UltraFlux: Data-Model Co-Design for High-quality Native 4K Text-to-Image Generation across Diverse Aspect Ratios
Summary
UltraFlux introduces a data-model co-design approach for native 4K text-to-image generation across diverse aspect ratios, addressing positional encoding, VAE compression, and optimization challenges. It outperforms existing open-source baselines and matches proprietary models like Seedream 4.0.
View Cached Full Text
Cached at: 07/02/26, 05:41 AM
# UltraFlux: Data-Model Co-Design for High-quality Native 4K Text-to-Image Generation across Diverse Aspect Ratios
Source: [https://arxiv.org/html/2511.18050](https://arxiv.org/html/2511.18050)
Tian YeSong Fei11footnotemark:1Lei ZhuHKUST\(GZ\)HKUST\(GZ\)HKUST, HKUST\(GZ\)tye610@connect\.hkust\-gz\.edu\.cnsfei285@connect\.hkust\-gz\.edu\.cnleizhu@ust\.hk Project:[https://w2genai\-lab\.github\.io/UltraFlux/](https://w2genai-lab.github.io/UltraFlux/) Code:[https://github\.com/W2GenAI\-Lab/UltraFlux](https://github.com/W2GenAI-Lab/UltraFlux)
###### Abstract
Diffusion transformers have recently delivered strong text\-to\-image generation around 1K resolution, but we show that extending them to*native 4K*across diverse aspect ratios exposes a tightly coupled failure mode spanning positional encoding, VAE compression, and optimization\. Tackling any of these factors in isolation leaves substantial quality on the table\. We therefore take a data–model co\-design view and introduce*UltraFlux*, a Flux\-based DiT trained natively at 4K on*MultiAspect\-4K\-1M*, a 1M\-image 4K corpus with controlled multi\-AR coverage, bilingual captions, and rich VLM/IQA metadata for resolution\- and AR\-aware sampling\. On the model side, UltraFlux couples \(i\)*Resonance 2D RoPE with YaRN*for training\-window\-, frequency\-, and AR\-aware positional encoding at 4K; \(ii\) a simple, non\-adversarial VAE post\-training scheme that improves 4K reconstruction fidelity; \(iii\) an*SNR\-Aware Huber Wavelet*objective that rebalances gradients across timesteps and frequency bands; and \(iv\) a*Stage\-wise Aesthetic Curriculum Learning*strategy that concentrates high\-aesthetic supervision on high\-noise steps governed by the model prior\. Together, these components yield a stable, detail\-preserving 4K DiT that generalizes across wide, square, and tall ARs\. On the Aesthetic\-Eval@4096 benchmark and multi\-AR 4K settings, UltraFlux consistently outperforms strong open\-source baselines across fidelity, aesthetic, and alignment metrics, and—with a LLM prompt refiner—matches or surpasses the proprietary Seedream 4\.0\.
## 1Introduction
Diffusion transformers \(DiTs\)\[peebles2023scalable,batifol2025flux,esser2024scaling,chen2024pixart,xie2024sana\]have recently pushed text\-to\-image generation to impressive quality around 1K resolution, enabled by efficient backbones, token compression, and carefully tuned training pipelines\[chen2024pixart,xie2024sana\]\. However, extending these systems to*native 4K*while supporting a broad spectrum of aspect ratios \(ARs\) is not a simple matter of scaling resolution\. At 4096×\\times4096 and beyond, we empirically observe three coupled challenges: \(i\)*positional representation and AR extrapolation*, where 2D rotary embeddings calibrated on a single training window can drift or alias under large changes in resolution and AR\[peng2023yarn,zhang2024hirope\]; \(ii\)*high\-frequency fidelity under VAE compression*, where higher downsampling factors improve throughput but tend to erase fine structures that dominate 4K perception\[xie2024sana,zhang2025diffusion\]; and \(iii\)*4K\-aware optimization*, where gradient contributions become heavily skewed across timesteps and frequency bands, making standard objectives poorly matched to the statistics of 4K latents\[hang2023efficient,zhang2025diffusion\]\. These factors interact: the choice of positional scheme, VAE compression ratio, and training objective jointly determines whether a model can remain stable and detailed across native 4K resolutions and diverse ARs\.
On the model side, several scaling strategies partially address these issues but leave the overall design space fragmented\. Training\-free high\-resolution methods mitigate tiling artifacts and duplication at inference time, yet largely preserve the underlying positional encoding and were not designed for systematic multi\-AR extrapolation\[zhang2024hidiffusion,huang2024fouriscale\]\. Decoder\-side approaches based on global–local fusion or tiled diffusion improve size flexibility but introduce new failure modes, such as coherence gaps across tiles or heavy reliance on a global prior for consistency\[haji2024elasticdiffusion,bar2023multidiffusion\]\. Native\-4K systems\[yu2025ultra,liu2024clear\]demonstrate that carefully engineered backbones can make 4K training tractable\[chen2024pixart,xie2024sana\], but most emphasize token/architecture efficiency and treat*positional robustness, VAE compression, and loss design*as largely orthogonal choices rather than a jointly optimized 4K regime\.
Progress at 4K is further constrained by the data itself\. Public 4K corpora are typically modest in scale \(on the order of10410^\{4\}–10510^\{5\}images\), heavily biased toward near\-square ARs and landscape\-centric content, and curated with early CLIP\-based aesthetic predictors\. For example, Aesthetic\-4K takes an important step by assembling high\-quality 4K image–text pairs with GPT\-4O captions\[zhang2025diffusion\], yet its scale and AR coverage remain limited for studying*resolution–AR coupling*, and its subject distribution under\-represents human\-centric scenes\. More critically, existing 4K datasets rarely provide the*structured metadata*needed for modern 4K training\. As a result, practitioners have limited control over sampling data slices tailored to specific training regimes \(e\.g\., high\-detail or high\-aesthetic subsets\), and it becomes difficult to perform fine\-grained aesthetic or AR\-conditioned analyses\.
On the optimization and adaptation side, recent work explores complementary—but still incomplete—directions\. Wavelet\-aware objectives at native resolution improve fidelity on strong backbones by better emphasizing high\-frequency content\[zhang2025diffusion\], yet they typically combine simple quadratic or perceptual penalties and thus remain vulnerable to cross\-scale dominance of low\-frequency energy\. Latent\-space super\-resolution and self\-cascade schemes sharpen details beyond the original training resolution and reduce the cost of high\-resolution transfer\[jeong2025latent,guo2024make\], but they operate as post\-hoc adapters on fixed backbones and do not resolve the underlying trade\-off between VAE compression and 4K reconstruction fidelity\. In parallel, timestep curricula adjust noise sampling while holding the data distribution fixed, and aesthetic post\-training applies high\-aesthetic data uniformly across timesteps, leaving unexplored the regime where*high\-noise steps—those most governed by the model prior—are selectively sculpted by high\-aesthetic supervision*\. Finally, existing RoPE interpolation and NTK\-style scaling strategies are primarily developed for 1D sequence length extrapolation, and provide little guidance for*2D token grids at native 4K under strongly varying ARs*, where misaligned phase behavior manifests as ghosting, drift, and striping artifacts\. Altogether, native 4K multi\-AR generation still lacks a unified framework that couples: \(i\) a large\-scale, multi\-AR, content\-diverse, VLM\-curated 4K corpus with rich metadata; \(ii\) an efficient, non\-adversarial VAE post\-training strategy that improves 4K reconstruction without sacrificing throughput; \(iii\) an SNR\-Aware Huber Wavelet Training Objective and a stage\-wise aesthetic curriculum matched to 4K statistics; and \(iv\) a training\-window aware, band\-aware, and AR\-aware positional encoding scheme\. In this work, we explicitly target this data–model co\-design space\.
Concretely, we make the following contributions:
- •MultiAspect\-4K\-1M: a large\-scale, multi\-AR, aesthetically curated 4K corpus\.We construct a 1M\-scale 4K dataset with native 4K and near\-4K resolution, controlled aspect\-ratio coverage, and a dual\-channel pipeline that debiases landscape\-heavy sources toward human\-centric content\. Each image is accompanied by decoupled VLM\-based quality and aesthetic scores, classical IQA signals, bilingual captions, and subject tags, providing the structured metadata needed for data–model co\-design\.
- •UltraFlux: a data–model co\-designed DiT for native 4K multi\-AR generation\.We train a Flux\-based backbone on MultiAspect\-4K\-1M with a co\-designed recipe that couples \(i\)*Resonance 2D RoPE with YaRN*for training\-window aware, band\-aware, and AR\-aware positional encoding, \(ii\) an*SNR\-Aware Huber Wavelet Training Objective*tailored to 4K latents, \(iii\) a*Stage\-wise Aesthetic Curriculum Learning \(SACL\)*scheme that concentrates high\-aesthetic supervision on high\-noise steps, and \(iv\) a simple, non\-adversarial, data\-efficient VAE post\-training procedure that improves Flux VAE reconstructions at 4K\. Together, these components yield a stable, detail\-preserving DiT for native 4K synthesis across diverse ARs\.
- •State\-of\-the\-art native 4K performance\.On standard 4K benchmarks and popular metrics covering fidelity, aesthetic quality, and text alignment, UltraFlux consistently outperforms strong 4K baselines, including recent native\-4K and training\-free scaling methods\.
## 2Related Work
This section reviews approaches to scaling text\-to\-image diffusion models to high\-resolution T2I, native‑4K and diverse aspect ratios\. We group prior work into three lines: training‑free inference‑time scaling, lightweight adaptations \(e\.g\., latent super‑resolution and self‑cascade\), and native‑4K training with 4K‑capable backbones\.
Training\-Free High\-Resolution Scaling\.Training\-free strategies extend pre\-trained 512–1K models to 2K/4K and diverse aspect ratios by modifying inference\-time computation, without re\-training\.*HiDiffusion*diagnoses duplication and quadratic self\-attention costs at high resolutions and introduces a resolution\-aware U\-Net and windowed attention to improve quality and speed\[zhang2024hidiffusion\]\.*FouriScale*approaches ultra\-high resolution from the frequency view via Fourier\-domain low\-pass guidance and dilated convolutions, improving global structure while injecting high frequencies\[huang2024fouriscale\]\. These approaches are effective for quick scaling, yet commonly*keep the original positional scheme unchanged*, which leaves*positional extrapolation stability under extreme ARs*only partially addressed\[zhang2024hidiffusion,huang2024fouriscale,haji2024elasticdiffusion,bar2023multidiffusion\]\.
Lightweight Adaptation: Latent SR and Self\-Cascade Models\.Lightweight adaptations improve high\-resolution quality with minimal cost by augmenting the sampling pipeline or attaching small modules\.*LSRNA*maps low\-res latents to a high\-res manifold via latent\-space super\-resolution and injects region\-wise noise to restore high\-frequency detail without retraining the base model\[jeong2025latent\]\.*Self\-Cascade Diffusion*integrates low\-resolution generation into the high\-resolution denoising process and optionally fine\-tunes small multi\-scale upsamplers, achieving rapid 4K adaptation at a fraction of full fine\-tuning cost\[guo2024make\]\. While these methods markedly sharpen details and reduce adaptation overhead, they typically*inherit the original positional scheme*, leaving*AR\-generalized extrapolation*under\-explored\[jeong2025latent,guo2024make\]\.
