@eliebakouch: every infra piece you need to know to do RL on GLM-5 https://primeintellect.ai/blog/rl-at-1t-scale…
Summary
Prime Intellect releases prime-rl v0.6.0, enabling efficient reinforcement learning at trillion-parameter scale on large Mixture-of-Experts models, with sub-5-minute step times and optimizations for asynchronous RL.
View Cached Full Text
Cached at: 06/23/26, 08:03 AM
every infra piece you need to know to do RL on GLM-5
https://t.co/pvevY6zYUD https://t.co/rhky5OvmMk
RL at 1T Scale: prime-rl Performance Deep Dive
Source: https://www.primeintellect.ai/blog/rl-at-1t-scale
RL at 1T Scale: prime-rl Performance Deep Dive
Today we are releasing prime-rl version 0.6.0. This version enables us (and you) to train models of trillion-parameter scale on heavy agentic workloads at the highest efficiency. We have been relentlessly optimizing our RL infrastructure to maximize performance on large MoE models, reducing the cost, time and suffering required to post-train OSS models on agentic workflows. We are able to train GLM-5 on SWE tasks at up to 131k sequence length, with sub-5-minute step times and a batch size of 256 rollouts, on only 28 H200 nodes.
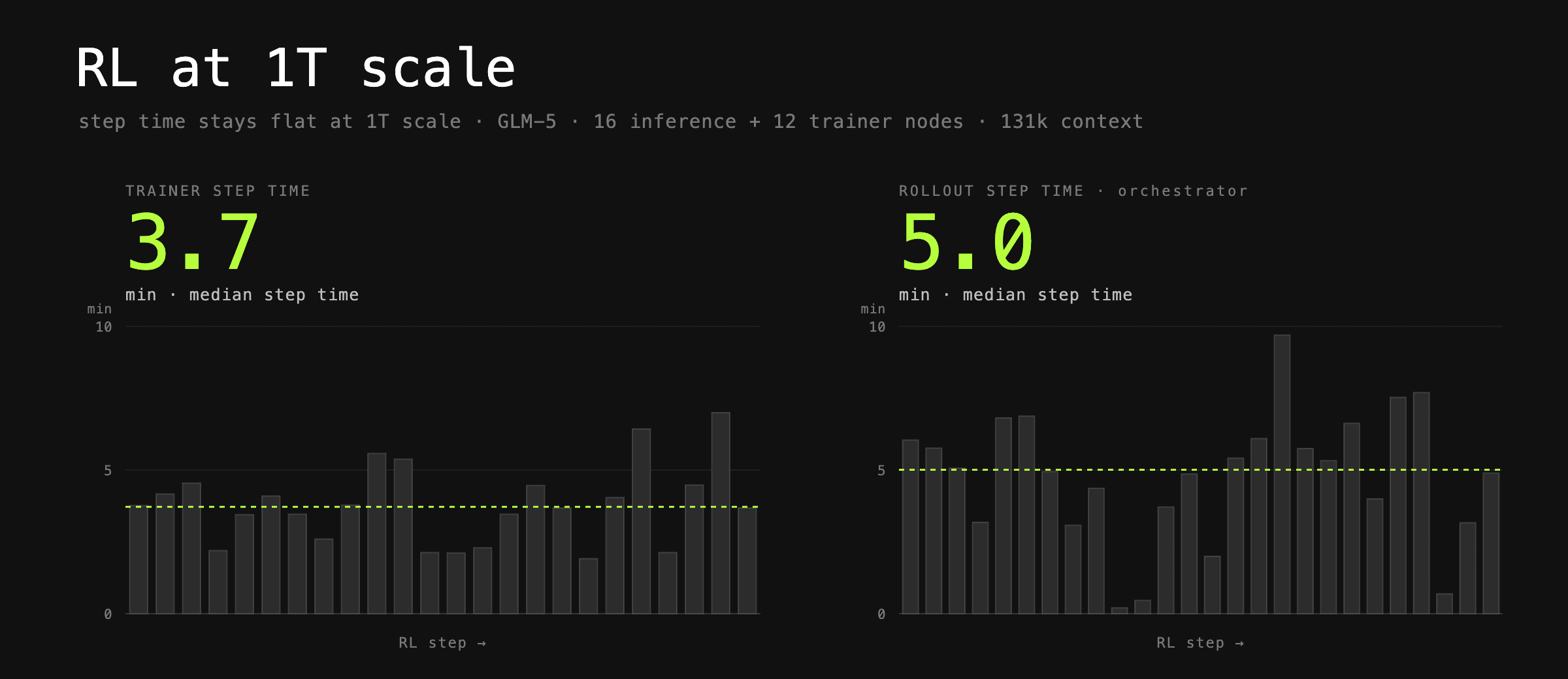 In this blog we will cover all the optimizations that lead to these results, from low-precision inference and training to prefill and decode disaggregated inference deployment. We will takezai-org/GLM-5.1as our model example, but our optimizations translate to any large mixture-of-experts model, such asmoonshotai/Kimi-K2.7-Code,nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16, etc.
In this blog we will cover all the optimizations that lead to these results, from low-precision inference and training to prefill and decode disaggregated inference deployment. We will takezai-org/GLM-5.1as our model example, but our optimizations translate to any large mixture-of-experts model, such asmoonshotai/Kimi-K2.7-Code,nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16, etc.
GLM-5.1 training can be run with a single command on a Slurm cluster using prime-rl:
uv run rl @ examples/glm5_llmd/rl.toml --output-dir /shared/outputs/glm5-llmd
Agentic RL from first principles
prime-rl has been built from the ground up to allow for efficient agentic post-training, embracing asynchronous RL. Agentic tasks often have long-tail outliers; these rollouts can take up to a few hours, especially long-horizon coding tasks. Delaying the policy update until these rollouts finish would under-utilize GPUs and hurt performance. Asynchronous RL solves this by allowing the inference policy to be updated as soon as the optimizer step is finished on the trainer deployment. In asynchronous RL the trainer and inference are disaggregated and can be optimized independently.
 There is an inherent synchronization point between trainer and inference — the policy update. The rollout policy is updated with new weights after each optimizer step. In prime-rl we update the weights as soon as the new set is available. To not slow down inference, the active prefix cache is not reset for already dispatched rollouts — these rollouts will be comprised of tokens generated by various policies, with the KV cache also being produced by multiple versions. However, new rollouts, even when they share a prefix with older ones, re-populate their own KV cache; we use a KV-cache salt to force this. Finally, requests are dropped if they were generated by too old a policy; you control this with the
There is an inherent synchronization point between trainer and inference — the policy update. The rollout policy is updated with new weights after each optimizer step. In prime-rl we update the weights as soon as the new set is available. To not slow down inference, the active prefix cache is not reset for already dispatched rollouts — these rollouts will be comprised of tokens generated by various policies, with the KV cache also being produced by multiple versions. However, new rollouts, even when they share a prefix with older ones, re-populate their own KV cache; we use a KV-cache salt to force this. Finally, requests are dropped if they were generated by too old a policy; you control this with themax\_off\_policy\_stepsvalue.
