@pauliusztin_: I spent months optimizing GraphRAG retrieval. But it turned out I was optimizing the wrong thing.... The biggest knowle…
Summary
A detailed guide on optimizing knowledge graph ingestion for AI agents, presenting a five-step pipeline (extraction, resolution, embedding, deduplication, routing) to prevent graph corruption and improve retrieval quality.
View Cached Full Text
Cached at: 06/10/26, 09:58 PM
I spent months optimizing GraphRAG retrieval.
But it turned out I was optimizing the wrong thing….
The biggest knowledge graph problems usually occur during ingestion (even though most conversations focus on retrieval).
Every new document creates a risk of graph corruption.
This is why I now think about knowledge graph ingestion as a 5-step pipeline:
1/ Extraction
Convert raw text into entities and relationships.
For example: Person → WORKS_AT → Organization
The goal is to extract what your ontology cares about.
2/ Resolution
This step standardizes names.
For example:
NYC → New York City P Morgan → JPMorgan Chase Jon Smith → John Smith
Most importantly, nothing has been merged yet.
3/ Embedding
Next, embed the entity’s full context (not just the name).
Think:
Type Attributes Metadata Relevant content
Because identity lives in context.
4/ Deduplication
Many systems fail here.
Because:
Apple the company ≠ Apple the fruit Paris, France ≠ Paris, Texas Two people can share the same name
Resolution answers naming. Deduplication answers identity.
Those are two completely different jobs.
5/ Routing
Finally, the system decides:
Merge Human review Create new node
And the best systems follow a simple rule:
Evidence strength = permission strength.
Weak evidence → new node Strong evidence → merge Uncertain evidence → human review
Because false merges are expensive.
A duplicate node is annoying.
But a corrupted graph can silently poison retrieval quality for months.
My biggest takeaway?
Knowledge graph quality isn’t determined by your retrieval strategy…
It’s determined by the pipeline that creates the graph in the first place.
Get these five steps right… and retrieval becomes much easier.
P.S. I break down the full pipeline, entity resolution, deduplication thresholds, review queues, and production architecture in Decoding AI Magazine
Check it out here: https://decodingai.com/p/keep-knowledge-graph-clean…
How to Keep a Knowledge Graph Clean for AI Agents
Source: https://www.decodingai.com/p/keep-knowledge-graph-clean
 Two months ago, I started building unified memory layers on top of knowledge graphs. One question kept coming back from readers. How do you handle entity resolution and deduplication without corrupting the graph?
Two months ago, I started building unified memory layers on top of knowledge graphs. One question kept coming back from readers. How do you handle entity resolution and deduplication without corrupting the graph?
Rather than guessing, I spent serious time studying how mem0, cognee, and Neo4j actually solve it. The recurring question exposes a confusion almost everyone shares. People treat entity resolution and deduplication as the same step.
That confusion is exactly what corrupts graphs. People collapse naming and identity into 1 fuzzy check.
Also, if the merging step is not properly designed, 2 different real-world entities can silently merge, corrupting your graph.
Resulting in losing the trust in your graph that made it worth building. The graph quietly rots. Nobody trusts it, and the entire memory layer you invested in goes unused.
The failure is invisible until it becomes expensive to undo. The fix is to separate naming from identity.
We will walk through the end-to-end pipeline. This includes LLM extraction, entity resolution for naming, embedding the full node and deduplication for identity. Plus, the 2 safety nets most tutorials skip.
We covered the fullmemory-system designand theontology designin prior articles. This piece focuses only on keeping the graph clean. By the end, you will be able to design a graph that stays clean and usable as it grows.
Why We Killed RAG in Production (Product)
 This article shows how to keep a graph memory layer clean. In a recent podcast, I covered the decision that comes before it: whether you need retrieval at all.
This article shows how to keep a graph memory layer clean. In a recent podcast, I covered the decision that comes before it: whether you need retrieval at all.
I explain why we killed RAG for a financial advisor product. All of an advisor’s data summed to 64,000 tokens, so loading the full context beat RAG’s zigzag retrieval loop. The formula I use: your data-to-context-window ratio.
We also get into regretting MCP everywhere, treating vibe-coded output as a compilation step, and why AI evals become the real job once the model writes the code.
In goes a document or a conversation turn. Out comes a set of canonical, deduplicated nodes correctly wired into the existing graph. Everything between is about making sure each new node is named and identified right.
