@RuohanZhang76: Excited to introduce StereoPolicy, led by @EvansXuHan. StereoPolicy is an effective way to add geometric cues to modern…
Summary
Introduces StereoPolicy, a framework that leverages synchronized stereo image pairs to improve geometric reasoning for robot manipulation policies, avoiding the fragility of RGB-D and point clouds. It integrates with diffusion-based and vision-language-action policies, showing consistent improvements in simulation and real-world tasks.
View Cached Full Text
Cached at: 06/04/26, 03:58 AM
Excited to introduce StereoPolicy, led by @EvansXuHan.
StereoPolicy is an effective way to add geometric cues to modern robot policy models while keeping the strengths of pretrained 2D encoders.
Why stereo for robot manipulation?
Monocular RGB often lacks the depth cues needed for precise manipulation, while RGB-D and point clouds can be noisy or brittle, especially on reflective and transparent objects in real-world deployment.
Instead of explicitly reconstructing disparity, depth, or point clouds, StereoPolicy directly fuses synchronized left/right RGB views to learn implicit stereo cues, avoiding extra reconstruction latency that can make real-time manipulation difficult.
Project Page: https://stereopolicy.github.io
StereoPolicy: Improving Robotic ManipulationPolicies via Stereo Perception
Source: https://stereopolicy.github.io/ Huang Huang1Jianwen Xie3Jiajun Wu1Li Fei-Fei1Ruohan Zhang1,2
1Stanford University2Northwestern University3Lambda, Inc
Preprint
Abstract
Recent advances in robot imitation learning have produced powerful visuomotor policies that manipulate diverse objects from visual inputs. However, monocular observations lack depth information, which is critical for precise manipulation in cluttered or geometrically complex scenes. Explicit depth maps and point clouds are often noisy and fragile in real-world manipulation. We introduceStereoPolicy, a visuomotor policy learning framework that directly leverages synchronized stereo image pairs to improve geometric reasoning without constructing explicit 3D representations. StereoPolicy processes each image with pretrained 2D