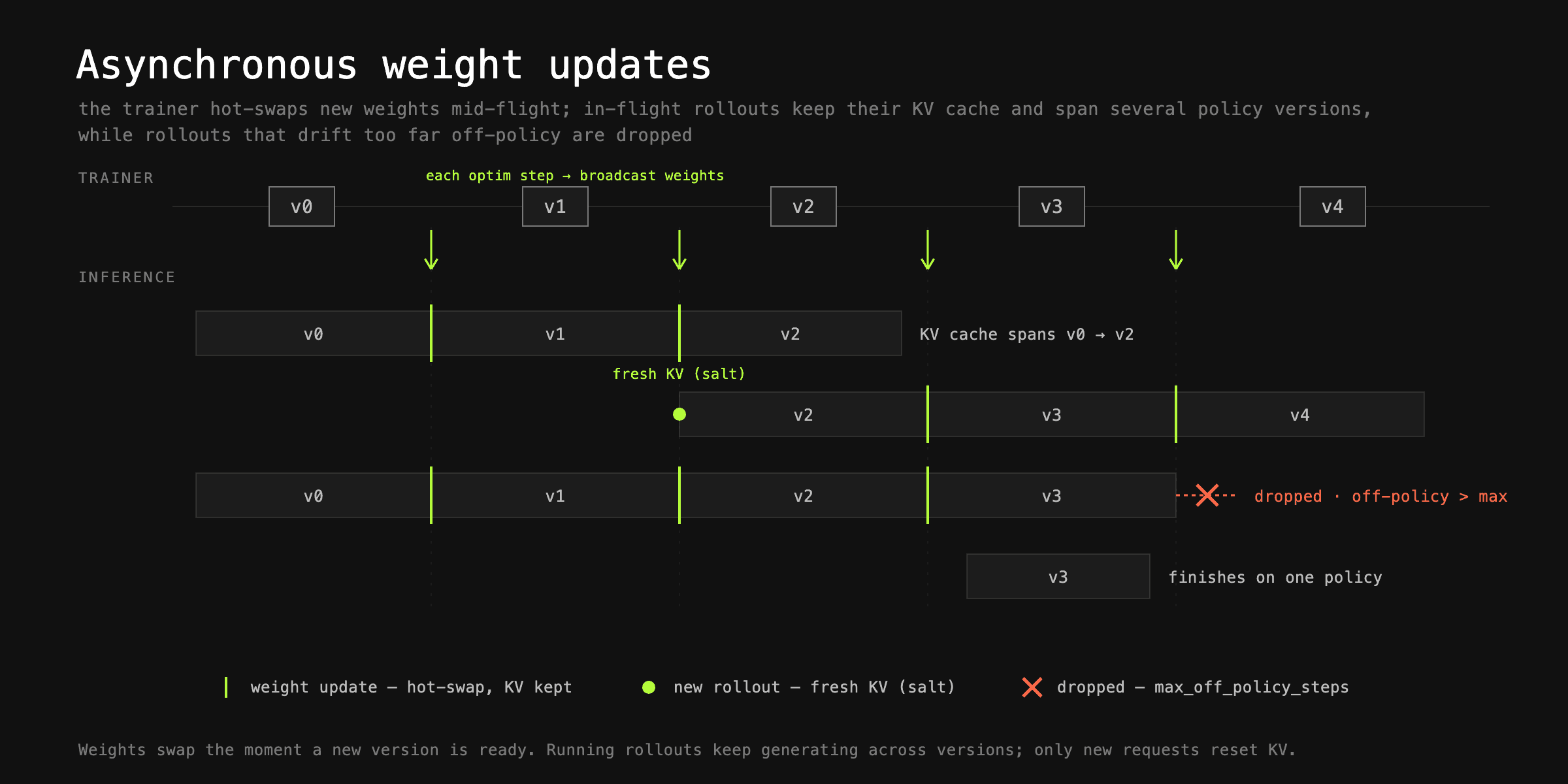 These interactions create an interesting problem from the systems optimization perspective: how to optimize 2 systems — trainer and inference — while keeping them compatible.
These interactions create an interesting problem from the systems optimization perspective: how to optimize 2 systems — trainer and inference — while keeping them compatible.
In the following sections, we will dissect both of these systems and what optimizations we’ve done.
Inference
Inference is the critical part of the RL training lifecycle. That’s where the model interacts with its environment, producing rollouts that are evaluated and assigned a reward. Some of these features already exist in inference frameworks; for others we work closely with frameworks like vLLM and Dynamo, with one goal: to give the community the highest-performance inference with validated, easy-to-use recipes.
FP8 Inference
Inference throughput is usually the bottleneck of your RL system. Inference throughput heavily benefits from lower precision on both prefill and decode deployments. We heavily utilize FP8 inference, together with optimized kernels fromDeepEPandDeepGEMMto achieve lower latency and higher throughput.
