@LangChain: How do you support full-text search JSON filtering over agent traces that span up to hundreds of MBs, while keeping a m…
Summary
LangChain engineers detail how they built a custom inverted index for SmithDB to support full-text search and JSON filtering over large agent traces stored in object storage, achieving median latency of 400ms despite huge payload sizes.
View Cached Full Text
Cached at: 06/11/26, 09:42 PM
How do you support full-text search JSON filtering over agent traces that span up to hundreds of MBs, while keeping a median (P50) latency of 400ms?
Here’s an inside look at how we built a custom inverted index from scratch for SmithDB.
https://t.co/QwSu0JqRg5
Full Text Search in SmithDB: Designing an Inverted Index for Object Storage
Overview
SmithDB supports full-text search and JSON filtering over agent traces with a median (P50) latency of 400 ms, even though the underlying data consists of large, deeply nested JSON documents stored in object storage.
Full-text search is well-trodden ground. Lucene is two decades old;TantivyandQuickwithave already pushed search and indexing onto object storage. However, when building text search into SmithDB, we decided to approach the problem from first principles because indexing agent traces for search workloads presents a unique challenge.
SmithDB requires a different approach to search
Challenge 1: Unique data characteristics of agent traces
Every LangSmith event encodes the fieldsinputsandoutputsas the overwhelming majority of its total bytes. 1 MB+ payload sizes forinputsandoutputsare common, with some of these stretching to hundreds of megabytes uncompressed. These content columns dwarf the identity, timestamp, and other metadata columns by orders of magnitude.
Additionally, as mentioned in the originalSmithDB blogpost, the payloads associated with agent traces continue to increase in size over time. This is direct result of LLM context window sizes growing larger and agents running for longer time horizons, causing LLMs to accumulate more context.
These characteristics invert the usual economics of a search index. A traditional log engine indexes billions ofsmalldocuments, so the index is small relative to each document. We index billions ofenormousdocuments, where one document can produce more index data than many small log lines.Typicallythe source:index ratio for logs is about to 1:1.25. However for agent traces in LangSmith, we observed the average to be closer to 1:1.9. Three things follow:
- A content filter without an index is catastrophically slow.“Find runs whose tool output mentions a timeout” cannot scan every payload in the candidate range otherwise it would scan many gigabytes to return three rows.
- **Term frequencies follow a Zipfian distribution.**Natural-language and JSON payloads follow a power law: a handful of tokens (
"agents","import", "role", "type", ubiquitous keys) appear in nearly every document, while the long tail of terms appear once or twice. The index must stay compact and prunable across many orders of magnitude of term frequency, all inside one file. - **Multiple query modalities matter.**Users query bypath(“does this run have
inputs\.content\.messages?”), byvalue(“…where it mentionsAlex”), and byfree text(“…mentions a latency regression anywhere”).
An inverted index is what prevents a content query from performing a full payload scan, and it has to absorb heavy, skewed, semi-structured payloads.
Challenge 2: Object storage
SmithDB keeps all durable data in object storage so compute is relatively stateless and the system scales by adding nodes without having to manage local disks.
The cost of a query is roughly proportional to**(requests issued to object storage) × (bytes read per request)**. On object storage:
- Each object store request carries tens of milliseconds to hundreds of milliseconds of latency.
- Per-request throughput is modest, so fetching a large postings list or positions list before you know you need it can dominate the query.
Every aspect of SmithDB’s inverted index, from its storage layout to query execution is designed with these constraints in mind.
SmithDB search query shapes
Before going deeper into the storage layout for our inverted index, let’s go over the main query patterns the index has to answer. SmithDB’s query surface boils down to three predicate families, and they differ in what they match against and what pattern syntax they admit.
- The first ispath existence(
json\_key):*does this document contain key K?*For examplejson\_key\(inputs, "author\.name"\)asks which documents mentionauthor\.name. Path existence also supportsLIKEon the key path itself:json\_key\(inputs, "author\.%"\)orjson\_key\(inputs, "%\.user\_id"\)is a first-class query. Patterns can land anywhere in the path (prefix, suffix, infix). - The second iskeyed value(
json\_key\_search):does key K have a value matching V?json\_key\_search\(inputs, "author\.name", "Jane"\)is the canonical form. The query may be a single token or a multi-token phrase (json\_key\_search\(inputs, "title", "latency regression"\)), and the phrase variant adds adjacency:"latency regression"matches only documents where those words appear consecutively, not anywhere in the value. - The third isfull-text search(
search):does any indexed value match Q?search\(error, "timeout"\)searches a text column directly;search\(inputs, "latency regression"\)searches across every JSON value, regardless of path.
