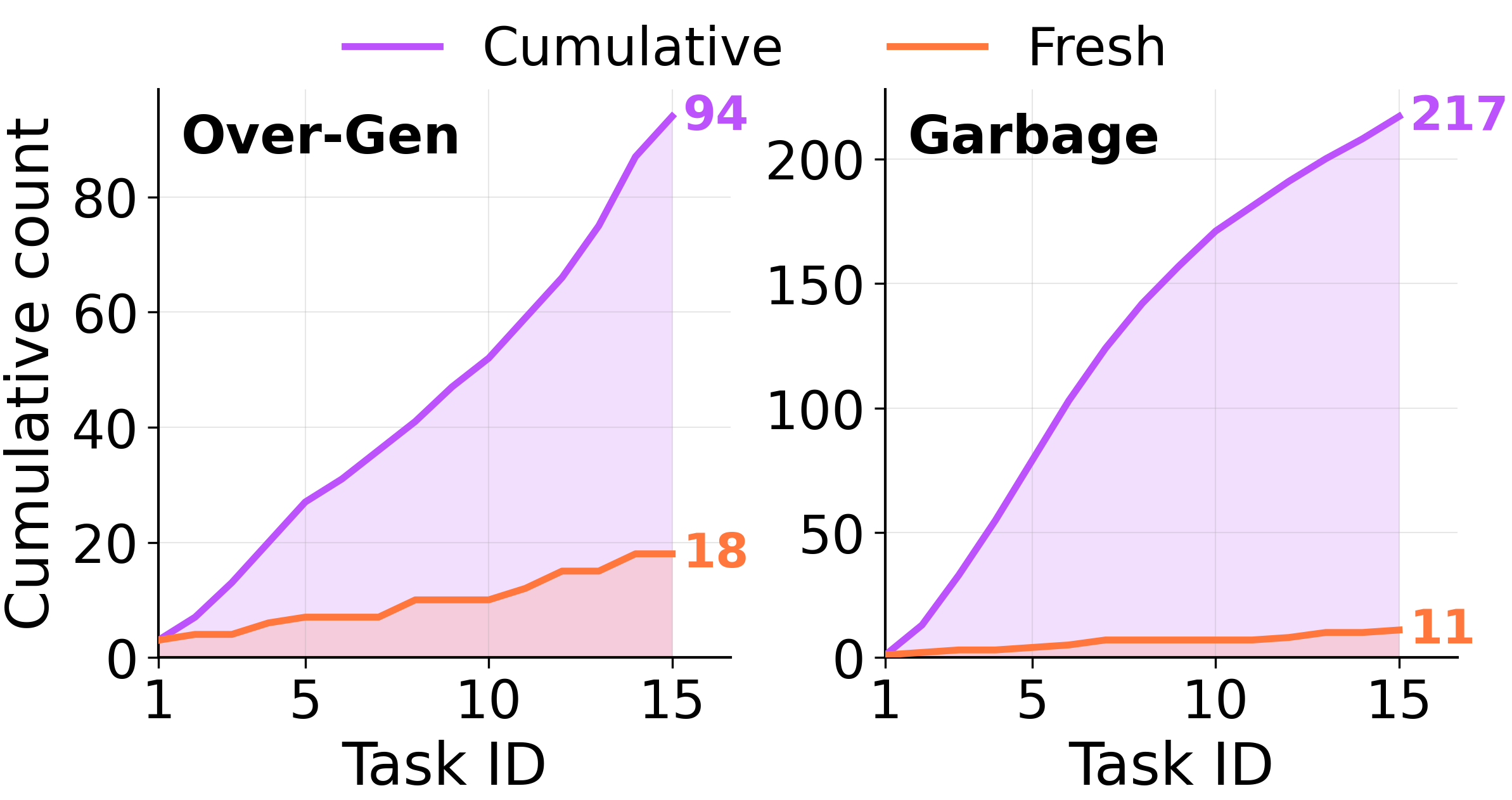Running counts of over\-generalized and garbage memories under**Cumulative**consolidation diverge from**Fresh**almost immediately and never recover\.
