@Xx15573208: 看了很多 Transformer 的文章,能听懂原理,但真正坐下来写代码,完全无从下手。 LLMs-from-scratch 专门解决这个问题:配套《Build a Large Language Model》一书,带你用 PyTorch …
摘要
LLMs-from-scratch 是一个 GitHub 仓库,配套《Build a Large Language Model》一书,提供从零用 PyTorch 实现 GPT 的完整代码,涵盖预训练、微调、RLHF 等全流程,已获 93K+ stars,适合想深入理解大模型原理的开发者。
查看缓存全文
缓存时间: 2026/05/12 16:56
看了很多 Transformer 的文章,能听懂原理,但真正坐下来写代码,完全无从下手。 LLMs-from-scratch 专门解决这个问题:配套《Build a Large Language Model》一书,带你用 PyTorch 一行行手写一个完整的 GPT。93K+ stars,是目前 GitHub 上最受关注的 LLM 学习项目之一。 GitHub:https://github.com/rasbt/LLMs-from-scratch… 7 章递进式内容: 从注意力机制开始,从头搭出完整 GPT 架构 预训练、监督微调、RLHF 全流程代码都有 BPE 分词器、KV 缓存、MoE、DPO 等进阶技术配套实现 已包含 Llama 3.2、Qwen3、Gemma 现代架构的实现 代码支持 CPU 和 GPU,普通笔记本可跑。配套 17 小时视频课程和 170 页练习题,适合想从代码层真正理解大模型、不只是调 API 的开发者。 Github:https://github.com/rasbt/LLMs-from-scratch… 7 章递进式内容: 从注意力机制到完整 GPT 实现 监督微调、RLHF、偏好优化(DPO) BPE 分词器、KV 缓存、MoE 等进阶附录 已实现 Llama 3.2、Qwen3、Gemma 现代架构 代码支持 CPU 和 GPU,普通笔记本可跑。配套 17 小时视频课程和 170 页练习题 PDF,适合想从原理层真正理解大模型的开发者。
rasbt/LLMs-from-scratch
Source: https://github.com/rasbt/LLMs-from-scratch
Build a Large Language Model (From Scratch)
This repository contains the code for developing, pretraining, and finetuning a GPT-like LLM and is the official code repository for the book Build a Large Language Model (From Scratch).

In Build a Large Language Model (From Scratch), you’ll learn and understand how large language models (LLMs) work from the inside out by coding them from the ground up, step by step. In this book, I’ll guide you through creating your own LLM, explaining each stage with clear text, diagrams, and examples.
The method described in this book for training and developing your own small-but-functional model for educational purposes mirrors the approach used in creating large-scale foundational models such as those behind ChatGPT. In addition, this book includes code for loading the weights of larger pretrained models for finetuning.
- Link to the official source code repository
- Link to the book at Manning (the publisher’s website)
- Link to the book page on Amazon.com
- ISBN 9781633437166

To download a copy of this repository, click on the Download ZIP button or execute the following command in your terminal:
git clone --depth 1 https://github.com/rasbt/LLMs-from-scratch.git
(If you downloaded the code bundle from the Manning website, please consider visiting the official code repository on GitHub at https://github.com/rasbt/LLMs-from-scratch for the latest updates.)
Table of Contents
Please note that this README.md file is a Markdown (.md) file. If you have downloaded this code bundle from the Manning website and are viewing it on your local computer, I recommend using a Markdown editor or previewer for proper viewing. If you haven’t installed a Markdown editor yet, Ghostwriter is a good free option.
You can alternatively view this and other files on GitHub at https://github.com/rasbt/LLMs-from-scratch in your browser, which renders Markdown automatically.
Tip: If you’re seeking guidance on installing Python and Python packages and setting up your code environment, I suggest reading the README.md file located in the setup directory.