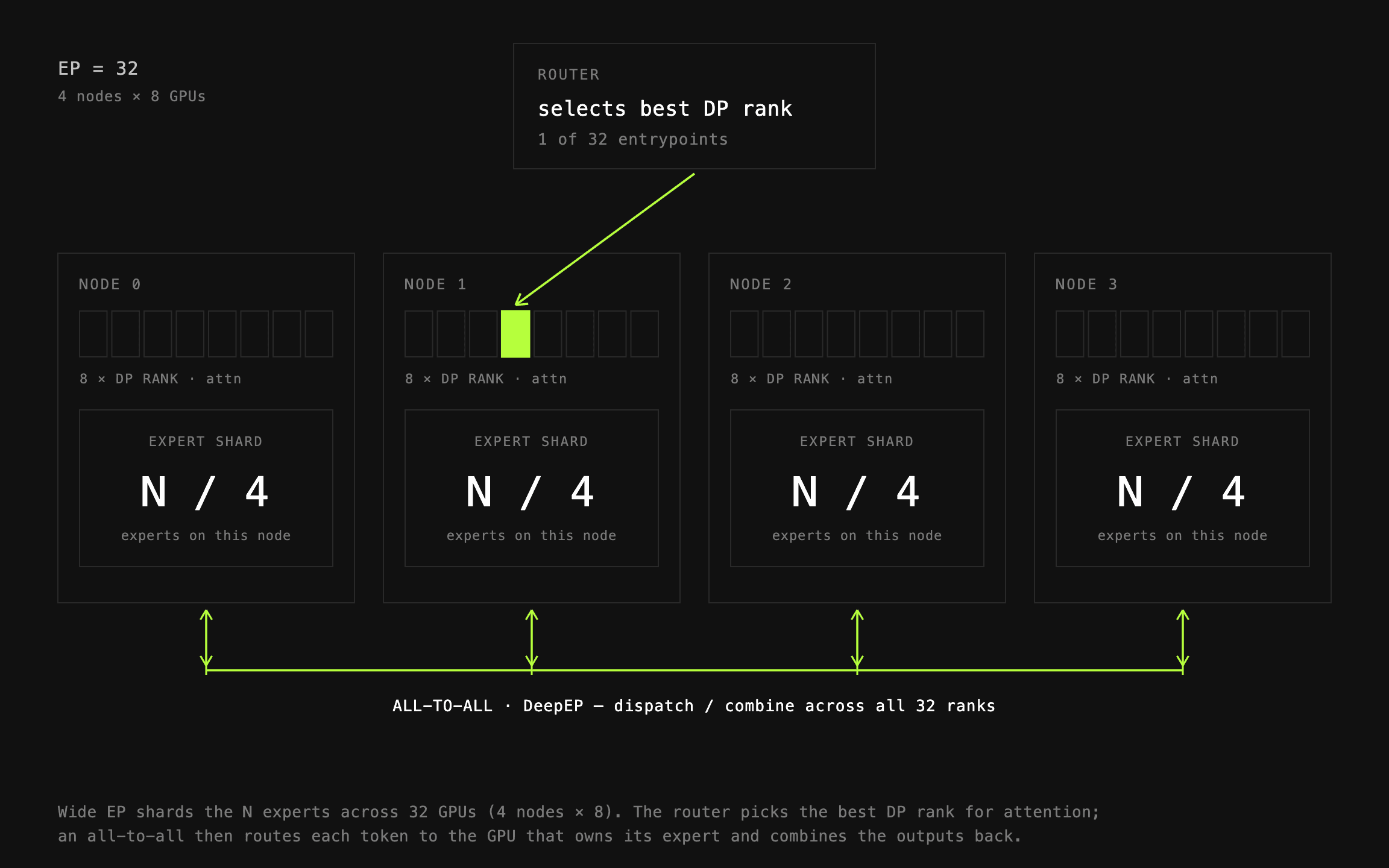
Wide Expert Parallelism
In other articles about inference performance, you might have noticed a lot of focus on minimizing latency, to achieve the highest interactivity for the users. This is not the case with RL — our primary focus is maximizing throughput, while keeping latency somewhat bounded (more on that later).
One of the best configurations to achieve this is Wide EP — large-scale expert parallelism, often spanning ≥32 GPUs. To maximize throughput, we combine this strategy with a large data-parallel rank — for example 32 — creating a large group of GPUs, each holding separate experts, each serving as a separate endpoint. Synchronization happens per-layer, in dispatch and combine operations respectively.
 ### Prefill and Decode Disaggregation
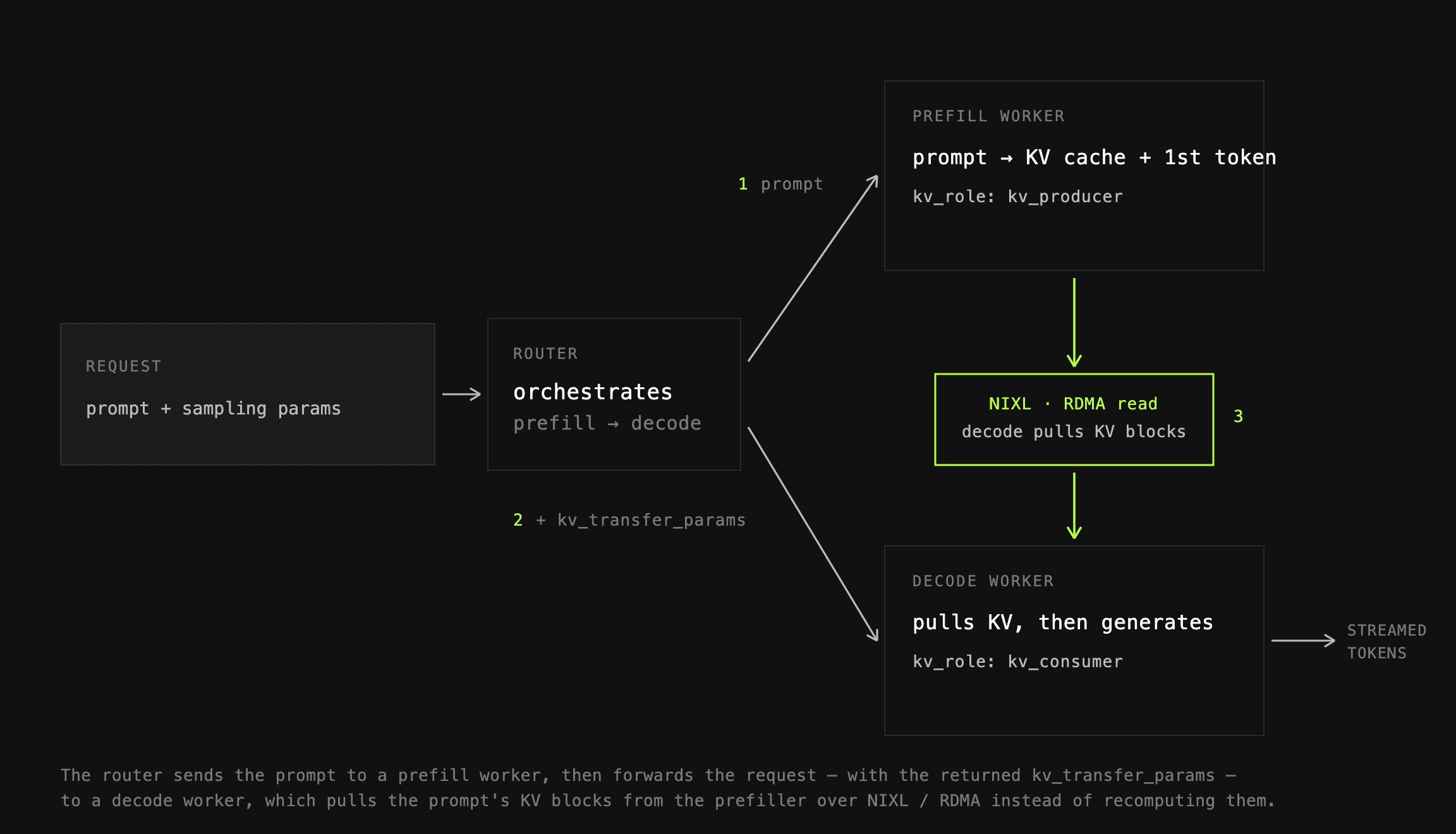
### Prefill and Decode Disaggregation
Prefill throughput is a big bottleneck of agentic rollouts — some combinations of model↔env pairs produce as much as a 4:1 prefill:decode token ratio. Having the same inference workers serve both prefill and decode requests would increase E2E latency, significantly reducing the benefits ofPipelineRL.
