@jerryjliu0: You can now equip your n8n workflows with the world's best parsing/extraction over your most complex documents We're ex…
Summary
LlamaParse is now an officially verified community node for n8n, enabling users to integrate document parsing, extraction, classification, splitting, and retrieval into their workflow automations. The update includes v5 and v6 with streamlined architecture and single-node design.
View Cached Full Text
Cached at: 06/26/26, 08:16 PM
You can now equip your n8n workflows with the world’s best parsing/extraction over your most complex documents
We’re excited to announce that LlamaParse is now an officially verified community node for n8n. This includes all our core capabilities: Parse, Extract, Classify, Split, and Retrieve.
This means you can build the following:
-
A document extraction workflow over an accuracy-sensitive use case (e.g. loan processing)
-
An indexed document knowledge base that you can plug into an AI agent.
To get started, all you need is a LlamaParse key.
Blog: https://llamaindex.ai/blog/bring-your-document-workflows-to-n8n-with-the-llamaparse-node?utm_medium=socials&utm_source=twitter&utm_campaign=2026-jun-…
Come check out LlamaParse: https://cloud.llamaindex.ai/?utm_source=xjl&utm_medium=social…
LlamaParse Platform Node for n8n: Parse, Classify, Extract & Retrieve Documents with AI
Source: https://www.llamaindex.ai/blog/bring-your-document-workflows-to-n8n-with-the-llamaparse-node?utm_medium=socials&utm_source=twitter&utm_campaign=2026-jun- We’ve shippedv5 and v6of theLlamaParse Platformcommunity node forn8n, and the package is now anofficially verified****community nodeas part of a broader partnership we signed with n8n to bring document intelligence to the no-code and low-code world. This post covers what the node exposes, what changed across the two major versions, and three concrete workflows you can build with it.
What the node does
The package ships a single node,**LlamaParse Platform,**which surfaces five LlamaCloud resources behind one resource/operation dropdown. All five share the sameLlamaParse APIcredential.
ResourceInputOutputParsebinary file\{ text \}— Markdown or plain textClassifybinary file +\{ category, description \}rules\{ category, reasons, confidence \}Splitbinary file + categoriesone item per segment:\{ category, confidence, pages \}Extractbinary file + Extraction Config ID\{ result \}— serialized JSON matching your schemaRetrieveindexId,query,topK``\{ context: string\[\] \}
Parse runs across four tiers (fast,cost\_effective,agentic,agentic\_plus) with optional pinned parser versions. Retrieve targets both the v1 Pipelines API and the v2 Index Retrieval API. Every resource is markedusableAsTool: true, so it can be attached to an n8nAI Agentas a callable tool rather than only living in a linear flow.
What changed in v5
v5 was a foundation rewrite:
- Dropped the SDKin favor of direct HTTP calls against the LlamaCloud API, meaning no need for bundling and maintaining the SDK, as well as a smaller, more predictable surface.
- Extract migrated from V1 to V2, aligning with the current Extract service product config model.
- Configurable API base URL, so region-specific and self-hosted deployments are a credential setting rather than a fork.
- Reworked binary file handlingso files flow cleanly from any upstream node.
What changed in v6
v6 consolidated the package. Earlier releases shipped several distinct nodes (LlamaParse, LlamaClassify, LlamaExtract, and so on); v6collapses them into the single LlamaParse Platform nodewith the resource/operation pattern used by first-party n8n nodes. It also addsindex actionsfor managing and retrieving from indexes, and incorporates fixes from the n8n verification review (linting, packaging, and class-naming corrections).
Install the node on your n8n instance
In order to install the LlamaParse Platform node, open a new n8n workflow canvas, and typeLlamaParse Platformin the node search bar: once the node appears among the search results, click on it and then onInstall node. Verify and manage the installation fromSettings → Community nodes.
 ## Example workflows
## Example workflows
To use the LlamaParse integration, add aLlamaParse APIcredential (paste your key fromcloud.llamaindex.ai; base URL defaults tohttps://api\.cloud\.llamaindex\.ai) and drop the node onto the canvas.