First, an LLM extractor reads the text and emits entities and relationships connected by\(entity, relationship, entity\)triplets. It anchors within the POLE+O, Facts, and Preferences ontology. This ensures it only extracts the entity types you actually care about, as we explained in depthin this article.
For example, a sentence about a person working at a company becomes a\(Person\)\-\[:WORKS\_AT\]\-\>\(Organization\)triplet. The ontology told the extractor those are the types that matter.
If using only LLMs for extraction becomes too costly, you can use a cost-tiered cascade here, starting with fast statistical models like spaCy for common entities, moving to zero-shot models like GLiNER for domain-specific types, and falling back to an LLM for complex cases.
Before touching the graph, we must decide what this new entity should be called. The system normalizes its name against existing nodes of the same type. This is the finding-the-canonical-name step, and no merges happen yet.
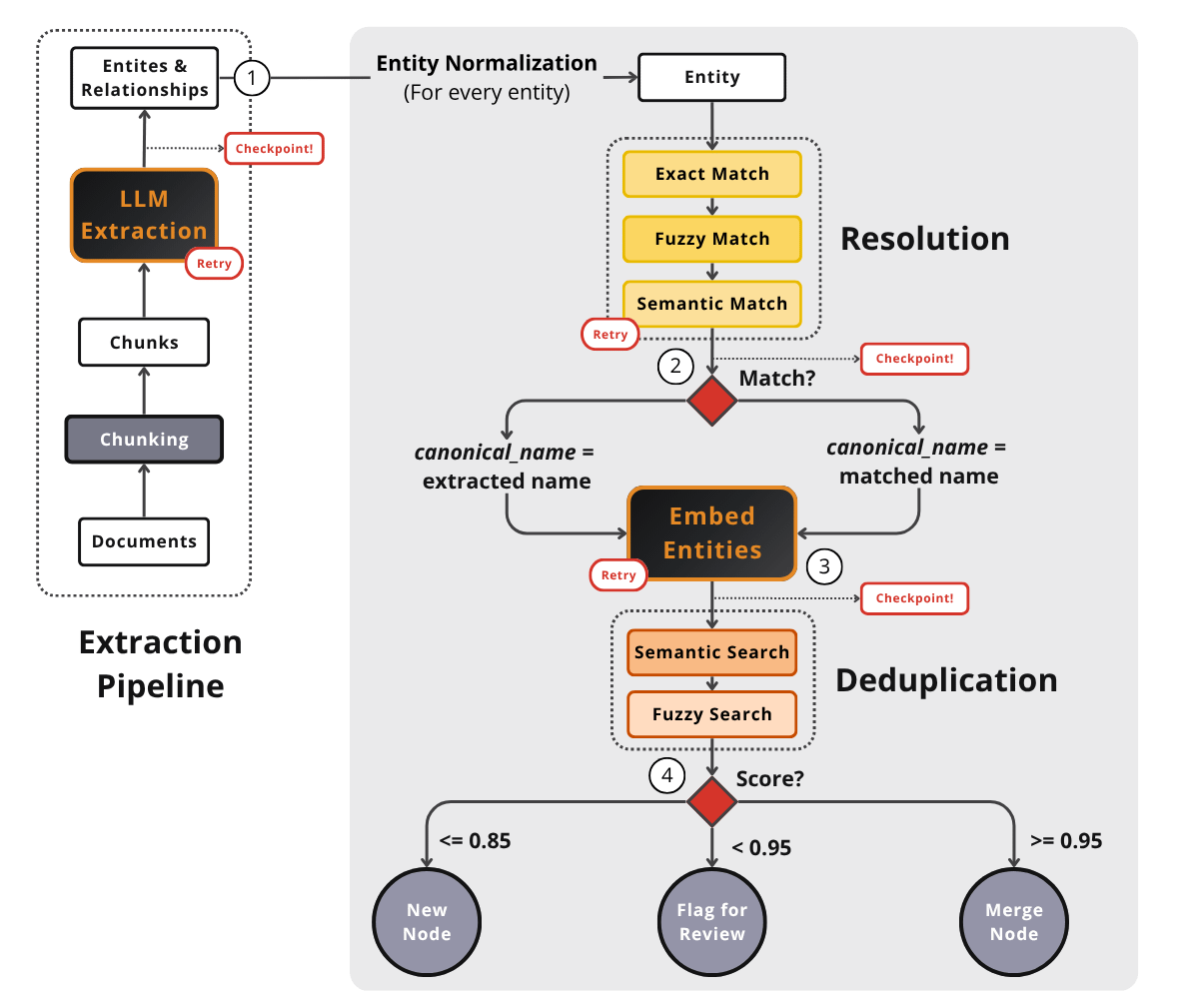 From raw documents to a clean graph node: extraction, resolution, embedding, deduplication, then the merge/flag/add decision.