As mentioned before, the priority for RL is maximizing inference throughput, not minimizing latency. However, if latency grows large due to inference batches getting dominated by prefill requests, “grouping” of finished inference rollouts can be observed, leading to low overlap of trainer and inference steps.
With prime-rl you can seamlessly use P/D disaggregation. When prefill and decode workers are separated, long prefill requests (lengthy tool outputs, etc.) do not throttle the decode workers, letting them progress with predictable latency. This completes model turns faster, tool-calls then reach sandbox execution faster, and the cycle repeats, sometimes across 100s of turns.
 ### KV cache management
### KV cache management
Maximizing throughput requires high concurrency. That in turn requires a lot of KV cache space. If there is not enough space, KV cache thrashing and a low prefix-cache hit rate can occur, lowering the throughput. prime-rl stays on top of the newest features in inference frameworks, supporting them E2E — one of these cases is KV cache offloading.
We support tiered KV cache offloading to both CPU and disk using both native vLLM offloading andMooncake. With more KV cache space, we can increase concurrency, amortizing more of the trainer costs.
There are 2 main differences between each of these approaches:
- vLLM native offloading— a simple approach, creates a single CPU/disk pool per worker (DP rank); only this worker can in turn load from this cache.
- Mooncake Storeinstead works as a centralized store, that pools RAM/disk from all the clients (nodes) into 1 large pool, that can then be reached from any inference worker from any node — this provides a significant advantage, especially when using more sophisticated routing strategies.
Request Routing
To tie everything together, inference requests need to be routed efficiently to allow for efficient prefix reuse, load-aware routing, etc.
The default routing option in prime-rl is our fork of vllm-router, a minimal, lightweight solution that delivers strong performance with minimal configuration overhead. Depending on your requirements, you can choose your own routing strategies optimized for load balancing, KV cache reuse, or other objectives.
We also support the NVIDIA Dynamo router as a drop-in alternative. This allows us to develop and deploy more sophisticated routing strategies for larger-scale runs. These strategies combine different factors, such as KV cache reuse, queue depth, KV cache utilization or current load, based on the live metrics from the inference workers, to compute a score given to each worker. Workers then get selected based on a policy and their scores.
Combined with Mooncake Store, which serves as a centralized KV cache offloading layer, this enables prefix cache hits across replicas while distributing the load fairly and reacting to live inference metrics.
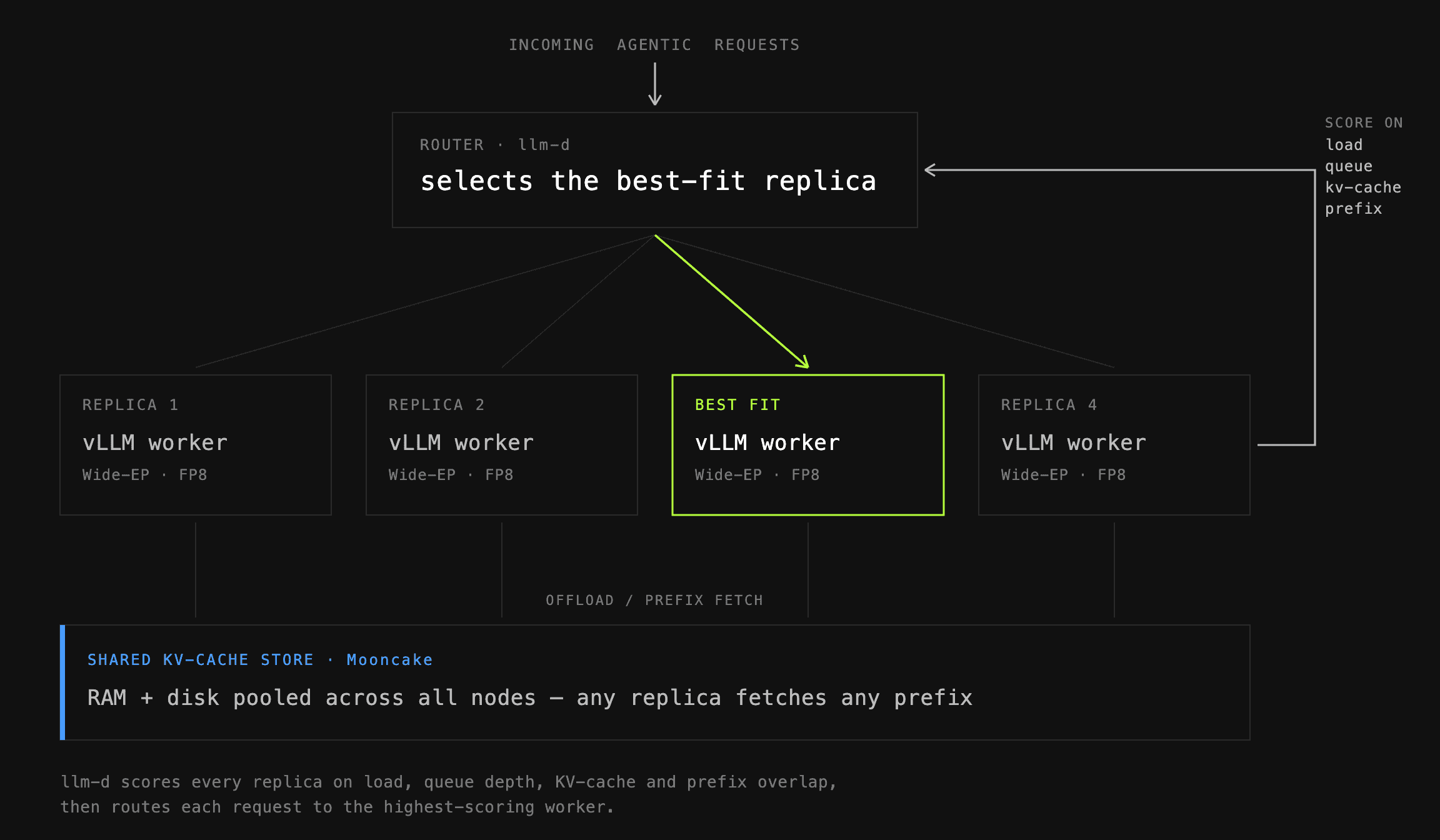 We are also actively collaborating with the vLLM and Dynamo teams on continuously improving the routing solutions, bringing more performance to inference.
