@robertnishihara: Some intuition about PD disaggregation from the blog - PD doesn't speed up prefill and can actually hurt TTFT - PD's re…
Summary
This blog post from Anyscale explains the intuition behind Prefill-Decode (PD) disaggregation for LLM serving, showing how separating prefill and decode phases onto dedicated GPUs can achieve up to 2.7x better goodput and 67% cost savings when using Ray and vLLM on AMD MI325X, while also discussing when PD disaggregation does not help.
View Cached Full Text
Cached at: 06/17/26, 03:44 AM
Some intuition about PD disaggregation from the blog
- PD doesn’t speed up prefill and can actually hurt TTFT
- PD’s real benefit is flat, stable TPOT under load
- TPOT savings compound over output sequence length
The optimal P:D ratio is dependent in particular on input lengths, output lengths, and cache hits. Meaningful optimizations are possible, but tuning can be sensitive.
Benchmarks performed with @raydistributed + @vllm_project on AMD MI325X.
Achieving Up to 67% Cost Savings with Prefill-Decode Disaggregation Using Ray + vLLM on AMD MI325X | Anyscale
Source: https://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings In LLM serving, the optimization objective is deceptively simple: given a set of latency SLA targets – time to first token (TTFT), time per output token (TPOT), end-to-end latency (E2E) – maximize the queries per second (QPS) you can sustain, also known as the “goodput”.
One of the most powerful levers for breaking through the goodput ceiling isPrefill-Decode (PD) disaggregation. In this post, we cover how we used Ray Serve LLM to orchestrate PD disaggregation inference workloads on AMD, achieving up to2.7x better goodput.
The key advantage for using PD disaggregation is that instead of running both phases on the same GPUs – where they compete for compute, memory bandwidth, and scheduling budget – PD separates them onto dedicated hardware. Prefill GPUs handle prompt processing. Decode GPUs handle token generation. By eliminating mutual interference, each phase runs closer to its theoretical throughput, and the system as a whole serves more requests under the same SLA constraints.