Next, we compute an embedding over the entity’s full context. This includes its name, type, and attributes. We embed more than just its bare name. This is what later lets deduplication compare identity rather than spelling.
From raw documents to a clean graph node: extraction, resolution, embedding, deduplication, then the merge/flag/add decision.
Next, we compute an embedding over the entity’s full context. This includes its name, type, and attributes. We embed more than just its bare name. This is what later lets deduplication compare identity rather than spelling.
We compare the embedded node against existing nodes. This decides whether it is the same real-world entity as one already in the graph.
Based on the deduplication outcome, the system makes a final routing decision. It either merges into an existing node, flags the pair for human review, or adds a brand-new node.
A new mention of a company gets extracted as a typed entity. The resolution step normalizes it to a canonical name. Then, it gets embedded with its full context so we capture its semantic meaning. It is compared against existing same-type nodes to verify its identity. Finally, it gets added, merged, or flagged for review.
Resolution and deduplication are 2 distinct decisions doing 2 distinct jobs. Let’s zoom in on each one.
During resolution we find the canonical name for each entity. It answers*“what should we call this?”*.
It handles typos, acronyms, and surface-form similarity. These are the noisy ways humans and documents write the same thing. It uses exact, fuzzy, and semantic matching in a short-circuit chain.
The short-circuit chain passes the entity to the next matcher only if no confident match is found. If exact match fails, it tries fuzzy match. If fuzzy match fails, it tries semantic match (using light embeddings only on the name).
But it matches only against the names of existing nodes of the same type. You never compare aPERSONname against anORGANIZATIONname.
“NYC” resolves to “New York City”. “JP Morgan” resolves to “JPMorgan Chase”. The 3 forms"John Smith ","john smith", and"Jon Smith"all collapse to 1 canonical “John Smith”.
This happens because resolution absorbs whitespace, casing, and typo variations. Fuzzy string matching uses token-based comparison to handle word order and partial matching for abbreviations. At this stage the system only updates the node’scanonical\_nameproperty. No graph merges happen yet.
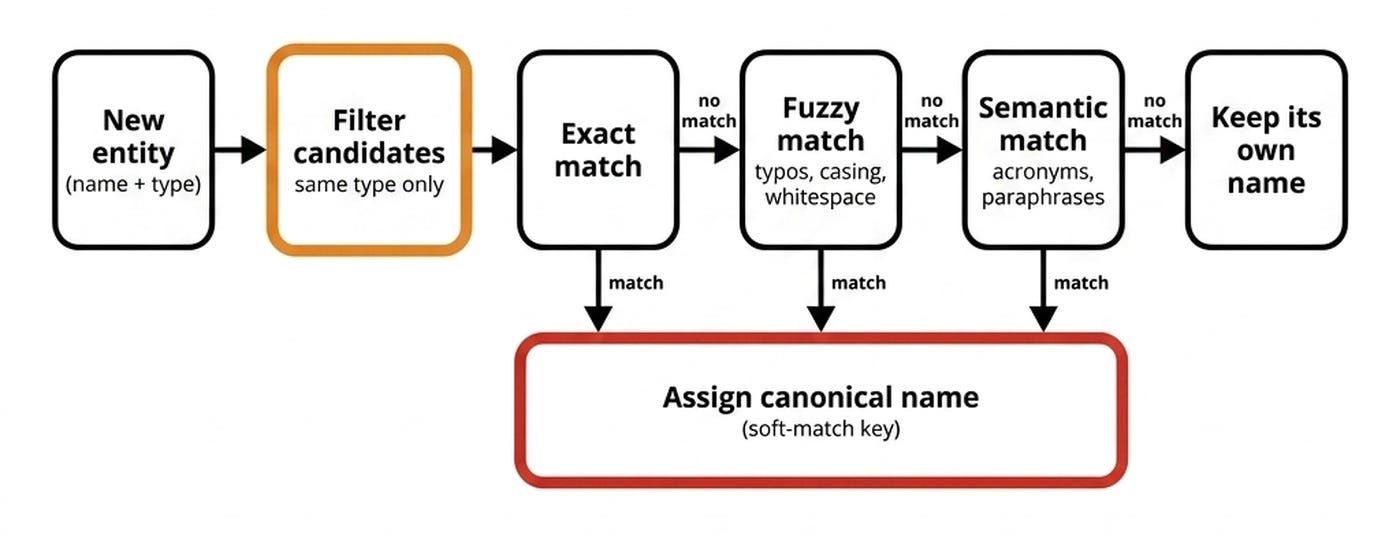 Resolution chains exact → fuzzy → semantic matching against same-type names to assign a canonical name (without ever merging nodes).
