@rsalakhu: Congrats to the @browser_use team for taking the #1 spot on Odysseys, a highly challenging benchmark for long-horizon w…
Summary
The browser_use team achieved the #1 spot on the Odysseys benchmark, a challenging evaluation for long-horizon web agents, outperforming models like Opus 4.6 and GPT-5.4.
View Cached Full Text
Cached at: 06/16/26, 09:40 PM
Congrats to the @browser_use team for taking the #1 spot on Odysseys, a highly challenging benchmark for long-horizon web agents:
https://odysseys-website.pages.dev/leaderboard
Odysseys evaluates realistic, multi-hour web workflows that require sustained planning, memory, reasoning, and verification across numerous websites and tools, far beyond short single-step browser tasks.
Exciting progress toward truly capable long-horizon agents.
Leaderboard — Odysseys
Source: https://odysseys-website.pages.dev/leaderboard Nine entries on all 200 Odysseys tasks. Eight CUA models were evaluated by us under identical settings — 100-step budget, maximum reasoning effort, Google Chrome in an OSWorld Ubuntu VM.
ModelTypeAgentO-M2W JudgeRubric AvgPerfectAvg. StepsTraj. Eff.
*Notes.Rubric Avgtreats each task rubric pair as an independent observation and averages them.Perfectmarks a task as passing only if every rubric is satisfied.O-M2W Judgeis the trajectory-level holistic LLM judge from Online-Mind2Web.Avg. Stepsis the mean number of interaction steps the agent takes per task, where lower is more efficient.Traj. Eff.(Trajectory Efficiency) is\(1/N\) · Σ sᵢ / nᵢ, wheresᵢis the averaged rubric score on taskiandnᵢis the number of agent steps. Higher values mean stronger outcomes achieved in fewer steps.AgentdistinguishesCUA(computer-use agents that consume screenshots and emit GUI actions) fromTerminalagents that drive the browser by writing code (e.g. Playwright). Cells marked—*are metrics not reported by the source. CUA scores are reproduced from Table 2 of the paper; WebWright is reproduced from the WebWright article.
Breakdown by difficulty
Tasks come in three tiers. Easy tasks use at most 5 steps and 3 domains, medium tasks use 6 to 8 steps or 4 or more domains, and hard tasks exceed both thresholds. Each bar shows the perfect rubric rate, the share of tasks a model solves with every rubric item satisfied.
Steps vs perfect score
Each model’s perfect rubric rate plotted against its average number of steps per task, with the Pareto frontier overlaid. Opus 4.6 sits at the capability end of the frontier, with GPT-5.4 and GPT-5.4 Mini trading off step budget for perfect rate. Each additional step of compute buys progressively smaller gains.
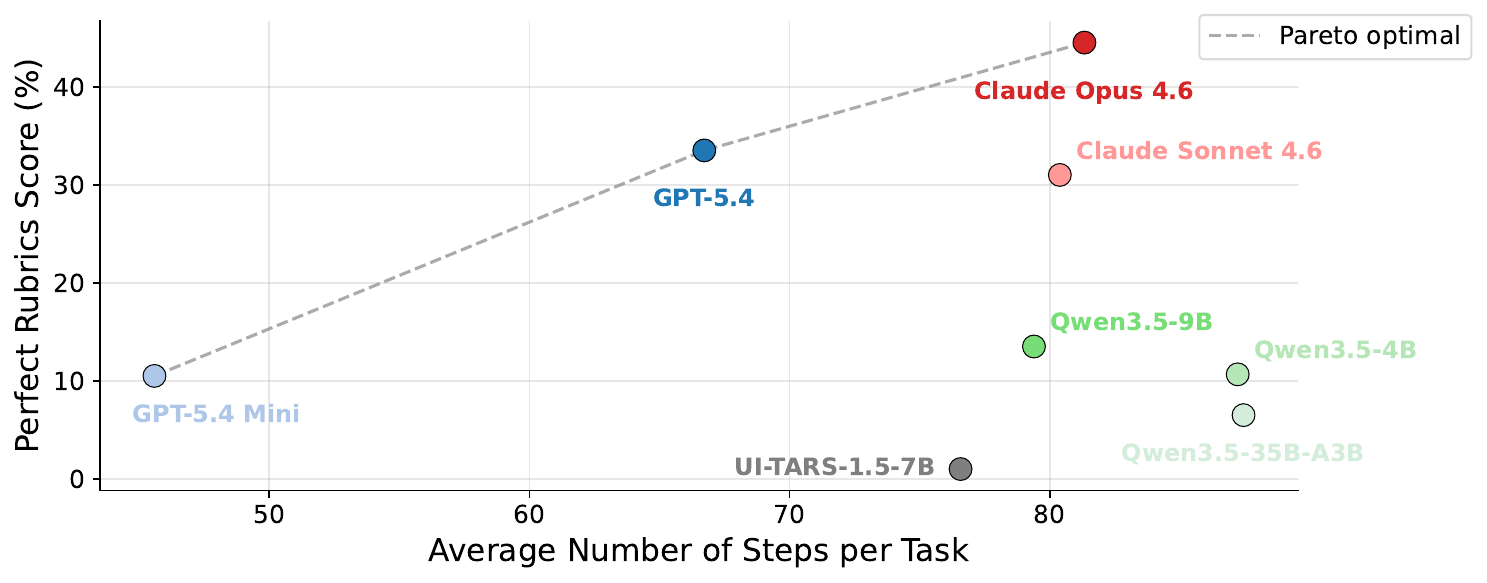 Figure.Sonnet 4.6 is Pareto-dominated by both Opus 4.6 and GPT-5.4, which achieve higher perfect rates with fewer steps. Open-weight models sit well inside the frontier, spending more steps for substantially lower perfect rates, pointing to capability ceilings rather than step-budget shortfalls.
Figure.Sonnet 4.6 is Pareto-dominated by both Opus 4.6 and GPT-5.4, which achieve higher perfect rates with fewer steps. Open-weight models sit well inside the frontier, spending more steps for substantially lower perfect rates, pointing to capability ceilings rather than step-budget shortfalls.
Similar Articles
@browser_use: BrowserCode is incredibly good at long-running tasks It orders pizza for us
BrowserCode achieves #1 spot on Odysseys benchmark for long-horizon web agents, demonstrating strong performance in multi-hour web workflows.
@gregpr07: Browser Use Beta just achieved SOTA on our hardest internal web agent benchmark. Fable is genuinely amazing for optimiz…
Browser Use Beta achieved state-of-the-art results on a difficult internal web agent benchmark, using Fable for optimization and analysis.
@browser_use: Introducing Browser Use 0.13.0 [beta] > The old Browser Use was built for GPT-4. > This one was built for SOTA models. …
Browser Use 0.13.0 is a complete rewrite in Rust, providing custom LLM and browser harnesses optimized for state-of-the-art models, replacing the previous GPT-4-centric version.
"Browser OS" implemented by Qwen 3.6 35B: The best result I ever got from a local model
A user reports achieving impressive results with Qwen 3.6 35B running a 'Browser OS' implementation locally, highlighting the model's capability for complex task execution without cloud dependencies.
@reagan_hsu: hello potential Browser Use Desktop(https://github.com/browser-use/desktop…) users!! if you've used the app, love it or…
Browser Use Desktop is an open-source app for running AI browser agents, with cookie syncing and keyboard shortcuts, supporting Anthropic and Codex models.