However, this is no free lunch – PD adds operational complexity: KV cache must be transferred across nodes and the prefill-to-decode ratio must be tuned per workload. We show results where under the same GPU budget and SLA, Prefill-Decode disaggregation on Ray + vLLM can serve1.3x to 2.3x more QPSthan aggregated serving – depending on the workload (up to67% compute cost reduction) and also results where it does not help – so you can make the right decision for your workload.
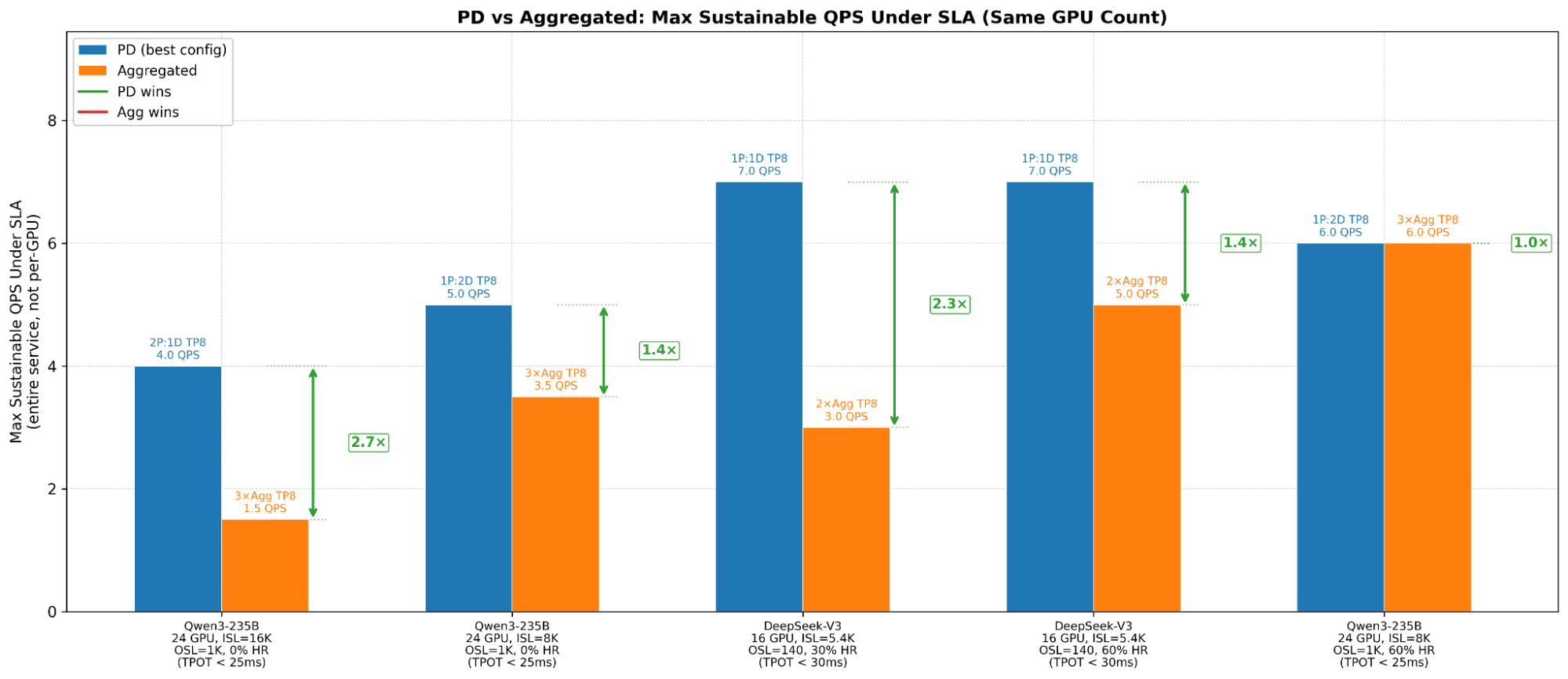 PD vs Aggregated max sustainable QPS under SLA across 5 workload scenarios (Model, ISL/OSL and hit-rate variations). Validated on Qwen3-235B and DeepSeek-V3 on AMD MI325X.
PD vs Aggregated max sustainable QPS under SLA across 5 workload scenarios (Model, ISL/OSL and hit-rate variations). Validated on Qwen3-235B and DeepSeek-V3 on AMD MI325X.
PD vs Aggregated - Max Sustainable QPS Under SLA (Same GPU Count) We tested two large MoE models across a range of workloads – varying input/output lengths, KV cache hit rates, and P:D ratios – to find where PD disaggregation saves cost and where it doesn’t. This post walks through the core intuition behind why PD disaggregation helps, the AMD stack needed to enable PD disaggregation (RIXL for KV transfer), and how to set it up with Ray Serve. For a managed solution you can useAnyscalebringing similar cost savings to your workloads.
LinkCore Intuition – Why PD Works (and When It Doesn’t)https://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings#core-intuition-%E2%80%93-why-pd-works-(and-when-it-doesn’t)
This section covers the four key insights you need to reason about PD disaggregation for any workload. Each insight includes data from our experiments, plus clear guidance on when PD disaggregation loses. These results are agnostic to hardware setup and should be taken as general guidelines and conclusions about prefill decode disaggregation.
LinkInsight 1: PD does NOT make prefill faster – it can actually hurt TTFThttps://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings#insight-1:-pd-does-not-make-prefill-faster-%E2%80%93-it-can-actually-hurt-ttft
The most common misconception about PD is that it speeds up everything. It does not. On the metric that matters most for interactive responsiveness – time to first token – PD is consistently slower than aggregated serving on the same GPU footprint.