vision encoders and fuses left-right features through a cross-attention-based Stereo Transformer, capturing spatial correspondence and disparity cues implicitly. The framework integrates with diffusion-based and pretrained vision-language-action (VLA) policies, delivering consistent improvements over RGB, RGB-D, point cloud, and multi-view baselines across three simulation benchmarks and seven real-robot tabletop and bimanual mobile manipulation tasks. Our results show that stereo vision bridges 2D pretrained representations and 3D geometric understanding for robotic manipulation.
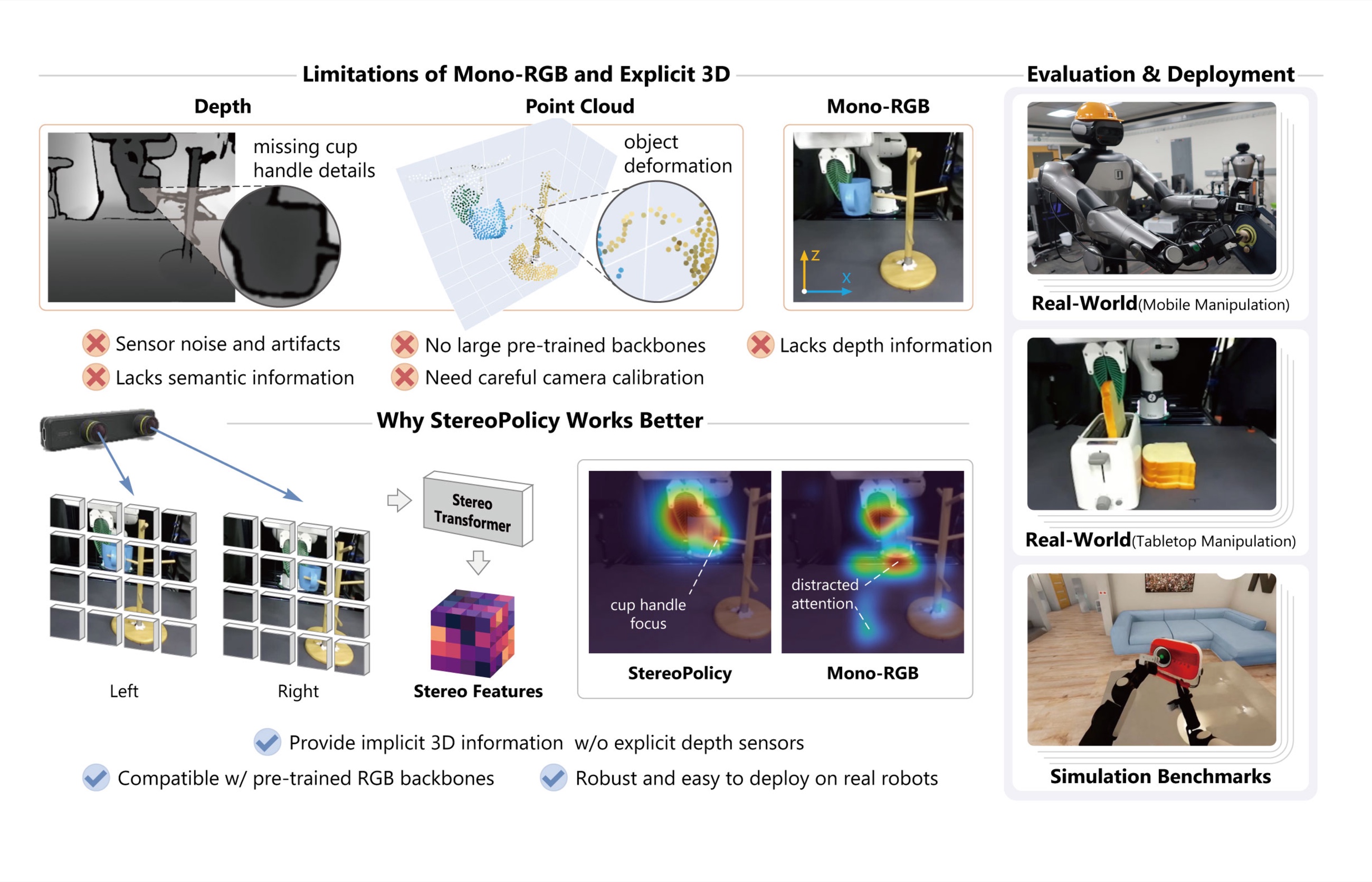
RGB-D and PCD are fragile in real world deployment
Hover to zoom
Regular Cup Hang
External-View Stereo RGB Reference
Left CameraRight Camera

Depth VisualizationDepth misses the cup handle and thin rack geometry.
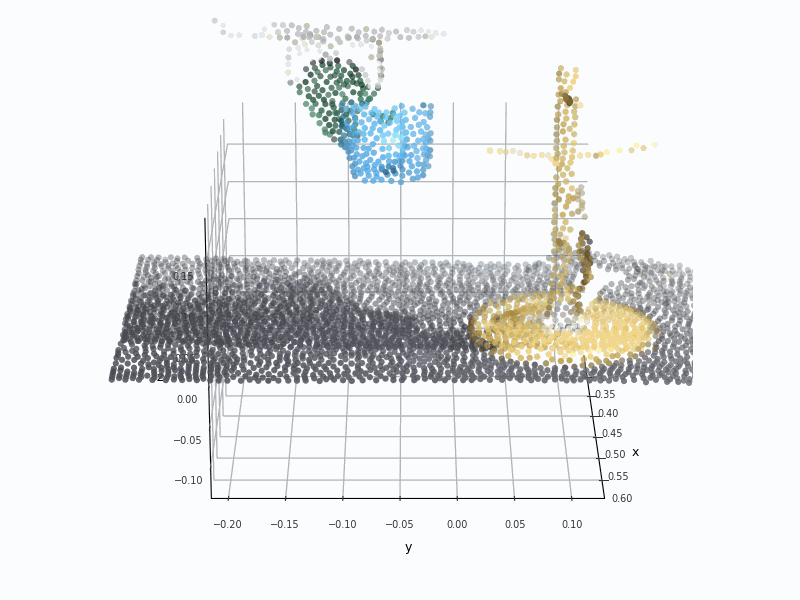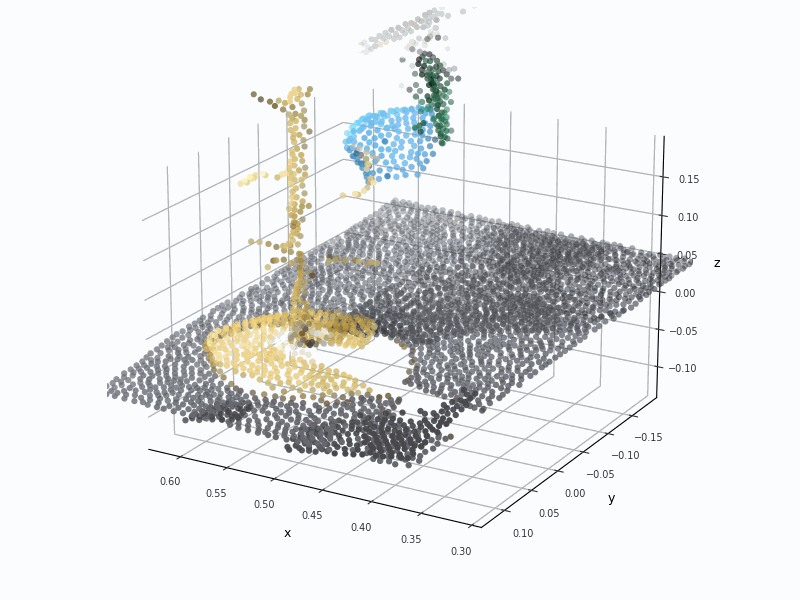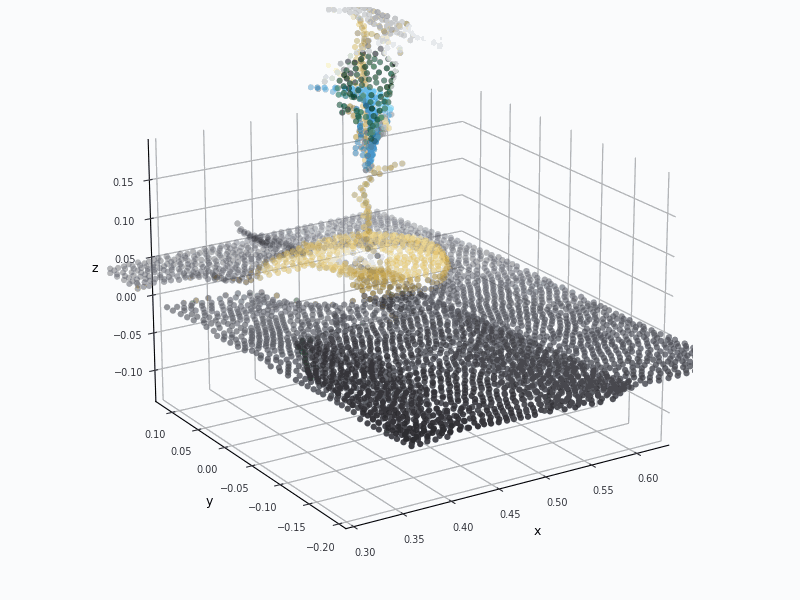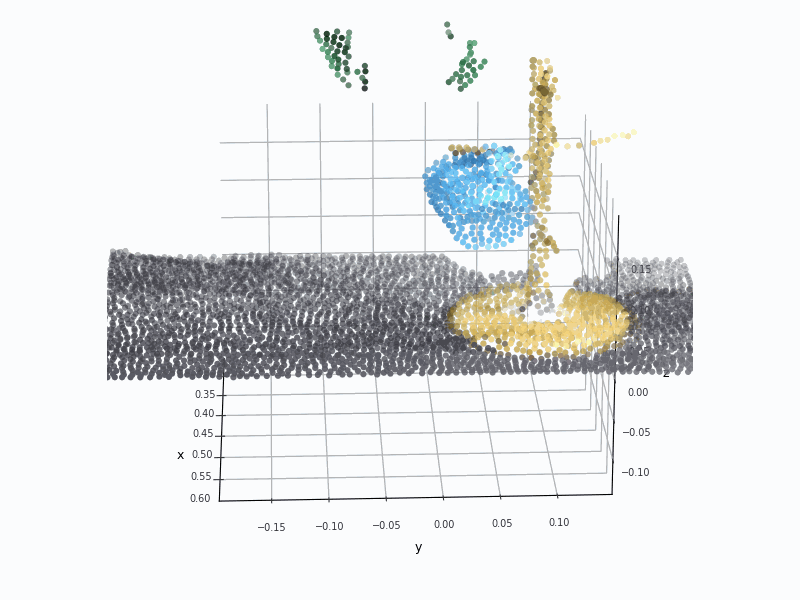
Point Cloud (PCD) VisualizationPCD deforms the cup and rack structure.
