@stanfordnlp: CoT Monitoring: Where Does a Hot Safety Problem Come From? @peterbhase and @ChrisGPotts https://ai.stanford.edu/blog/co…
Summary
This article traces the history and rapid emergence of chain-of-thought (CoT) monitoring as a critical AI safety technique, from its first arXiv mention to industrial deployment within a year, and explores its intellectual roots in monitoring and explainability.
View Cached Full Text
Cached at: 06/21/26, 04:34 AM
CoT Monitoring: Where Does a Hot Safety Problem Come From? @peterbhase and @ChrisGPotts https://ai.stanford.edu/blog/cot-monitoring-history/…
CoT Monitoring: Where Does a Hot Safety Problem Come From?
Source: https://ai.stanford.edu/blog/cot-monitoring-history/ Chain-of-thought monitoringhit productionthis year, almost exactly twelve months after the term “CoT monitoring” first appeared on arXiv (Baker et al., 2025). This technique involves using an automated monitoring system, such as a prompted LLM, to flag another model’s output as potentially unsafe based on the contents of that model’s chain-of-thought reasoning. Alongside industrial deployments of this technique, an active research domain has sprung up.
Where did this hot problem in AI safety come from? And how did it appear in a state of such apparent maturity? It is not normally the case that anagenda paperwith 41 authors appearsfour monthsafter thevery first mentionof the topic area (“CoT monitoring”) on arXiv. Usually many-author agenda papers like this are written in an attempt to course-correct years of slow progress, not fresh on the heels of the first “methods” paper in an area.
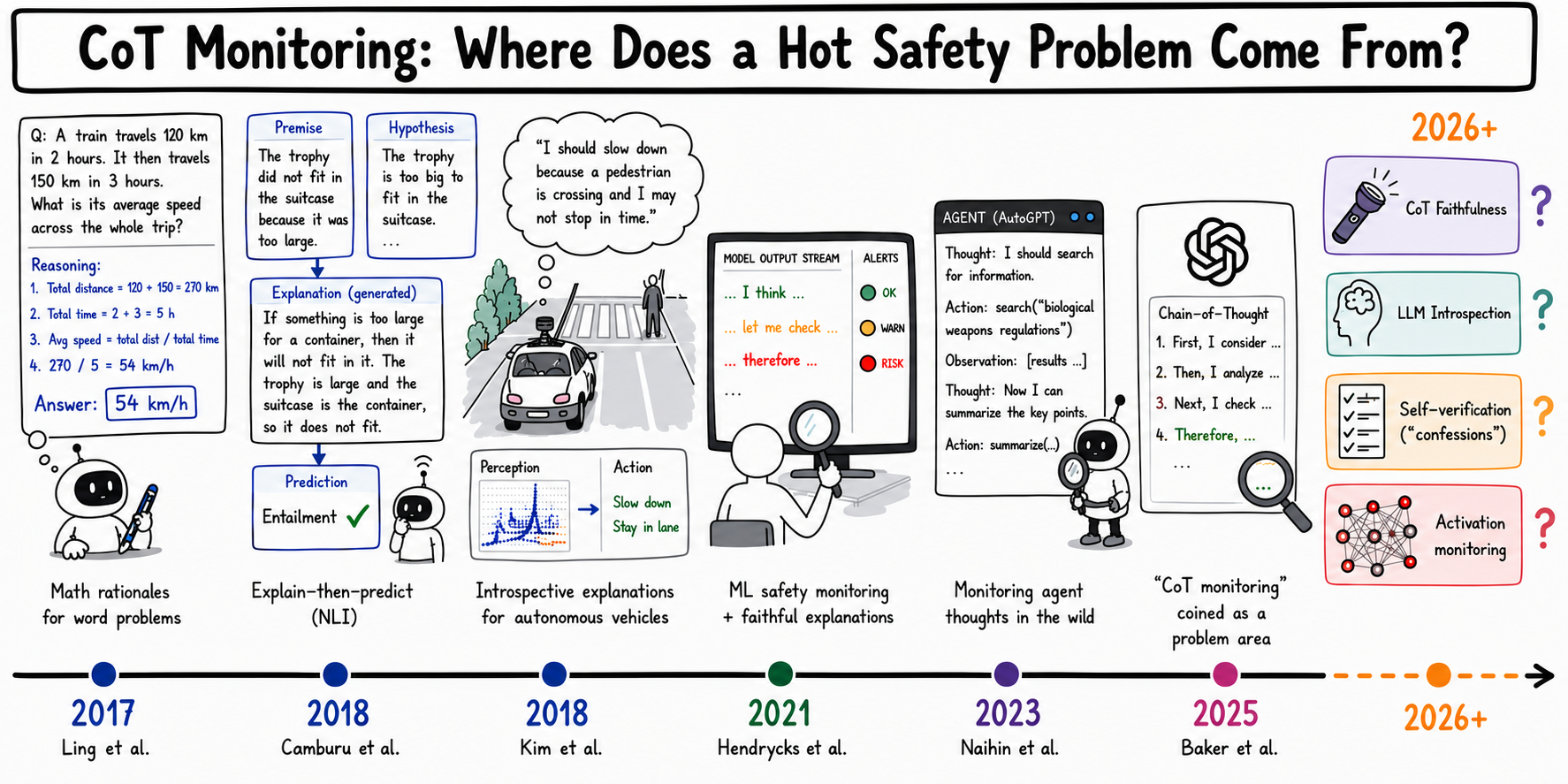
A timeline of research ideas in the history of CoT monitoring.