Case 4### A 50\-item memory becomes a 1\-item memory in a single consolidation step
ALFWorld · gpt\-5\-nano consolidator · stage 168 → 169 · cap 50 items
At stage 168 the memory holds 50 structured items, ~48k characters, each covering a distinct insight \(task taxonomy, state\-change shortcuts, look\-at\-light protocol, multi\-object recipes\)\. One consolidation step later, at stage 169, the memory contains**a single item**:
Stage 169 memory · 1 item · 1,960 chars · verbatimAfter one merge step
Use a single, repeatable loop to handle both single and multi\-object tasks across cleaning, cooling, heating, and look\-at\-in\-light\.1\) Systematically search common room sources… 2\) Pick each target; if a state change is required \(cool X with fridge, heat X with microwave, or clean X with sinkbasin\), perform it while holding… 3\) Navigate to the destination… 4\) Place the object… 5\) If two identical objects must go to the same destination… 6\) If an object starts at the destination… 7\) Manage distractors… 8\) After completing a batch… 9\)Look\-at\-in\-light\-specific extension: anchor a central desklamp location, co\-locate the target and lamp…10\) Pitfalls to avoid…
The cooling\-vs\-heating asymmetry that was a separate item at stage 168 \(cooling needs no insertion; heating does\) is gone\. The two\-object shuttle default is gone\. The look\-at protocol is now a half\-sentence sub\-clause inside step 9\.
The cost on the next eval, against the same memory's stage\-168 snapshot:
RolloutNo memoryStage 168 \(50 items\)Stage 169 \(1 item\)ΔQwen3\.5\-4B15/4835/4829/48−6Qwen3\.5\-9B15/4836/4826/48−10Qwen3\.5\-27B19/4837/4824/48−13
**One step\. 6 to 13 wins lost\.**The drop is biggest at the largest rollout: stronger solvers extracted more from the 50\-item structured memory, so they lose more when those distinctions collapse into a single "unified loop\."
Case 5### 99 votes for a tautology: a top\-ranked memory that mutated three times
ExpeL on ALFWorld · gpt\-5\.4 base, gpt\-5\-nano management · 200 stages
ExpeL ranks memory items by an integer vote score that increments on`EDIT`\. By stage 200, the top slot has 99 votes — the highest in the memory by a factor of 2\. This sounds like extreme value\. But the score keeps incrementing when an`EDIT`*replaces*the underlying concept\. Tracing the same slot:
Stage 028 votes
For tasks phrased as"examine/look at X with/by/using Y,"first locate both objects, then prefer the environment's direct task\-relevant interaction \(e\.g\., use Y, examine X with Y, or examine X if Y has been activated\)…
Concrete: names the look\-at\-obj\-in\-light pattern\.
↓
Stage 8046 votes
Prioritize the simplest action that directly advances the current subgoalwith the fewest prerequisites and minimal detours, while also favoring actions that reuse already\-opened receptacles or inventory\-held items…
Generic planning heuristic\. Task\-type cue gone\.
↓
Stage 20099 votes
Prioritize actions that directly advance the current subgoal using the nearest feasible fixture or item;verify prerequisites before acting; minimize travel; interleave subgoals when beneficial; attempt to combine state\-change and final placement… avoid assuming an item's state without explicit verification\.
Tautology\. Applies to any agent benchmark\.
The 99 votes were earned across*three different concepts*\. At stage 200, only the third concept is in the slot\. The popularity score is a measure of slot edit\-volume, not content quality\. The most "trusted" memory entry in this run is a directive that ships with every planning agent ever written\.
Memory zoo
## Click through\. Each one is a real entry from a real run\.
No charts here, just artifacts\. Each tab loads one verbatim entry along with a one\-line note on what's broken about it\.
GPT\-5\-mini · ARC\-AGI · 200 tasks · entry 1 of memory
"Make a working copy of the input grid \(list of row lists\) before mutating, perform all modifications on the copy, and return the copy to avoid mutating the original input\."
**What's wrong\.**A defensive Python idiom\. Mentions no color, shape, or rule that the six task families distinguish themselves by\. The model wrote a coding tip and called it a strategy\.
The deeper problem
## Every consolidation step is a generation\. The agent is hallucinating its own past\.
The failure is not "the LLM is bad at summarizing\." It's structural\. We're building a system whose stable long\-term knowledge is the fixed point of a generative loop — and there is no fixed point\.