1. Retrievers as agent tools
Because the node isusableAsTool: true, retrieval resources can be wired directly into an AI Agent’s tool list:
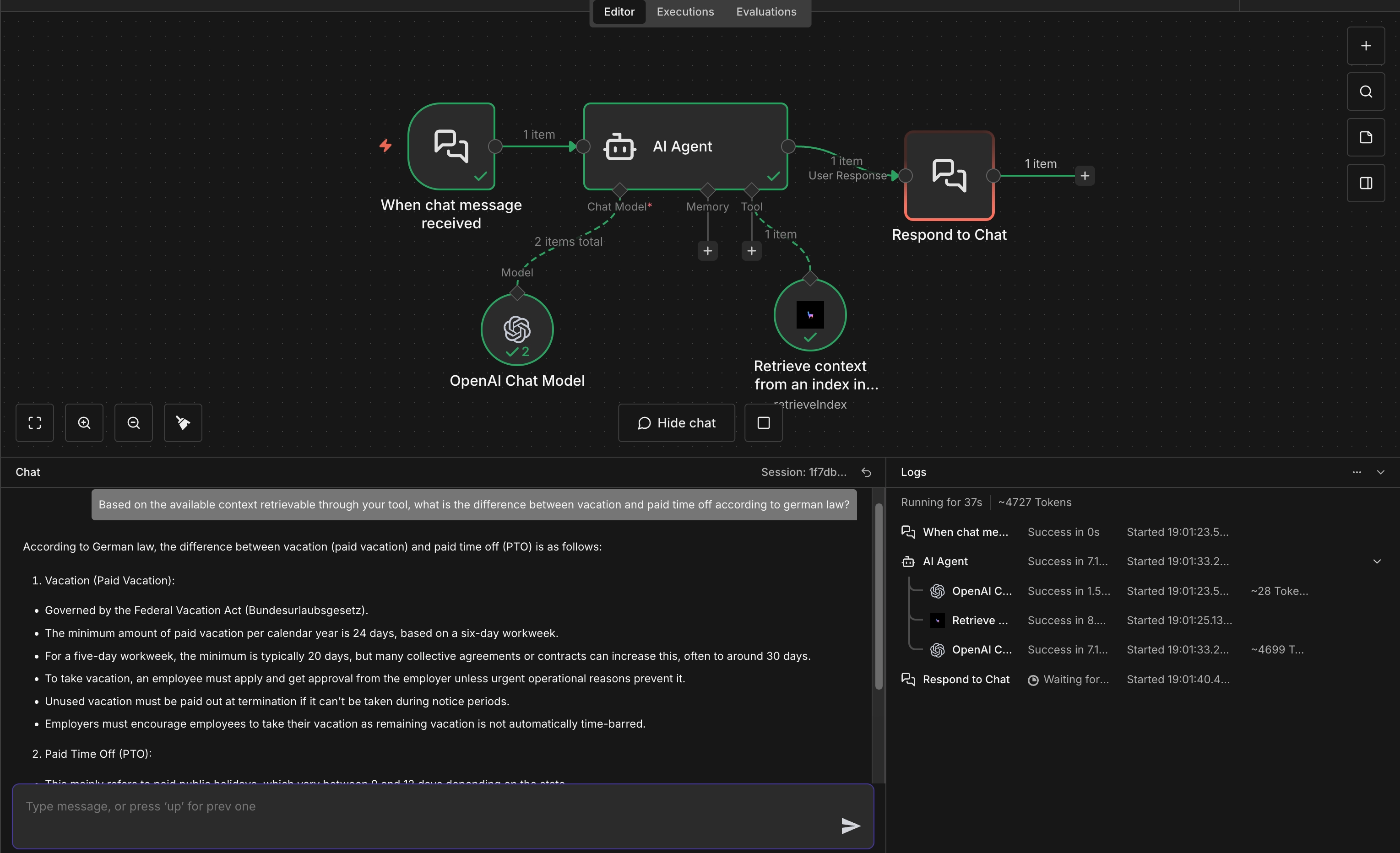 The agent decides whether to call the retriever tool based on the user’s query. For instance, if a user asks a domain-specific question that requires context not currently available to the agent, the agent can retrieve the relevant information from the Index. The agent invokes the tool, receives retrieved chunks back and reasons over them in the same turn: just like that, you have plugged in an agent into your own knowledge base, and you can easily expand it with more tools and connections.
