@jerryjliu0: We built a cool project that shows you how to compose our core document intelligence primitives into a reusable pipelin…
Summary
Parse-Flow is an open-source visual workflow designer that composes document intelligence primitives (parsing, extraction, classification, splitting) into reusable pipelines, backed by LlamaIndex and a Python worker.
View Cached Full Text
Cached at: 06/05/26, 07:11 AM
We built a cool project that shows you how to compose our core document intelligence primitives into a reusable pipeline that turn your documents into machine-readable data. Come check it out! https://llamaindex.ai/blog/designing-a-visual-document-intelligence-workflow-with-llamaparse?utm_medium=socials&utm_source=twitter&utm_campaign=2026-jun-…
Parse-Flow: Open-Source Visual Document Intelligence Workflow Designer
Source: https://www.llamaindex.ai/blog/designing-a-visual-document-intelligence-workflow-with-llamaparse?utm_medium=socials&utm_source=twitter&utm_campaign=2026-jun- Unstructured documents are still the dominant interface businesses use to store and share the information they run on. From contracts to invoices to reports, these documents all have one thing in common: they are a mixture of layout, language and context that downstream systems can’t consume directly.Document intelligence, i.e. the discipline of turning those documents into structured, machine-readable data, is the layer that makes the rest of the modern AI stack actually useful for enterprise, since, without robust parsing, classification, splitting and extraction, every retrieval pipeline, every agent, every analytics dashboard would be built on fragile foundations .
Parse-Flowis a small open-source project that puts the four document processing primitives —Parsing,Extraction,ClassificationandSplitting— at the center of a visual workflow designer, an async worker, and a live event dashboard. You drag steps onto a canvas, drop a document in, and watch events stream back as the pipeline runs. This post is a tour of how it is built, with a particular focus on how the backend workflow is designed on top ofllama\-agentsworkflows.
 ParseFlow canvas## The shape of the system
ParseFlow canvas## The shape of the system
Parse-Flow is split across four cooperating processes:
- AReact frontendthat hosts the node-based workflow designer, the run view, and the jobs dashboard.
- ABun serverthat accepts uploads, talks to the LlamaParse Platform, enqueues jobs, reads history from Postgres, and bridges the event stream to the browser over Server-Sent Events.
- APython workerthat consumes jobs and executes the actual document workflow.
- Redisas the job queue and event bus, andPostgresas the system of record for jobs and their event history.
The communication pattern is the following: the Bun server pushes jobs onto a Redis list, the worker pulls them and, as the job runs, every event is added onto a per-job Redis stream and simultaneously persisted to Postgres. The Bun server bridges that stream to the browser with by creating a dedicated subscriber connection, sending keep-alives and closing the connection once a final event is observed.
This separation buys two main things:
- the worker is free to be slow without blocking the HTTP layer
- Every event is captured twice (once on the live stream, once in durable storage) so a user who reloads the page can see and replay the full history reconstructed from Postgres
Four primitives, arbitrary compositions
The workflow vocabulary is intentionally narrow and focused around the services offered by the LlamaParse Platform:
- parse— turn a document into clean markdown and text using Parse, choosing a tier and an optional prompt.
- classify— assign the document to one of a set of user-defined rules with reasoning and a confidence score.
- split— segment the document into typed chunks according to a list of categories.
- extract— pull structured JSON out of the document against a user-provided JSON schema.
What gives the system its expressive power is not the primitives themselves but theallowed-pairs graphthat constrains how they can be chained. Not every transition is meaningful:extractis always terminal,parsecan hand off to any of the other three,classifyandsplitcan route intoparseorextractbased on which rule or category matched. The frontend validates the flow against this graph before it is ever submitted, and the backend re-validates it on the way in.
The result is a small Domain Specific Language built on JSON: aFlowDefinitionof ordered steps with typed handoffs, that is rich enough to describe most real document pipelines (parse-then-extract, classify-then-route-to-the-right-schema, split-by-section-then-parse-each-differently) while staying small enough to reason about exhaustively.