Each consolidation pass works like this:
1. **Read**the current memory and a fresh trajectory\.
2. **Generate**what the new memory entry "should" be\. This is an LLM forward pass\. It produces fluent, plausibly\-structured text\. It is not a faithful summary of the input — it is a sample from a distribution conditioned on the input\.
3. **Write**the sample back as if it were ground truth\. The next consolidation step reads this sample and conditions on it\.
Now stack 200 of these\. Step*k\+1*'s context is a sample drawn conditioned on step*k*'s sample, which was drawn conditioned on step*k−1*'s, and so on\. Plausible\-looking text accumulates\. Specific facts \(which color, which receptacle, which selector\) are most likely to drop out at each step because they're the most surprising tokens conditional on the running summary\.**The memory drifts toward the LLM's prior over what a good lesson looks like, not toward the truth of the trajectories\.**
The reframe
Continuously updated textual memory is an iterated generative loop with no anchor\. The "memory" is not a record\. It is a sample — fluent, confident, and increasingly disconnected from what actually happened\. We saw vacuous abstractions, phantom rules distilled from bugs, byte\-identical duplicates, 99\-vote tautologies, 50 items collapsing into one\. These are not bugs\. They are*what samples from the consolidator's prior look like*after enough iterations\.
### Why the experiments line up\.
Three specific results we showed earlier follow directly from this framing:
- **Stream < Static\-All < Static\-Group\.**The more times the sample is fed back as context, the more the entry drifts toward the prior\. Static\-Group resamples once per family; Stream resamples thousands of times\.
- **Cumulative < Fresh by 203 points\.**Cumulative consolidates over a growing prefix of past summaries; Fresh consolidates from raw trajectories of one task\. Cumulative sits deeper in the loop\.
- **Episodic\-only matches abstraction\.**Raw episodes are*outside*the loop\. They are not samples\. They are records\. Of course they hold up better\.
### The implication is uncomfortable\.
The dominant agentic\-memory paradigm — "after each task, distill the trajectory into a textual lesson and store it" — is not a way of accumulating experience\. It is a way of replacing experience with a slowly\-drifting LLM prior over what experience looks like\. Until the consolidator is grounded in something it cannot itself overwrite, scaling the experience scales the drift\.
A surprisingly strong fix