**Why aggregated TTFT is already good.**In vLLM’s scheduler, there is no separate “prefill phase” or “decode phase.” The scheduler runs all currently-active requests – both prefill and decode – before admitting new requests from the waiting queue. Chunked prefill is enabled by default for all decoder-only models, i.e. long prompts are split into chunks sized bymax\_num\_batched\_tokens(defaults to 8192). Each chunk runs as one scheduler iteration. Typically, decode steps consume trivially little budget per iteration. For example, a batch of 128 concurrent decode requests uses at most 128 tokens out of the 8192-token budget, leaving the vast majority of each iteration available for prefill tokens. In this case, when a new request gets added to the batch, the 8064 unused token budget gets allocated to the prefill of the new request. This implies inflation on the TPOT of that iteration but not much inflation on the TTFT. TTFT is therefore dominated by the raw compute time of the prefill forward pass (attention + MoE routing), not by contention with decode.
 In aggregated serving, decode tokens consume only ~1.6% of the scheduler’s token budget per iteration — TTFT is dominated by prefill compute, not decode contention.
In aggregated serving, decode tokens consume only ~1.6% of the scheduler’s token budget per iteration — TTFT is dominated by prefill compute, not decode contention.
Aggregated Serving - vLLM Scheduler Timeline **What PD changes.**PD adds a KV cache transfer step after prefill completes. The prefill node sends KV data over the network (RDMA/RoCE) to the decode node. This transfer has inherent overhead that depends on model architecture, KV cache size, and network conditions. Under high load and kv-cache pressure, prefill nodes can also queue up, adding queuing delay on top of transfer overhead.
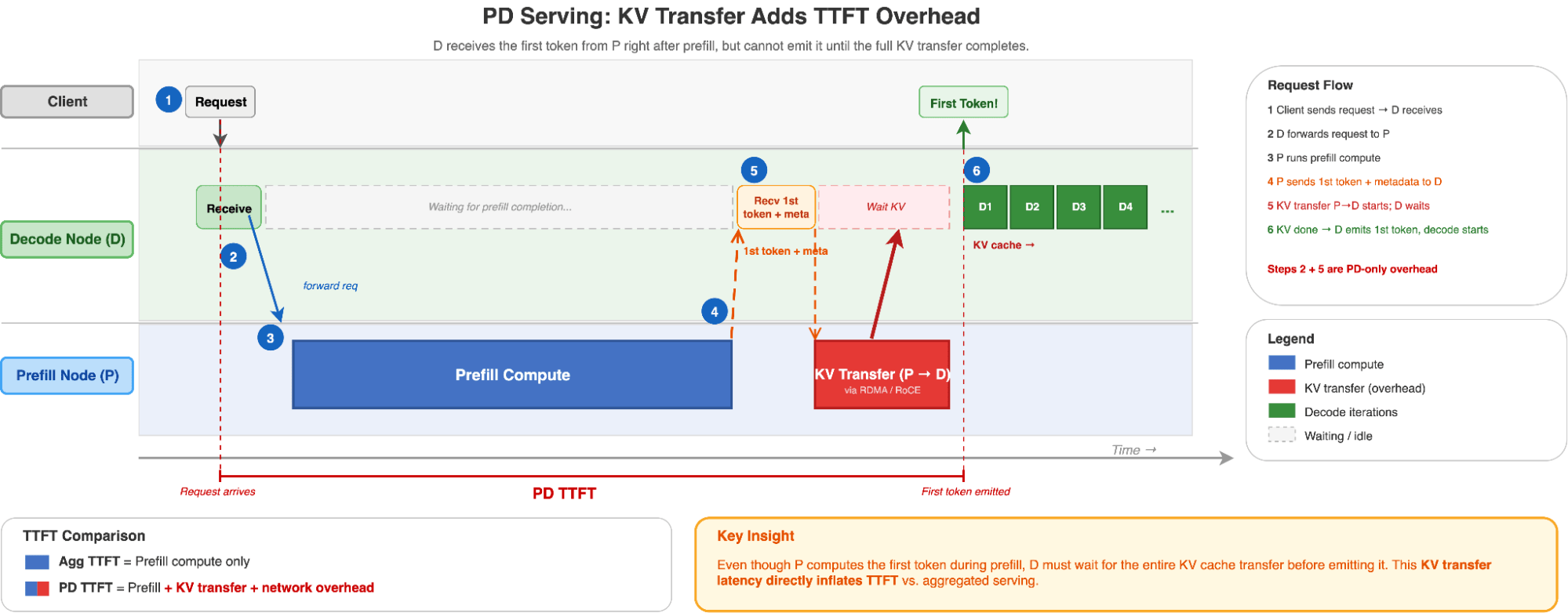 In PD serving, the KV cache transfer step between prefill and decode nodes adds overhead that inflates TTFT.
