@verityw_: Generalist robot policies learn many useful skills. How can we elicit relevant behaviors when faced with new tasks? We …
Summary
Introduces Flow Reversal Steering (FRS), a method to refine coarse actions from semantic reasoning into precise robot actions by reversing and re-denoising through a flow-matching generalist policy, improving zero-shot control and enabling policy learning.
View Cached Full Text
Cached at: 06/12/26, 05:00 PM
Generalist robot policies learn many useful skills. How can we elicit relevant behaviors when faced with new tasks? We introduce Flow Reversal Steering (FRS): a way to refine coarse actions produced by semantic reasoning into similar precise ones! https://t.co/BRdvq0OVg0 1/N https://t.co/ua8lRrgmzM
Improving Robotic Generalist Policies via Flow Reversal Steering
Source: https://flow-reversal-steering.github.io/ FRSZero-ShotDSBCDSRL + FRS## Flow Reversal Steering
1Stanford University,2UC Berkeley*Equal contribution
Abstract
Generalist policies can learn a wide range of skills from diverse robot datasets. In order to solve or improve on challenging new tasks, we need a way to infer and invoke the appropriate actions from the policy’s rich behavioral prior, especially when directly commanding the policy fails. We focus on flow matching generalists and proposeFlow Reversal Steering (FRS): a method that takes suboptimal but “reasonable” actions, finds their latent noises by passing them through the flow policy in reverse, and maps them to nearby generalist action modes. We evaluate FRS across many simulated and real-world manipulation settings. First, FRS can turn coarse semantic guidance from humans or vision-language models (VLMs) into corresponding good robot actions, improving zero-shot control. These gains can be distilled with behavioral cloning by training an auxiliary policy to output noises that the generalist maps to good actions — showing up to 95% absolute task success rate boosts in under a minute of training. Finally, FRS enables policy improvement by bootstrapping reinforcement learning with semantic knowledge, improving on several tasks that standard RL fails to improve on.
Flow Reversal Steering (FRS)
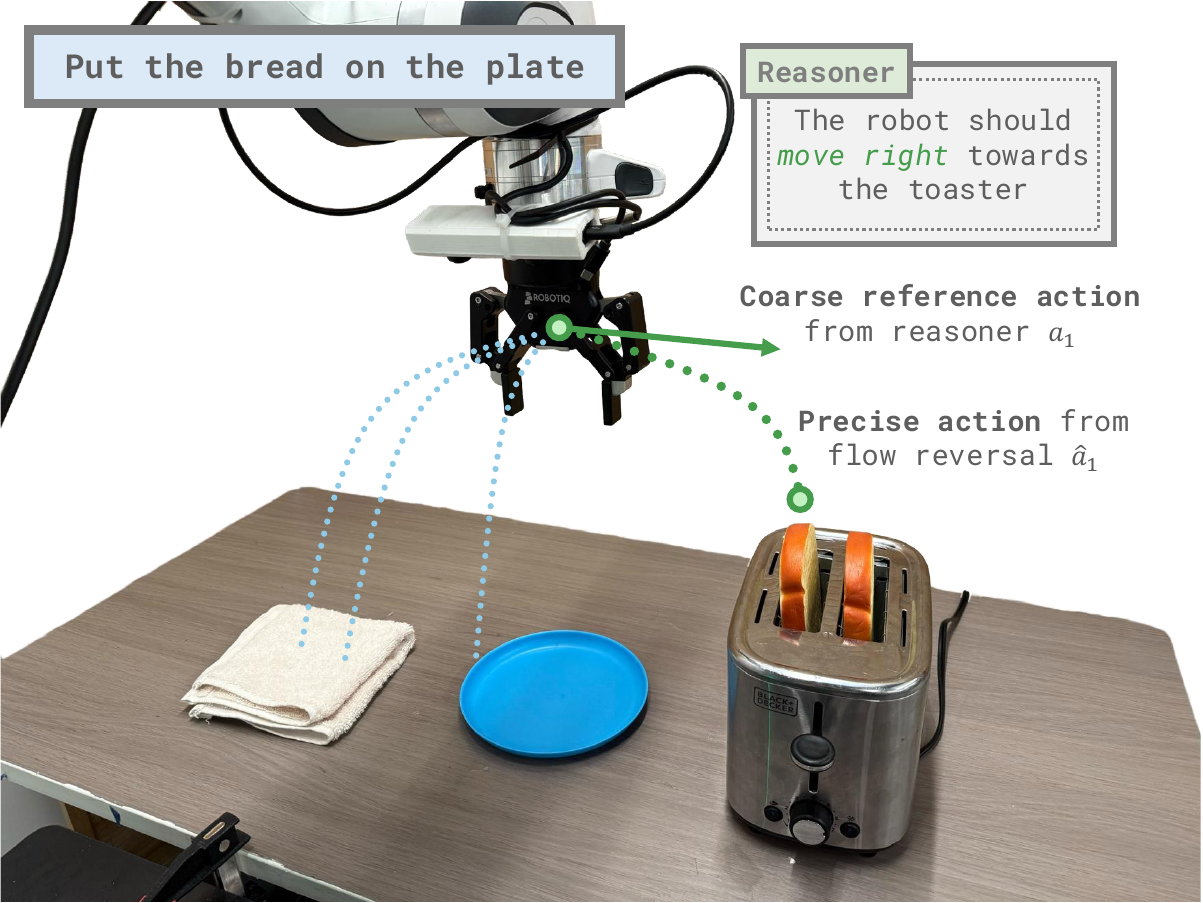
FRS passes coarse reference actions through a flow policy in reverse, finding latent noises which map to precise actions from a nearby behavioral mode.