Often, you also keep track of a list of aliases for each node. Whenever you find a new hit via fuzzy or semantic match that doesn’t match the current
Resolution chains exact → fuzzy → semantic matching against same-type names to assign a canonical name (without ever merging nodes).
Often, you also keep track of a list of aliases for each node. Whenever you find a new hit via fuzzy or semantic match that doesn’t match the currentcanonical\_name, you add it to the list of aliases. Like this, in future checks you can speed up matching by checking the alias list first.
Similar names are not strong enough evidence that 2 entities are identical. This is the line most people blur. Blurring it is what causes silent corruption.
Apple the company is not Apple the fruit. They have different types, so type-gating already separates them. A harder example is Jensen Huang the CEO of NVIDIA versus a doctor in Taipei with the same name.
They have the same name and the same type. Yet they are 2 different real-world people. Naming similarity alone would happily fuse them.
Still, canonical names are extremely useful for GROUP BY operations where, during querying and visualizations, we can quickly understand the data. During human review, we can even spot duplicates and resolve them manually.
That is why identity is a separate decision. Resolution has told us what to call the node. It has deliberately not told us whether the node is a duplicate.
That second, riskier question belongs to deduplication.
Deduplication is the identity layer. It answers the harder question:“is this the same real-world entity?”. It is the step where merges actually happen[5].
In goes 1 embedded node. Out comes a single routing decision: merge into an existing node, flag it for review, or create a new node.
The system embeds the full entity context. It compares it against existing nodes using semantic and fuzzy similarity across that full context. The richer signal is what lets it distinguish 2 same-named, same-type entities that resolution could not.
By the context of a node, we refer to the entity’s attributes such as its text, image, video content or even its metadata properties such as a person’s email or date of birth. Or an object’s model or manufacturer. Still, you don’t want to embed everything, such as identifier, but per each ontology type pick the fields that contain the highest signal.
The combined deduplication score is an explicit weighted blend. It uses the embedding score multiplied by 0.7 and the fuzzy score multiplied by 0.3. Based on a similarity score from 0 to 1, we have 3 bands.
High confidence (≥0.95) triggers an auto-merge. Medium confidence (0.85–0.95) flags the pair for human review. Low confidence (<0.85) creates a new node.
Near-certain identity is allowed to merge automatically. The uncertain middle is escalated. Weak evidence just becomes a fresh node.
False merges silently corrupt the graph. The corruption is invisible until it is expensive. Take the Paris example: 2LOCATIONnodes both named “Paris”.
One is the capital of France, and the other is Paris, Texas. They have the same name, the same type, and very similar bare-name embeddings. But they are 2 different places.
The dangerous part is the middle band, the gray area. This is where the system is not sure and a human has to step in.
