在OpenTelemetry中通过回溯采样优化尾部采样
摘要
VictoriaMetrics在KubeCon EU 2026上介绍了回溯采样,这一新方法与传统OpenTelemetry尾部采样相比,显著降低了流量、CPU和内存开销。
暂无内容
查看缓存全文
缓存时间: 2026/04/22 02:30
# VictoriaMetrics 在 KubeCon:用回溯采样优化 OpenTelemetry 的尾部采样
来源:https://victoriametrics.com/blog/kubecon-eu-2026-sampling/index.html
上个月,VictoriaMetrics 团队在 KubeCon Europe 2026 上分享了**回溯采样(retroactive sampling)**的演讲。
本文作为该 session 的文字版,介绍回溯采样如何**相比 OpenTelemetry 的尾部采样显著降低出站流量、CPU 与内存占用**。
基准对比(越低越好,第 3 节详述)
## 1 背景
如果你已熟悉相关概念,可直接跳到第 2 节,不会错过关键信息。
### 1.1 分布式追踪
分布式追踪原理简单:一次请求流经数十个微服务,每个服务把自身工作记为 span,并按父子关系汇成一条 trace。
trace 可能非常昂贵:一条 trace 含成百上千 span,每个 span 几百字节到数 KB。网关每秒百万请求时,trace 数据可达 GB/s,采集、传输、处理都会压垮带宽、CPU、内存和存储。
### 1.2 采样
采样是降低 trace 量级最常见手段,按发生时机分两类:
- 头部采样(head sampling)
- 尾部采样(tail sampling)
其他采样(如单元采样、反向采样、离线采样)本文不展开,仅聚焦尾部采样。
头部采样在分布式入口(网关)随机决定保留或丢弃,并把决策随请求向下传递。它不会根据后续异常调整决策,直接丢弃数据。
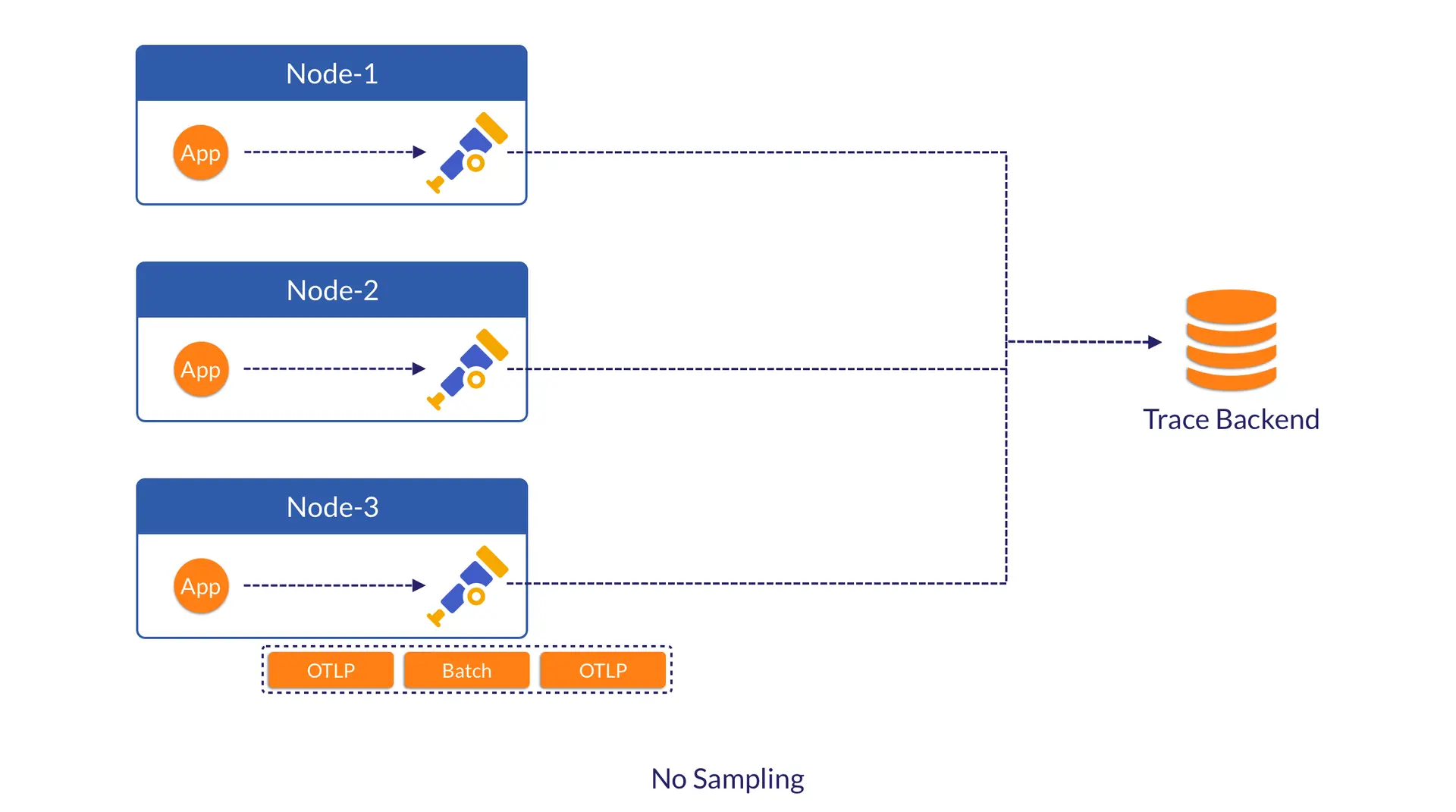
尾部采样更符合用户需求:等一条 trace 的全部 span 到齐后,再基于完整上下文决定是否保留。
span 先发到集中 collector,collector 聚合后等待一段时间再决策,采样通过的 trace 才写入存储。
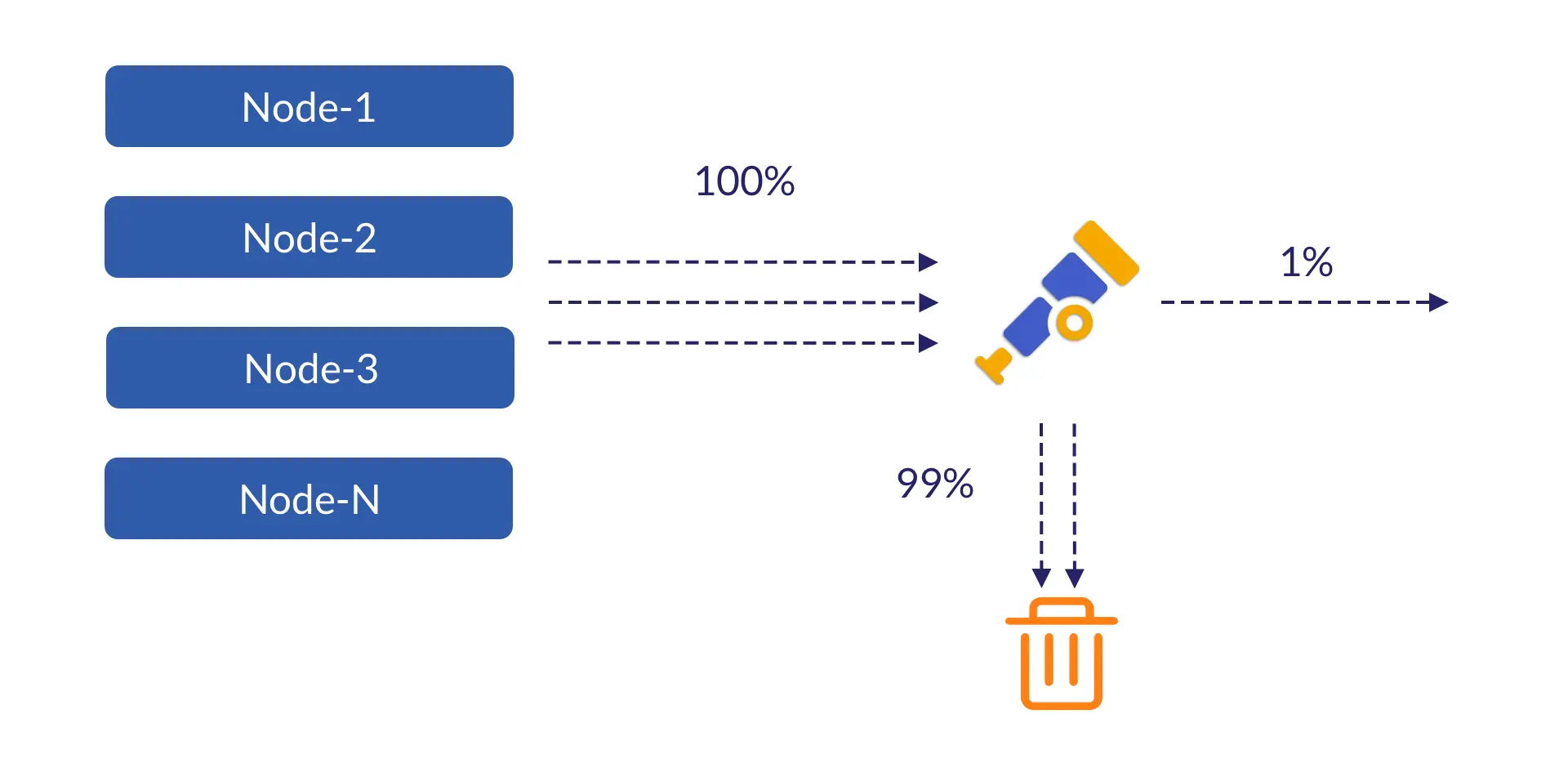
### 1.3 尾部采样的资源开销
尾部采样**并不免费**,有时甚至**比全量采集更贵**:
1. 按 `trace_id` 聚合 span 需在内存缓冲,collector 需大内存。
2. 为扩容需部署多个 collector 实例,同 trace 的 span 必须路由到同一实例,因此必须引入**负载均衡器**。
3. **网络开销**:跨集群/跨区/跨云时,100% trace 都需付费传输,最终却只保留 1% 甚至 0.1%,等于为“垃圾数据”付全价。
## 2 回溯采样
核心思想两点:
1. 仅把决策必需的属性发到中心 collector,原始数据缓存在边缘 agent,采样通过后再拉回。
2. 用**磁盘 FIFO 队列**替代内存缓冲,进一步降低边缘内存占用。