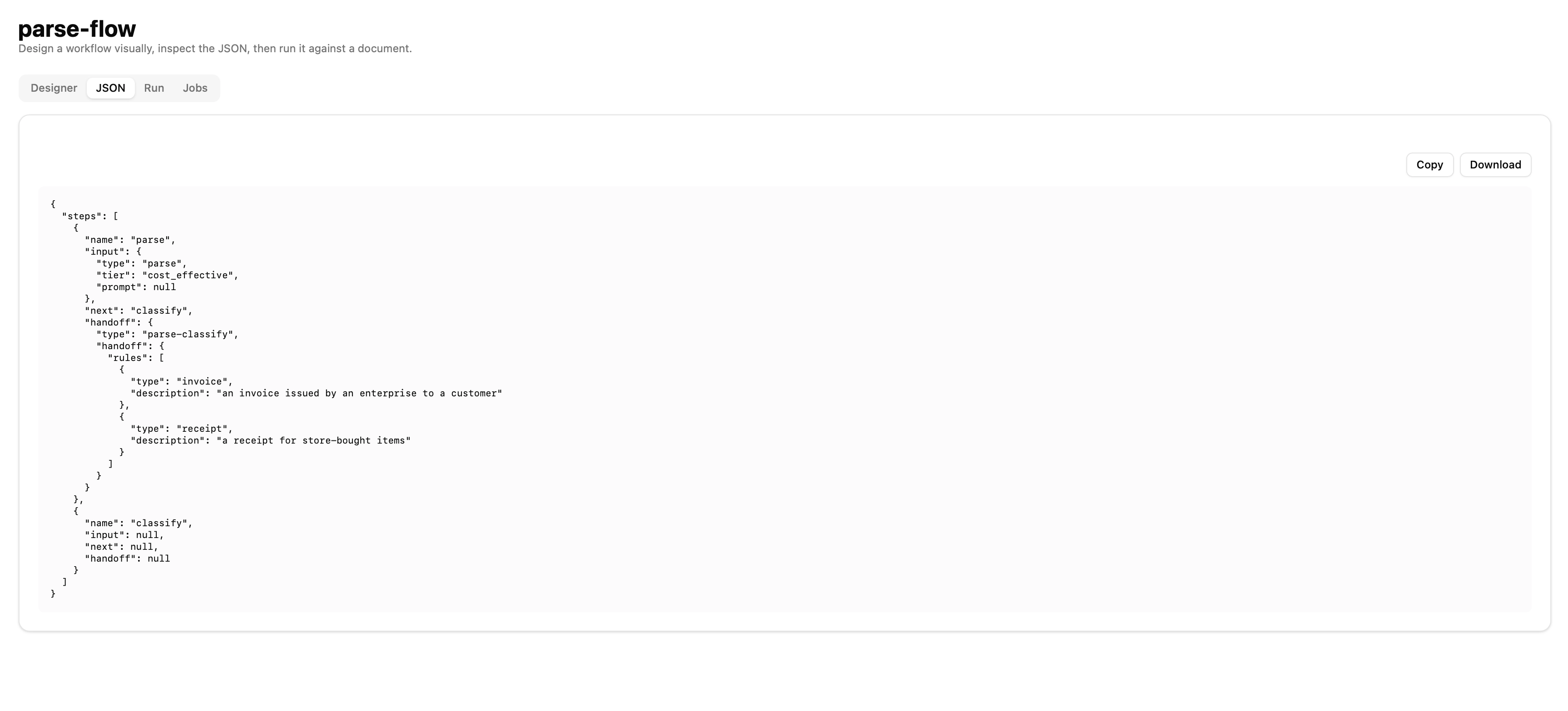 JSON definition of a flow in ParseFlow## The LlamaAgent workflow at the core
JSON definition of a flow in ParseFlow## The LlamaAgent workflow at the core
The interesting design work lives in the worker, where a single LlamaAgentWorkflowinterprets the user-defined flow at runtime.
Thellama\-agentsframework provides an event-driven, unopinionated workflow engine: each@stepis an async function that takes an event in and returns one or more events out, and the runtime routes events to whichever step’s type signature matches. State is held in a typedContextstore that steps can read and edit transactionally. Events written viactx\.write\_event\_to\_streamare surfaced to whoever is observing the run (in our case, the worker that forwards them to Redis and Postgres).
Parse-Flow’sDocumentWorkflowexposes exactly three steps, and the key of the execution system is in how they cooperate to walk a flow of arbitrary length.
Step 1 — bootstrap
The first step receives aRedisInitialEventcarrying the parsedFlowDefinitionand the LlamaCloud file ID. It writes the flow into the workflow state, records that we are at index zero, and emits the typed input event for whatever the first step happens to be (aParsingInputEvent, aClassifyInputEvent, aSplitInputEventor anExtractInputEvent). From this point on the workflow is data-driven; the bootstrap step never runs again.