![]()
![]()
![]()
| Chapter Title | Main Code (for Quick Access) | All Code + Supplementary |
|---|---|---|
| Setup recommendations How to best read this book | - | - |
| Ch 1: Understanding Large Language Models | No code | - |
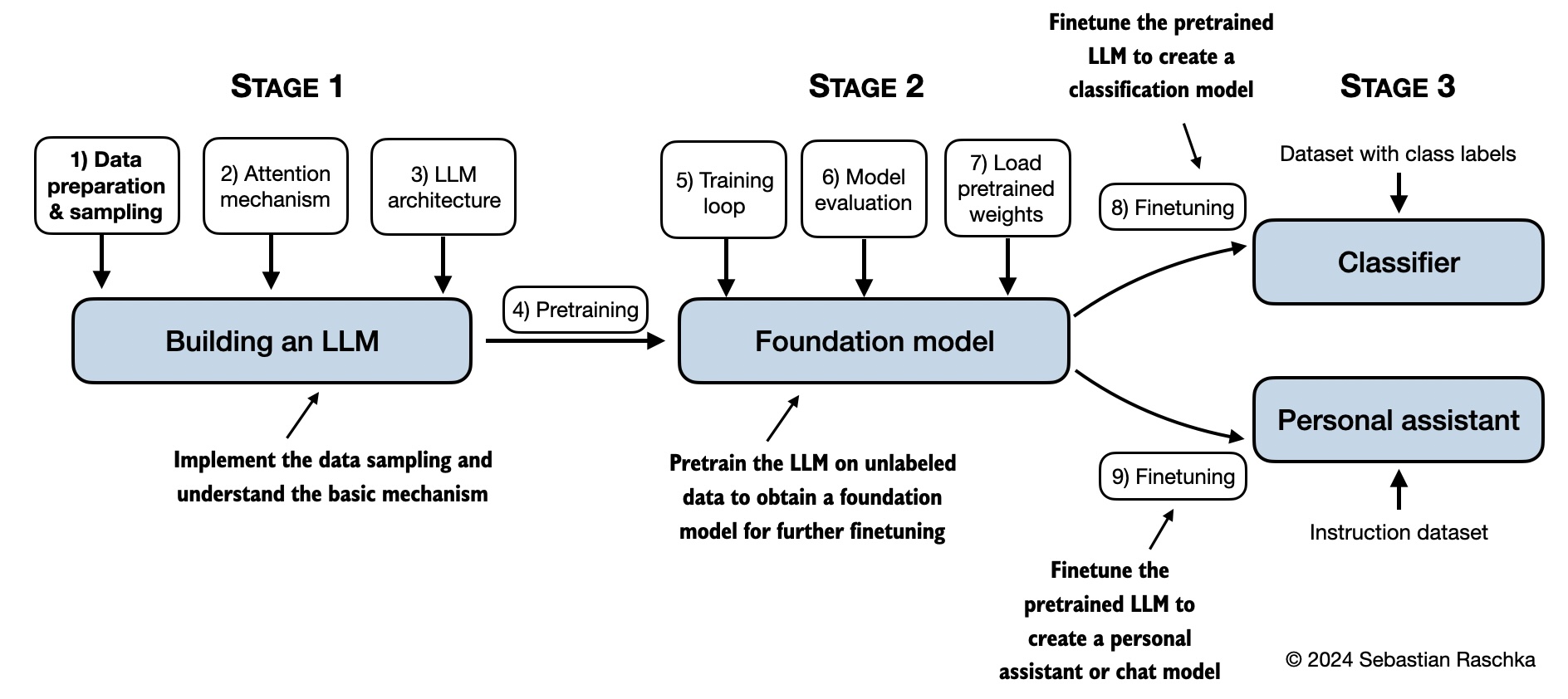
| Ch 2: Working with Text Data | - ch02.ipynb - dataloader.ipynb (summary) - exercise-solutions.ipynb | ./ch02 |
| Ch 3: Coding Attention Mechanisms | - ch03.ipynb - multihead-attention.ipynb (summary) - exercise-solutions.ipynb | ./ch03 |
| Ch 4: Implementing a GPT Model from Scratch | - ch04.ipynb - gpt.py (summary) - exercise-solutions.ipynb | ./ch04 |
| Ch 5: Pretraining on Unlabeled Data | - ch05.ipynb - gpt_train.py (summary) - gpt_generate.py (summary) - exercise-solutions.ipynb | ./ch05 |
| Ch 6: Finetuning for Text Classification | - ch06.ipynb - gpt_class_finetune.py - exercise-solutions.ipynb | ./ch06 |
| Ch 7: Finetuning to Follow Instructions | - ch07.ipynb - gpt_instruction_finetuning.py (summary) - ollama_evaluate.py (summary) - exercise-solutions.ipynb | ./ch07 |
| Appendix A: Introduction to PyTorch | - code-part1.ipynb - code-part2.ipynb - DDP-script.py - exercise-solutions.ipynb | ./appendix-A |
| Appendix B: References and Further Reading | No code | ./appendix-B |
| Appendix C: Exercise Solutions | - list of exercise solutions | ./appendix-C |
| Appendix D: Adding Bells and Whistles to the Training Loop | - appendix-D.ipynb | ./appendix-D |
| Appendix E: Parameter-efficient Finetuning with LoRA | - appendix-E.ipynb | ./appendix-E |
The mental model below summarizes the contents covered in this book.