Native 4K Training and 4K\-Capable Foundation Models\.A complementary direction trains or fine\-tunes models directly at native‑4K and curates high\-quality 4K corpora\.*Diffusion\-4K*introduces Aesthetic\-4K and a wavelet\-based fine\-tuning scheme that improves fidelity and prompt alignment on large modern backbones\[zhang2025diffusion\]\. Meanwhile, efficient backbones such as*PixArt\-Σ\\Sigma*\(token\-compression attention\) and*Sana*\(32×\\timesVAE with linear\-attention DiT\) make 4096×\\times4096 synthesis computationally feasible at small model scales\[chen2024pixart,xie2024sana\]\. Despite these advances, public corpora remain limited in*scale and AR diversity*, constraining systematic study of*resolution–AR coupling*\.Moreover, end‑to‑end methodologies for stable native‑4K training are under‑documented and fragmented across implementations, slowing progress and curbing real‑world adoption while masking the gains of true 4K training\. A practical distinction concerns*native*versus*upscaler\-based*4K\. Unlike platform services that reach 4K primarily via 2×\\times/4×\\timesupscalers \(e\.g\., Midjourney\[MidJourney\]; Google Imagen\[Imagen\]exposes a dedicated upscaler; Ideogram offers a 2×\\timesUpscale endpoint\[ideogram2025upscale\]\), recent closed\-source leaders such as*Seedream 4*\[seedream2025seedream\]explicitly support*multi\-AR, native‑4K*generation within a unified T2I/editing architecture\. This distinction matters: cascade upscaling pipelines couple low\-resolution synthesis with a separate restoration prior, conflating high\-frequency fidelity and positional extrapolation, whereas native‑4K training compels the backbone to learn long\-range dependencies and cross\-AR spatial alignment directly\.Therefore, we treat native‑4K as a distinct training/evaluation regime and design both our data \(MultiAspect\-4K\-1M\) and recipe \(UltraFlux\) to isolate the gains of true 4K training from post\-hoc upscaling\.
## 3Method: Data–Model Co\-Design for Native 4K Multi\-AR Generation
### 3\.1MultiAspect\-4K\-1M Dataset
Design goals and scope\.Public 4K corpora for text\-to\-image training remain modest in scale \(typically below10510^\{5\}images\) and are usually curated with early CLIP\-based aesthetic predictors such as LAION\-Aesthetic\. While these datasets already achieve reasonably good visual quality, their*aspect\-ratio \(AR\) coverage*is coarse and imbalanced—only a few popular ARs are well\-populated at native 4K—and the textual side \(captions and aesthetic/quality supervision\) is constrained by legacy CLIP\-only scoring\. Our data design therefore targets three complementary gaps: \(i\)*broad multi\-AR coverage*at native 4K to avoid overfitting to a small set of AR buckets; \(ii\)*refreshed supervision quality*, coupling modern VLM\-based quality/aesthetics estimators instead of relying solely on legacy CLIP\-based predictors; and \(iii\)*distribution debiasing*that compensates for the over\-representation of landscapes and the under\-representation of human\-centric content in existing 4K sources\. We adopt a*VLM\-driven*filtering strategy—semantic quality via*Q\-Align*\[wu2023qalign\]and aesthetics via*ArtiMuse*\[cao2025artimusefinegrainedimageaesthetics\]—complemented by interpretable classical signals \(flatness and information entropy\), and a dedicated*character augmentation*branch to improve recall for human subjects\. Figure[2](https://arxiv.org/html/2511.18050v1#S3.F2)sketches the two\-channel pipeline and the final merge\.
Sources and overall structure\.After an NSFW safety check, we curate from a pool of approximately66M high\-resolution images whose subject distribution is skewed toward landscapes\. To operationalize the goals in Sec\.[3\.1](https://arxiv.org/html/2511.18050v1#S3.SS1), we adopt a*dual\-channel*pipeline: \(i\) ageneral, AR\-aware curationpath that enforces native/near\-4K resolution and broad aspect\-ratio \(AR\) coverage while filtering for quality and aesthetics; and \(ii\) ahuman\-centric augmentationpath that restores the underrepresented*character*category via open\-vocabulary detection\. The two channels are merged after de\-duplication and with consistent metadata \(resolution/AR, VLM scores, classical signals, caption, subject tags\), yielding*1M*images\. Figure[2](https://arxiv.org/html/2511.18050v1#S3.F2)provides a high\-level overview and stage\-wise retention\.
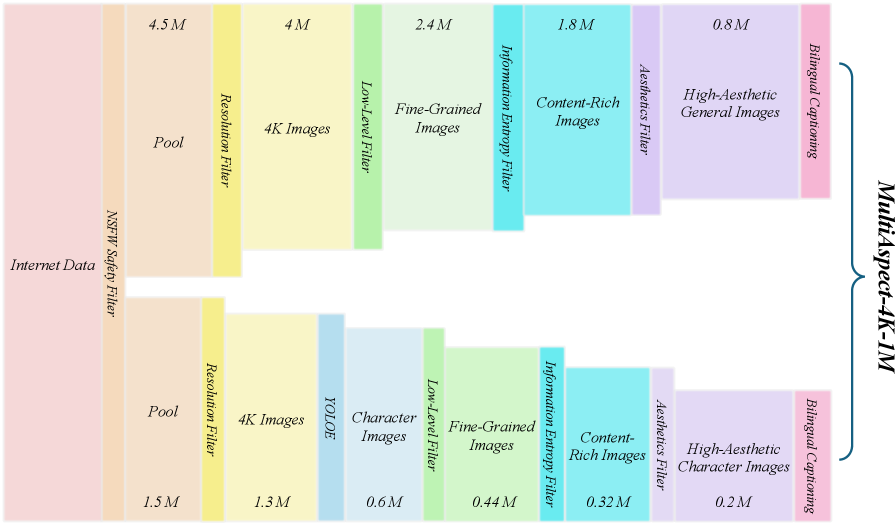Figure 2:Data Pipeline overview\.VLM\-based Filtering for HQ 4K Data\.We begin with a safety screen, then enforce a*pixel\-count threshold*as resolution filtering stage—images must have at least 3840×\\times2160 total pixels; we*preserve each image’s native aspect ratio without any resizing*\. This keeps the corpus artifact\-free while naturally retaining a wide spectrum of ARs \(e\.g\., 1:1, 16:9, 3:2, 4:3, 9:16\), enabling transparent auditing of AR coverage\. The resulting resolution and aspect\-ratio distribution across 4K corpora is visualized in Figure[4](https://arxiv.org/html/2511.18050v1#S3.F4)\. On this scaffold, we*decouple*qualityfromaesthetics: for quality we adopt*Q\-Align*, a large multimodal model \(LMM\)\-based visual scorer shown to deliver robust IQA judgments via discrete text\-level supervision, and for aesthetics we use*ArtiMuse*, a recent MLLM\-based image aesthetics evaluator that provides numeric scores together with*reasoned, expert\-style explanations*\(rather than score\-only outputs\)\. Classical, interpretable signals—*flatness*and*information entropy*—act as guardrails to suppress low\-texture or overly smooth images that VLMs may tolerate, yielding a cleaner, high\-frequency–preserving pool without sacrificing semantic clarity\.
Figure 3:Dataset example\.Figure 4:Dataset aspect and resolution analysis\. All datasets use 10k samples\. MultiAspect\-4K\-1M has a broader aspect ratio distribution\.Human\-centric augmentation via open\-vocabulary detector\.To correct the chronic under\-representation of people in 4K sources, we run a targeted augmentation path\. Candidate images are collected via person\-related retrieval under the same safety and resolution/AR checks\. We then apply the same*Q\-Align*and*ArtiMuse*filters, strengthened by*information entropy*to suppress low\-texture portraits\. Crucially, we require*structured evidence of human presence*usingYOLOE\[wang2025yoloerealtimeseeing\], a promptable open\-vocabulary detector, which improves both recall and precision beyond fixed\-class detectors\. The accepted subset is merged into the main pool with acharacterflag\.
Key statistics and comparisons to existing 4K and popular T2I datasets are summarized in Table[1](https://arxiv.org/html/2511.18050v1#S3.T1)\.
Table 1:Dataset statistical comparisons\.Bilingual captioning\.Captioning is performed*last*\. For the retained set, we generate detailed captions with*Gemini\-2\.5\-Flash*, a production multimodal model suitable for fast, high\-quality captioning; we then translate each caption into accurate Chinese with*Hunyuan\-MT\-7B*\[zheng2025hunyuan\]to serve bilingual users\. An example image with its metadata and bilingual captions is shown in Figure[3](https://arxiv.org/html/2511.18050v1#S3.F3)\.
The finalMultiAspect\-4K\-1Mcorpus comprises*1M*4K images with balanced coverage over standard AR buckets and a diversified subject mix \(landscapes, people, objects\)\. Each image includes resolution,*Q\-Align*,*ArtiMuse*, flatness/entropy, English/Chinese caption, and thecharactertag\. These fields are designed for transparent auditing and flexible data\-model co\-design:*they can act as analysis tags and stratified sampling keys for text\-to\-image training\.*
### 3\.2UltraFlux: Scaling Flux to Native 4K Image Generation
With the data foundation in place, we now turn to the model side and build*UltraFlux*\. Rather than redesigning the DiT architecture, we keep the core Flux transformer intact and focus on three components that bottleneck 4K performance: the VAE, the positional representation, and the training objective and strategy\. We first post\-train anF16F16VAE to recover fine details without giving up the efficiency gains of stronger compression, then introduce a Resonance 2D RoPE with a YaRN\-style extrapolation scheme to stabilize attention across resolutions and aspect ratios\. Finally, we couple an SNR\-aware Huber wavelet loss with a stage\-wise aesthetic curriculum that concentrates learning on high\-frequency structure and high\-aesthetic examples\. Together, these lightweight but targeted changes upgrade Flux into an efficient, high\-fidelity 4K generator that can fully exploit*MultiAspect\-4K\-1M*\.
#### 3\.2\.1VAE Post\-training for High\-resolution Reconstruction Fidelity
A strong but efficient VAE is essential for practical native 4K image generation\. The Flux backbone uses anF8F8VAE \(height/width downsampling by88\), which at 4K yields a very large latent grid and makes sampling prohibitively slow: in our profiling, a single 4K image with5050diffusion steps takes on the order of3030minutes\. Following Diffusion\-4K\[zhang2025diffusion\], we instead adopt anF16F16VAE, halving the latent resolution while keeping comparable channel capacity, and focus on*post\-training*the decoder to improve high\-resolution reconstruction fidelity\.