t =1.00
Noise via flow reversalDenoise via flow matching
Generalist flow-matching robot policies learn a rich prior over behaviors. These policies contain many skills needed for novel tasks — provided these appropriate behaviors are elicited. How can we use semantic knowledge to steer generalist policies towards sampling “reasonable” actions for new tasks?
We thus proposeFlow Reversal Steering (FRS): a method for guiding generalist flow policies’ action sampling by finding underlying noises that map to semantically-reasonable behaviors. By passing a coarse reference action — which captures roughly how the robot should move — through the flow policy in reverse, FRS finds the noise which approximately maps to the action. When subsequently denoised,FRS effectively finds a nearby good behavioral mode from the generalist’s prior that is similar to the reference.
Standard Flow Denoising
# Sample action from flow policy (K integration steps)
x ~ N(0, I) # Sample noise
dt ← 1 / K
for t in 0 … 1: # K forward steps, size dt
x ← x + dt·vθ(x, t)
return x # action sample
Flow Reversal Steering
# Steer w/ reference action a_ref (K integration steps)
x ← a_ref
dt ← 1 / K
for t = 1 … 0: # reverse the flow → noise
x ← x − dt·vθ(x, t)
for t = 0 … 1: # denoise → nearby mode
x ← x + dt·vθ(x, t)
return x # refined, in-distribution
In turn, this allows semantic reasoners, like humans or VLMs, to guide the policy towards task-relevant good behaviors. The noises and actions produced by FRS can also be used for policy learning and improvement, especially via noise-space behavioral cloning and reinforcement learning.

Overview of the FRS pipeline.
We demonstrateFRSusing state-of-the-artπ0.5vision-language-action models (VLAs)in both simulatedLIBEROand real-worldDROIDmanipulation tasks. We present three ways to useFRS:
- Zero-shotFRS: directly execute the refined actionsFRSelicits from coarse human or VLM guidance, with no additional training.
- Diffusion Steering via Behavioral Cloning (DSBC): distill good noises from flow reversal into a noise policy using supervised learning.
- Diffusion Steering via Reinforcement Learning (DSRL) +FRS: bootstrap noise-space reinforcement learning withFRSrollouts.
Zero-Shot Flow Reversal Steering
FRSconverts coarse actions into better fine-grained actions from the generalist policy’s prior. The simplest way to useFRSis to directly execute these refined actions without any training. Thezero-shot FRSinference loop involves: (1) querying a reasoner (e.g. human or VLM) for a coarse reference action, (2) passing the reference action through flow reversal to find the corresponding noise, and (3) denoising this noise to get the final action to execute at each step.
We make use of theGemini-ER-1.6 VLMto scalably produce semantically-meaningful coarse directional reference actions for evaluation in the LIBERO simulator.
Zero-shotFRSallows a VLM to guide the generalist policy based on its semantic reasonings, raising performance across LIBERO.