The agent decides whether to call the retriever tool based on the user’s query. For instance, if a user asks a domain-specific question that requires context not currently available to the agent, the agent can retrieve the relevant information from the Index. The agent invokes the tool, receives retrieved chunks back and reasons over them in the same turn: just like that, you have plugged in an agent into your own knowledge base, and you can easily expand it with more tools and connections.
A document-processing pipeline that turns raw files into structured, verified output:
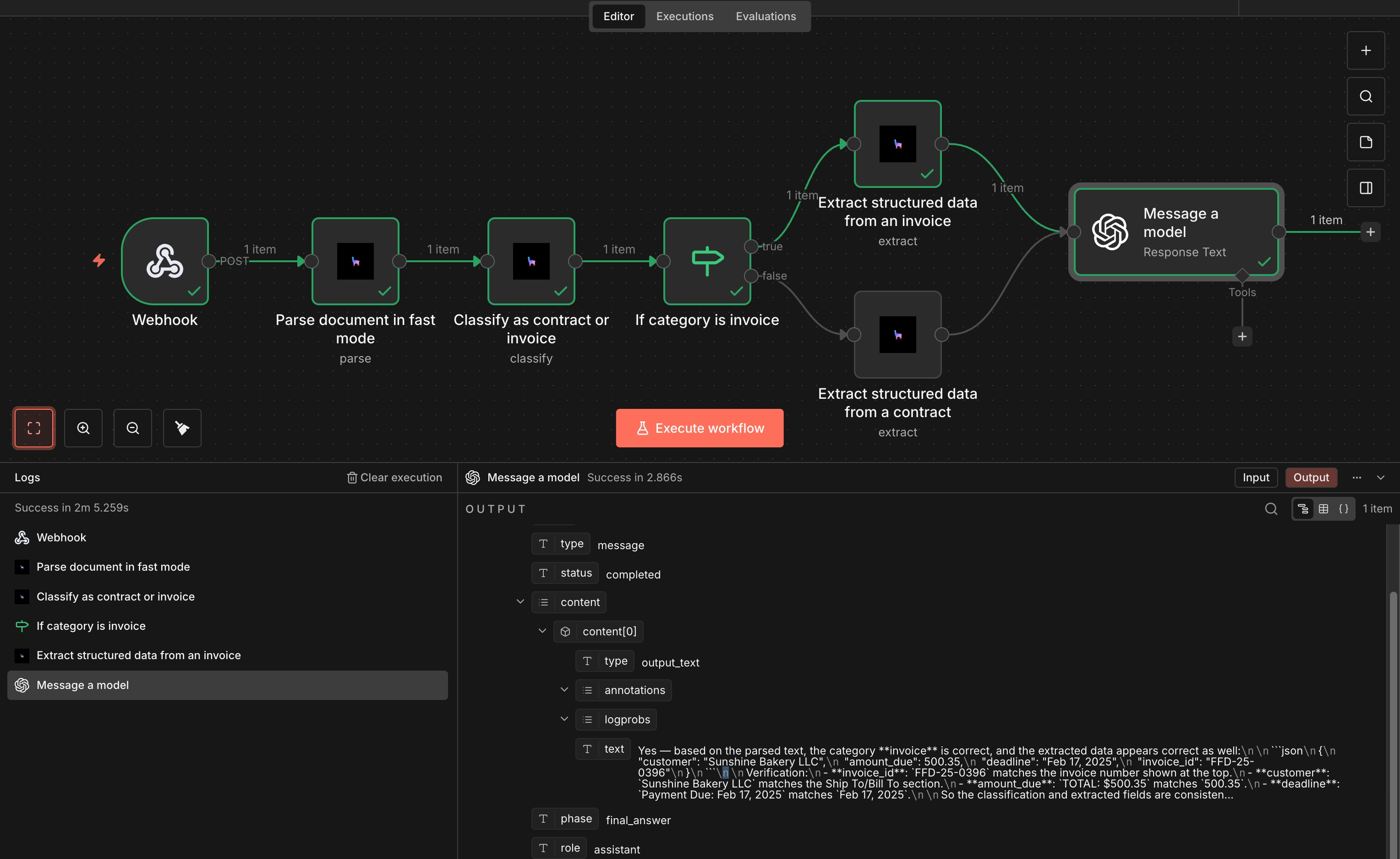 Classifyroutes each document to the right branch (in the example,
Classifyroutes each document to the right branch (in the example,invoicevs.contract),Extractpulls structured fields using a schema tuned for that type, and anLLM nodeverifies the correctness of the extracted data based on theparsed contentof the file. In addition to what is shown in the example, theconfidencefield from Classify could be a convenient gate for sending low-confidence documents to a manual-review branch.