In PD serving, the KV cache transfer step between prefill and decode nodes adds overhead that inflates TTFT.
PD Serving - KV Transfer Adds TTFT Overhead **The net effect.**On the same GPU footprint, aggregated consistently achieves equal or lower TTFT than PD.
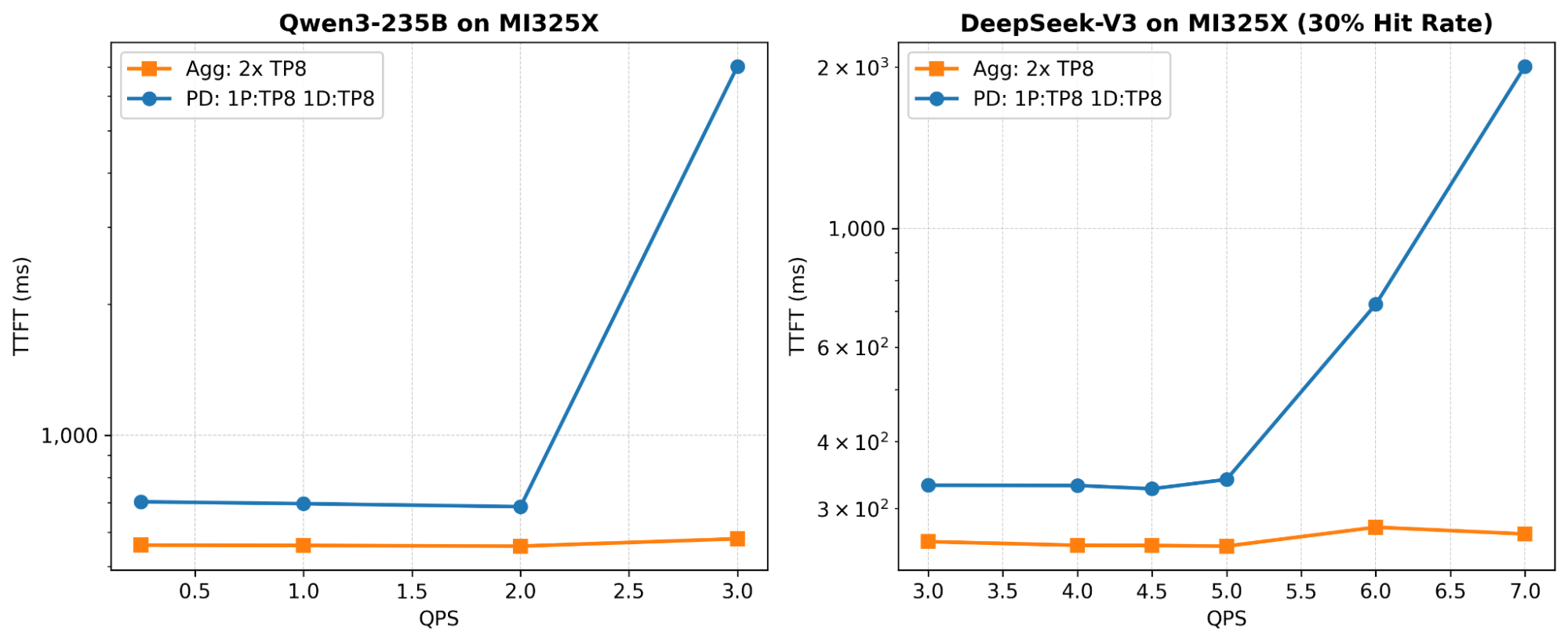 Figure 3: TTFT vs QPS — Agg TTFT stays flat while PD TTFT rises under load.
Figure 3: TTFT vs QPS — Agg TTFT stays flat while PD TTFT rises under load.