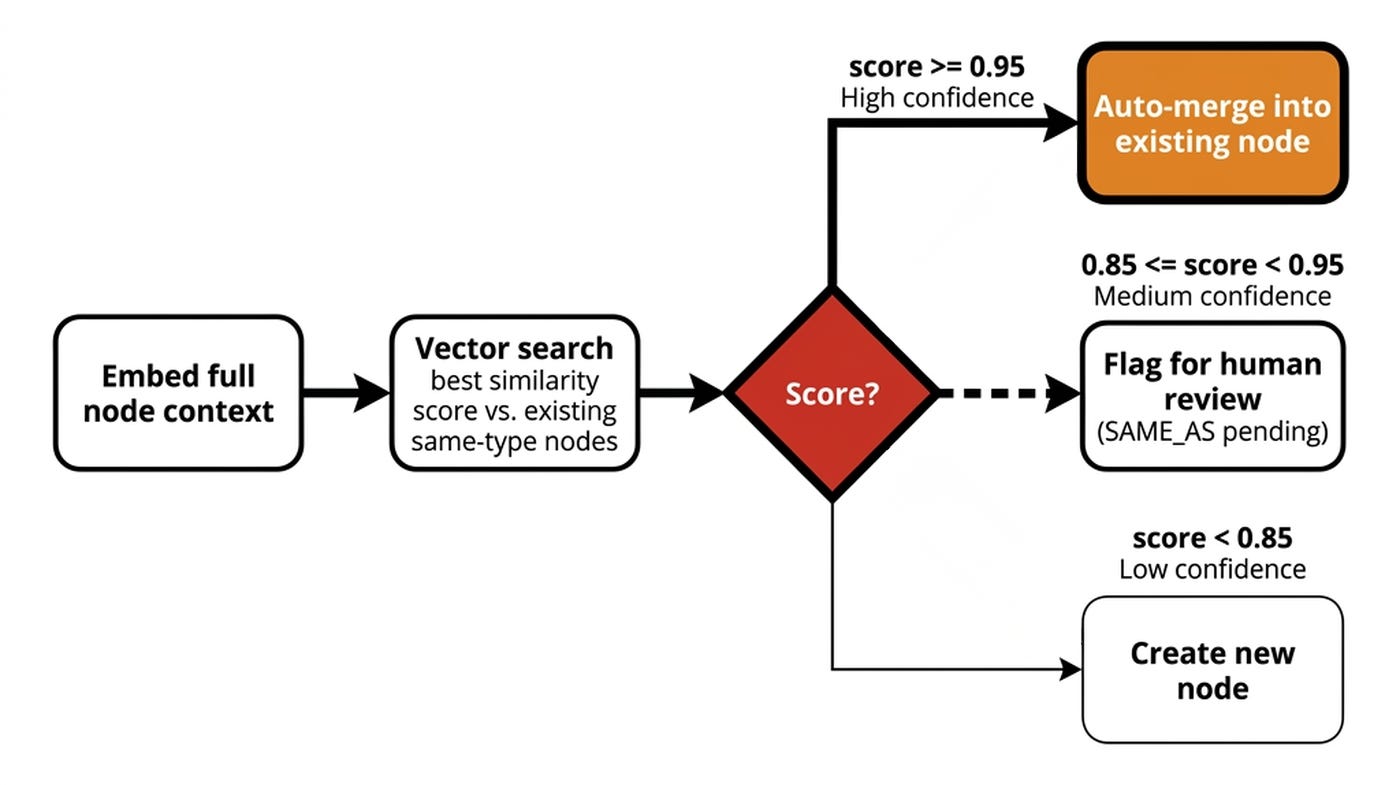 Deduplication scores full-context similarity, then routes to auto-merge, human review, or a new node.
When a deduplication score lands in the medium band (0.85–0.95), the system deliberately does not merge. It flags the pair for a human to decide, as merging is a dangerous operation we should be really deliberate about.
Deduplication scores full-context similarity, then routes to auto-merge, human review, or a new node.
When a deduplication score lands in the medium band (0.85–0.95), the system deliberately does not merge. It flags the pair for a human to decide, as merging is a dangerous operation we should be really deliberate about.
The source node gets tombstoned, meaning it is kept queryable for forensics but skipped from future matching. Actually undoing a merge means re-ingesting the source data. That reversibility cost is the whole reason for the gray zone.
Whenever a new entity is flagged for human review, a new node is created and a\(:Entity\)\-\[:SAME\_AS \{status:'pending', confidence\}\]\-\>\(:Entity\)edge is added inside the graph itself. The human review step transitions thatstatustoconfirmedorrejected. The review queue is just a Cypher query over pendingSAME\_ASedges, ordered by confidence.
For each flagged pair, the reviewer answers 1 question. Is this actually a duplicate, a new node, or neither?
This usually happens to entities that are related but not identical. The Codex model and the Codex CLI are related, but not the same object. The same applies to Jensen Huang the CEO versus a same-named doctor in Taipei.
This is hardest at the start of an entity’s lifecycle. When metadata is scarce, similarity spikes, and you risk polluting 1 node with another’s attributes.
Human review catches the uncertain pairs the live pipeline surfaces. But some duplicates never get surfaced at all. That is the gap the dream pipeline closes.
While the system ingests documents, data often flows through in parallel. If 2 entities are processed at the same time, the resolution and deduplication steps never get to compare them against each other.