Prerequisites
The most important prerequisite is a strong foundation in Python programming. With this knowledge, you will be well prepared to explore the fascinating world of LLMs and understand the concepts and code examples presented in this book.
If you have some experience with deep neural networks, you may find certain concepts more familiar, as LLMs are built upon these architectures.
This book uses PyTorch to implement the code from scratch without using any external LLM libraries. While proficiency in PyTorch is not a prerequisite, familiarity with PyTorch basics is certainly useful. If you are new to PyTorch, Appendix A provides a concise introduction to PyTorch. Alternatively, you may find my book, PyTorch in One Hour: From Tensors to Training Neural Networks on Multiple GPUs, helpful for learning about the essentials.
Hardware Requirements
The code in the main chapters of this book is designed to run on conventional laptops within a reasonable timeframe and does not require specialized hardware. This approach ensures that a wide audience can engage with the material. Additionally, the code automatically utilizes GPUs if they are available. (Please see the setup doc for additional recommendations.)
Video Course
A 17-hour and 15-minute companion video course where I code through each chapter of the book. The course is organized into chapters and sections that mirror the book’s structure so that it can be used as a standalone alternative to the book or complementary code-along resource.

Companion Book / Sequel
Build A Reasoning Model (From Scratch), while a standalone book, can be considered as a sequel to Build A Large Language Model (From Scratch).
It starts with a pretrained model and implements different reasoning approaches, including inference-time scaling, reinforcement learning, and distillation, to improve the model’s reasoning capabilities.
Similar to Build A Large Language Model (From Scratch), Build A Reasoning Model (From Scratch) takes a hands-on approach implementing these methods from scratch.

- Amazon link (TBD)
- Manning link
- GitHub repository
Exercises
Each chapter of the book includes several exercises. The solutions are summarized in Appendix C, and the corresponding code notebooks are available in the main chapter folders of this repository (for example, ./ch02/01_main-chapter-code/exercise-solutions.ipynb.
In addition to the code exercises, you can download a free 170-page PDF titled Test Yourself On Build a Large Language Model (From Scratch) from the Manning website. It contains approximately 30 quiz questions and solutions per chapter to help you test your understanding.