Step 2 — the worker
The worker step has a deliberately wide input type: anyInputEvent. It pattern-matches on the event type, advances the step index in state, and dispatches to the corresponding operation on the LlamaParse Platform. Each operation returns a Rust-likeResultthat is unwrapped into either the typed success event (with the parsed markdown, the classification verdict, the segmented chunks, or the extracted JSON) or anErrorOutputEventcarrying the failure message.
A small but important detail: once aparsestep has produced aparse\_job\_id, subsequentclassifyandextractoperations prefer that ID over the raw file. This means that when the user chainsparse → extract, the extract step operates on the already-parsed representation rather than re-parsing the file from scratch, a free latency and cost reduction that comes from state being shared across steps.
Step 3 — the router
The post-process step is where the allowed-pairs graph is actually enforced at runtime. It looks at the last output event, the current step in the flow, and the handoff descriptor recorded on the previous step. From those three pieces of information it decides what to emit next:
- If we have walked off the end of the flow, it wraps the last output in a
WrapperStopEventand the workflow terminates. - If the output is an error, it short-circuits to a stop.
- Otherwise it consults the handoff (
classify\-extract,parse\-classify,split\-parseand so on) to construct the next input event. For routing handoffs, this means looking up the JSON schema, the parse tier and prompt, or the categories that correspond to whichever rule the previous step matched, and packing them into the next input event.
That router then emits anInputEventagain, which loops straight back into the worker step. The bootstrap-worker-router triple becomes a state machine that walks the user’s flow one step at a time, with every transition typed, every handoff validated, and every event observable.
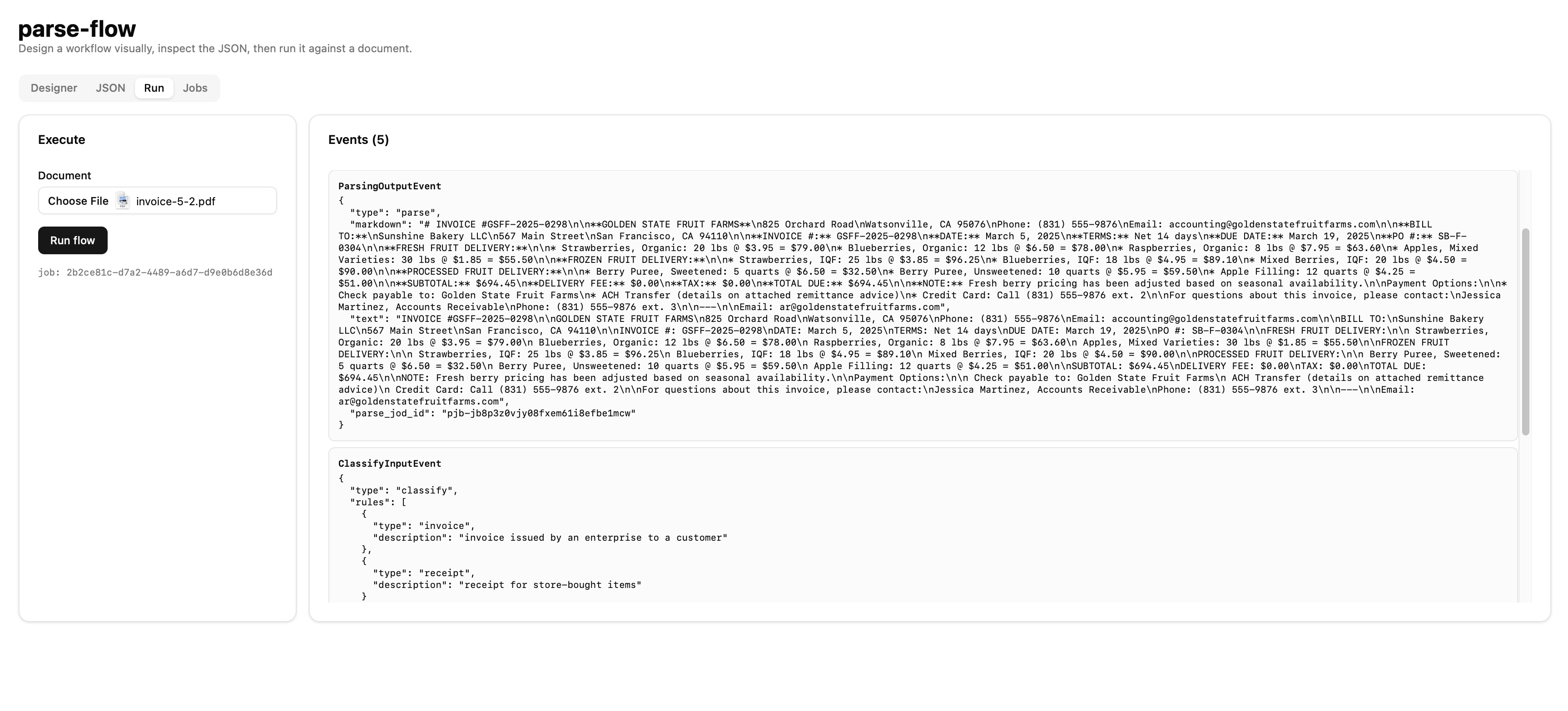 Dashboard displaying events during a ParseFlow run## Why this design holds up
Dashboard displaying events during a ParseFlow run## Why this design holds up
Three properties make the design pleasant to live with.