To summarize:
ShapeWhat it matchesjson_keykey path existsjson_key_searchpath + valuesearchtext column or any JSON value
Every later section refers back to this table: when we say “path-only query” we mean json_key, “keyed value” meansjson\_key\_search, and “full-text” meanssearch.
An overview of inverted indexes
An inverted index is the data structure powering every search library, fromLucenetoTantivy. It is like the index at the back of a textbook: look up a term once and jump straight to the pages that mention it instead of reading every page. SmithDB builds on this idea and specializes the storage layout for the large agent-trace payloads it stores in object storage.
Terms, postings, positions
The inverted index structure rests on three concepts:
- atermis the unit we index: a JSON path, a keyed value, or a text token
- apostingis thesortedset of document IDs that contain a term
- apositionis where in a document a term appears, which is what makes phrase search possible.
Take five traces indexed on their text:
doc 0: "langchain agents emit traces"
doc 1: "langsmith engine runs deep agents"
doc 2: "langchain deep agents workflow"
doc 3: "agents emit deep langsmith traces"
doc 4: "deep langsmith powers the engine"
The index keeps one entry per term, pointing at the documents that mention it:
term posting list positions
────────── ────────────── ─────────────────────────
agents [0, 1, 2, 3] 0:[1] 1:[4] 2:[2] 3:[0]
deep [1, 2, 3, 4] 1:[3] 2:[1] 3:[2] 4:[0]
emit [0, 3] 0:[2] 3:[1]
engine [1, 4] 1:[1] 4:[4]
langchain [0, 2] 0:[0] 2:[0]
langsmith [1, 3, 4] 1:[0] 3:[3] 4:[1]
powers [4] 4:[2]
runs [1] 1:[2]
the [4] 4:[3]
traces [0, 3] 0:[3] 3:[4]
workflow [2] 2:[3]
Each term is one dictionary entry: look up the value, read its posting list, and you know exactly which documents to fetch. A query likesearch\("deep agents"\)intersects the posting lists fordeep(\[1, 2, 3, 4\]) andagents(\[0, 1, 2, 3\]) to get\[1, 2, 3\]with no payload scan.
The positions column records, per document, the token offset(s) where the term appears, e.g.1:\[0\]means doc 1, position 0. That is what makes phrase search possible:search\("langsmith engine"\)matches doc 1 becauselangsmithis at offset 0 andengineat offset 1 (0 \+ 1 == 1), but not doc 4, wherepowersandthesit between them (langsmithat 1,engineat 4).
Why we leveraged Vortex and not Tantivy
Tantivyis an excellent search indexing library and the obvious reference point for Lucene-style search in Rust. We started by asking whether we could adopt it directly. The design we ended up with is heavily inspired by Tantivy, but a few constraints made it an awkward fit for our use-case directly:
- **Object storage, not local disk.**Tantivy is built around
mmap; every byte is microseconds away and random I/O is effectively free. We’re on object storage with ~100 ms round trips, where layout and coalescing decide query latency, not CPU. - **Embedded in a columnar engine.**SmithDB queries run throughApache DataFusionoverVortex. We wanted search to push down through the same scan pipeline as every other predicate, not run as a parallel query stack with its own segment model and IO assumptions.
- **Doc IDs aligned with Vortex rows.**Tantivy’s writer assigns its own segment-local doc IDs in insertion order and renumbers them on every merge. SmithDB needs the index to point directly at row positions in the corresponding Vortex data file (we use Vortex for our core event data files), so a doc ID is a row index — no translation table, no second identity to reconcile at query time, and merges that follow the data file’s row ordering need no remap. Additionally, our compaction remaps the row positions which also doesn’t work well with Tantivy’s index merge as we’ll detail in the second part of this blog post.
Our journey to develop SmithDB’s inverted index
Quick primer on Vortex
Vortexis an extensible and columnar file format SmithDB uses for object storage. Unlike fixed formats such as Parquet, Vortex allows pluggable encodings and custom file layouts which lets us tailor compression and I/O access patterns to our workload without forking the file format.
Every readprunesentire row groups using statistics,filterssurviving rows down to a mask, andprojectsonly the columns the query actually needs.