We fine\-tune the FluxF16F16decoder on our curated*MultiAspect\-4K\-1M*corpus to enhance fine\-scale 4K detail\. Ablations on loss design and training recipes lead to three key findings:*\(i\)*explicitly targeting high\-frequency content is essential—combining a wavelet reconstruction loss applied to high\-frequency sub\-bands with a feature\-space perceptual loss consistently outperforms purely pixel\-wise and perceptual objectives in sharpness and structural fidelity;*\(ii\)*once reconstruction reaches a reasonable regime, an adversarial discriminator offers negligible benefit—the GAN loss saturates quickly, induces optimization instability, and fails to improve perceptual quality, so our final recipe omits the adversarial term and retains only wavelet, perceptual andL2L\_\{2\}losses; and*\(iii\)*stringent data curation substantially reduces post\-training cost—by applying a flatness filter to select a high\-detail subset of*MultiAspect\-4K\-1M*, we obtain the bulk of reconstruction gains within around4k4\\text\{k\}update steps, and observe that a few hundred thousand carefully screened, detail\-rich images suffice to markedly upgrade the FluxF16F16VAE without multi\-day GAN training or tens of millions of samples\. This lightweight post\-training stage produces a decoder that preserves fine 4K structures while maintaining the throughput advantages ofF16F16compression, thereby enabling native 4K synthesis with both high fidelity and practical efficiency\.
#### 3\.2\.2Resonance 2D RoPE for Multi\-AR 4K Extrapolation
The official Flux backbone employs a fixed per\-axis rotary spectrum with an optional*global*NTK factor\[batifol2025flux\], following the standard RoPE formulation\[su2024roformer\]but without band\-specific treatment or training\-window awareness\. Consequently, the frequencies do not adapt to the inference sizeH×WH\{\\times\}W, and phase grows purely with position, which empirically destabilizes multi–aspect\-ratio generation at native 2K/4K\.
Flux baseline: 2D RoPE\.Following Flux, we assign rotary embeddings independently along height and width\. For each axisa∈\{H,W\}a\\in\\\{H,W\\\}with channel sizedad\_\{a\}andma=da/2m\_\{a\}=d\_\{a\}/2complex pairs, we use rotary baseb\>1b\>1and optional NTK factorη≥1\\eta\\geq 1to define per\-axis frequencies
ωk\(a\)=\(b⋅η\)−αk\(a\),αk\(a\)=2kda,k=0,…,ma−1,\\omega^\{\(a\)\}\_\{k\}\\;=\\;\(b\\cdot\\eta\)^\{\-\\alpha^\{\(a\)\}\_\{k\}\},\\qquad\\alpha^\{\(a\)\}\_\{k\}\\;=\\;\\frac\{2k\}\{d\_\{a\}\},\\qquad k=0,\\ldots,m\_\{a\}\-1,\(1\)and phases for a positionp=\(pH,pW\)p=\(p\_\{H\},p\_\{W\}\)\(in patches\)
ϕk\(a\)\(pa\)=paωk\(a\)\.\\phi^\{\(a\)\}\_\{k\}\(p\_\{a\}\)\\;=\\;p\_\{a\}\\,\\omega^\{\(a\)\}\_\{k\}\.\(2\)Writing each pair aszk\(a\)=x2k−1\(a\)\+ix2k\(a\)z^\{\(a\)\}\_\{k\}=x^\{\(a\)\}\_\{2k\-1\}\+i\\,x^\{\(a\)\}\_\{2k\}, we apply the usual complex rotationz~k\(a\)=zk\(a\)eiϕk\(a\)\(pa\)\\tilde\{z\}^\{\(a\)\}\_\{k\}=z^\{\(a\)\}\_\{k\}\\,e^\{\\,i\\,\\phi^\{\(a\)\}\_\{k\}\(p\_\{a\}\)\}, with wavelength \(in patches\)λk\(a\)=2π/ωk\(a\)\\lambda^\{\(a\)\}\_\{k\}=2\\pi/\\omega^\{\(a\)\}\_\{k\}\.
Resonance 2D RoPE\.Motivated by the Resonance RoPE idea for train\-short\-test\-long generalization in LLMs\[wang2024resonance\], we reinterpret the 2D rotary spectrum on a*finite*training window\. LetLH,LWL\_\{H\},L\_\{W\}be the training\-window lengths \(in patches\) along height and width, and letωk\(a\)\\omega^\{\(a\)\}\_\{k\}be the per\-axis frequencies from Eq\. \([1](https://arxiv.org/html/2511.18050v1#S3.E1)\)\. We define the number of cycles completed by component\(a,k\)\(a,k\)inside the training window as
rk\(a\)=Laλk\(a\)=Laωk\(a\)2π\.r^\{\(a\)\}\_\{k\}\\;=\\;\\frac\{L\_\{a\}\}\{\\lambda^\{\(a\)\}\_\{k\}\}\\;=\\;\\frac\{L\_\{a\}\\,\\omega^\{\(a\)\}\_\{k\}\}\{2\\pi\}\.\(3\)We then*snap*rk\(a\)r^\{\(a\)\}\_\{k\}to the nearest nonzero integer:
r^k\(a\)=max\(1,⌊rk\(a\)\+12⌋\),\\hat\{r\}^\{\(a\)\}\_\{k\}\\;=\\;\\max\\\!\\Big\(1,\\ \\big\\lfloor r^\{\(a\)\}\_\{k\}\+\\tfrac\{1\}\{2\}\\big\\rfloor\\Big\),\(4\)and replaceωk\(a\)\\omega^\{\(a\)\}\_\{k\}by its integer\-cycle projection
ω^k\(a\)=2πr^k\(a\)La\.\\hat\{\\omega\}^\{\(a\)\}\_\{k\}\\;=\\;\\frac\{2\\pi\\,\\hat\{r\}^\{\(a\)\}\_\{k\}\}\{L\_\{a\}\}\.\(5\)The phase becomes
ϕ^k\(a\)\(pa\)=paω^k\(a\),\\hat\{\\phi\}^\{\(a\)\}\_\{k\}\(p\_\{a\}\)\\;=\\;p\_\{a\}\\,\\hat\{\\omega\}^\{\(a\)\}\_\{k\},\(6\)and we reuse the same complex rotation as in the Flux baseline, now driven byϕ^k\(a\)\\hat\{\\phi\}^\{\(a\)\}\_\{k\}\. The snapped wavelength isλ^k\(a\)=2π/ω^k\(a\)=La/r^k\(a\)\\hat\{\\lambda\}^\{\(a\)\}\_\{k\}=2\\pi/\\hat\{\\omega\}^\{\(a\)\}\_\{k\}=L\_\{a\}/\\hat\{r\}^\{\(a\)\}\_\{k\}\.
Discussion\.Snappingr\(a\)∗kr^\{\(a\)\}\*\{k\}to the nearest nonzero integer turns each rotary band into a finite\-window “standing wave” on\[0,La\]\[0,L\_\{a\}\]that completes an exact integer number of cycles and has matching phase atpa=0p\_\{a\}=0andpa=Lap\_\{a\}=L\_\{a\}\. In the original Flux spectrum, many bands traverse the training window with a fractional number of cycles, so reusing the same frequencies at larger resolutions or different ARs accumulates half\-cycle phase error, which appears as spatial drift and faint striping, especially in high\-frequency channels\. By replacingω\(a\)∗k\\omega^\{\(a\)\}\*\{k\}in Eq\. \([1](https://arxiv.org/html/2511.18050v1#S3.E1)\) with their resonant counterpartsω^k\(a\)\\hat\{\\omega\}^\{\(a\)\}\_\{k\}, Resonance 2D RoPE makes the spectrum explicitly training\-window aware and prevents this fractional\-cycle build\-up, empirically reducing ghosting and striping artifacts when extrapolating to native\-4K multi\-AR grids\.
Resonance 2D RoPE with YaRN\.Inspired by the YaRN scheme for length extrapolation of 1D RoPE\[peng2023yarn\], we further make the extrapolation*band\-aware*\. Leta∈\{H,W\}a\\\!\\in\\\!\\\{H,W\\\}index spatial axes\. Given the training\-window lengthLaL\_\{a\}\(in patches\) and the*resonant*frequencyω^k\(a\)\\hat\{\\omega\}^\{\(a\)\}\_\{k\}with integer cyclesr^k\(a\)\\hat\{r\}^\{\(a\)\}\_\{k\}from the previous section, define the inference lengthLa′L^\{\\prime\}\_\{a\}and the extrapolation scalesa=La′/La≥1s\_\{a\}=L^\{\\prime\}\_\{a\}/L\_\{a\}\\\!\\geq\\\!1\. We use a linear ramp to map each band:
γ\(r;α,β\)=\{0,r<α,r−αβ−α,α≤r≤β,1,r\>β,0≤α<β,\\gamma\(r;\\alpha,\\beta\)=\\begin\{cases\}0,&r<\\alpha,\\\\\[2\.0pt\] \\dfrac\{r\-\\alpha\}\{\\beta\-\\alpha\},&\\alpha\\leq r\\leq\\beta,\\\\\[6\.0pt\] 1,&r\>\\beta,\\end\{cases\}\\qquad 0\\leq\\alpha<\\beta,\(7\)and interpolate between position\-interpolation scaling and no scaling using the resonant cycle count:
ωk,yarn\(a\)=\(1−γ\(r^k\(a\);α,β\)\)ω^k\(a\)sa\+γ\(r^k\(a\);α,β\)ω^k\(a\)\.\\omega^\{\(a\)\}\_\{k,\\mathrm\{yarn\}\}\\;=\\;\\bigl\(1\-\\gamma\(\\hat\{r\}^\{\(a\)\}\_\{k\};\\alpha,\\beta\)\\bigr\)\\,\\frac\{\\hat\{\\omega\}^\{\(a\)\}\_\{k\}\}\{s\_\{a\}\}\\;\+\\;\\gamma\(\\hat\{r\}^\{\(a\)\}\_\{k\};\\alpha,\\beta\)\\,\\hat\{\\omega\}^\{\(a\)\}\_\{k\}\.\(8\)The phase isϕk,yarn\(a\)\(pa\)=paωk,yarn\(a\)\\phi^\{\(a\)\}\_\{k,\\mathrm\{yarn\}\}\(p\_\{a\}\)=p\_\{a\}\\,\\omega^\{\(a\)\}\_\{k,\\mathrm\{yarn\}\}, and the complex rotation is identical to the Flux baseline\. Compared to Flux’s fixed spectrum with a single global NTK factor, Resonance 2D RoPE with YaRN first snaps frequencies to finite\-window resonant modes and then uses the axis\-wise cycle countsr^k\(a\)\\hat\{r\}^\{\(a\)\}\_\{k\}to decide how much to scale each band for a given extrapolation factorsas\_\{a\}\. This makes the positional encoding explicitly training\-window aware, band\-aware, and AR\-aware, and empirically enables more stable 2K/4K multi\-AR inference with negligible overhead\.