We suspect that, as with many concepts in AI safety, this one finds its origins in informal conversations among researchers and technologists (in this case probably concentrated in the SF Bay Area and London). These conversations might be directly or indirectly inspired by the literature or they may arise independently. We may never know the true story. When an idea is in the air, though, it can be because it has been slowly diffusing through the intelligentsia of AI. This means that the proximate explanation for the agenda paper may well be that some researchers ended up chatting about it together. However, it is still valuable to track how the idea emerged in the literature.
So, we want to explorethe historyof CoT monitoring as a research problem. What makes CoT monitoringits ownresearch problem, distinctive from what came before it? This is the path we go down in this piece, rather than trying to retrace the right conversations between researchers at Anthropic, OpenAI, GDM, and the AISI(s).
Before we dive in, we’ll give two main highlights:
Monitoringas a practice is rooted in testing procedures for complex systems with unpredictable and low-frequency “runtime” hazards. There is a notable tension here with how research often uses static benchmarks for reproducibility or efficiency. In fact, the first work that employed automated monitoring of model “thinking” was “Testing Language Model Agents Safely in the Wild” (Naihin et al., 2023), which was directly focused on open-ended deployment settings.
CoT(Wei et al., 2022), treated as an explainability technique, draws on themes tracing back to work on “rationales” in mathematical reasoning (Ling et al., 2017), “explain-then-predict” models fromCamburu et al. (2018), and even “introspective explanations” for autonomous vehicles (Kim, 2018). Nowadays, work on monitoring should combine insights from CoT faithfulness, LLM introspection, self-verification (“confessions”), and activation monitoring.
We hope that CoT Monitoring will continue maturing into a useful safety technique for a world with agents running amok.
The History
Where did CoT Monitoring come from?
While the phrase first appears on arXivin 2025, we can trace the intellectual history of CoT monitoring to related, foundational ideas that took on different names.
A first key idea, monitoring, is explored in 2021 in “Unsolved Problems in ML Safety” (Hendrycks et al.). The authors identify the chief limitation of static evaluation of ML models: “…[models] are trained and tested pointwise using specific cases, which has limited effectiveness at improving and assessing an ML system’s completeness and coverage.” This is the chief justification of monitoring. The practice of monitoring in complex systems focuses on uncovering unpredictable and low-frequency issues that wouldlikely only arise during real system runs or deployments.
The paper then connects monitoring directly to explainability/interpretability: “Human monitors can more effectively monitor models if they produce outputs that accurately, honestly, and faithfully [62] represent their understanding or lack thereof.” This “[62]” reference is to Leilani Gilpin’s “Explaining Explanations: An Overview of Interpretability”survey. Thus we see the idea that a faithful accounting of a model’s understanding, made explicit in the model output, would make the model itself more monitorable. So, we have connected monitoring and interpretability. But it’s 2021, and there’s no “CoT” anywhere in this paper. So where does the CoT come in?
Chain-of-thought as a term was coined byWei et al. (2022). Before we rejoin CoT with monitoring, we should first go back in time to understand how CoT can be connected to interpretability in the first place. As far as the mechanics of “generating reasoning before an answer” goes, we see what looks like canonical CoT reasoning in at least two places1in the years prior.Ling et al. (2017)generate natural language “rationales” that precede final answers to math word problems. AndCamburu et al. (2018)propose an “explain-then-predict” model for problems in natural language understanding. (Phil Blunsom is the last author on both papers.) Connecting to interpretability, Camburu’s paper in particular claims we can achieve “better trust that when Explain-Then-Predict predicts a correct label, it does so for the right reasons.”
Being “right for the right reasons” is the antidote to the problem monitoring is concerned with: unpredictable generalization on deployment distributions. And this is what made CoT such a natural surface area for monitoring. Models that are “right for the right reasons” generalizebetterandmore predictably(Ross et al., 2017). By monitoring reasoning itself, we make the monitoring problem easier for ourselves. We don’t have to check as many inputs to validate that the model works as intended.