The unit ofI/O in a Vortexfile is a**segment:**a contiguous physical byte range. On object storage a round-trip costs roughly 100 ms, so the primary lever for query latency is minimizing the number of requests. Vortex’s I/O scheduler coalesces nearby segment reads into a single request, merging reads within a 1 MB gap into one, up to a 16 MB window, so sequential access patterns in the index map to very few object store GETs.
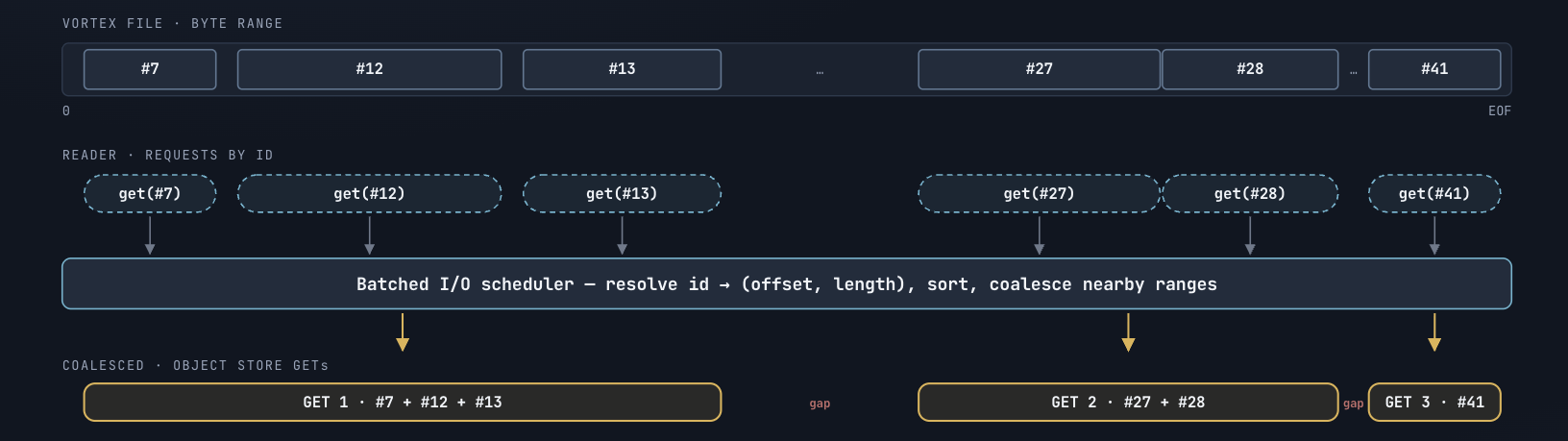
Our (unsuccessful) first attempt
The first version was a near-literal translation of the textbook inverted index. Two columns (term\_keyfor paths andterm\_valuefor tokens) lets one layout serve all three query shapes:path-existencereadterm\_key,keyed searchintersected postings across both columns, andfull-textintersected onterm\_valuealone. Postings were stored asList<u32\>cells, positions asList<List<u32\>\>.
We leaned on Vortex’s defaults: FSST encoding for the term columns, bitpacked encoding for postings and positions, and a zoned storage layout that allowed for pruning at query time. Positions (required for phrase search) alone were an order of magnitude larger than every other column, so we kept the index in a separate file from the core run data. This let us decouple index construction and merge from the core write path. Vortex’s APIs work on row indices and masks, so delegating index filtering to a sibling file composed naturally.