#### 3\.2\.3SNR\-Aware Huber Wavelet Training Objective
Motivation\.Wavelet\-space objectives such as*Diffusion4K*demonstrate that measuring errors in a multi\-scale transform can materially improve 4K fidelity\[zhang2025diffusion\], but at native 4K we empirically observe that standardL2L\_\{2\}\-based training on VAE latents still suffers from three coupled pathologies\. \(i\)*Frequency imbalance*—natural\-image wavelet coefficients are heavy\-tailed\[wainwright1999scale\], so large high\-frequency residuals \(textures, edges, micro\-geometry\) are aggressively shrunk by quadratic losses, leading to over\-smoothing of detail\. \(ii\)*Timestep imbalance*—gradients concentrate at extremely small or large noise levels, echoing Min\-SNR analyses that show inefficient use of intermediate timesteps\[hang2023efficient\]\. \(iii\)*Cross\-scale energy coupling*—low\-frequency bands dominate pixel/latent norms, so the high\-frequency errors that largely govern 4K perceptual quality receive disproportionately small gradient signal\[zhang2025diffusion\]\. To address these issues, we design a single objective that is simultaneously \(a\)*robust yet smooth*—using a Pseudo\-Huber penalty that behaves likeL2L\_\{2\}near zero andL1L\_\{1\}in the tails\[song2020improved\]; \(b\)*SNR\-aware*—with an adaptive thresholdc\(t\)c\(t\)that is small under high noise and grows as signal dominates; \(c\)*frequency\-aware*—by measuring residuals in an orthonormal wavelet space that decouples low and high bands; and \(d\)*time\-rebalanced*—via Min\-SNR weighting that emphasizes mid\-SNR timesteps for stable, faster optimization\[hang2023efficient\]\. These choices yield the*SNR\-Aware Huber Wavelet*objective, a drop\-in replacement for standard flow\-matching losses tailored to the demands of native 4K generation\.
Classical FM setup\.Prior work on flow matching for DiTs adopts a straight\-line interpolation between a clean latentzzand Gaussian noiseε\\varepsilon\[lipman2022flow,batifol2025flux\]:
zt=\(1−t\)z\+tε,t∈\(0,1\),ε∼𝒩\(0,I\)\.z\_\{t\}=\(1\-t\)\\,z\+t\\,\\varepsilon,\\qquad t\\in\(0,1\),\\ \\varepsilon\\sim\\mathcal\{N\}\(0,I\)\.\(9\)Under this parameterization, the DiT model predicts a velocity fieldvθ\(zt,t\)v\_\{\\theta\}\(z\_\{t\},t\)and the associated data\-prediction is
z^θ\(zt,t\)=zt−tvθ\(zt,t\)\.\\hat\{z\}\_\{\\theta\}\(z\_\{t\},t\)=z\_\{t\}\-t\\,v\_\{\\theta\}\(z\_\{t\},t\)\.\(10\)
To balance gradients across timesteps, we collapse the straight\-path factor and Min\-SNR into a single weight
ω\(t\)=t1−tmin\{SNR\(t\),γ\}β\.\\omega\(t\)=\\frac\{t\}\{1\-t\}\\,\\min\\\{\\mathrm\{SNR\}\(t\),\\gamma\\\}^\{\\beta\}\.\(11\)HereSNR\(t\)=\(1−t\)2/t2\\mathrm\{SNR\}\(t\)=\{\(1\-t\)^\{2\}\}/\{t^\{2\}\}under the straight FM path, withγ\>0\\gamma\>0andβ≥0\\beta\\geq 0\. We measure residuals in a wavelet space: letting𝒲\(⋅\)\\mathcal\{W\}\(\\cdot\)denote a one\-level orthonormal DWT \(sub\-bands concatenated along channels\), we compute the residualRθ\(x,ε,t\)=𝒲\(z^θ\(zt,t\)\)−𝒲\(z\)R\_\{\\theta\}\(x,\\varepsilon,t\)=\\mathcal\{W\}\(\\hat\{z\}\_\{\\theta\}\(z\_\{t\},t\)\)\-\\mathcal\{W\}\(z\)\. For robustness we use the Pseudo\-Huber penaltyρc\(r\)=c2\(1\+\(r/c\)2−1\)\\rho\_\{c\}\(r\)=c^\{2\}\\\!\\big\(\\sqrt\{1\+\(r/c\)^\{2\}\}\-1\\big\)\[song2020improved\]and schedule its threshold as
c\(t\)=cmin\+\(cmax−cmin\)\(min\{SNR\(t\),γ\}γ\)α\.c\(t\)=c\_\{\\min\}\+\(c\_\{\\max\}\-c\_\{\\min\}\)\\\!\\left\(\\frac\{\\min\\\{\\mathrm\{SNR\}\(t\),\\gamma\\\}\}\{\\gamma\}\\right\)^\{\\alpha\}\.\(12\)We takeα∈\[0,1\]\\alpha\\in\[0,1\], so thatc\(t\)c\(t\)is small and robust at low SNR and grows smoothly toward high SNR\. LetNNdenote the number of pixels after wavelet stacking\. The per\-pixel robust wavelet loss is
ℓHuber\(Rθ;c\(t\)\)=1N∑p=1Nρc\(t\)\(Rθ,p\),\\ell\_\{\\text\{Huber\}\}\\\!\\big\(R\_\{\\theta\};c\(t\)\\big\)=\\frac\{1\}\{N\}\\sum\_\{p=1\}^\{N\}\\rho\_\{\\,c\(t\)\}\\\!\\big\(R\_\{\\theta,p\}\\big\),\(13\)whereRθ,pR\_\{\\theta,p\}is thepp\-th element ofRθ\(x,ε,t\)R\_\{\\theta\}\(x,\\varepsilon,t\)\. Our final objective for the DiT of our UltraFlux becomes
ℒ\(θ\)=𝔼z,ε,t\[ω\(t\)ℓHuber\(Rθ;c\(t\)\)\]\.\\mathcal\{L\}\(\\theta\)=\\mathbb\{E\}\_\{z,\\varepsilon,t\}\\\!\\Big\[\\omega\(t\)\\;\\ell\_\{\\text\{Huber\}\}\\\!\\big\(R\_\{\\theta\};c\(t\)\\big\)\\Big\]\.\(14\)Settingc\(t\)→∞c\(t\)\\\!\\to\\\!\\inftyandβ=0\\beta\\\!=\\\!0recovers the standard flow\-matching objective on this path\.
Table 2:Quantitative comparison under 4K res\. with open\-source methods\.Table 3:Quantitative comparison with Sana at 4096×\\times2048 \(2:1\) and 2048×\\times4096 \(1:2\) resolutions\.
Table 4:Quantitative comparison with Sana at 5120×\\times2880 \(16:9\) and 5952×\\times2496 \(2\.39:1\) resolutions\.
Table 5:Quantitative comparison under 4K res\. with close\-source method\.
#### 3\.2\.4Stage\-wise Aesthetic Curriculum Learning
Recent analyses highlight that diffusion timesteps correspond to qualitatively different generation tasks, with high\-noise steps shaping global structure and low\-noise steps refining local details\[yi2024diffusion,kim2024denoising\]\. Building on this view, OmniSync\[peng2025omnisync\]assigns different datasets to different timestep ranges for lip\-synchronization, and several works propose timestep curricula or timestep\-dependent adaptation to focus training on harder noise regimes\[xu2024towards,soboleva2025t\]\. In parallel, aesthetic filtering and post\-training on high\-quality subsets \(e\.g\., LAION\-Aesthetics\[schuhmann2022laionaesthetics\]and subsequent aesthetic post\-training methods\[liang2025aesthetic\]\) have proven effective for improving visual appeal, but they typically apply a static high\-aesthetic prior uniformly across all timesteps\.
We instead couple the noise and data axes in a simple two\-stage scheme, which we term*Stage\-wise Aesthetic Curriculum Learning \(SACL\)*\. In Stage 1, we fine\-tune the model on the full*MultiAspect\-4K\-1M*corpus with standard timestep sampling over the entire diffusion horizon, giving the DiT backbone broad coverage of aspect ratios, content types, and noise levels\. Stage 2 then restricts training to a high\-noise band—timesteps above a threshold where the model relies most on its generative prior—and to the top\-5%5\\%images ranked by the ArtiMuse aesthetic score\. Intuitively, Stage 1 learns a general 4K prior across all denoising tasks, while Stage 2 concentrates the remaining compute on the hardest regime with ultra high\-aesthetic supervision\. Unlike prior timestep curricula, which modulate timestep sampling under a fixed data distribution\[yi2024diffusion,xu2024towards,kim2024denoising\], or aesthetic post\-training, which ignores the different roles of noise levels\[liang2025aesthetic\], SACL uses stage\-wise aesthetic filtering to define a curriculum over high\-noise timesteps, steering the global 4K generative prior toward high\-aesthetic modes precisely where the sampling process is most underdetermined and yielding substantial 4K aesthetic and alignment gains at modest additional training cost \(Sec\.[5](https://arxiv.org/html/2511.18050v1#S4.F5)\)\.
## 4Experiment
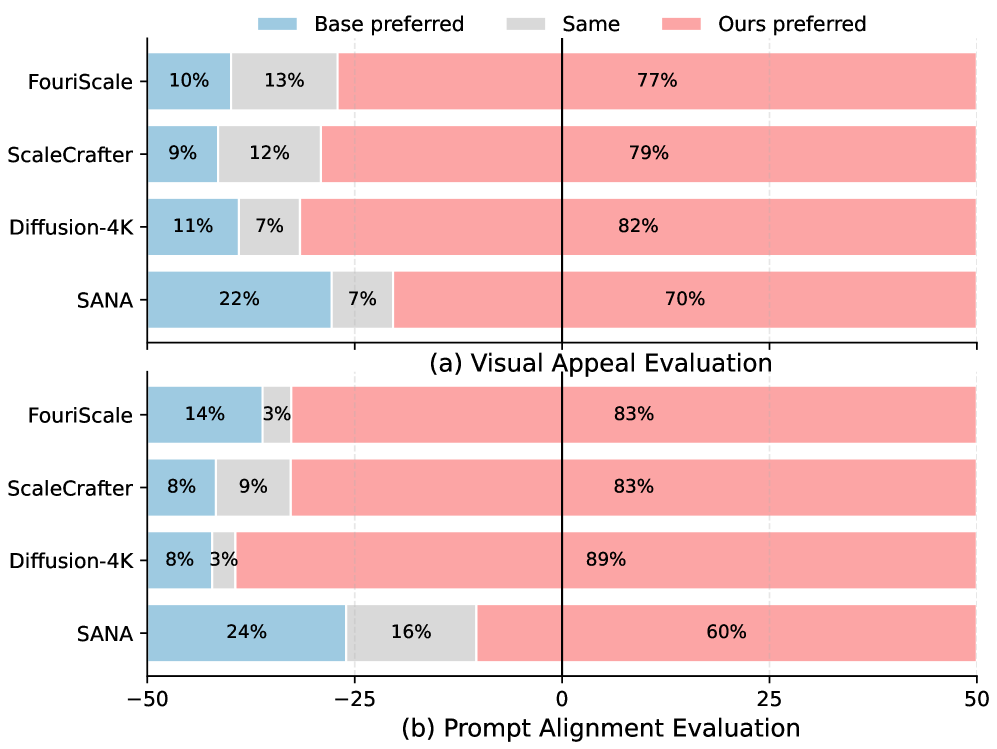Figure 5:Gemini\-2\.5\-Flash preference comparison\.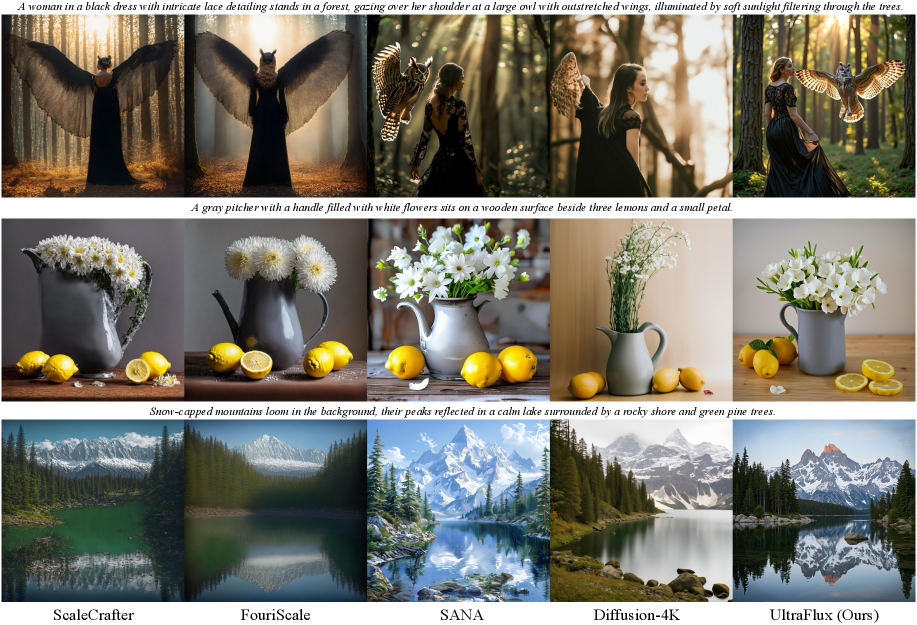Figure 6:Visual comparison of open\-source methods on the Aesthetic\-Eval@4096 benchmark at 4096×\\times4096 resolution\.### 4\.1Comparison with Open\-source Methods\.