### 2.1 trace 的“导出”与“回溯”
对比 tail sampling 条件你会发现,大量 span 属性(`os.version`、`sdk.version`、`request.path`…)与决策无关。
collector 仅需 `trace_id`、span 起止时间、`status_code` 即可决策。
回溯采样流程:
1. 节点 agent 缓存完整 span,仅提取关键属性发往 collector。
2. collector 决策后把采样结果回传 agent。
3. agent 删除未采样 span,仅发送被采样 span 到存储。
本质:**用小数据做决策,再回溯拉取完整 trace**。
关键属性仅 33 字节,而完整 span 常超 1 KB,collector 内存骤减。
```
+---------------------------+-----------------+-----------------+-----------------+
| 16 bytes | 8 bytes | 8 bytes | 1 byte |
+---------------------------+-----------------+-----------------+-----------------+
| trace_id | start_time | end_time | status_code |
+---------------------------+-----------------+-----------------+-----------------+
```
决策回传可 push 也可 pull。
### 2.2 原始数据缓冲优化
若 agent 仍用内存缓冲,只是把内存压力从中心转移到边缘,整体未降。
我们把**内存缓冲换成磁盘 FIFO 队列**:
1. agent 数据量远小于中心,普通磁盘即可胜任。
2. 磁盘队列可做多种优化,支撑高吞吐。
原型实现流程:
1. 提取关键属性发 collector。
2. 将 span 批序列化并打上时间戳,写入**磁盘 FIFO**。
3. 后台线程按时间戳读取块,若已超过保留期(如 1 min)且已收到采样决策,则过滤后转发到存储。
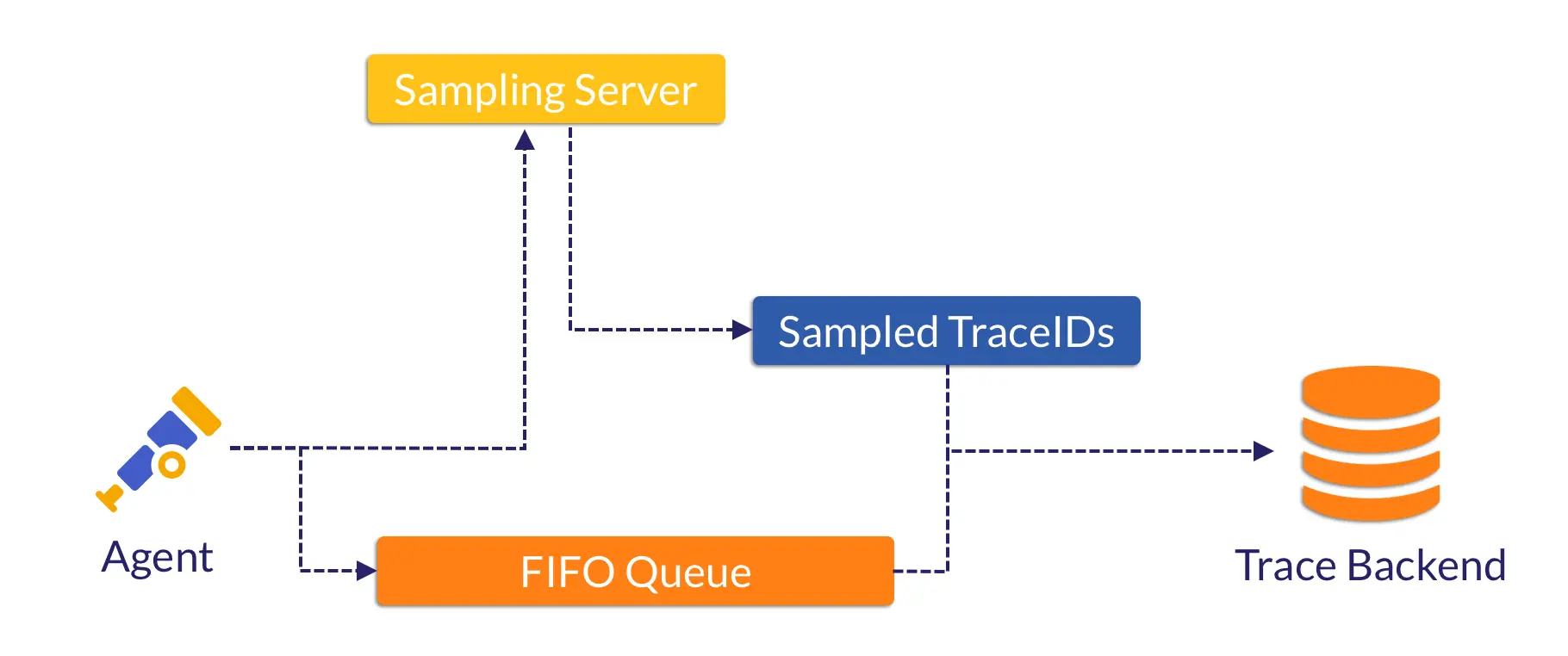
我们自研了 sampling server 替代 collector,社区接受后可直接用标准 OpenTelemetry collector。
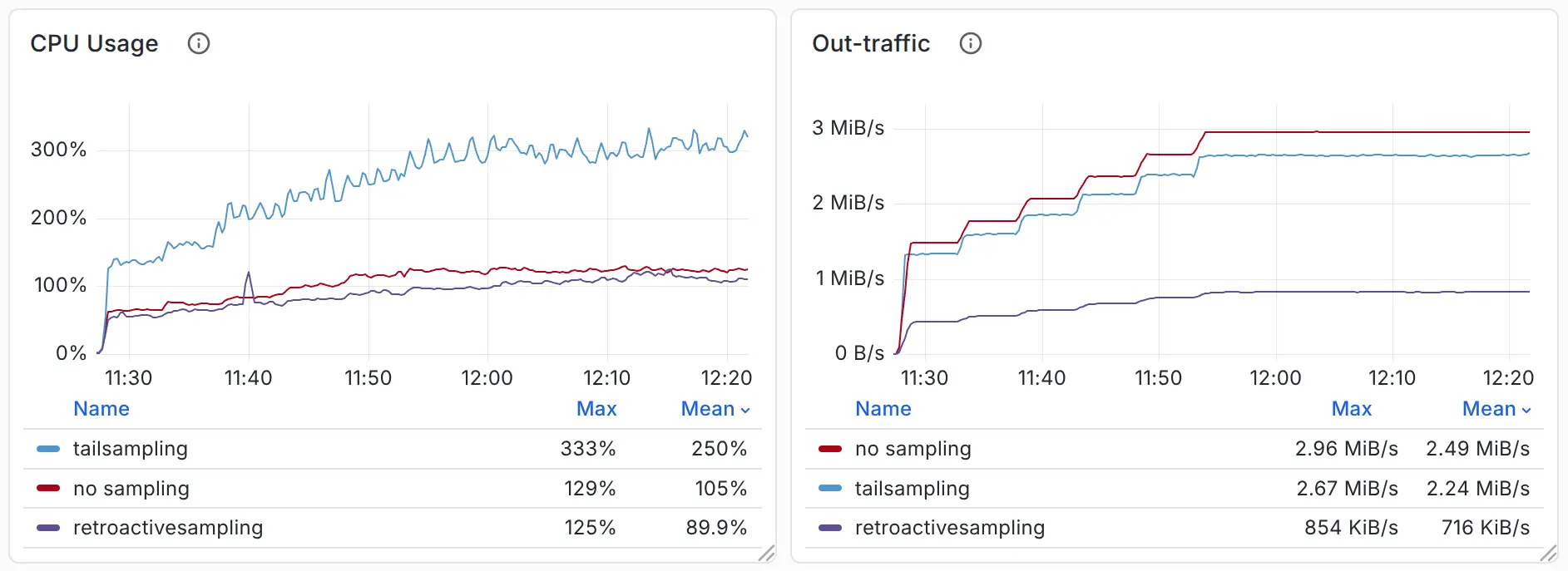
## 3 基准对比
用 OpenTelemetry Demo + 流量回放做测试,对比**无采样 / 尾部采样 / 回溯采样**。
部署:
- 应用(负载生成器)+ OpenTelemetry agent + VictoriaTraces 后端。
- 尾部采样:agent → OTel collector 集群 → VictoriaTraces。
- 回溯采样:agent 内置处理器 → 自研 sampling server → VictoriaTraces。
每秒 15k–30k span 负载下结果:
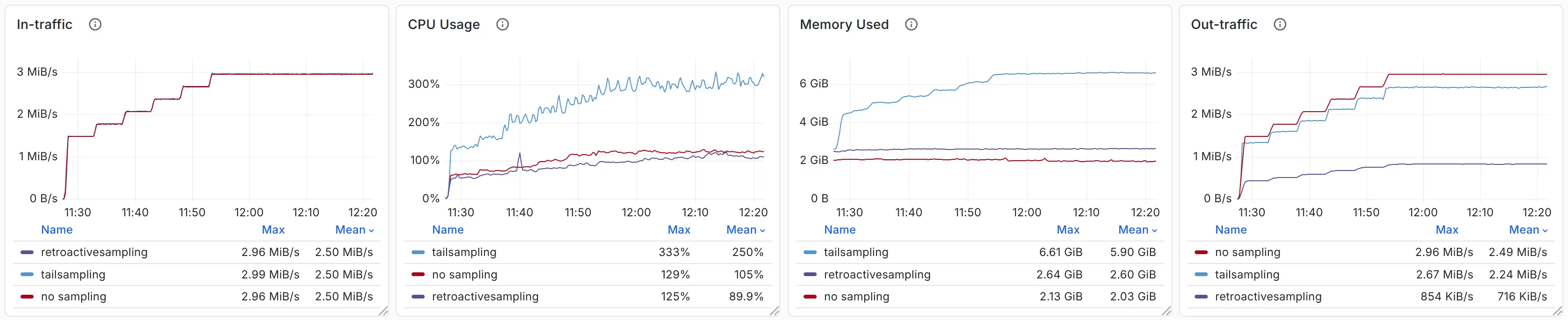
- **出流量**:agent 实际跨节点发送流量,回溯采样减少 70%。