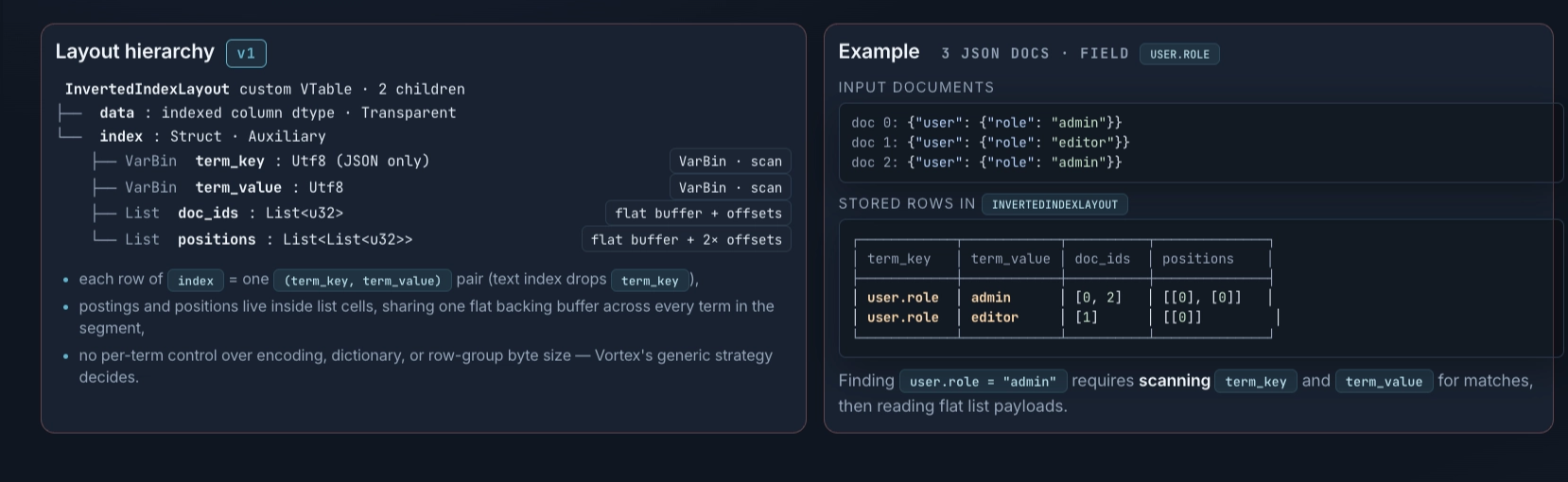
Three problems showed up at scale:
- **No per-term encoding control.**Vortex picked the encoding for the whole column, not per term, so a single common token (
agent,langchain) forces a larger bit width on every term in the entire chunk, leading to poor bitpacking. The rest of the column paid for it with worse cache behavior and larger reads, and we had no lever to apply more aggressive bitpacking selectively to high-frequency terms. - **Fixed-size row groups were blind to term skew.**We batched a fixed number of terms per row group, which meant a single high-frequency term could push one row group past 100 MB compressed while another sat at a few MB. At query time that turned into one outsized object-store GET; at merge time it turned into outsized in-memory decode.
- **Merge had to reshape positions.**Merging two segments meant decoding the full positions
List<List<u32\>\>, reshuffling inner lists into the new document order, and recomputing every outer offset. CPU time and allocations both spiked on compaction. For an index where 70%+ of bytes are positions, this was the dominant compaction cost.

Second attempt: V2 Inverted index storage layout
Our v2 layout addresses all three v1 problems by changing the unit of organization from “N terms per row group” to abyte-budgeted row group, and by owning the byte layout per column instead of directly relying on Vortex defaults. The rest of this section walks through the new unit of organization, what lives inside it, and the encoding choices that earned the byte budget.
Row groups, sized in bytes
Since a row group is the unit of pruning and I/O, we determine the row group sizes with fixed independentbytebudgets instead of a fixed row count.
- **32 MB of posting bytes:**bounds the worst-case object-store GET when a query reads postings for a row group.
- **64 MB of raw term-string bytes:**caps raw bytes per row group.
Sizing inbytes, not term count, is what fixes v1’s third problem. Term skew makes term count a poor proxy for IO size, as one high-frequency term in a v1 row group could push it past even 500 MB compressed. The byte budgets give us an upper bound on every row group for the amount of bytes fetched from object store or memory footprint while executing queries.
Per-row-group min/max/count via a zoned storage layout on the term column lets the query planner skip entire row groups before touching the FST. For path queries that target a specific prefix this is the single biggest saving: most row groups simply don’t contain anything in the predicate’s range.