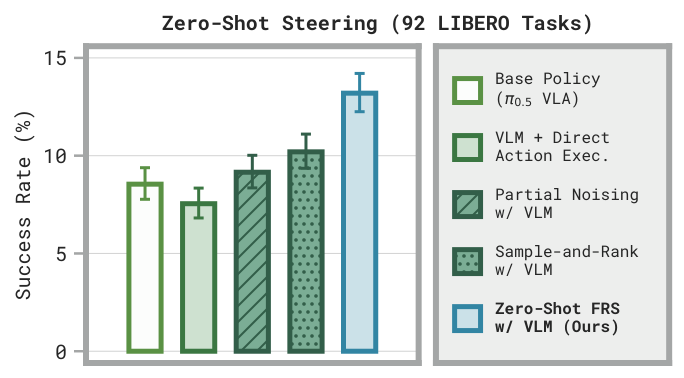 Zero-shotFRSconverts coarse VLM actions into effective robot actions, outperforming the base policy and prior steering methods.Zero-shotFRSoutperforms the base VLA across LIBERO. On hard tasks where the base policy achieves ≤ 2% success,11 of 42tasks gain at least**10%**absolute success rate with zero-shotFRS. Other steering baselines only boost 3 or 4 such tasks in this way, suggesting FRS is better in low-success regimes which are especially hard for generalist improvement.FRSalso outperforms directly executing VLM actions, showing that flow reversalrefinesthe coarse reference actions, rather than simply reconstructing them.
Zero-shotFRSconverts coarse VLM actions into effective robot actions, outperforming the base policy and prior steering methods.Zero-shotFRSoutperforms the base VLA across LIBERO. On hard tasks where the base policy achieves ≤ 2% success,11 of 42tasks gain at least**10%**absolute success rate with zero-shotFRS. Other steering baselines only boost 3 or 4 such tasks in this way, suggesting FRS is better in low-success regimes which are especially hard for generalist improvement.FRSalso outperforms directly executing VLM actions, showing that flow reversalrefinesthe coarse reference actions, rather than simply reconstructing them.
Diffusion Steering via Behavioral Cloning (DSBC)
Flow policies can be steered via small auxiliary noise policies, which output noises which the generalist flow policy maps to good actions. However, finding good noises can be challenging —past works like Diffusion Steering via Reinforcement Learning (DSRL)require trial-and-error and Q-learning to find good noises. In contrast, flow reversal rapidly and scalably identifies good noises when simply given reference actions.
Thus, flow reversal enables training noise-steering policies viasupervised learning, rather than expensive reinforcement learning. We naturally call thisDiffusion Steering via Behavioral Cloning (DSBC).
Real-World (DROID)
Noise policies trained with DSBC can steer the generalist VLA on real-world DROID tasks.
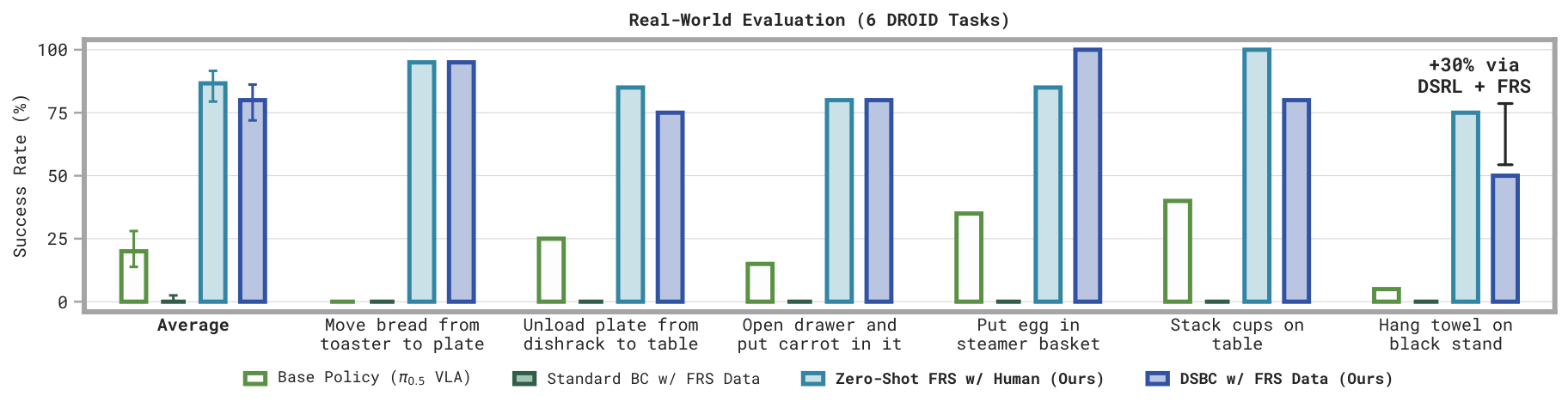
DSBC improves real-world task performance by training on FRS data.