## Don't force abstraction\. Just keep the episodes\.
ARC\-AGI Stream lets us put the agent in charge of its own memory\. At each step it canRetain,Delete, orConsolidate\. We compare three regimes:
#### Force
Must consolidate every round\. Episodic entries don't persist between rounds\.*The default in most existing systems\.*
#### Auto
Agent chooses: retain raw, delete, or consolidate\. Both episodic and abstract stores are available at retrieval\.
#### Episodic Only
Retain or delete raw episodes\. Abstraction is*disabled entirely*\.
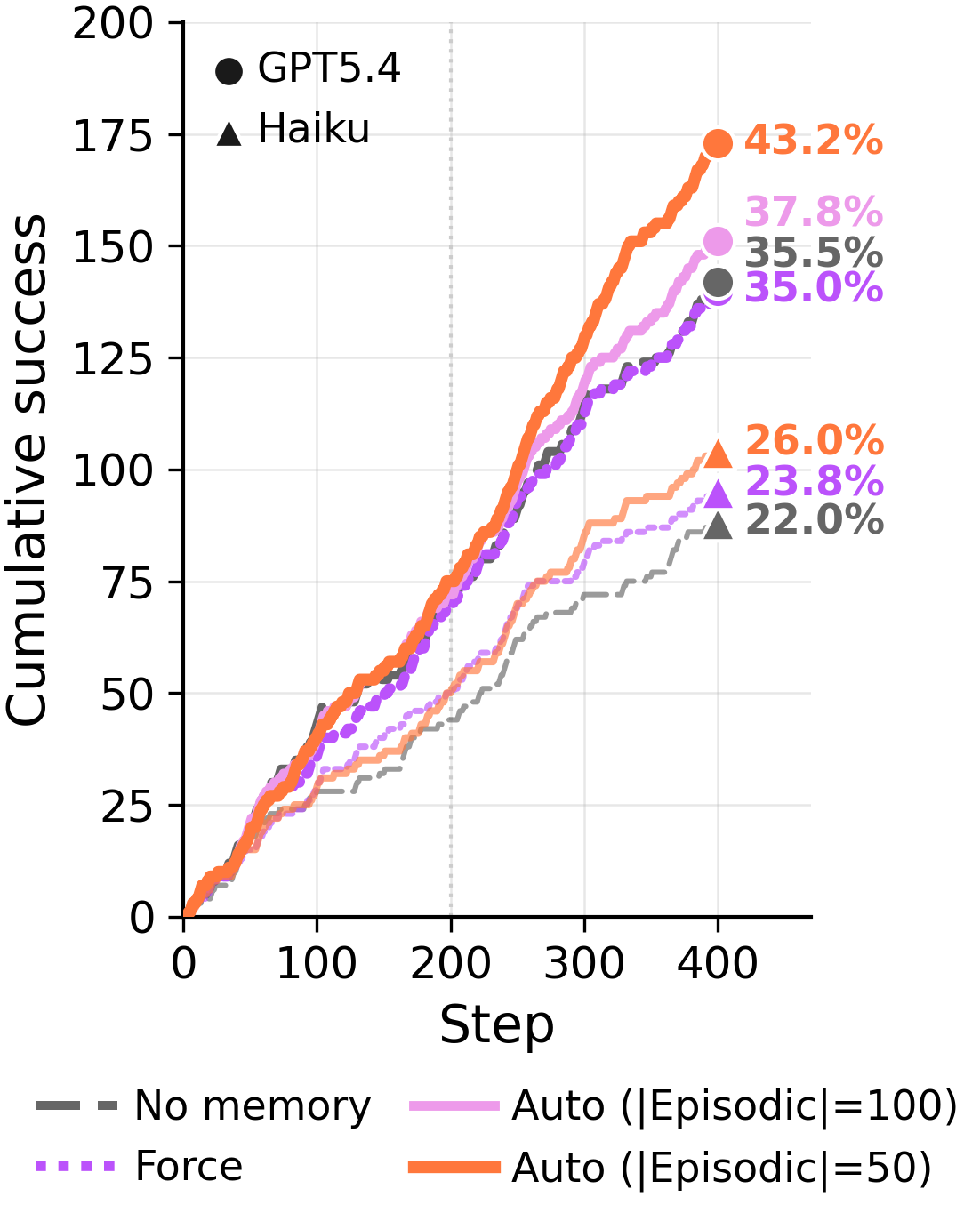Across 400 training steps and two backbones,**Auto**— which keeps episodes by default and uses abstraction sparingly — outperforms**Force**\. Whatever Force gains from compression, it loses more by overwriting evidence\.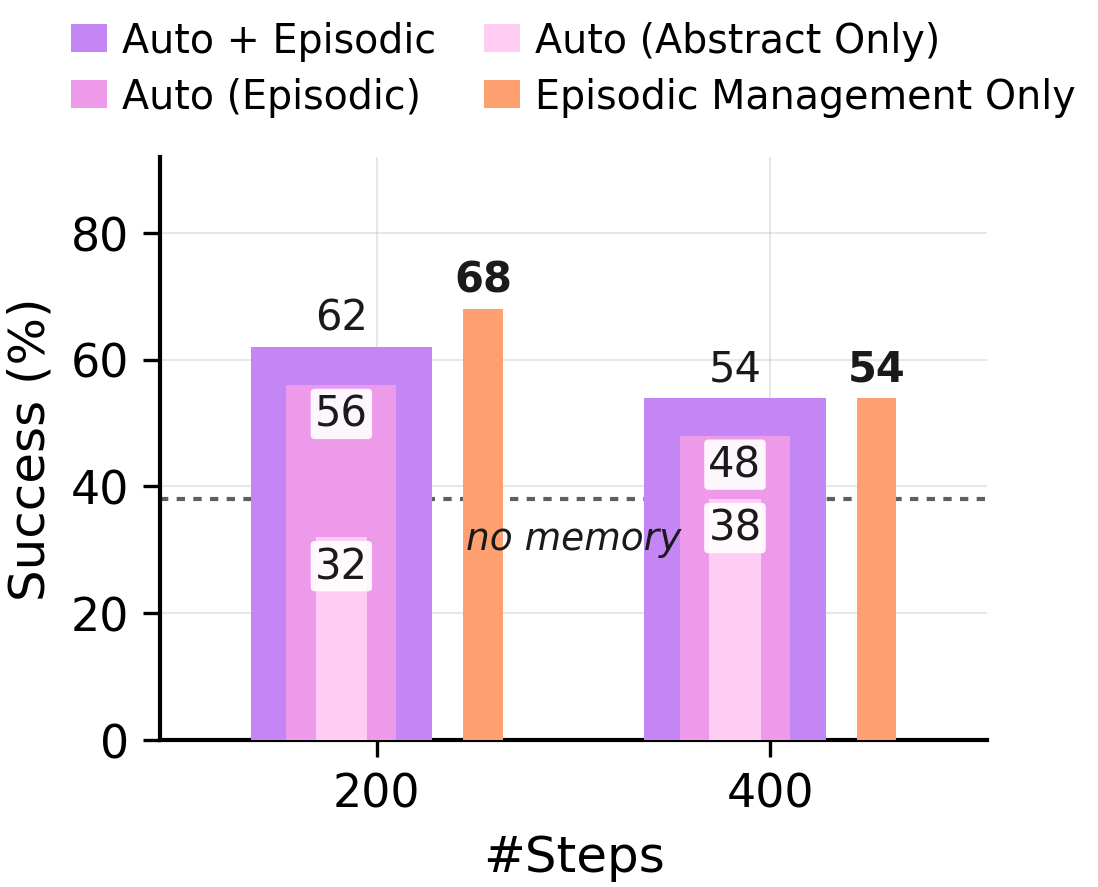**Where the gain actually lives\.**Removing episodic evidence and reading only abstract lessons collapses accuracy back to the no\-memory baseline\.*Episodic Management Only*— raw episodes that the agent has*selectively*retained or deleted, with abstraction disabled — matches or exceeds the full Auto mode\. The useful information was sitting in the curated raw episodes the whole time\.### ARC\-AGI GT Stream: 400 steps, ground\-truth solutions, all four management policies\.