Qwen3-235B on MI325X & DeepSeek-V3 on MI325X (30- Hit Rate) If your SLA is measured purely on time-to-first-token (e.g., interactive search, auto-complete), aggregated will consistently beat PD. As Figure 3 shows, PD’s TTFT baseline on DeepSeek-V3 is ~330ms (due to KV transfer overhead), while Agg stays at ~260ms across all QPS levels:
- Under aTTFT < 300msSLA, PDcannot serve any traffic(baseline TTFT exceeds the target), while Agg sustains7.0+ QPS.
- Under aTTFT < 500msSLA, Agg sustains7.0+ QPSvs PD’s5.0 QPS– Agg wins by at least 1.4x.
Agg’s advantage here is structural: no KV transfer step, and prefill load is naturally distributed across replicas. If you needbothfast TTFT and fast TPOT, consider accepting a slightly relaxed TTFT target – even a small relaxation can unlock major TPOT and E2E improvements through PD.
**Bottom line:**If your SLA is strictly TTFT-limited, aggregated is the simpler and better choice.
LinkInsight 2: PD’s real win is flat, stable TPOT under loadhttps://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings#insight-2:-pd’s-real-win-is-flat,-stable-tpot-under-load
This is the core mechanism behind PD’s value. In aggregated serving, prefill and decode share the same GPU. Each scheduler iteration that includes prefill tokens is compute-heavier than a pure-decode iteration. As QPS rises, more prefill work stacks up, and decode tokens wait longer. TPOT degrades linearly (or worse) with increasing QPS, because every new prefill request steals compute from all in-flight decode steps.