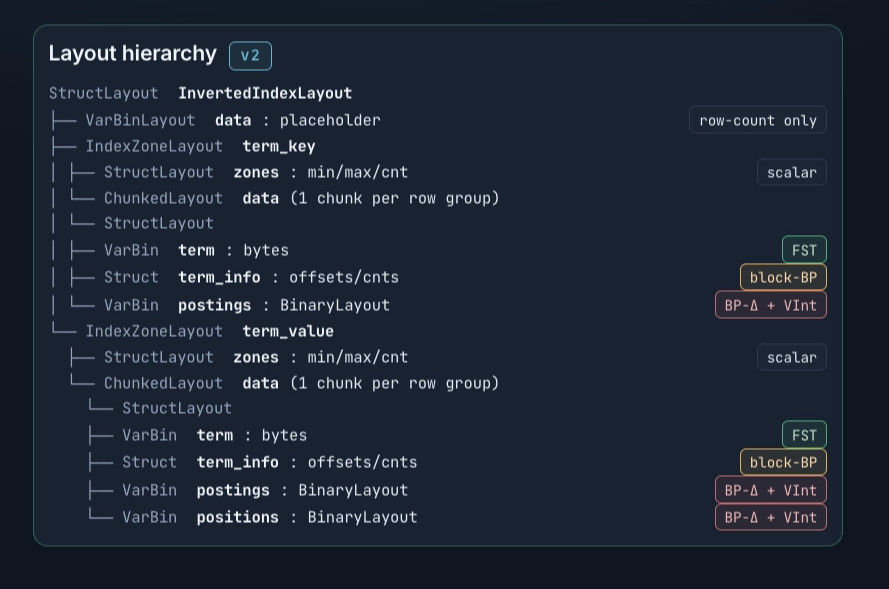
Inside one row group
Each row group carries four columns (three forterm\_key, which skips positions):
term— a binary layout whose bytes are anFST (finite state transducer**)**mapping each term to an ordinal (its row index inside this row group). Our usage of FSTs is inspired by Tantivy.term\_info— term metadata: doc count plus offsets intopostingsandpositions.postings— binary blob. Per-term lists are split into128-doc blocks of bitpacked deltaswith aVInttail for the leftover < 128 docs.positions— binary blob, same encoding. Only present onterm\_value; path existence is a document-level question, soterm\_keyskips this column entirely.
A lookup is one walk through the dictionary, one offset table read, and one byte-range fetch. The FST resolves the term to an ordinal. The ordinal indexes intoterm\_info, which gives an offset intopostingsand (for phrase queries) an offset intopositions. The query reads those byte ranges directly. No payload scan, no nested-list decode, and because each column is its own chunked layout, a non-phrase query fetches justterm+term\_info+postingsand never opens the positions column.
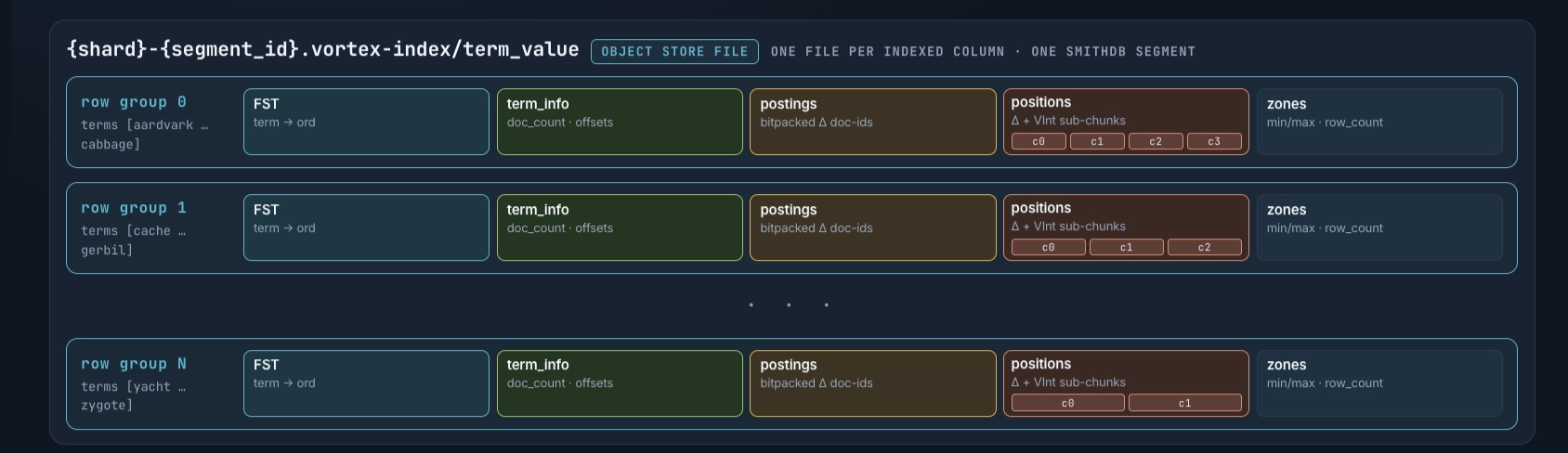
Encoding choices
**We use FST for the term dictionary.**We compared FST against the obvious alternatives (Vortex’s default FSST string encoding, prefix-sharedkeep\_add, and plain zstd) on a representative row group with 2.79M term occurrences. The shape of the win depends on cardinality:
ColumnUnique termsRawFSSTzstdFSTterm_key (JSON paths)54688.8 MiB34.7 MiB16.3 KiB3.8 KiBterm_value (token values)1.41M55.1 MiB65.7 MiB21.7 MiB32.7 MiBterm_value:term_key combined2.79M146.6 MiB81.7 MiB31.3 MiB37.6 MiB
Onterm\_key, where a few hundred JSON paths repeat across millions of rows, the FST collapses the entire dictionary to3.8 KiB:four orders of magnitude smaller than the raw bytes and ~4× smaller than zstd. On the high-cardinalityterm\_valuecolumn, FST is ~1.5× larger than zstd but still beats FSST. The crucial point is thatzstd is opaque: every lookup requires decompressing the block. The FST is theindex itself— exact lookup, prefix and range scans, and automaton walks (LIKE, fuzzy, regex) all run directly against the compressed bytes withO\(\|term\|\)cost and no hashing.