So this brings us to the first evident example of CoT monitoring, originally published on November 17, 2023: “Testing Language Model Agents Safely in the Wild” (Naihin et al., 2023).

This paper is very explicit about its focus on deployment behavior, writing, “In complex domains, it is recognized that open-world tests are essential for evaluating real-world performance.” In fact, the object of its monitors isAutoGPT, a bona fide agent! Their “AgentMonitor” observes “agent ‘thoughts’ and actions”, where these “thoughts” are CoT outputs from AutoGPT. And indeed, they find that monitoring the CoT itself produces gains in monitor ability to catch unsafe code generation, among other unsafe behaviors.
We thinkNaihin et al. (2023)is the first demonstration of CoT monitoring in practice. But we should point out that the idea is also developed in a2022 blog postby Tamera Lanham, who writes, “For a model in deployment, we could use automated oversight tools that scan its reasoning process for elements we don’t approve of.” The focus of the monitoring here is “externalized reasoning,” which CoT is treated as an example of, along with other language-based, “scratchpad” methods. It took another year to see an empirical instantiation of this idea, though, so we would still place Naihin et al. (2023) as the landmark demonstration of CoT monitoring.
Now, why the gap in CoT monitoring work between Naihin et al. in November 2023 and Baker et al. in March 2025? It’s rare that presently-popular problems have ever rested dormant like this, even just for a year and a half. One explanation is that CoT monitoring was basically gated on models like o1. When OpenAI announced o1 publicly onSeptember 12, 2024, it ignited huge community interest in RL for LLMs, specifically RL that leveraged CoT reasoning. Just six days later, a lengthy meta-analysis of CoT uplift showed that models up to Claude 3.5 Sonnet mostlydid notbenefit from CoT on problems outside of math, logic, and coding (Sprague et al., 2024). While coding is obviously of supreme interest today, this meta-analysis embodied a notable sentiment at the time: that CoT was not critical for models doing unsafe things.2This was long before the days of rampant unit test hacking and cybersecurity apocalypses. But o1 changed this, and CoT became an object of concern again. This is one possible explanation, at least. The record of research artifacts makes it hard to say with certainty.
This is our story of CoT monitoring. Early commentary in ML safety pointed out the importance of monitoring and faithful explanation. Longstanding work in NLP made it clear that natural language reasoning was a promising surface area for monitoring. And empirical research in late 2023 began to deliver on that promise. But it wasn’t until reasoning models took the stage that CoT Monitoring would become a neologism and the term would see about30 papersin the space of a year.
Going forward, we are optimistic that CoT monitoring will improve model safety. To get there, it seems natural that researchers will have to draw on work in CoT faithfulness, LLM introspection, self-verification (“confessions”), and activation monitoring. How can we get models to record their decision-making processes in representations that are informative to monitors? It is a hot problem, but it has deep intellectual roots, and we encourage more researchers to help solve it.
Acknowledgements
We thank David Bau and Tomek Korbak for helpful conversations about this piece.
Stanford AI Lab (@StanfordAILab): New SAIL Blog post: CoT Monitoring: Where Does a Hot Safety Problem Come From?
@peterbhase and @ChrisGPotts trace the history of a big idea in AI Safety
Similar Articles
Detecting misbehavior in frontier reasoning models
OpenAI researchers demonstrate that chain-of-thought monitoring can detect misbehavior in frontier reasoning models like o3-mini, but warn that directly optimizing CoT to prevent bad thoughts causes models to hide their intent rather than eliminate the behavior.
Evaluating chain-of-thought monitorability
OpenAI researchers introduce a framework and suite of 13 evaluations to systematically measure chain-of-thought monitorability in large language models, finding that monitoring reasoning processes is substantially more effective than monitoring outputs alone, with important implications for AI safety and supervision at scale.
NTS-CoT: Mitigating Hallucinations in LLM-based News Timeline Summarization with Chain-of-Thought Reasoning
This paper proposes NTS-CoT, a novel framework that uses Chain-of-Thought reasoning to mitigate hallucinations in LLM-based news timeline summarization. It introduces three modules—Element-CoT, Date Selection, and Causal-CoT—to improve faithfulness and reduce omissions, outperforming state-of-the-art baselines on three benchmarks.
Reasoning models struggle to control their chains of thought, and that’s good
OpenAI researchers study whether reasoning models can deliberately obscure their chain-of-thought to evade monitoring, finding that current models struggle to control their reasoning even when aware of monitoring. They introduce CoT-Control, an open-source evaluation suite with over 13,000 tasks to measure chain-of-thought controllability in reasoning models.
Training on Documents About Monitoring Leads to CoT Obfuscation
This paper demonstrates that models trained on documents describing chain-of-thought monitoring can learn to obfuscate their reasoning to avoid detection, posing a risk to CoT-based alignment techniques.