Glass Cup Hang
External-View Stereo RGB Reference
Left CameraRight Camera
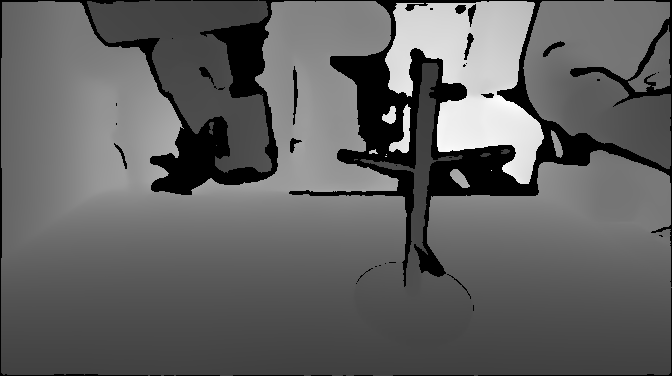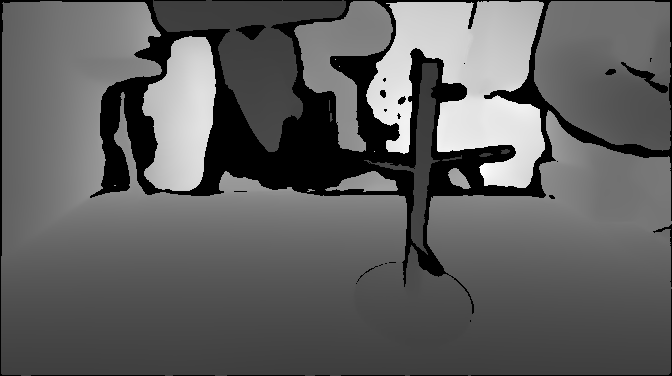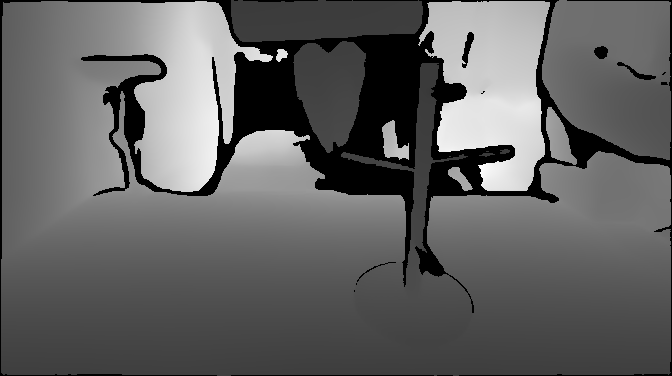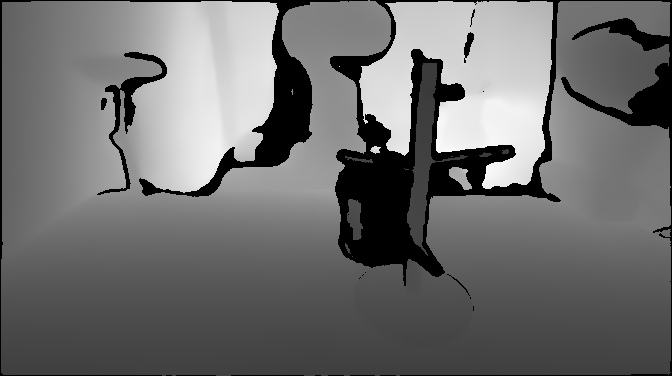
Depth VisualizationDepth misses the transparent cup surface.
Point Cloud (PCD) VisualizationPCD loses most of the glass cup geometry.