We are also actively collaborating with the vLLM and Dynamo teams on continuously improving the routing solutions, bringing more performance to inference.
Router replay
Trainer↔inference mismatch silently kills your RL training. To fight this, you can use router replay — R3 in prime-rl. This works by capturing the routing decisions made during inference and then replaying them directly on the trainer. This effectively reduces KL mismatch between trainer and inference by an order of magnitude, resulting in more stable training.
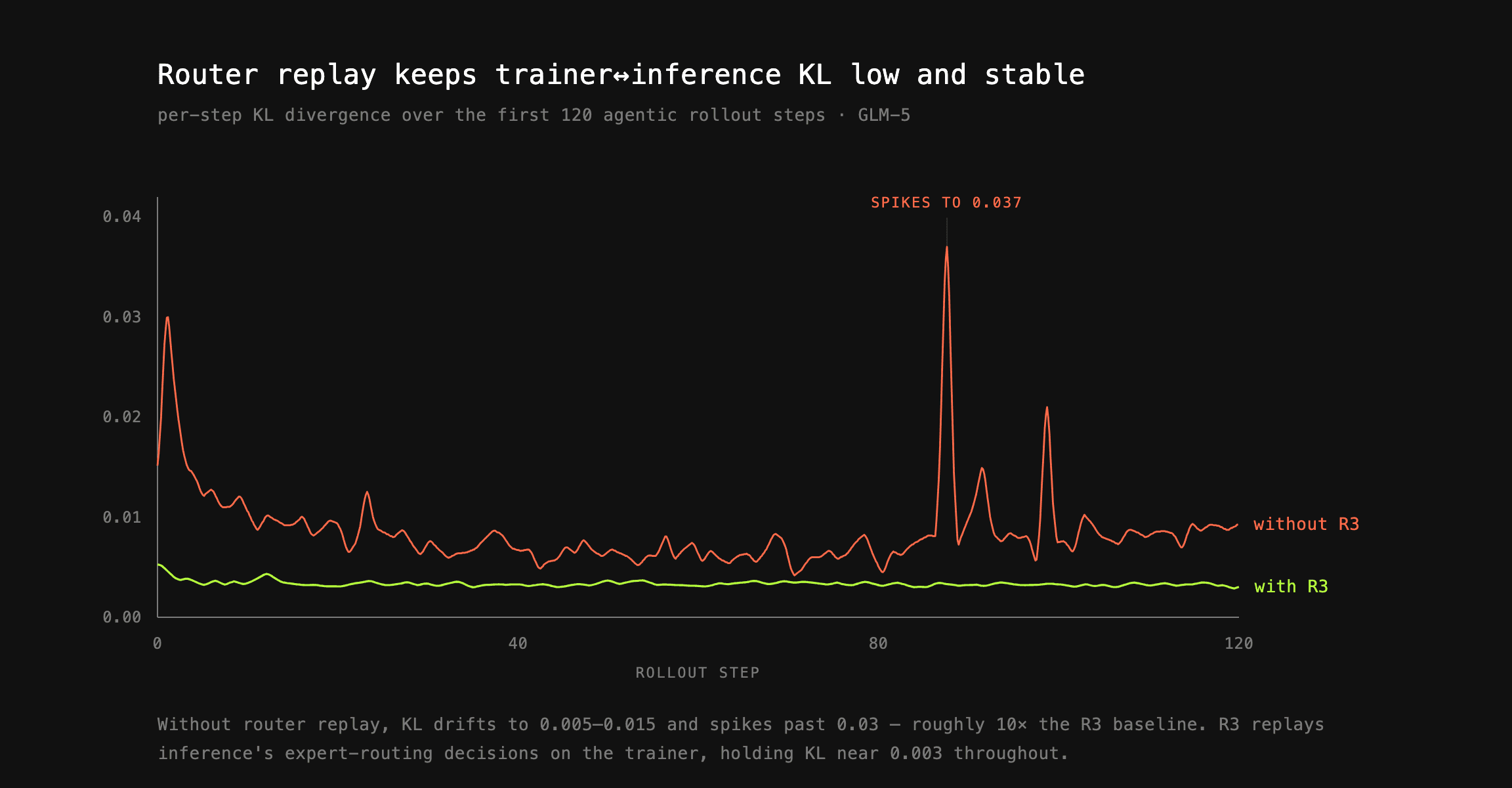 This doesn’t come for free — at large-scale deployments, routed-experts data can reach up to tens of Gbps, creating a large strain on the processing. This caused us a lot of headache, but now prime-rl can serve thousands of concurrent agentic rollouts while processing this data.
This doesn’t come for free — at large-scale deployments, routed-experts data can reach up to tens of Gbps, creating a large strain on the processing. This caused us a lot of headache, but now prime-rl can serve thousands of concurrent agentic rollouts while processing this data.
Routed experts are a large payload of shape\[num\_layers, top\_k, seq\_len\]which can quickly grow to hundreds of GB, which in turn causes large load on the Python processing — even seemingly simple operations, such as converting responses into Python dictionaries, can cause significant event-loop lag and CPU bottlenecks. To eliminate this overhead, prime-rl treats routed experts as an opaque payload where the only processing is handled by heavily optimized PyTorch operations, reducing the CPU strain.
Router Replay is fully compatible with other inference optimizations, including P/D disaggregation, allowing you to deploy production-ready stacks with ease.
Training
Our trainer is based ontorchtitan— a high-performance PyTorch-native large-scale training code-base. We’ve adapted a lot of our trainer code from torchtitan, spanning features like FSDP, EP and various other abstractions, while adding our own touches and improvements.
Parallelism
prime-rl mostly relies on 3-D parallelism, to be exact: FSDP, CP and EP. Each of these has its own use-cases, benefits and drawbacks. To get a large-scale run going smoothly, you need to use a combination of them in varying degrees. For our GLM-5 case study, we employ all 3.
Let’s do a short refresher on all of them.
**FSDP.**Fully Sharded Data Parallel is our baseline distribution strategy. Parameters, gradients, and optimizer states are sharded across the data-parallel ranks and gathered on demand during the forward and backward pass. For a model with 1T+ parameters, this is required to amortize the memory footprint of the full optimizer state or parameters. We utilizefully\_shard(FSDP2) from PyTorch as our FSDP implementation; this allows easy composition with other strategies, as discussed further.