DSBC trained on 10 successful human-steeredFRSrollouts per task significantly outperforms the base π0.5VLA on six DROID tasks. Standard BC with an equivalent flow policy completely fails in this data regime.
Offline DSBC (Ours) solves the precise tape-hanging task, where the base VLA and standard flow BC fail.
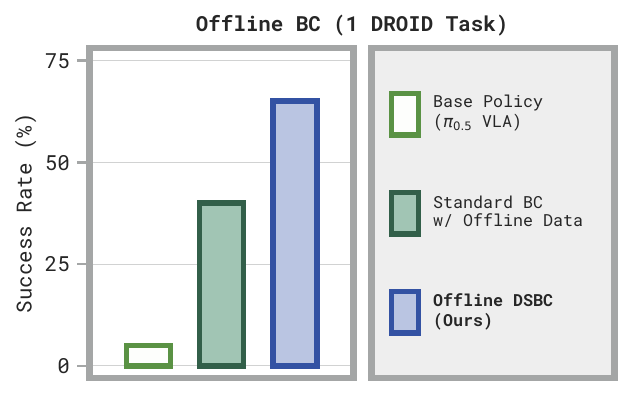 DSBC can also be trained fully offline from a fixed dataset of teleoperated trajectories.Alternatively, DSBC can also be used with standardofflinerobotic demonstration data, e.g., collected via teleoperation. Flow reversal can augment each frame with the noise that approximately maps to the corresponding action chunk, then the DSBC noise policy can be trained on this augmented dataset. We demonstrate this on a more precise tape hanging task, training on 20 teleoperated demonstrations.
DSBC can also be trained fully offline from a fixed dataset of teleoperated trajectories.Alternatively, DSBC can also be used with standardofflinerobotic demonstration data, e.g., collected via teleoperation. Flow reversal can augment each frame with the noise that approximately maps to the corresponding action chunk, then the DSBC noise policy can be trained on this augmented dataset. We demonstrate this on a more precise tape hanging task, training on 20 teleoperated demonstrations.
Simulation (LIBERO)
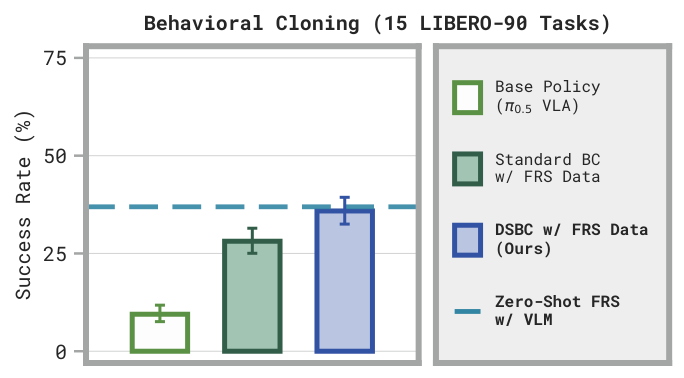 DSBC on latent noise actions matches zero-shotFRSand beats standard BC on robot actions.We also evaluate DSBC on LIBERO, where it distills the performance gains of zero-shot VLM FRS on 15 tasks, outperforming standard BC. DSBC is also highly efficient: each noise policy trains in under1 minuteusing ~1 GBof GPU memory, without loading the full VLA.
DSBC on latent noise actions matches zero-shotFRSand beats standard BC on robot actions.We also evaluate DSBC on LIBERO, where it distills the performance gains of zero-shot VLM FRS on 15 tasks, outperforming standard BC. DSBC is also highly efficient: each noise policy trains in under1 minuteusing ~1 GBof GPU memory, without loading the full VLA.
We hypothesize that when the noise policy enters out-of-distribution states, the VLA maps its outputs back to reasonable in-distribution actions, providing implicit robustness against compounding error.
Diffusion Steering via Reinforcement Learning (DSRL) +FRS
Bootstrapping DSRL withFRStrajectories enables faster learning and higher final success on hard tasks. We propose two simple augmentations forDSRL +FRS: (1) prefilling the replay buffer with zero-shotFRSrollouts and (2) adding a BC auxiliary loss on successful trajectories’ noise actions.