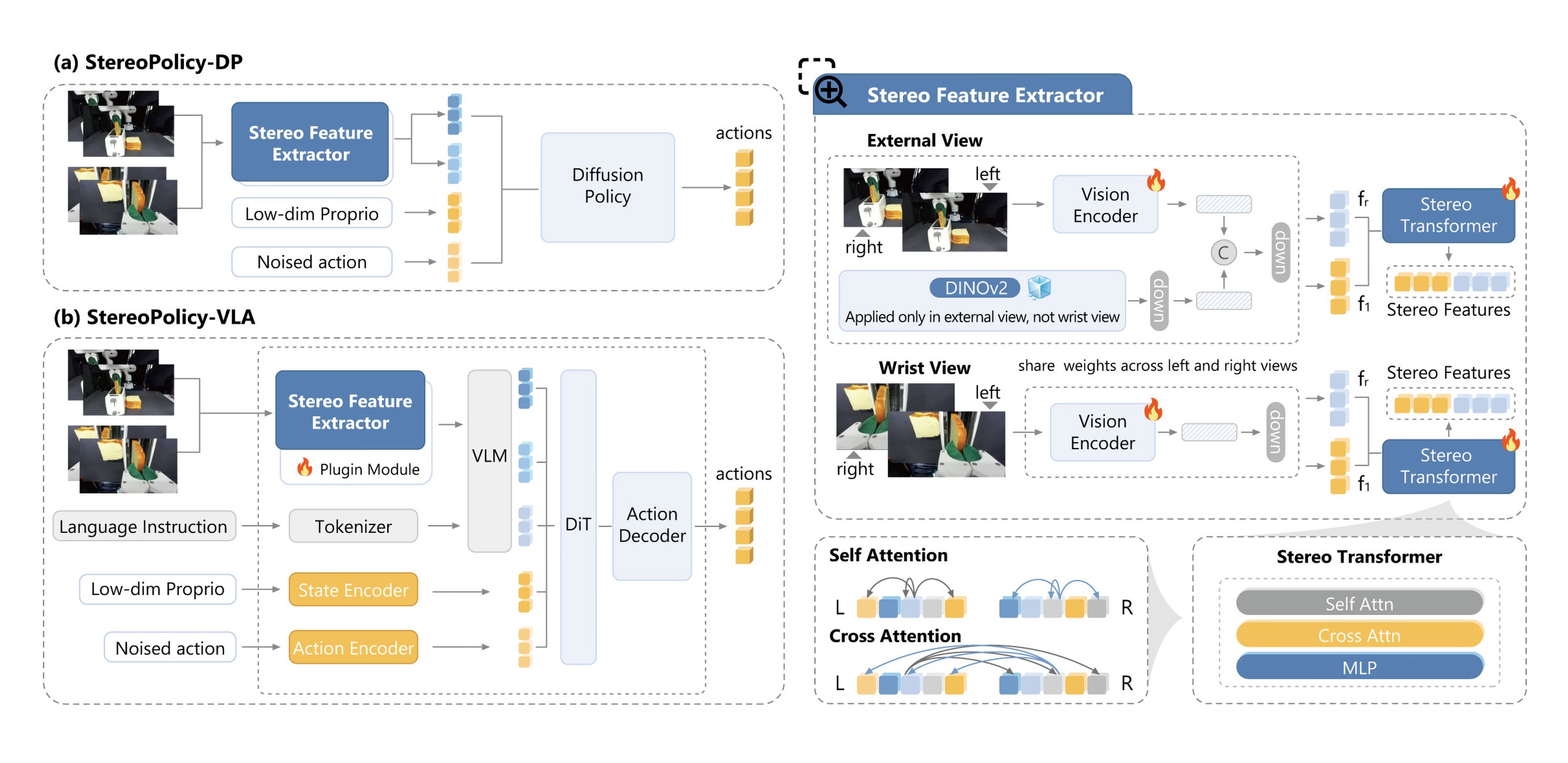
Overview of StereoPolicy
Hover a module, then click to highlight it and read how it works.
Click a module in the pipeline
StereoPolicy directly turns synchronized stereo images into geometry-aware policy features, bridging pretrained 2D visual representations with implicit 3D spatial reasoning.
**Pipeline of StereoPolicy.**A stereo perception module to extract geometry-aware features for robot policies. The resulting representations can be seamlessly integrated into both diffusion policies and VLA models without modifying their backbone architectures.
- StereoPolicy-DPintegrates stereo encoder into diffusion policy, trained from scratch on each benchmark task.
- StereoPolicy-VLAcombines the stereo encoder with pre-trained VLA model and fine-tunes the system.
Real-World Deployments
Bimanual Mobile Manipulation
Turn On Radio
PnP Toast
Bimanual Mobile Manipulation
StereoPolicy-VLA (Pi0.5)performance onbimanual mobile manipulation tasksin both real-world and simulation settings (success rate over 20 trials).
Tabletop Manipulation
Interactive demos
Select a tabletop task to inspect its synchronized third-person and wrist stereo views.
Videos are shown from the original 3x recordings.
PnP Banana
External Stereo View
Left CameraRight Camera
Wrist Stereo View
Left CameraRight Camera
Performance
Tabletop Manipulation
MethodBanana PnPToast InsertPlastic Cup HangSteel Cup HangGlass Cup HangAVG SR (%)RGB12/207/2012/2010/201/2042.0%RGBD14/208/2011/208/200/2041.0%RGBD-3DDA13/209/2013/2010/200/2045.0%PCD-PointNet7/200/205/202/200/2014.0%PCD-DP311/203/208/205/200/2027.0%MultiView13/208/2013/209/201/2044.0%StereoPolicy-DP16/2012/2015/2013/203/2059.0% Real-World Tabletop Task Performance.****StereoPolicy-DPconsistently outperforms other visual modalities. PCD performs worst in all real tasks; both RGBD and PCD fail on glass cup hang tasks.