We also fold the keyed-search and full-text query shapes into a single FST per row group by storingterm\_valueentries as\{token\}\\0\{flattened\_path\}. Keyed search becomes exact FST lookup; full-text search becomes a prefix scan ontoken\\0, walking every path the token appears under.
**We use block-bitpacked deltas per term.**Postings and positions both use the same Tantivy/Lucene-style two-tier encoding. The shape of the encoding is what makes per-term control possible and what makes merge cheap.
Each per-term list is split into fixed128-element blocksplus a tail of< 128leftovers:

Within a block we store deltas between successive doc IDs, not the IDs themselves, and bitpack the block to the minimum width that fits its max delta. A dense, regular run of IDs packs down to just a few bits each. The trailing partial block (by definition rare for high-frequency terms, and the entire posting list for low-frequency ones) falls back toVInt, ~1 byte per small delta, degrading gracefully on the long tail.
Two properties fall out of it that the v1List<u32\>encoding didn’t have:
- **Per-term encoding, not per-column.**Each term picks its own bit widths block-by-block: a frequent term like
agentpacks at 3–4 bits per doc, a rare term never leaves itsVInttail. v1 forced one width across the whole column, so frequent terms inflated everyone’s bytes. - **Opaque to Vortex.**Vortex sees the encoded bytes as a single binary blob; it never decodes them into Arrow on the read path. That’s what lets a query fetch just the byte range it needs, decode blocks on demand, and skip-decode past everything the skip list rules out.
Where we diverge from Tantivy with FST usage
Tantivy also leverages FSTs, but builds one FST per segment with sharded partitioning. We build one FST per row group. A row-group-sized FST is small enough that the writer streams through it without ever holding a segment-wide FST in memory, and zone-level pruning skips most row groups before any FST work happens at query time. The trade-off is that a single lookup may touch multiple FSTs per file, but pruning makes that cost rare in practice; the surviving FSTs are small enough that the walks are cheap.
What’s next
In part 2, we’ll explore how we implemented inverted index construction and merging, as well as how we leverage the index in our read path.
//
We’re building SmithDB to solve the systems problems that come with agent observability. If that kind of infrastructure work sounds interesting,we’re hiring.
Similar Articles
@LangChain: Just announced at Interrupt! SmithDB. Agent traces have outgrown the databases built to hold them. That’s why we built …
LangChain announces SmithDB, a purpose-built distributed database for agent observability that powers LangSmith, offering improved performance and flexibility for complex agent trace data.
We built SmithDB, the data layer for agent observability
LangChain announces SmithDB, a purpose-built distributed database for agent observability that powers LangSmith, offering up to 12x performance improvements and support for complex agent trace queries.
@LangChain: .@AdamRLucek on how we use traces to build evals for production agents.
Adam Łucek discusses how LangChain uses trace data to build evaluations for production agents.
@LangChain: Spend less time on triaging Ship fixes faster Catch regressions earlier Introducing LangSmith Engine: an agent that wor…
LangChain launches LangSmith Engine in public beta, an autonomous agent that monitors production traces, clusters failures, diagnoses root causes, and proposes fixes and eval coverage to streamline agent development.
@LangChain: Tracking your agents shouldn’t be a workout. LangSmith Observability helps you understand how your agents are performin…
LangSmith Observability provides real-time monitoring for AI agents to help identify performance issues quickly.