Quantitative Comparison\.As shown in Table[2](https://arxiv.org/html/2511.18050v1#S3.T2), we compare our method against several strong baselines: ScaleCrafter\[he2023scalecrafter\]and FouriScale\[huang2024fouriscale\]as representative training\-free high\-resolution scaling methods, Sana\[xie2024sana\]as a recent native 4K text\-to\-image foundation model, and Diffusion\-4K\[zhang2025diffusion\]as a Flux\-based model trained natively at 4K resolution\. All methods are evaluated on the Aesthetic\-Eval@4096 benchmark\[zhang2025diffusion\]using FID\[heusel2017gans\], HPSv3\[ma2025hpsv3widespectrumhumanpreference\], PickScore\[Kirstain2023PickaPicAO\], ArtiMuse\[cao2025artimuse\], CLIP Score\[zhang2024long\], Q\-Align\[Q\-Align\]and MUSIQ\[MUSIQ\]\. Beyond the square setting, Table[4](https://arxiv.org/html/2511.18050v1#S3.T4)further shows that UltraFlux consistently matches or surpasses SANA across a range of non\-square 4K aspect ratios, delivering better semantic alignment, and perceptual quality even in challenging panoramic and wide ARs\. We also provide visual comparison as show in Figure[6](https://arxiv.org/html/2511.18050v1#S4.F6)\.
Gemini\-based Preference Evaluation\.To complement automatic metrics, we conduct a large\-scale pairwise preference study using*Gemini\-2\.5\-Flash*in reasoning mode as an LMM judge\. For each prompt and baseline, Gemini is shown the prompt and two anonymized images \(baseline vs\. UltraFlux\) and asked which it prefers in terms of*visual appeal*and*prompt alignment*, with ties allowed\. As summarized in Figure[5](https://arxiv.org/html/2511.18050v1#S4.F5), UltraFlux is preferred in7070–82%82\\%of cases on visual appeal and6060–89%89\\%on prompt alignment across all comparisons\.
### 4\.2Comparison with Close\-source 4K Native Generation Models
As shown in Table\.[5](https://arxiv.org/html/2511.18050v1#S3.T5)To make the comparison with*Seedream 4\.0*\[seedream2025seedream\]as fair as possible, we mirror its use of a large\-scale LLM\-based prompt refiner by evaluating*UltraFlux w\. Prompt Refiner \(Ours\)*with a GPT\-4O front\-end\. Under the same 4096×\\times4096 evaluation protocol, Table[5](https://arxiv.org/html/2511.18050v1#S3.T5)shows that UltraFlux with GPT\-4O achieves a slightly higher HPSv3 score than Seedream 4\.0 \(12\.03 vs\. 11\.98\), while remaining competitive on PickScore, ArtiMuse, and CLIP Score, and clearly surpassing it on Q\-Align and MUSIQ, which better capture semantic alignment and perceptual image quality\. This indicates that, once both systems are equipped with strong prompt refiners, our open\-source UltraFlux model trained on 1M images can closely track—and in some aspects exceed—the performance of a leading proprietary 4K generator\.Notably, Seedream 4\.0 further benefits from large\-scale RL post\-training, whereas our full pipeline relies solely on stage\-wise SFT\.
### 4\.3Ablation Study
Table 6:Ablation study on UltraFlux at 4K resolution training\.Starting from a Flux and trained F16 VAE baseline, replacing the standard latent regression loss with our SNR\-Aware Huber Wavelet Training \(SNR\-HW\) objective already yields consistent gains across metrics under the same 500K data&\\&10K steps fine\-tuning schedule, indicating that SNR\-aware wavelet supervision better balances high\-frequency detail preservation with stable optimization\. Introducing the SACL term on top of SNR\-HW further improves both human preference and aesthetic scores, suggesting that stronger text–image alignment is especially beneficial at native 4K\. Finally, equipping UltraFlux with Resonance 2D RoPE and YARN produces the best overall configuration, delivering monotonically improved perceptual and aesthetic metrics while also reducing FID\. Taken together, these ablations show that the proposed objective, alignment loss, and positional encoding contribute complementary gains rather than merely redistributing performance among metrics\.
## 5Conclusion
UltraFlux couples a carefully curated MultiAspect\-4K\-1M corpus with AR\-aware positional encoding, reconstruction, and optimization components into a unified framework for native 4K multi\-AR generation\. This data–model co\-design yields state\-of\-the\-art fidelity, aesthetic quality, and text alignment on standard 4K benchmarks while remaining computationally practical\.
\\thetitle
Supplementary Material
## Supplementary Overview
This document complements the main paper by \(i\) clarifying the regime\-level novelty of*UltraFlux*as a data–model co\-designed system for native 4K, multi\-AR text\-to\-image generation, and \(ii\) providing the analyses, metrics, and implementation details needed to faithfully reproduce and stress\-test our setup\. Rather than introducing isolated primitives, we make explicit how dataset curation, positional representation, VAE compression, and optimization objectives must be co\-designed to operate robustly in the 4K, multi\-AR regime\.
Organization\.Sec\. S1 \(*Clarifying Novelty and Data–Model Co\-Design*\) positions UltraFlux as a regime\-level, system\-oriented contribution and introduces a 2×\\times2 data–model ablation that disentangles the roles ofMultiAspect\-4K\-1Mand the UltraFlux architecture/loss\. Sec\. S2 \(*Implementation Details*\) expands on the dataset pipeline, DiT training schedule, VAE post\-training recipe, and key hyperparameters, including reconstruction metrics for our F16 VAE\. Sec\. S3 and Sec\. S4 provide focused analyses of Resonance 2D RoPE with YaRN and wavelet\-space statistics of 4K VAE latents, together with qualitative 4K visualizations, motivating our positional design and SNR\-Aware Huber Wavelet objective\. Sec\. S5–S7 report additional ablations, 4K runtime measurements, and more extensive quantitative comparisons at challenging wide aspect ratios, as well as extended visual comparisons against open\-source baselines\. Sec\. S8 discusses the main limitations of UltraFlux in terms of sampling cost, memory footprint, and aesthetic ceiling, while Sec\. S9 details our Gemini\-based preference evaluation and GPT\-4o prompt\-refiner setup used for large\-scale automatic assessment and prompt expansion\.
Taken together, these sections are intended to show that UltraFlux is a*regime\-level, system\-oriented contribution*rather than a mere aggregation of existing tricks, and to document the concrete choices required to make native\-4K, multi\-AR generation work in practice\.
## 6Clarifying Novelty and Data–Model Co\-Design
The main paper positions UltraFlux as a*data–model co\-designed recipe*for native\-4K, multi\-AR text\-to\-image generation\. Several of the building blocks—resonance\-style rotary encodings, wavelet objectives, Min\-SNR weighting, and aesthetic curricula—indeed draw inspiration from prior work\. Our contribution is not to claim each primitive as a standalone invention, but to show that: \(i\) at 4K with diverse aspect ratios, positional encoding, VAE compression, and optimization objectives form a*coupled regime*that existing methods treat largely in isolation; and \(ii\) a carefully unified design across*dataset, representation, and loss*yields behaviors that cannot be reproduced by swapping in any single component in isolation\.
To make this clearer, we provide in this supplement:
- •A data\-model ablation \(Table[7](https://arxiv.org/html/2511.18050v1#S6.T7)\) showing that neither a stronger 4K dataset nor architectural changes alone are sufficient: MultiAspect\-4K\-1M and UltraFlux each yield modest gains in isolation, while their combination delivers the full non\-additive improvements in 4K, multi\-AR fidelity\.
- •One\-dimensional and two\-dimensional diagnostics of Resonance 2D RoPE with YaRN \(Sec\.[8](https://arxiv.org/html/2511.18050v1#S8)\), analyzing cycle snapping, phase closure on the training window, and the stability of phase geometry under aspect\-ratio extrapolation\.
- •Wavelet\-space statistics of 4K VAE latents \(Sec\.[9](https://arxiv.org/html/2511.18050v1#S9)\) that empirically confirm the low\-frequency–dominated yet heavy\-tailed structure motivating our SNR\-Aware Huber Wavelet objective, clarifying why a robust, SNR\-aware wavelet loss is better aligned with the 4K regime than a pure latentL2L\_\{2\}objective\.
- •Expanded implementation details for the dataset pipeline, DiT training, and VAE post\-training \(Sec\. S2\), to facilitate faithful reproduction of our 4K native, multi\-AR training setup\.
We hope these analyses better convey that UltraFlux is a*regime\-level, system\-oriented contribution*rather than a mere aggregation of existing tricks\.
Table 7:2×\\times2 data–model co\-design ablation\. A: baseline; B: data only; C: model/loss only; D: full co\-design\.
## 7Implementation Details
### 7\.1Dataset Pipeline
Flat\-region detection\.For each image, we first partition it into non\-overlapping240×240240\\times 240patches and quantify the edge richness of every patch with a Sobel\-based score,
Sflat=Var\(\(∂xI\)2\+\(∂yI\)2\)\.S\_\{\\text\{flat\}\}=\\mathrm\{Var\}\\\!\\left\(\\sqrt\{\(\\partial\_\{x\}I\)^\{2\}\+\(\\partial\_\{y\}I\)^\{2\}\}\\right\)\.Patches withSflat<800S\_\{\\text\{flat\}\}<800are flagged as texture\-poor, and any image in which more than50%50\\%of the patches are flagged is removed from the dataset\. The patch\-level threshold of800800and the50%50\\%image\-level ratio are selected empirically via manual inspection of edge\-statistic histograms and visual audits\. This conservative configuration effectively filters out images dominated by large uniform regions while still retaining plausible low\-texture content such as sky and water, ensuring that the remaining images maintain sufficient edge and texture diversity for high\-fidelity generation\.