PD eliminates this entirely. Decode runs on dedicated GPUs that never see a prefill token. TPOT stays nearly flat regardless of how much prefill work is happening on other nodes.
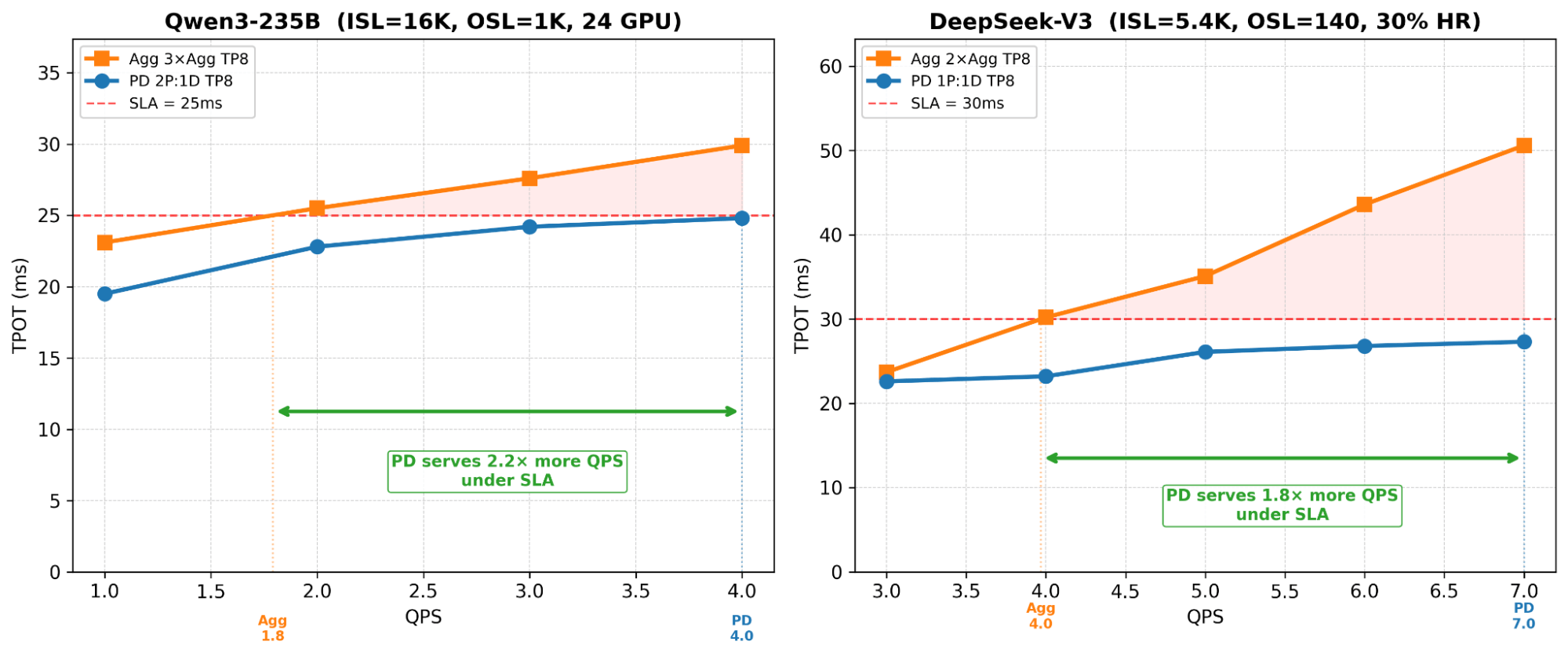 Figure 4: TPOT vs QPS – Agg TPOT rises steeply while PD stays flat. Under the target SLA, PD sustains significantly more QPS than Agg on both models.
Figure 4: TPOT vs QPS – Agg TPOT rises steeply while PD stays flat. Under the target SLA, PD sustains significantly more QPS than Agg on both models.
Qwen3-235B and DeepSeek-V3
LinkInsight 3: TPOT savings compound over output sequence lengthhttps://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings#insight-3:-tpot-savings-compound-over-output-sequence-length
PD’s per-token TPOT advantage looks modest in isolation (5-10ms). But it multiplies across every output token:
Total savings = TPOT delta × output_length.
This compounding is why PD wins on E2E latency despite losing on TTFT.
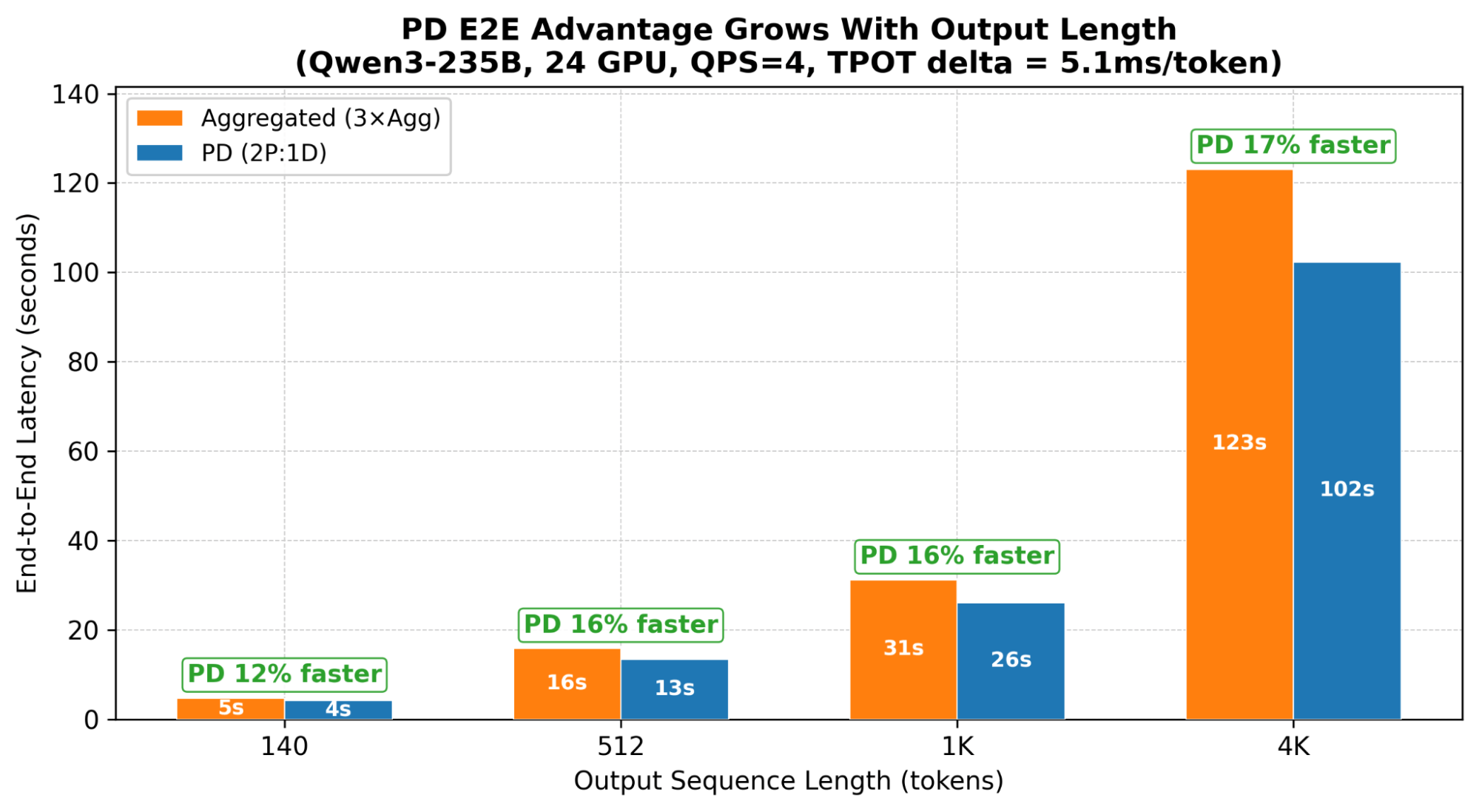 A 5.1ms/token TPOT advantage compounds: PD’s E2E win grows from 12% at OSL=140 to 17% at OSL=4K (Qwen3-235B, 24 GPU, QPS=4).
A 5.1ms/token TPOT advantage compounds: PD’s E2E win grows from 12% at OSL=140 to 17% at OSL=4K (Qwen3-235B, 24 GPU, QPS=4).