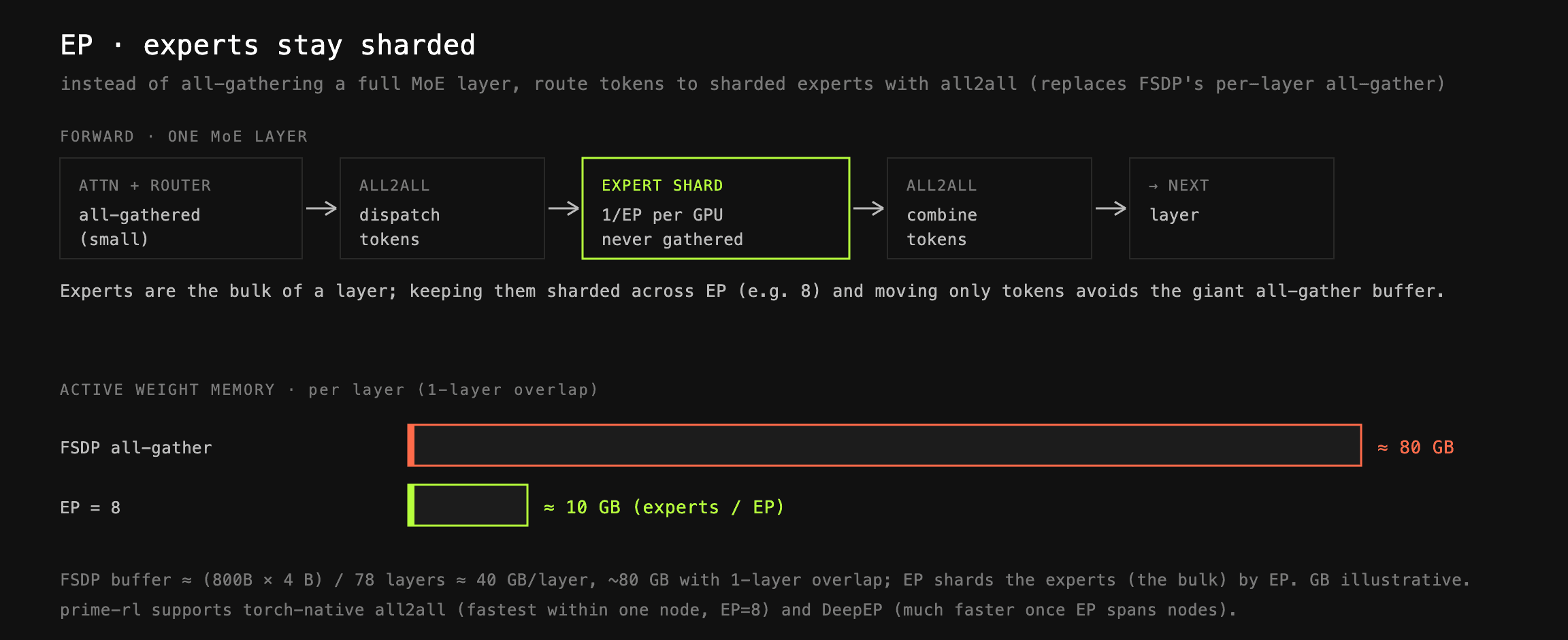
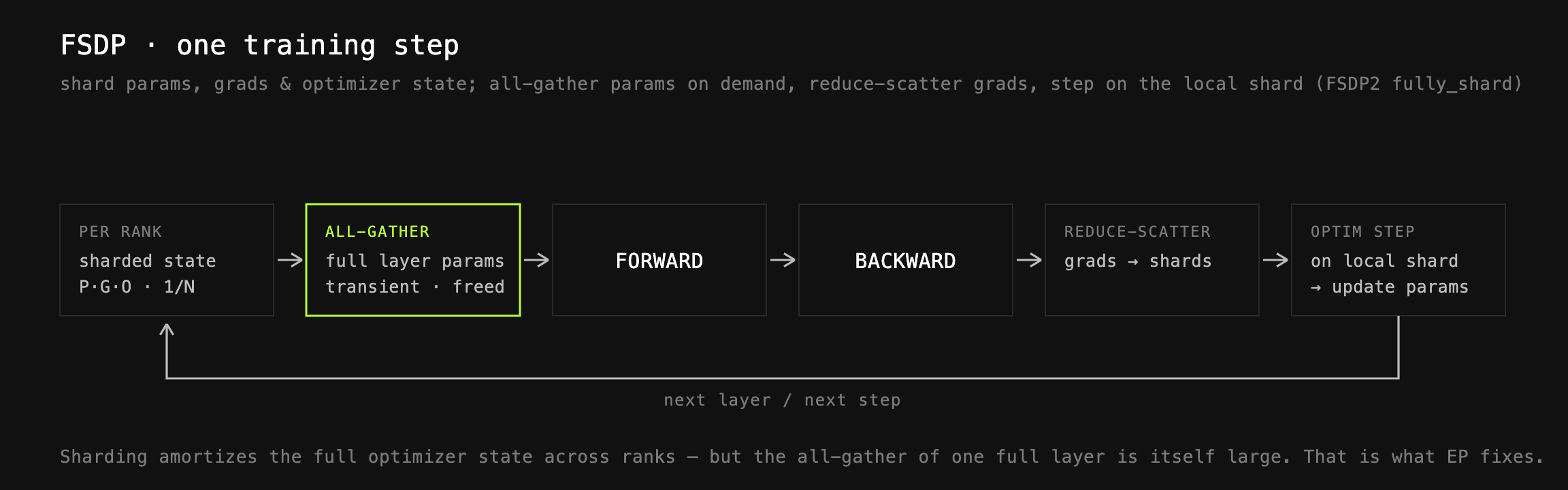 **Expert Parallelism (EP).**Even after FSDP, large model layers are still way too large to effectively fit into single-GPU HBM after an FSDP all-gather. With 78 layers, 800B params and master weights in float32, an all-gather of a single layer requires roughly (800B × 4) / 78 ≈ 40GB buffer. With FSDP overlap of 1 layer, this would require ~80GB of memory just for active layer weights.
**Expert Parallelism (EP).**Even after FSDP, large model layers are still way too large to effectively fit into single-GPU HBM after an FSDP all-gather. With 78 layers, 800B params and master weights in float32, an all-gather of a single layer requires roughly (800B × 4) / 78 ≈ 40GB buffer. With FSDP overlap of 1 layer, this would require ~80GB of memory just for active layer weights.