Information Entropy Filtering\.Each image is analyzed for its Shannon entropy to quantify the amount of information it contains\. The Shannon entropyHHof an image is defined as:
H=−∑i=1Np\(xi\)log2p\(xi\),H=\-\\sum\_\{i=1\}^\{N\}p\(x\_\{i\}\)\\log\_\{2\}p\(x\_\{i\}\),wherep\(xi\)p\(x\_\{i\}\)denotes the probability of the pixel valuexix\_\{i\}within the image\. Images with an entropy valueH<7\.0H<7\.0are flagged as texture\-poor, and any image in whichH<7\.0H<7\.0is removed from the dataset\. The threshold of7\.07\.0is selected empirically based on the observed distribution of entropy values across the dataset\. This threshold effectively filters out images with insufficient texture or information, ensuring that the remaining images exhibit adequate variability for high\-quality processing while preserving content diversity\.
Image Quality Filtering\.To ensure semantic quality, we compute the quality score for each image using*Q\-Align*\[wu2023qalign\]\. Images with a quality score greater than4\.04\.0are retained, while those below this threshold are discarded\. This threshold is determined empirically based on the distribution of quality scores across data sources, ensuring that only images with sufficient semantic clarity are kept for further analysis\.
Aesthetic Quality Filtering\.For aesthetic evaluation, we use the*ArtiMuse*\[cao2025artimusefinegrainedimageaesthetics\]model to compute aesthetic scores for each image\. Only the top30%30\\%of images, based on their aesthetic rating, are preserved\. This strategy ensures that images with higher aesthetic appeal are prioritized, while lower\-rated images are excluded from the dataset\. This filtering method helps maintain a diverse and aesthetically pleasing selection of images for further processing\.
### 7\.2Training Details
DiT Training\.We train*UltraFlux*, a large Flux\-based DiT model for native 4K text\-to\-image generation\. During DiT training, we freeze the VAE and text encoders and update all DiT blocks end\-to\-end\. Training is conducted on8×8\\timesNVIDIA H800 GPUs using DeepSpeed ZeRO\-2 \(without CPU offload\)\. We choose ZeRO\-2 because it shards optimizer states and gradients without partitioning model parameters, which substantially reduces memory usage while yielding higher throughput than ZeRO\-3 in our setting, enabling efficient 4K training\. We use AdamW with a learning rate of1×10−61\\times 10^\{\-6\}and an effective batch size of 64; the full training run takes roughly 12 days\. We adopt a two\-stage training schedule, with approximately 30K steps in the first stage and a further 2K steps in the second fine\-tuning stage \(Stage\-wise Aesthetic Curriculum Learning\)\. To support multi\-AR native 4K generation, we adopt a bucketed resolution scheme: for each image, we snap its resolution to the nearest target from a fixed set of landscape buckets \(e\.g\.,5120×28805120\\times 2880for 16:9,4704×31364704\\times 3136for 3:2\), portrait buckets \(e\.g\.,2880×51202880\\times 5120for 9:16,3136×47043136\\times 4704for 2:3\), and a single square bucket at3840×38403840\\times 3840, then center\-crop and resize the image to the selected bucket resolution\.
VAE Training\.For VAE post\-training, we fine\-tune the decoder on the proposed*MultiAspect\-4K\-1M*dataset, retaining the top50%50\\%of images according to the flatness score and training at512×512512\\times 512resolution with an effective batch size of 384\. We use AdamW with a learning rate of1×10−51\\times 10^\{\-5\}\.
Table 8:Reconstruction metrics of F16 VAEs on the Aesthetic\-4K@4096 Eval set\[zhang2025diffusion\]\.VAE reconstruction metrics and post\-training gains\.Table[8](https://arxiv.org/html/2511.18050v1#S7.T8)quantitatively compares ourUltraFlux\-F16\-VAEwith the Flux\-VAE\-F16 baseline on theAesthetic\-4K@4096evaluation set\[zhang2025diffusion\]\. Despite using the same F16 compression ratio, UltraFlux\-F16\-VAE achieves substantially better reconstruction quality across all metrics\. These consistent gains indicate that our post\-trained decoder not only preserves low\-frequency structure, but also better reconstructs high\-frequency details that are typically washed out under aggressive F16 compression\. Combined with the wavelet\-space analysis above, this suggests that the proposed post\-training scheme effectively aligns the VAE with the heavy\-tailed, cross\-scale statistics of native 4K images, narrowing the reconstruction gap\.
Table 9:Summary of training\-related hyperparameters for UltraFlux and associated components\. Values are left blank to be filled with the final configuration\.ComponentHyperparameterValueStage\-wise Aesthetic CurriculumStage 1 timestep range0–999Stage 2 timestep range0–459Stage 2 aesthetic filter \(ArtiMuse percentile\)top\-5%5\\%DiT objectiveWavelet type / number of levelsHaar,J=1J\{=\}1Pseudo\-Huber thresholds\(cmin,cmax\)\(c\_\{\\min\},c\_\{\\max\}\)cmin≈0\.2,cmax≈1\.0c\_\{\\min\}\{\\approx\}0\.2,\\;c\_\{\\max\}\{\\approx\}1\.0Resonance 2D RoPE with YaRNRoPE basebb10,00010\{,\}000NTK scaling factorη\\eta1\.01\.0YaRN ramp parameters\(α,β\)\(\\alpha,\\beta\)\(1\.25,0\.75\)\(1\.25,\\,0\.75\)Maximum extrapolation scalesa=La′/Las\_\{a\}=L^\{\\prime\}\_\{a\}/L\_\{a\}2\.02\.0F16 VAE post\-trainingTraining resolution512×512512\\times 512Global batch size \(images/step\)384Optimizer / learning rate / weight decayAdamW,1×10−41\\times 10^\{\-4\},1×10−21\\times 10^\{\-2\}Loss weights\(λwav,λperc,λL2\)\(\\lambda\_\{\\text\{wav\}\},\\lambda\_\{\\text\{perc\}\},\\lambda\_\{L\_\{2\}\}\)0\.2,0\.1,10\.2,\\,0\.1,\\,1Multi\-AR 4K DiT trainingLandscape target sizes \(W×\\timesH\)5440×30725440\{\\times\}3072,5184×32645184\{\\times\}3264,4992×33284992\{\\times\}33284736×35204736\{\\times\}3520,5824×28805824\{\\times\}2880,6272×26886272\{\\times\}26885568×30085568\{\\times\}3008,6336×26246336\{\\times\}2624,5632×30085632\{\\times\}30084608×36484608\{\\times\}3648Portrait target sizes \(W×\\timesH\)3072×54403072\{\\times\}5440,3648×46083648\{\\times\}4608,3520×47363520\{\\times\}47363328×49923328\{\\times\}4992Square target sizes \(W×\\timesH\)4096×40964096\{\\times\}4096
Figure 7:1D band\-wise analysis of Resonance 2D RoPE with YaRN\. \(a\) Number of cyclesrkr\_\{k\}in the training window and their integer\-snapped counterpartsr^k\\hat\{r\}\_\{k\}\. \(b\) Phase\-closure error\|Δϕk\|\|\\Delta\\phi\_\{k\}\|atp=Lp=L, showing exact closure for Resonance RoPE\. \(c\) Phase difference\|Δϕk\(p\)\|\|\\Delta\\phi\_\{k\}\(p\)\|between baseline and Resonance under2×2\\timeslength extrapolation, illustrating how fractional cycles in the baseline accumulate into large out\-of\-distribution phase errors\.Figure 8:Height–width cosine phase patterns for a representative rotary band under different aspect ratios\. Each panel displaysf\(h,w\)=cos\(hωH\+wωW\)f\(h,w\)=\\cos\(h\\,\\omega\_\{H\}\+w\\,\\omega\_\{W\}\)evaluated on anH×WH\{\\times\}Wpatch grid, with the top row using the Flux baseline frequencies and the bottom row using our resonant frequencies\. The first column shows the training resolution \(64×6464\{\\times\}64patches, AR1:11\{:\}1\); the remaining columns visualize extrapolation to128×64128\{\\times\}64\(2:12\{:\}1\),64×12864\{\\times\}128\(1:21\{:\}2\), and128×32128\{\\times\}32\(4:14\{:\}1\)\. At train scale, baseline and Resonance RoPE induce similar diagonal stripe patterns, indicating that resonance acts as a mild reparameterization of the spectrum\. Under aspect\-ratio extrapolation, the baseline stripes rotate and change spacing more aggressively, while our resonant variant maintains more regular, coherent patterns along both height and width, qualitatively echoing the improved phase stability observed in the 1D analyses\.
## 8Analyses of Resonance 2D RoPE with YaRN
Figure[7](https://arxiv.org/html/2511.18050v1#S7.F7)gives a 1D band\-wise diagnostic of Resonance 2D RoPE on a single spatial axis, which is then used by YaRN\. In panel \(a\), we plot the cycles completed in the training window of lengthLaL\_\{a\}by each rotary band,
rk\(a\)=Laωk\(a\)2π,r^\{\(a\)\}\_\{k\}\\;=\\;\\frac\{L\_\{a\}\\,\\omega^\{\(a\)\}\_\{k\}\}\{2\\pi\},together with their snapped counterparts
r^k\(a\)=max\(1,round\(rk\(a\)\)\)\.\\hat\{r\}^\{\(a\)\}\_\{k\}\\;=\\;\\max\\\!\\bigl\(1,\\;\\mathrm\{round\}\(r^\{\(a\)\}\_\{k\}\)\\bigr\)\.The Flux baseline \(blue\) yields a dense sequence of non\-integerrk\(a\)r^\{\(a\)\}\_\{k\}, whereas Resonance RoPE \(orange\) projects every band onto the nearest nonzero integerr^k\(a\)\\hat\{r\}^\{\(a\)\}\_\{k\}, producing a piecewise\-constant spectrum that leaves low\-frequency modes almost unchanged and regularizes higher ones\.
Panel \(b\) measures phase closure at the boundary of the training window\. For each band we evaluate the phase atpa=Lap\_\{a\}=L\_\{a\}using both the original frequencyωk\(a\)\\omega^\{\(a\)\}\_\{k\}and the resonant frequency
ω^k\(a\)=2πr^k\(a\)La,\\hat\{\\omega\}^\{\(a\)\}\_\{k\}\\;=\\;\\frac\{2\\pi\\,\\hat\{r\}^\{\(a\)\}\_\{k\}\}\{L\_\{a\}\},and plot the absolute phase mismatch\|Δϕk\|\|\\Delta\\phi\_\{k\}\|betweenpa=0p\_\{a\}=0andpa=Lap\_\{a\}=L\_\{a\}\. The baseline shows up to several radians of mismatch, while Resonance RoPE drives\|Δϕk\|\|\\Delta\\phi\_\{k\}\|to zero for all bands, confirming that every component becomes an exact standing wave on\[0,La\]\[0,L\_\{a\}\]\.