Bonus Material
Several folders contain optional materials as a bonus for interested readers:
-
Setup
-
Chapter 2: Working With Text Data
-
Chapter 3: Coding Attention Mechanisms
-
Chapter 4: Implementing a GPT Model From Scratch
-
Chapter 5: Pretraining on Unlabeled Data
- Alternative Weight Loading Methods
- Pretraining GPT on the Project Gutenberg Dataset
- Adding Bells and Whistles to the Training Loop
- Optimizing Hyperparameters for Pretraining
- Building a User Interface to Interact With the Pretrained LLM
- Converting GPT to Llama
- Memory-efficient Model Weight Loading
- Extending the Tiktoken BPE Tokenizer with New Tokens
- PyTorch Performance Tips for Faster LLM Training
- LLM Architectures
- Chapter 5 with other LLMs as Drop-In Replacement (e.g., Llama 3, Qwen 3)
-
Chapter 6: Finetuning for classification
-
Chapter 7: Finetuning to follow instructions
- Dataset Utilities for Finding Near Duplicates and Creating Passive Voice Entries
- Evaluating Instruction Responses Using the OpenAI API and Ollama
- Generating a Dataset for Instruction Finetuning
- Improving a Dataset for Instruction Finetuning
- Generating a Preference Dataset With Llama 3.1 70B and Ollama
- Direct Preference Optimization (DPO) for LLM Alignment
- Building a User Interface to Interact With the Instruction-Finetuned GPT Model
More bonus material from the Reasoning From Scratch repository:
-
Qwen3 (From Scratch) Basics
-
Evaluation
-
Inference Scaling
-
Reinforcement Learning (RL)
Questions, Feedback, and Contributing to This Repository
I welcome all sorts of feedback, best shared via the Manning Forum or GitHub Discussions. Likewise, if you have any questions or just want to bounce ideas off others, please don’t hesitate to post these in the forum as well.
Please note that since this repository contains the code corresponding to a print book, I currently cannot accept contributions that would extend the contents of the main chapter code, as it would introduce deviations from the physical book. Keeping it consistent helps ensure a smooth experience for everyone.
Citation
If you find this book or code useful for your research, please consider citing it.
Chicago-style citation:
Raschka, Sebastian. Build A Large Language Model (From Scratch). Manning, 2024. ISBN: 978-1633437166.
BibTeX entry:
@book{build-llms-from-scratch-book,
author = {Sebastian Raschka},
title = {Build A Large Language Model (From Scratch)},
publisher = {Manning},
year = {2024},
isbn = {978-1633437166},
url = {https://www.manning.com/books/build-a-large-language-model-from-scratch},
github = {https://github.com/rasbt/LLMs-from-scratch}
}
相似文章
@NFTCPS: 天天喊着搞AI,结果你连Transformer是个啥都说不清? 有个仓库够狠,从零手搓一个GPT,不调任何高级库。Attention、多头、前馈、Embedding、残差、Layer Norm,怎么拼起来的全摊给你看。而且不止模型,整条链…
一个GitHub开源项目,从零实现完整的GPT训练流程,包含数据预处理、预训练、SFT和RLHF后训练,全部基于原生PyTorch,适合想深入理解Transformer原理的开发者。
@GitHub_Daily: 想搞懂大语言模型底层原理,大部分资料只介绍理论知识,或者只给源码,看完还是一头雾水。 偶然看到 EveryonesLLM 这个开源教程,手把手带我们在 Google Colab 上从零搭建一个完整的大语言模型,全程动手写代码。 整套教程分…
EveryonesLLM 是一个开源教程,提供29个章节的Colab笔记本,手把手教用户从零在Google Colab上搭建完整的大语言模型,包括预训练和指令微调,并支持中文。
rasbt/LLMs-from-scratch
该仓库提供开源代码,用于从零开始构建、预训练和微调一个类似GPT的大型语言模型,是Sebastian Raschka同名书籍的官方代码配套。
Hi Reddit, I posted my Build Your Own LLM workshop to Youtube (GPT2 & Qwen3.6 style)
Justin Angel 发布了一个完整的 YouTube 工作坊,教你从零构建自己的大语言模型(基于 GPT-2 和 Qwen3.6 风格),涵盖 Transformer 架构、训练流程,并提供 Excel 手动操作和 Python/PyTorch 代码实践,无需数学或 ML 先修知识。
@akshay_pachaar: 从头开始训练你自己的LLM。这个仓库从头构建了一个GPT风格的Transformer,完全不用高级库…
一个从零开始构建GPT风格Transformer的仓库,不使用高级库,涵盖了从数据预处理到生成的整个过程,并包括SFT和RLHF的指南。