3. Evaluate Parsed Outputs
Evaluate parsed outputs with different parsing modes:
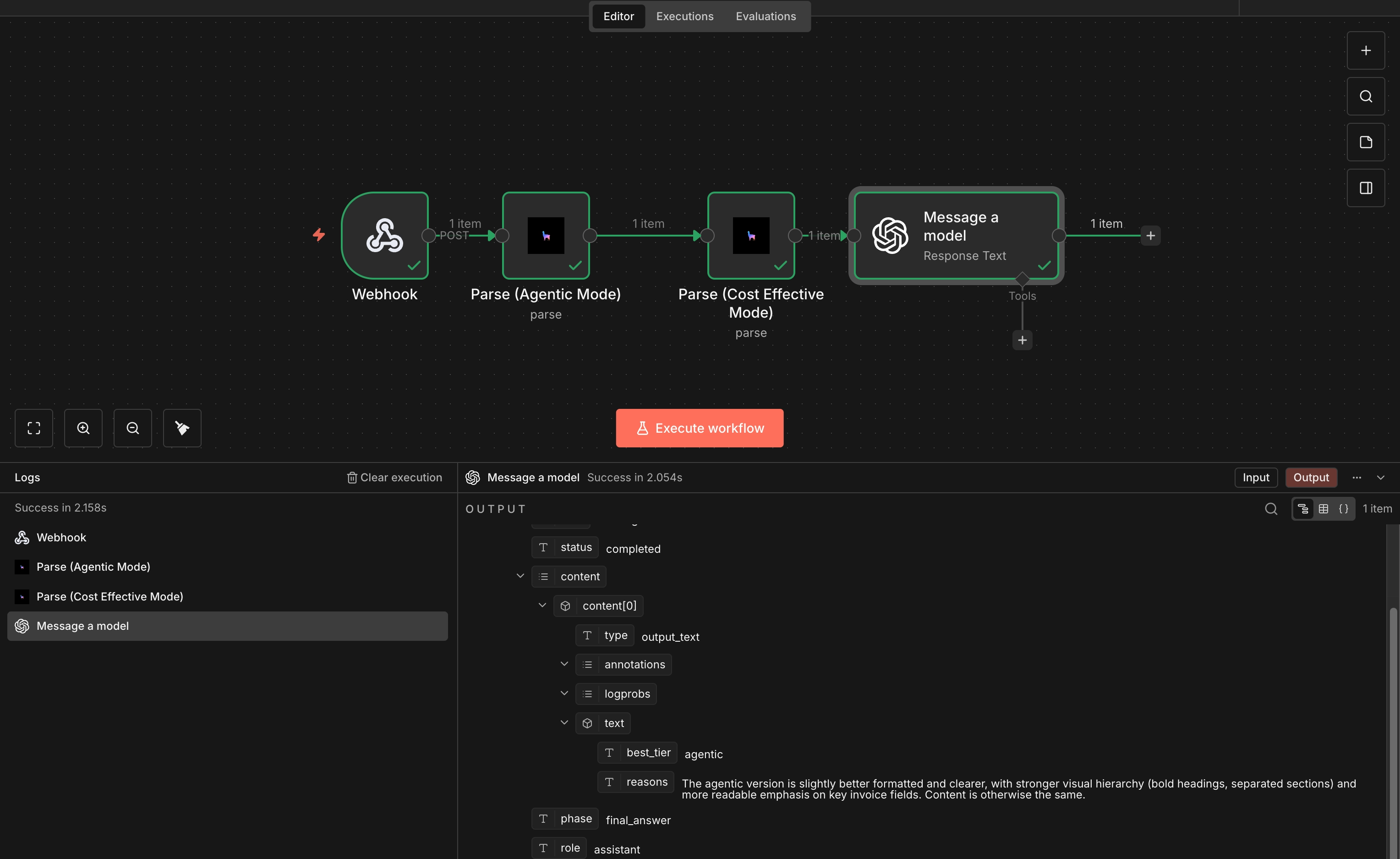 Chain Parse in Agentic and a Cost Effective mode, then pass the input file through both parsers and collect the results into an LLM prompt that looks like this:
Chain Parse in Agentic and a Cost Effective mode, then pass the input file through both parsers and collect the results into an LLM prompt that looks like this:
<agentic_tier>
{agentic output}
</agentic_tier>
<cost_effective_tier>
{cost effectie output}
</cost_effective_tier>
<task>
Determine which tier has produced the highest-quality result
</task>
Finally, represent the LLM-as-a-judge verdict as a structured output you can use for evaluation: this is particularly relevant if you are trying to find the best balance between accuracy and latency for your documents.
Get started
You can get started now with the LlamaParse Platform node, by using it directly in the n8n platform or by checking out:
- the Documentation:developers.llamaindex.ai/llamaparse/integrations/n8n
- the GitHub repository:github.com/run-llama/n8n-llamacloud
- the npm package:@llamaindex/n8n-nodes-llamacloud
- the LlamaParse Platform:cloud.llamaindex.ai
LlamaIndex 🦙 (@llama_index): The @n8n_io node for the LlamaParse Platform is now an officially verified community node, as part of a broader partnership with n8n to bring cutting-edge document intelligence to the low-code and no-code world🚀
The new version of the node brings together document parsing,
Similar Articles
@itsclelia: The @n8n_io node for the LlamaParse Platform is now an officially verified community node Out of the box, you get acces…