That’s where EP comes in: instead of all-gathering the full layer, we set a separate inner EP degree, for example EP=8, across which experts won’t be gathered. Instead, tokens will be dispatched and combined using all2all primitives. With experts being the major contributor to the layer memory footprint, this significantly reduces active memory.
In prime-rl we allow 2 separate EP configurations — torch-native all2all and DeepEP. From our observations, torch-native provides slightly better throughput on a single-node EP span (i.e. EP=8), but drops significantly when EP spans across nodes. This is where using DeepEP becomes faster by a large margin.
 **Context Parallelism (CP).**At 131k+ sequence length, intermediate activations — not parameters — become the dominant memory cost. Context parallelism shards the sequence dimension across ranks to reduce the per-GPU activation.
**Context Parallelism (CP).**At 131k+ sequence length, intermediate activations — not parameters — become the dominant memory cost. Context parallelism shards the sequence dimension across ranks to reduce the per-GPU activation.
In prime-rl we support context parallelism for all of our custom models. We support 2 main ways to use context parallelism:
- Ring Attention— The batch is sequence-sharded throughout the whole model forward. When core attention is reached, each rank holds its shard of Q, K and V, while also processing K and V from other ranks in a ring-like pattern.
- Ulysses— As in ring attention, data is sequence-length sharded through the whole model forward. When attention is reached, all2all operations flip the layout from sequence-sharded to head-sharded and attention is then computed across the head dimension. Once attention computation completes, the layout is again swapped back with another all2all. This works nicely with most of the non-standard attentions (linear attention, Mamba, etc.) and is our default.
However, there are some exceptions to this — one of them being DSA as used in GLM-5.
For models with attentions that can’t be parallelized with both Ulysses and Ring Attention, we write custom context-parallel implementations, GLM-5 being one of them.
Our context parallelism implementation keeps the sequences sharded and computes projections. After this, K and V are gathered — this is cheap as they are projected into a latent space — to allow the indexer to see the full sequence. The indexer computes sparse indices for the global sequence and core attention is computed on these indices. As DSA has fixedtop\_k, the cost of this is also fixed (except for the memory cost of KV, which is negligible as discussed before).
This scheme allows for only a single all-gather collective per attention layer, keeping the costs at a minimum.
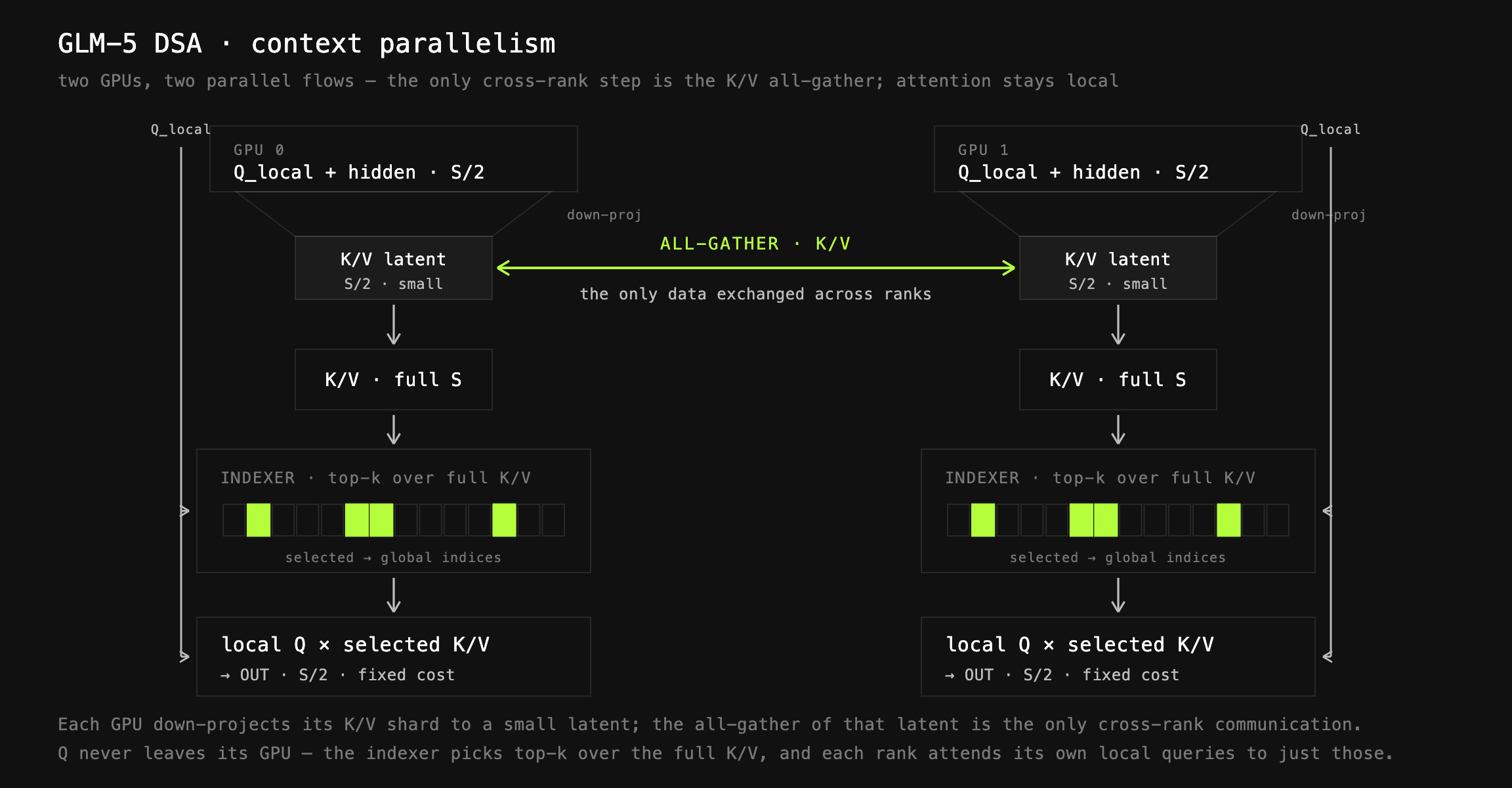 ### GLM-5 DSA
### GLM-5 DSA
To compute DSA efficiently, we use custom kernels, heavily based on the reference implementations and adapted to our needs, providing both fast forward and backward.