Panel \(c\) visualizes the phase difference between the baseline and Resonance RoPE under a2×2\\timesresolution extrapolation\. For positionspa∈\[0,2La\]p\_\{a\}\\in\[0,2L\_\{a\}\]we compute
Δϕk\(pa\)=wrap\(paωk\(a\)−paω^k\(a\)\),\\Delta\\phi\_\{k\}\(p\_\{a\}\)\\;=\\;\\mathrm\{wrap\}\\bigl\(p\_\{a\}\\,\\omega^\{\(a\)\}\_\{k\}\-p\_\{a\}\\,\\hat\{\\omega\}^\{\(a\)\}\_\{k\}\\bigr\),wherewrap\(⋅\)\\mathrm\{wrap\}\(\\cdot\)maps angles to\[−π,π\]\[\-\\pi,\\pi\], and plot\|Δϕk\(pa\)\|\|\\Delta\\phi\_\{k\}\(p\_\{a\}\)\|as a heatmap over\(k,pa\)\(k,p\_\{a\}\)\. The discrepancy is small near the training window but grows systematically with both position and frequency, illustrating how fractional cycles in the original spectrum accumulate into large out\-of\-distribution phase errors\. Since YaRN subsequently applies band\-wise scaling to these already integer\-cycle–aligned modes, the combined Resonance 2D RoPE with YaRN inherits training\-window awareness while achieving stable, AR\-robust extrapolation in 2D\.
2D spatial visualization\.Figure[7](https://arxiv.org/html/2511.18050v1#S7.F7)analyzes Resonance 2D RoPE with YaRN along a single spatial axis\. To understand how these band\-wise changes translate into actual image\-plane geometry, we further visualize 2D cosine patterns in Figure[8](https://arxiv.org/html/2511.18050v1#S7.F8)\. For a representative rotary band, we construct
f\(h,w\)=cos\(hωH\+wωW\),f\(h,w\)\\;=\\;\\cos\\\!\\big\(h\\,\\omega\_\{H\}\+w\\,\\omega\_\{W\}\\big\),on different height–width grids, where\(ωH,ωW\)\(\\omega\_\{H\},\\omega\_\{W\}\)are taken either from the Flux baseline or from the resonant frequencies\. The leftmost column corresponds to the training resolution \(64×6464\{\\times\}64patches, AR1:11\{:\}1\), while the remaining columns show extrapolation to128×64128\{\\times\}64\(2:12\{:\}1\),64×12864\{\\times\}128\(1:21\{:\}2\), and128×32128\{\\times\}32\(4:14\{:\}1\)\. At the training scale, baseline and Resonance RoPE produce very similar diagonal stripe patterns, consistent with the fact that snappingrkr\_\{k\}tor^k\\hat\{r\}\_\{k\}only slightly perturbs low\-frequency modes\. Across more extreme aspect ratios, however, the baseline stripes exhibit more pronounced changes in orientation and spacing, whereas the Resonance patterns remain more regular and coherent\. This 2D view complements the 1D diagnostics: once each band forms an integer\-cycle standing wave on the training window, spatial phase geometry varies more smoothly when scaling to multi\-AR 2K/4K grids\.
## 9Wavelet\-Space Statistics of 4K VAE Latents
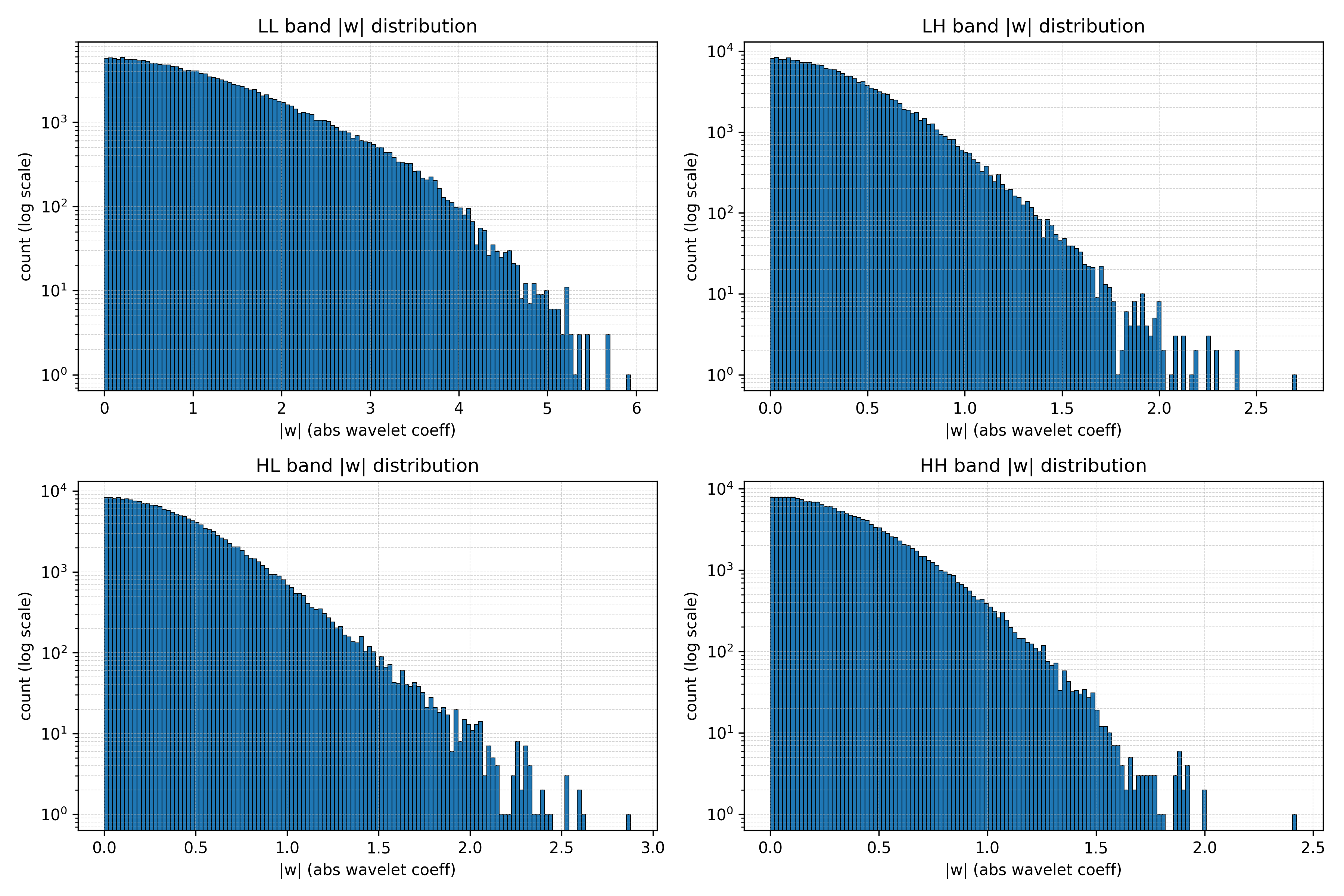Figure 9:Wavelet\-space statistics of 4K VAE latents\. We show log\-count histograms of absolute coefficients for the LL, LH, HL, and HH subbands over 400 samples\. Most energy resides in the LL band, while high\-frequency bands carry sparse but large\-magnitude coefficients, indicating heavy\-tailed behavior\. This cross\-scale structure motivates our SNR\-Aware Huber Wavelet objective\.In the main paper \(Section 3\.2\.3,*SNR\-Aware Huber Wavelet Training Objective*\) we argue that native 4K generation suffers from*\(i\) frequency imbalance and \(ii\) cross\-scale energy coupling: low\-frequency bands dominate latent norms, while high\-frequency, perceptually critical structures appear as sparse, large\-magnitude coefficients that are poorly handled by purely quadratic losses\.*Here we provide an empirical characterization of this effect in the VAE latent space used by UltraFlux\. We sample 400 images fromMultiAspect\-4K\-1M, encode them with our F16 VAE, and apply a one\-level orthonormal DWT to the resulting latents\. Figure[9](https://arxiv.org/html/2511.18050v1#S9.F9)shows log\-count histograms of the absolute wavelet coefficients in the LL, LH, HL, and HH subbands\. The energy distribution is strongly skewed across scales: the LL band accounts for87\.4%of the total latent energy \(mean per\-band energy3\.553\.55\), while each high\-frequency band contributes only3\.53\.5–4\.7%4\.7\\%\. At the same time, all bands exhibit pronounced heavy tails\. For example, in the LH band20\.8%20\.8\\%of coefficients satisfy\|w\|\>0\.5\|w\|\>0\.5,3\.2%3\.2\\%exceed\|w\|\>1\.0\|w\|\>1\.0, and values up to\|w\|≈7\.2\|w\|\\approx 7\.2occur; HL and HH show similar tail behavior\.
Figure 10:Qualitative effect of Resonance 2D RoPE with YaRN\.We compare three positional encodings at native 4K resolution for the same prompts\. \(a\) Flux\.1 2D RoPE baseline*without*any scaling at inference time, which tends to exhibit geometric drift and mild striping or warping artifacts in both foreground objects and backgrounds\. \(b\) 2D RoPE with YaRN scaling, which stabilizes the overall layout but still shows subtle distortions along long contours and in extreme regions of the image\. \(c\) Our proposed*Resonance 2D RoPE with YaRN*, which yields the most coherent global geometry and sharper, more regular fine structures \(e\.g\., ring edges and tree trunks\)\.These statistics quantitatively support the motivation in the main paper: at 4K resolution, VAE latents are dominated by low\-frequency energy, yet contain sparse, large\-magnitude high\-frequency coefficients that encode textures, edges, and micro\-geometry\. Under a standardL2L\_\{2\}latent loss, these heavy\-tailed residuals are aggressively shrunk, and gradients are largely governed by the LL band, leading to over\-smoothing of detail and weak supervision for high\-frequency errors\. This empirical evidence motivates our design of the SNR\-Aware Huber Wavelet objective, which replaces pureL2L\_\{2\}with a wavelet\-space, Pseudo\-Huber penalty with SNR\-dependent thresholds to better balance low\- and high\-frequency reconstruction errors in the 4K regime\.
## 10Additional Ablations
Figure[10](https://arxiv.org/html/2511.18050v1#S9.F10)provides a visual counterpart to the analyses in Sec\.[8](https://arxiv.org/html/2511.18050v1#S8)\. The Flux\.1 2D RoPE baseline without scaling \(a\) reuses its training\-time spectrum at 4K and produces noticeable geometric drift: objects appear slightly stretched or misaligned and backgrounds show faint striping\. Introducing YaRN scaling alone \(b\) reduces these artifacts by making the spectrum resolution\-aware, but residual phase misalignment still leads to mild warping along long contours\. Our Resonance 2D RoPE with YaRN \(c\) first snaps each band to an integer\-cycle standing wave on the training window and then applies band\-wise YaRN scaling, yielding visibly more stable composition and cleaner high\-frequency details, especially in the delicate structures of fur, foliage, and planetary rings\.
## 11Efficiency Comparison
Table 10:Inference time per 4K sample at 4096×\\times4096 resolution\.Table[10](https://arxiv.org/html/2511.18050v1#S11.T10)reports the wall\-clock time required for each method to generate a single 4096×\\times4096 sample under the same hardware and sampler configuration\. UltraFlux and Sana operate in a similar runtime regime, while both are several times faster than ScaleCrafter and FouriScale, whose 4K pipelines incur substantially higher latency\. In other words, UltraFlux achieves our best 4K fidelity and aesthetic metrics without introducing extra inference cost relative to the strongest open baseline, and remains markedly more efficient than earlier 4K upsampling\-based approaches\.