**The flow lives in the event, not in the code.**The sameDocumentWorkflowruns every job. New pipelines do not require new Python, they simply require a new JSON definition of the flow . That is what makes a visual designer on top of it feasible at all.
**Every transition is observable.**Because each step writes its events to the stream before returning, the dashboard sees the workflow exactly as the workflow sees itself. There is no separate logging layer to drift out of sync with reality.
**Failure is a value.**Errors are first-class output events that the router knows how to turn into a clean stop. The user gets a final event with a real message; the system never silently hangs.
Document intelligence is the layer that matters
It is tempting, in 2026, to treat parsing and extraction as solved problems hiding behind a model call. They are not. A pipeline that classifies an invoice with the wrong schema, or splits a contract on the wrong boundary, or extracts a date from the wrong page, will fail downstream in ways that no amount of retrieval cleverness can recover. The systems that are durable are the ones that take document intelligence seriously as a first-class engineering concern: composable primitives, validated transitions, observable runs, durable history.
Parse-Flow is a small example of what that looks like when you let yourself design the workflow layer properly: four primitives, a typed handoff graph, and a LlamaAgent workflow whose only job is to walk it.
Try it
The full source is open. Clone it, point it at a LlamaCloud key, and bring your own documents.
→github.com/run-llama/parse-flow
LlamaIndex 🦙 (@llama_index): Most AI pipelines are only as good as the data we provide them with, and that usually means PDFs or other unstructured documents.
Contracts, invoices, reports… All have special layout, language, and context mixed together, and getting reliable structured data out of them is
Similar Articles
@llama_index: Most AI pipelines are only as good as the data we provide them with, and that usually means PDFs or other unstructured …
Parse-Flow is an open-source visual workflow designer built by LlamaIndex that chains four document processing primitives—Parse, Classify, Split, and Extract—into a drag-and-drop canvas powered by LlamaAgents workflows, enabling reliable structured data extraction from unstructured enterprise documents like PDFs, contracts, and invoices.
@jerryjliu0: LiteParse is the best open-source, model-free document parser for AI agents. Run it over over 50+ document types, and i…
LlamaIndex releases liteparse-server, a self-hosted, model-free HTTP API for parsing diverse document types with high spatial fidelity and privacy preservation.
@jerryjliu0: Our core mission today is using AI to solve document OCR. All of our product offerings, from commercial (LlamaParse) to…
LlamaIndex has revamped its website and reaffirmed its core mission of AI-powered document OCR, with offerings including commercial product LlamaParse and open-source tools LiteParse and ParseBench. LlamaParse uses VLM-powered agentic document understanding to handle complex layouts, tables, charts, and handwritten text at scale.
@itsclelia: Do you actually own your document parsing infrastructure? At @llama_index, we wanted to make that easier, so we built �…
LlamaIndex introduces liteparse-server, an open-source, self-hosted HTTP backend for parsing PDFs, images, and Office documents with spatial layout extraction, OCR, and screenshot generation, designed for AI and data workflows.
@jerryjliu0: Fully solving document parsing includes covering every point on the Pareto curve of accuracy, cost, and latency: High-a…
Jerry Liu presents a framework for document parsing across accuracy, cost, and latency tradeoffs, introducing LiteParse as an open-source, low-latency parsing tool for AI agent loops, along with LlamaParse for high-accuracy modes.