The cleanest test of the gating prediction is the GT regime, where the agent receives ground\-truth solutions at every step\. There is no "the trajectories were noisy" excuse here\. Whatever happens at the consolidation step is what happens\.
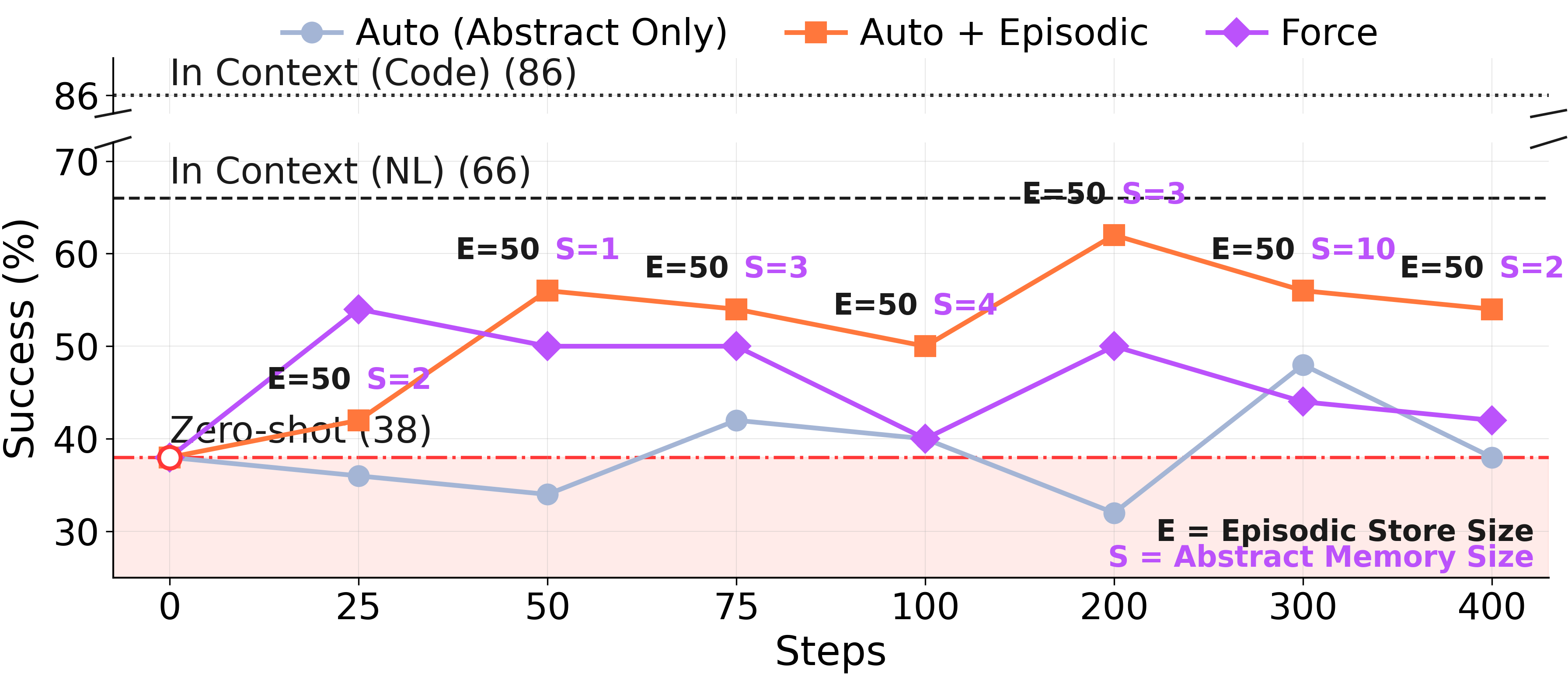**ARC\-AGI GT Stream, 400 training steps\.**Force lags from step ~50 onward\. The Auto\+Episodic curve climbs and stays climbing; Force plateaus and is overtaken\. Same model, same trajectories, same ground\-truth solutions — just a different rule about whether abstraction is mandatory\.To isolate where the Auto\+Episodic gain comes from, we re\-evaluated four checkpoints from the same run with each memory source restricted in turn:*Abstract Only*reads just the distilled lessons,*Episodic Only*reads just the raw episodic store, and*Auto*reads both\.
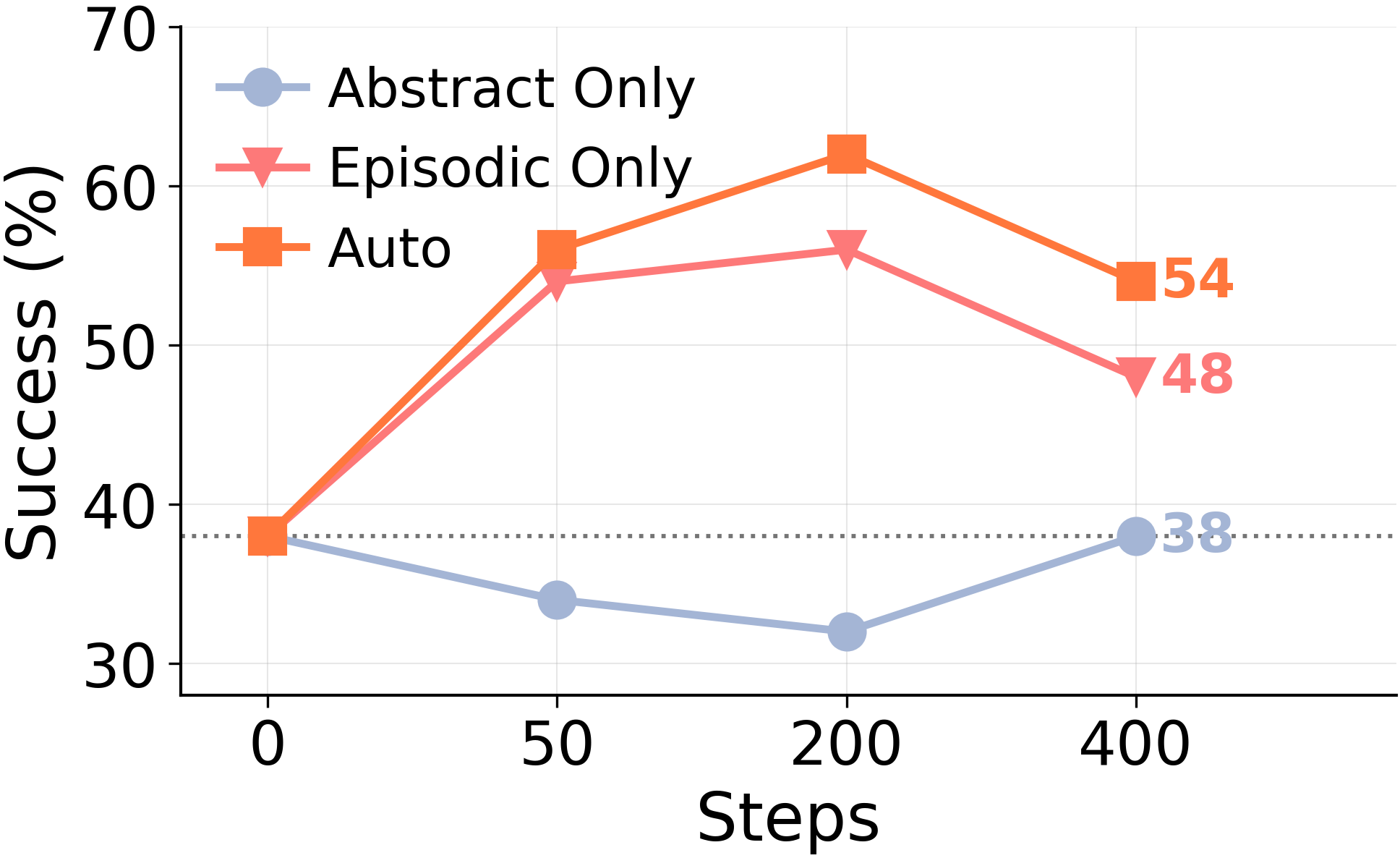**The abstract store is doing none of the work\.**Reading*only*distilled lessons \(Abstract Only\) never improves on the no\-memory baseline at any of the four checkpoints\. Reading*only*raw episodes \(Episodic Only\) recovers nearly the entire Auto gain\. The combined Auto reading is, at best, marginally better than Episodic Only alone — meaning the consolidator's distillations are contributing roughly zero on top of the raw episodes the agent already chose to keep\.And the agent itself agrees, when given the choice\. It saturates the episodic buffer quickly at every budget level and keeps the abstract store sparse:
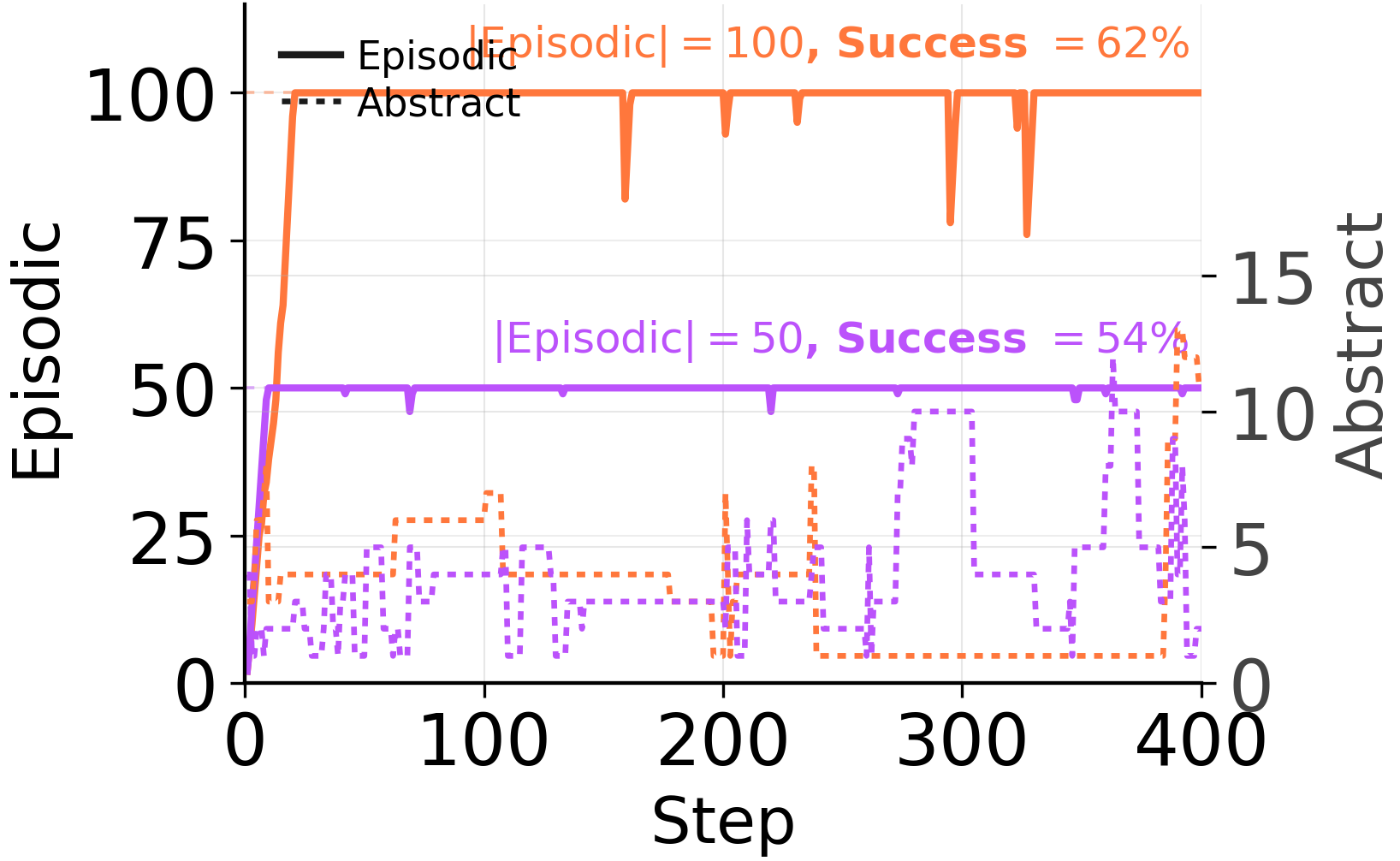Auto\-mode buffer composition\. The agent's own management policy is*episodic\-first*when the architecture permits it\.The principle
Episodic and schema\-forming roles should not be collapsed into a single rewrite loop\. Raw episodes are first\-class evidence, not material to be compressed away\. Abstraction, when it happens, should be*opt\-in and gated by the agent*— not forced on every trajectory\.
An uncomfortable baseline
## An episodic\-only memory is competitive with every consolidator we tested\.
On WebShop, ALFWorld, and AppWorld, an "episodic\-only" memory — just append raw trajectory rollouts to context, no cross\-trajectory rewriting — is competitive with ACE, AWM, and Dynamic Cheatsheet\. Same trajectories\. No distillation step\. The solver's in\-context learning extracts the relevant signal directly from preserved instances\.
We're not saying abstraction is useless\. We're saying:**a memory method whose value depends on distillation should be tested against the unabstracted rollouts it distills\.**Currently, very few are\.
Takeaways
## So — what should you build?
1. **Treat raw episodes as first\-class evidence\.**Don't compress them away by default\. Today's solvers can already use them via in\-context learning\.
2. **Make abstraction selective and gated\.**Not every trajectory needs to become a "lesson"\. Most should not\.
3. **Decouple the episodic and schema\-forming roles\.**A fast episodic buffer \+ a slow, gated abstract store dominates a single mandatory rewrite loop\.
4. **Stress\-test against scale\.**A memory system that's good at 8 examples and bad at 128 is not a memory system\. It's a prompt with a leak\.
5. **Always include an episodic\-only baseline\.**If your distilled memory can't beat raw rollouts retrieved as in\-context demos, the distillation isn't earning its keep\.
## Continually rewritten memory is fragile\.
Persistent textual memory promised a path for LLM agents to improve after deployment without weight updates\. Our results say: not yet\. Continuously updated textual memory should be viewed not as a reliable engine of self\-improvement, but as a fragile mechanism that can make*more experience lead to worse memory*\.
Long\-horizon agents will need both episodic and schematic memory\. But until LLMs can decide*when*and*how*to consolidate, the safer default is to keep the evidence and abstract sparingly — or not at all\.