PD E2E Advantage Grows With Output Length **When PD loses: short output.**For short-output workloads (classification, extraction, short QA), the savings don’t accumulate enough to justify the complexity. In these cases you should use aggregated.
LinkInsight 4: The optimal P:D ratio depends on your workloadhttps://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings#insight-4:-the-optimal-p:d-ratio-depends-on-your-workload
This is the most practical insight for practitioners. The P:D ratio determines how GPU resources are split between prefill and decode. Getting it wrong can make PDworsethan aggregated.
Key findings across workloads:
Workload
Cache Hit Rate
Bottleneck
Optimal Ratio
Long input, short output (ISL=16K, OSL=1K)
0%
Prefill throughput
2P:1D
Long input, long output (ISL=16K, OSL=4K)
0%
Decode throughput
1P:3D
Multi-turn with high cache reuse
80%
Decode throughput
1P:2D
Multi-turn with moderate cache reuse
30–60%
Mixed
1P:1Dto1P:2D
**Rule of thumb:**The marginal GPU should go to wherever the bottleneck is. High cache hit rates make prefill cheap – allocate more to decode. Low cache hit rates with long inputs – allocate more to prefill.
The most common PD pitfall: deploying with a ratio that does not match the workload. This can make PD strictly worse than aggregated on every metric.