Baseline Modalities Failure Cases
Mobile Manipulation
Failure Case 1
Imprecise radio-handle grasp.
Failure Case 2
Imprecise button press.
Failure Case 3
Imprecise toast grasp.
Tabletop Manipulation
Tabletop failure videos are shown at 2x speed.
Failure Case 1
Toast misses slot.
Failure Case 2
Insertion misaligned.
Failure Case 3
Cup grasp misses.
Failure Case 4
Imprecise handle insertion.
Failure Case 5
Transparent cup missed.
Simulation Benchmarks
 #### Diffusion Policy Performance
#### Diffusion Policy Performance
MethodOmniGibsonRoboMimicStrawberryPour WaterOpen DoorTurn On RadioTool HangSquareTransport100200100200200300200300100200100200100200RGB59.0%88.0%10.0%46.0%26.0%77.0%42.0%71.0%53.0%90.0%74.0%98.0%92.0%94.0%RGB-D63.0%85.0%16.0%52.0%31.0%80.0%47.0%73.0%56.0%88.0%79.0%92.0%**94.0%**94.0%RGBD-3DDA74.0%93.0%26.0%61.0%48.0%**100.0%**46.0%75.0%84.0%92.0%83.0%97.0%**94.0%****96.0%**PCD-DP345.0%63.0%3.0%31.0%30.0%69.0%35.0%64.0%40.0%76.0%69.0%88.0%63.0%72.0%MultiView68.0%89.0%21.0%52.0%31.0%75.0%43.0%71.0%54.0%92.0%78.0%96.0%92.0%94.0%StereoPolicy-DP82.0%100.0%34.0%70.0%57.0%100.0%55.0%82.0%94.0%96.0%88.0%100.0%94.0%96.0% **Simulation Task Performance of Diffusion Policies over Different Visual Modalities.**Stereo input consistently improves performance, especially under low-data regime.
VLA Average Performance on RoboCasa-Kitchen 24 Tasks
PI0.575%40%48.7151.7267.6471.5470.3174.4030100300Number of DemosRGBStereoGROOT-N1.575%40%44.9847.1263.5866.1764.3067.5030100300Number of DemosRGBStereoAverage StereoPolicy-VLA Performance on RoboCasa-Kitchen 24 Tasks.
Citation
@misc{han2026stereopolicyimprovingroboticmanipulation,
title={StereoPolicy: Improving Robotic Manipulation Policies via Stereo Perception},
author={Evans Han and Yunfan Jiang and Yingke Wang and Haoyue Xiao and Huang Huang and Jianwen Xie and Jiajun Wu and Li Fei-Fei and Ruohan Zhang},
year={2026},
eprint={2605.09989},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2605.09989},
}
Similar Articles
@artemZholus: thanks! in the second paper (https://arxiv.org/abs/2605.06388) we used your (and RAE's) recipe and it worked.
This paper systematically compares reconstruction-based and semantic latent spaces for action-conditioned latent diffusion world models in robotics. It finds that semantic encoders like V-JEPA 2.1 generally outperform reconstruction encoders on policy-relevant metrics, advocating for semantic latent spaces as a stronger foundation for robotics world models.
Structured Role-Aware Policy Optimization for Multimodal Reasoning
This paper introduces Structured Role-Aware Policy Optimization (SRPO), a method that improves multimodal reasoning in Large Vision-Language Models by assigning token-level credit based on distinct perception and reasoning roles within reinforcement learning frameworks.
αDepth: Learning Single-Pass Soft Boundary Decomposition for Stereo Conversion
αDepth introduces a layered representation with Circular Alpha Representation (CAR) to address soft boundary challenges in stereo conversion, achieving state-of-the-art performance without manual guidance.
@verityw_: Generalist robot policies learn many useful skills. How can we elicit relevant behaviors when faced with new tasks? We …
Introduces Flow Reversal Steering (FRS), a method to refine coarse actions from semantic reasoning into precise robot actions by reversing and re-denoising through a flow-matching generalist policy, improving zero-shot control and enabling policy learning.
@_akhaliq: CHORUS Decentralized Multi-Embodiment Collaboration with One VLA Policy
CHORUS is a decentralized method enabling multiple robots with different embodiments to collaborate using a single Vision-Language-Action policy.