- **CPU/内存**:采集+采样链路整体节省 60–70%。
- 磁盘占用仅 1.7 GB,却换回 4 GB 内存节省。
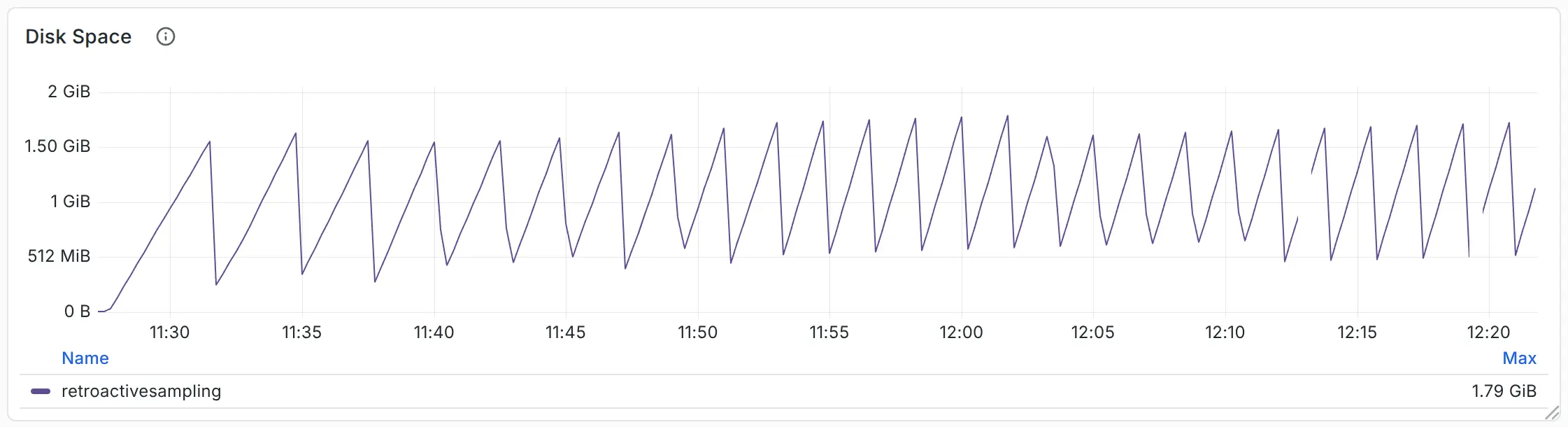
## 4 讨论
回溯采样并非银弹。
缺点:**提供给 collector 的决策信息有限**。
若用户需按 10 个属性采样,可把所需属性全部上传,但内存与带宽会随之增加;极端情况下要利用 span 全部属性,则退化为尾部采样,优势尽失。
```
+-------------+--------+------------------+---------------+---------------+----------------+
| 16 bytes | ... | 128 bytes | 64 bytes | 8 bytes | 64 bytes |
+-------------+--------+------------------+---------------+---------------+----------------+
| trace_id | ... | exception_log | user_agent | app_version | endpoint |
+-------------+--------+------------------+---------------+---------------+----------------+
```
### 4.1 变种:本地 + 回溯采样
若本地 agent 就能判断某 trace 应被采样,就无需上传全部属性。
可把采样条件分为两类:
1. 单 span 即可判定(如含错误码)→ 本地立即采样。
2. 需跨 span 聚合(如 trace 总延迟)→ 上传关键属性到中心做回溯采样。
这样可在降低上传量的同时,保留灵活决策能力。
相似文章
一种基于观测上下文压缩的高效终端智能体自我演化框架
TACO 提出了一种自我演化压缩框架,可自动学习压缩冗余的终端交互历史,在 TerminalBench 及其他代码智能体基准上将 token 开销降低约 10%,准确率提升 1–4%。
遥测驱动开发
Smart Rent 的 Noah 为 Elixir 提出「遥测驱动开发」:先用 OpenTelemetry 埋点,再上线,用 84.8 万台 Nerves 网关的真实数据取代拍脑袋。
动态自适应采样:用于数学推理的自感知迭代数据持久优化
SAI-DPO 引入了一个动态采样框架,在数学推理任务中根据模型不断演进的能力自适应调整训练数据,利用自感知难度指标和知识语义对齐在 AIME24 和 AMC23 等基准上以更少的数据实现最先进的效率。
Meta的优化版RecSys推理(58分钟阅读)
Meta的内核内广播优化(IKBO)通过内核-模型-系统协同设计,消除了RecSys推理中的冗余用户嵌入广播,在H100 GPU上实现了高达2/3的延迟降低和约4倍加速,并成为Meta自适应排名模型的骨干。
@ArizePhoenix:TanStack AI Otel 官方支持现已推出!正在寻找用于追踪、数据集和回放的开源后端?来看看我们的…
TanStack AI OpenTelemetry 官方支持现已推出,提供用于追踪、数据集和回放的开源后端,以提升可调试性。