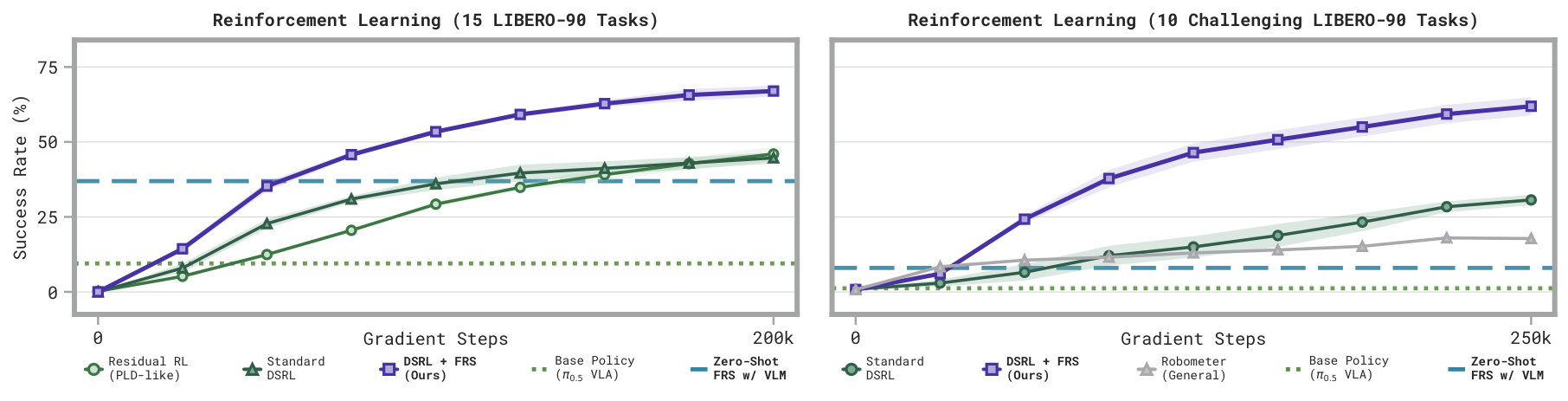
**Left:**DSRL +FRSon 15 tasks with effective zero-shot steering. **Right:**on 10 hard tasks whereFRSand the base policy both perform poorly, using even oneFRSsuccess drastically improves RL.
On 15 LIBERO-90 tasks, it learns faster and reaches higher final success than standard DSRL and PLD-style residual RL. On 10 harder tasks where the base VLA gets ~0% and zero-shotFRSreaches only 8%,even a single successful steered trajectory enables DSRL to learn substantially faster and better. By directing the learner toward semantically-meaningful behaviors early in training, DSRL +FRSimproves performance in the sparse-reward regime where standard generalist RL struggles.
As an example, DSRL +FRSlearns on Task 52:pick up the milk and put it in the basket, whereas standard DSRL completely fails, as the base VLA struggles to solve the task without semantic steering from VLMs.
BibTeX
@article{tang2026frs,
author = {Andy Tang and William Chen and Andrew Wagenmaker and Chelsea Finn and Sergey Levine},
title = {Improving Robotic Generalist Policies via Flow Reversal Steering},
year = {2026},
}
Similar Articles
@svlevine: Flow reversal steering allows "steering" diffusion-based VLAs with high-level actions, for example from VLM reasoning. …
Flow reversal steering enables steering diffusion-based vision-language-action models with high-level actions, such as from VLM reasoning, and allows RL in diffusion noise space for task exploration.
RoboLab: A High-Fidelity Simulation Benchmark for Analysis of Task Generalist Policies
RoboLab is a high-fidelity simulation benchmarking framework for evaluating task-generalist robotic policies, introducing the RoboLab-120 benchmark with 120 tasks across visual, procedural, and relational competency axes. It enables scalable, realistic task generation and systematic analysis of policy behavior under controlled perturbations to assess true generalization capabilities.
@svlevine: Diffusion (or flow) makes for excellent policies, but training them with RL is notoriously hard: BPTT is unstable, RL o…
New paper shows how to optimize flow matching actors for reinforcement learning by approximating the Jacobian of the flow denoising process with the identity matrix, making training feasible.
Generalizing from simulation
OpenAI describes challenges with conventional RL on robotics tasks and introduces Hindsight Experience Replay (HER), a new RL algorithm that enables agents to learn from binary rewards by reframing failures as intended outcomes, combined with domain randomization for sim-to-real transfer.
Beyond Steering Vector: Flow-based Activation Steering for Inference-Time Intervention
This paper introduces FLAS, a flow-based activation steering method that learns a concept-conditioned velocity field to steer language model activations at inference time. On the AxBench benchmark, FLAS is the first learned method to consistently outperform in-context prompting on held-out concepts without per-concept tuning.