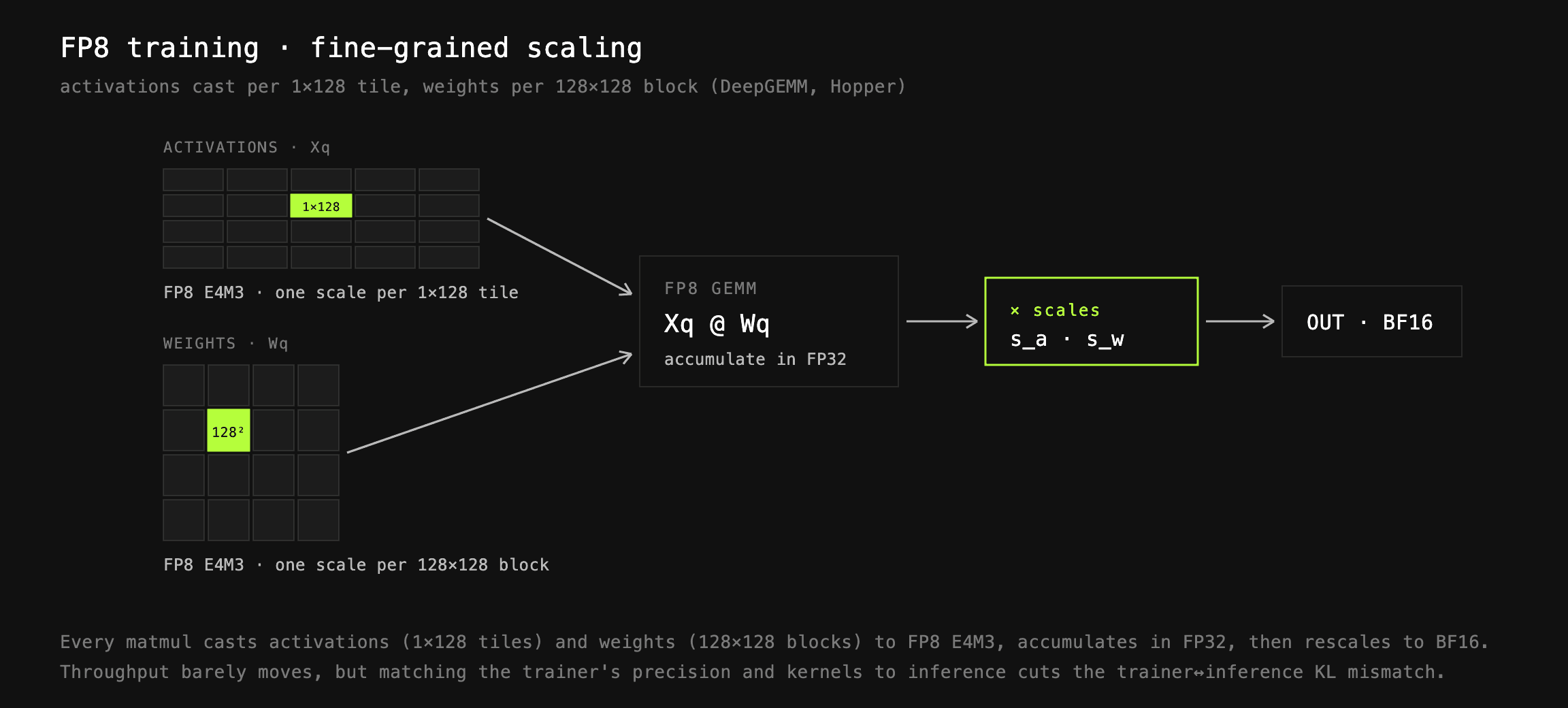
FP8 training
As noted earlier, trainer↔inference mismatch can hurt your training. To fight this, we useDeepGEMMkernels to perform block-scaled FP8, as proposed by DeepSeek V3. This, contrary to popular belief, doesn’t really increase the throughput, due to quantization overhead (except for specific configurations); however, it heavily decreases KL mismatch between trainer and inference, as both now use the same precision, and even the same kernels in some cases. This in turn leads to more stable training.
 ## Future work
## Future work
We continue exploring other ways to improve the performance of our RL engine, actively collaborating with other frameworks — notably vLLM, Dynamo and llm-d to speed up the inference side, or PyTorch for a blazingly fast trainer — exploring techniques such as speculative decoding, NVFP4 training and inference, or infrastructure improvements like fault tolerance, elastic scaling, and sub-1-second trainer↔inference weight transfer of huge models.
We’re hiring!
Large-scale agentic RL is, in our opinion, one of the most exciting systems challenges in AI today. Building an efficient RL stack requires optimizing a wide range of components, both individually and as a cohesive system: training, inference, request routing, weight broadcasting, in-flight weight updates, environments, code execution sandboxes, and much more.
At scale, every source of overhead matters. Success comes from understanding how these systems interact, identifying bottlenecks, and relentlessly pushing efficiency across the entire stack.
If this sounds interesting to you, and you’d like your day-to-day work to involve building and optimizing these systems at massive scale, experimenting with new distributed training and inference techniques, and squeezing every last bit of performance out of thousands of GPUs, we’d love to hear from you.
Applyhereor reach out to us on X.
Prime Intellect (@PrimeIntellect): Today we’re releasing prime-rl v0.6.0 — enabling RL at trillion-parameter MoE scale on agentic workloads at the highest efficiency.
We’ve relentlessly optimized our RL infra.
The result: GLM-5 on agentic SWE tasks at 131k context and sub-5-minute step time.
Similar Articles
@didier_lopes: Incredible how Z. ai literally has their RL infrastructure open source. The entire OPD post-training of GLM-5.2 took on…
Z. ai has open-sourced its RL infrastructure, the slime framework, which enabled efficient OPD post-training of GLM-5.2 in about two days. slime is an LLM post-training framework for RL scaling that integrates Megatron and SGLang, and has been battle-tested by frontier models like GLM, Qwen, DeepSeek, and Llama.
@neural_avb: Locally generating GRPO-like rollouts with my SLM, and using this tiny RM as the rubric. Next I'll be RL training on fr…
Neural_avb releases a lightweight Answer-eq Reward Model for RL training on QA tasks, claiming 80% agreement with external judge LM and faster than F1/ROUGE/BertScore.
ExpRL: Exploratory RL for LLM Mid-Training
ExpRL is a new RL-based mid-training method that uses human-written reference solutions as dense reward scaffolds (never shown to the policy) to improve LLM reasoning, achieving significant gains on hard math benchmarks like AIME-2026.
@SergioPaniego: if you're looking for a long read for the weekend ↓↓↓ the ultimate guide to RL environments by @adithya_s_k https://hug…
This article shares a comprehensive guide on building and scaling reinforcement learning environments for the LLM era, hosted as a Hugging Face Space by AdithyaSK.
Building Fast & Accurate Agents with Prime-RL Post Training (22 minute read)
Ramp presents a case study on using reinforcement learning post-training to build Fast Ask, a specialized spreadsheet retrieval agent that improves accuracy and reduces latency compared to general-purpose models.