## 12More Quantitative Comparison with SOTA Methods at Wide Aspect Ratios
To provide a more comprehensive evaluation of performance at challenging wide aspect ratios, including 2:1 \(4096×2048\), 1:2 \(2048×4096\), 16:9 \(5120×2880\), and the cinematic 2\.39:1, we compare with SOTA methods across four distinct acpect ratios and resolutions, as detailed in Table[11](https://arxiv.org/html/2511.18050v1#S12.T11)\. The results show that UltraFlux consistently surpasses the performance all competing methods across all tested aspect ratios and metrics, demonstrating its effectiveness in generating high\-quality images for diverse wide\-format scenarios\.
Table 11:Quantitative comparison with SOTA methods at different aspect ratios, including 4096×\\times2048 \(2:1\), 2048×\\times4096 \(1:2\), 5120×\\times2880 \(16:9\), and 5952×\\times2496 \(2\.39:1\) resolutions\.
## 13Qualitative Comparison with SOTA Methods at Wide Aspect Ratios
This section provides visual comparisons with SOTA methods at wide aspect ratios, complementing our quantitative analysis in Table[11](https://arxiv.org/html/2511.18050v1#S12.T11)\. The results are presented in Fig\.[14](https://arxiv.org/html/2511.18050v1#S17.F14)\(1:2\), Fig\.[15](https://arxiv.org/html/2511.18050v1#S17.F15)\(2:1\), Fig\.[16](https://arxiv.org/html/2511.18050v1#S17.F16)\(16:9\) and Fig\.[17](https://arxiv.org/html/2511.18050v1#S17.F17)\(1:2\.39\), respectively\.
At the 1:2 aspect ratio, all methods produce visually plausible results without severe artifacts\. However, our results are more visually appealing with better composition and aesthetic quality\. In the 2:1 case, methods such as Scalecrafter and Fouriscale exhibit noticeable structural distortions and artifacts, while Sana also shows visible flaws\. In contrast, our method generates remarkably natural and coherent images\. At the 2\.39:1 ultra\-wide ratio, both Scalecrafter and Fouriscale suffer from mild misalignment with text prompts as well as detail degradation\. Our results not only avoid these issues but also outperform Sana in overall visual quality\.
These observations demonstrate that our approach consistently maintains state\-of\-the\-art performance and high visual fidelity across a spectrum of challenging aspect ratios\.
## 14Additional Visual Comparison With Open\-Source methods
In Figures[11](https://arxiv.org/html/2511.18050v1#S17.F11)–[13](https://arxiv.org/html/2511.18050v1#S17.F13), additional visual comparisons are provided\. From the results, we observe that ScaleCrafter sometimes produces images with noticeable distortions, while FouriScale occasionally struggles to fully capture textual content\. The images generated by SANA, on the other hand, can appear somewhat overly smoothed or ”oily\.” In contrast, compared to Diffusion\-4K, our method consistently delivers higher\-quality images with more visually appealing results, offering a more pleasant overall experience\.
## 15Limitations
Although UltraFlux substantially improves native\-4K, multi\-AR generation over prior open\-source baselines, the system still has several practical limitations\.
Sampling cost and memory footprint\.First, UltraFlux is not yet a*efficient*4K generator\. Even with the F16 VAE and our optimized DiT backbone, sampling at native 4K with 50–60 flow\-matching steps remains noticeably slower than 1K\-class models and requires a high\-end 50GB GPU to avoid aggressive offloading\. This compute and memory footprint limits deployment to research\- or data\-center–grade hardware, and makes large\-scale 4K sampling expensive compared to lower\-resolution pipelines or distilled student models\.
Aesthetic ceiling and robustness\.Second, while our data–model co\-design delivers consistent gains in automatic metrics and Gemini\-based preference studies, the aesthetic quality is not uniformly top\-tier across all prompts and domains\. In challenging cases, UltraFlux can still produce occasional over\-smoothed textures, minor geometric artifacts, or compositions that are less polished than those from heavily engineered proprietary systems\. Our co\-design focuses on the 4K \+ multi\-AR regime rather than absolute peak aesthetics, and there remains headroom for further preference alignment, prompt understanding, and content diversity\.
Scope of co\-design\.Finally, the present work primarily co\-designs dataset, positional encoding, VAE, and loss under a single large DiT backbone\. We do not address complementary axes such as sparse or low\-rank attention, lightweight decoders, or distillation to smaller 4K models, which could significantly reduce memory usage and latency\. Extending UltraFlux\-style co\-design to more parameter\-efficient architectures and to broader data domains \(e\.g\., specialized scientific or medical imagery\) is an important direction for future work\.
## 16Details About Gemini\-based Preference Evaluation\.
In this section, we provide additional details on the Gemini\-based preference evaluation used to assess the visual quality and prompt alignment of different models\. As part of this evaluation, Gemini\-2\.5\-Flash, in reasoning mode, is employed to judge image pairs based on their aesthetic appeal and alignment with the given prompt\. The following is an example of the exact prompt used for evaluating*aesthetic preferences*in our study\. For each image pair, Gemini is asked to assess various aspects such as composition, sharpness, lighting, and overall visual appeal, ensuring that the evaluation process is both consistent and reproducible\.
Prompt 16\.1 \(Pairwise Preference for Aesthetics\)You are an impartial image aesthetics judge\. Compare Image A and Image B, and decide which one better fits human aesthetic preferences overall\.Evaluate:•Composition•Sharpness / clarity•Lighting / contrast•Color harmony•Noise / compression artifacts•Overall visual appealBe decisive; only return"tie"if the two images are nearly identical in quality\.Return strictly in the following JSON format \(no explanations, no extra text\):[⬇](data:text/plain;base64,ewogICAgInByZWZlcnJlZCI6ICJBIHwgQiB8IHRpZSIsCiAgICAiYV9zY29yZSI6IDAtMTAwLAogICAgImJfc2NvcmUiOiAwLTEwMCwKICAgICJyZWFzb25zIjogInNob3J0IGV4cGxhbmF0aW9uIgp9)\{"preferred":"A\|B\|tie","a\_score":0\-100,"b\_score":0\-100,"reasons":"shortexplanation"\}
## 17Details About Prompt Refiner using GPT\-4O\.
Prompt 17\.1 \(GPT\-4O Prompt Refining Process\)System prompt:You are a senior prompt refiner for AI image generation\. Expand each short prompt into a single rich, high\-aesthetic prompt\.Requirements:•Length: 55–100 words; one line per item; no newlines, numbering, or quotes\.•Preserve the original subject and intent; do not invent brands, copyrighted IP, or named people\.•Composition: camera angle, shot size/framing, focal length or lens type, foreground/midground/background, environment context\.•Subject attributes: age range, gender expression where implied, appearance details \(hair/eyes/skin or material\), clothing/fabric, pose, expression/action\.•Lighting and color: key light quality/direction, color temperature, time of day/season/weather, palette or dominant hues\.•Style/medium: photographic or cinematic unless the input implies another medium; mention film look or post\-processing if appropriate\.•Quality: tasteful, coherent, non\-repetitive language; avoid keyword stuffing\.User prompt:Short prompts: \{list of input prompts\}Language: Write outputs in\[language\]\(Chinese/English\); one line per item\. For each input, produce exactly one refined prompt; avoid lists, bullets, or line breaks inside items\.Expected output format:[⬇](data:text/plain;base64,WwogICJSZWZpbmVkIHByb21wdCAxIiwKICAiUmVmaW5lZCBwcm9tcHQgMiIsCiAgLi4uCl0=)\["Refinedprompt1","Refinedprompt2",\.\.\.
To further refine the quality of input prompts, we employ GPT\-4o as a front\-end for our*UltraFlux w\. Prompt Refiner \(Ours\)*configuration\. The process of prompt refinement involves transforming short and concise prompts into more detailed, high\-aesthetic descriptions suitable for image generation tasks\. The GPT\-4o model expands each input prompt into a rich description, incorporating essential elements such as composition, lighting, subject attributes, and stylistic choices\. The refined prompts follow a strict set of guidelines to maintain coherence, clarity, and aesthetic quality, ensuring that they meet the requirements for high\-fidelity image generation\. In the following example, we provide the exact system prompt and user instructions used to guide GPT\-4o in refining a list of short prompts\. The prompts are designed to ensure that the model generates visually appealing and contextually appropriate descriptions for each input\. This prompt refining process ensures that the generated prompts are detailed, high\-quality, and aligned with the intended visual aesthetics\. The use of GPT\-4o to refine short prompt significantly enhances the input quality, making it suitable for use in high\-fidelity image generation tasks\.
Figure 11:More visual comparison of open\-source methods on the Aesthetic\-Eval@4096 benchmark at 4096×\\times4096 resolution\.Figure 12:More visual comparison of open\-source methods on the Aesthetic\-Eval@4096 benchmark at 4096×\\times4096 resolution\.Figure 13:More visual comparison of open\-source methods on the Aesthetic\-Eval@4096 benchmark at 4096×\\times4096 resolution\.Figure 14:Visual comparison of open\-source methods at 1:2 aspect ratio \(2048x4096\)\.Figure 15:Visual comparison of open\-source methods at 2:1 aspect ratio \(4096x2048\)\.Figure 16:Visual comparison of open\-source methods at 16:9 aspect ratio \(5120x2880\)\.Figure 17:Visual comparison of open\-source methods at 1:2\.39 aspect ratio \(2496x5952\)\.Similar Articles
FLUX.2 [pro]
Black Forest Labs has released Flux 2 Pro, a new image generation and editing model with improved text rendering, photorealism, and character consistency. The model is available via API on Replicate.
PixVerve: Advancing Native UHR Image Generation to 100MP with a Large-Scale High-Quality Dataset
This paper introduces PixVerve-95K, a large-scale open-source dataset of 95K ultra-high-resolution (100MP) images with annotations, and PixVerve-Bench, a benchmark for evaluating native 100MP text-to-image generation, extending existing T2I models to unprecedented resolutions.
HiDream-ai/HiDream-O1-Image
HiDream-ai has open-sourced HiDream-O1-Image (8B), a unified image generative foundation model built on a Pixel-level Unified Transformer (UiT) that natively handles text-to-image, image editing, and subject-driven personalization at up to 2048×2048 resolution without external VAEs or disjoint text encoders. It debuted at #8 in the Artificial Analysis Text to Image Arena and is positioned as a leading open-weights text-to-image model.
Illuminating Unified Multimodal Model for Free-form Interleaved Text-Image Generation
ILLUME-X is a unified multimodal model for free-form interleaved text-image generation, featuring improved data efficiency, stable training, and a comprehensive evaluation metric called ILScore. It outperforms previous models on tasks like style transfer, image decomposition, and storytelling.
FLUX3D: High-Fidelity 3D Gaussian Generation with Diffusion-Aligned Sparse Representation
FLUX3D introduces a framework for high-fidelity image-to-3D Gaussian Splatting generation by enhancing representation learning and cross-modal alignment with diffusion-aligned structured latents and a sparse-structure-aware diffusion transformer, achieving state-of-the-art results.