LlamaIndex has released v5 and v6 of the LlamaParse Platform community node for n8n, now officially verified, providing document parsing, classification, splitting, extraction, and retrieval capabilities that can be used as tools for AI agents.
@jerryjliu0: We pride ourselves on building document processing that is not only accurate and cheap, but massively scalable to milli…
LlamaParse now offers latency metrics for Parse, Extract, and Classify jobs, providing queue time, processing time, and total latency breakdowns. This helps users monitor and scale their document processing.
@jerryjliu0: Our core mission today is using AI to solve document OCR. All of our product offerings, from commercial (LlamaParse) to…
LlamaIndex has revamped its website and reaffirmed its core mission of AI-powered document OCR, with offerings including commercial product LlamaParse and open-source tools LiteParse and ParseBench. LlamaParse uses VLM-powered agentic document understanding to handle complex layouts, tables, charts, and handwritten text at scale.
@jerryjliu0: We built a cool project that shows you how to compose our core document intelligence primitives into a reusable pipelin…
Parse-Flow is an open-source visual workflow designer that composes document intelligence primitives (parsing, extraction, classification, splitting) into reusable pipelines, backed by LlamaIndex and a Python worker.
@jerryjliu0: LiteParse is the best open-source, model-free document parser for AI agents. Run it over over 50+ document types, and i…
LlamaIndex releases liteparse-server, a self-hosted, model-free HTTP API for parsing diverse document types with high spatial fidelity and privacy preservation.