The system would never check whether Claude Code from Conversation X and Claude Code from Document Y are the same entity, because neither existed in the graph when the other was written.
You run a dream pass every night. It re-runs the deduplication pass on recently ingested nodes only. Otherwise, you will have to loop through all nodes in the graph. Which as the graph grows, becomes increasingly expensive.
It does not run the full resolution chain. Because the embeddings were already computed at ingest time, this is a light operation. It is primarily database reads and writes, not fresh model calls. Since it mostly adds I/O pressure, run it when organic traffic is low, which is usually during the night, hence the namethe dream pipeline.
I’ve spent the past 4 months building unified memory layers on top of knowledge graphs, and I learned that keeping them clean is the hardest part. Keeping your knowledge graph clean is the maintenance step that decides whether the graph ever gets used. A graph full of noise, fragments, and false merges will not be trusted or queried.
In case you want to learn more, remember that we also covered the fullmemory-system architecture via knowledge graphsand theontology designin prior articles.
But here is what I’m wondering:
What are the core strategies you’ve used to keep your knowledge graph clean and usable? Something close to our approach here, or something completely different?
Click the button below and tell me. I read every response.
Enjoyed the article? The most sincere compliment is to restack this for your readers.
Whenever you’re ready, here is how I can help you
If you want to go from zero to shipping production-grade AI agents, check out my**Agentic AI Engineering course**, built with Towards AI.
35 lessons. Three end-to-end portfolio projects. A certificate. And a Discord community with direct access to industry experts and me.
Built for software, data engineers or scientists transitioning into AI engineering.
Rated 5/5 by 300+ students. The first 7 lessons are free:
Not ready to commit?Start with ourfree Agentic AI Engineering Guide**, a 6-day email course on the mistakes that silently break AI agents in production.
- Iusztin, P. (n.d.). Understanding the Neo4j Graph Agent Memory System. Decoding AI Magazine.https://www.decodingai.com/p/understanding-neo4j-graph-agent-memory-system
- Iusztin, P. (n.d.). Ship a Knowledge Graph Ontology in 5 Minutes. Decoding AI Magazine.https://www.decodingai.com/p/ship-a-knowledge-graph-ontology-in-5-minutes
- POLE+O Data Model. (n.d.). Neo4j Labs.https://neo4j.com/labs/agent-memory/explanation/poleo-model/
- How Entity Extraction Works. (n.d.). Neo4j Labs.https://neo4j.com/labs/agent-memory/explanation/extraction-pipeline/
- Entity Resolution and Deduplication. (n.d.). Neo4j Labs.https://neo4j.com/labs/agent-memory/explanation/resolution-deduplication/
If not otherwise stated, all images are created by the author.
Similar Articles
Building Agentic GraphRAG Systems: From knowledge graphs and ontologies to a unified memory as an MCP server for your AI agent.
The author argues that GraphRAG is fundamentally a data modeling problem rather than just a retrieval algorithm, proposing a five-component architecture using ontologies, knowledge graphs, and an MCP server for unified agent memory.
@pauliusztin_: 2 months ago, I started building unified memory layers with knowledge graphs. Here’s the most common question I’ve been…
This thread discusses best practices for building unified memory layers with knowledge graphs, emphasizing the separation of entity resolution (naming) from deduplication (identity) to avoid graph corruption. It also highlights using orchestration tools like PrefectIO to manage expensive LLM extraction pipelines with checkpointing and caching.
I spent a year building agent memory on knowledge graphs. Here are the 5 mistakes that cost me months
The author shares five mistakes made while building a unified memory layer for AI agents using knowledge graphs and ontologies, emphasizing that agent memory is a data-modeling problem rather than a retrieval problem.
@_avichawla: Build human-like memory for your Agents (open-source)! Every agentic and RAG system struggles with real-time knowledge …
Graphiti is an open-source tool that builds human-like memory for AI agents using a continuously evolving, temporally-aware knowledge graph, achieving up to 18.5% higher accuracy and 90% lower latency compared to MemGPT.
Why Vector RAG fails for AI coding agents at scale (And how I used a Neo4j graph to fix it)
A new open-source tool called Writ uses a hybrid retrieval pipeline with BM25, ONNX vectors, and Neo4j graph traversals to provide context rules for AI coding agents, reducing token bloat by 726x and enforcing plan approval via bash hooks.