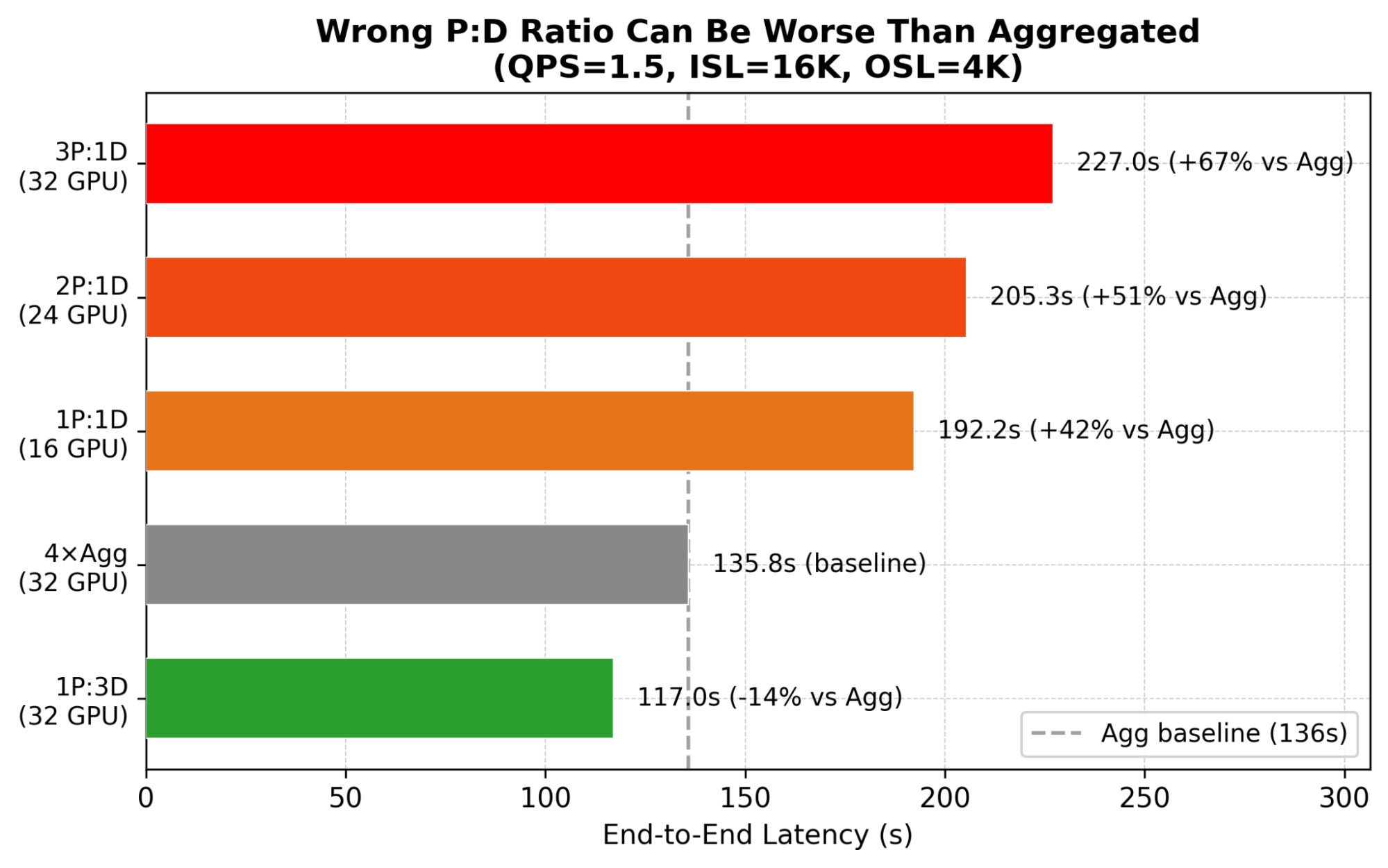 Wrong P:D ratio can be dramatically worse than aggregated. Always benchmark your specific workload. Start with 1:1, then adjust based on whether TTFT or TPOT hits the SLA first.
Wrong P:D ratio can be dramatically worse than aggregated. Always benchmark your specific workload. Start with 1:1, then adjust based on whether TTFT or TPOT hits the SLA first.
Wrong P:D Ratio Can Be Worse Than Aggregated
LinkWhat’s Special About AMD – RIXL and the KV Transfer Stackhttps://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings#what’s-special-about-amd-%E2%80%93-rixl-and-the-kv-transfer-stack
PD disaggregation requires high-bandwidth KV cache transfer between prefill and decode nodes. On NVIDIA hardware, this is handled byNIXL(NVIDIA Interconnect eXchange Library) over NVLink, InfiniBand, or EFA. On AMD, we useRIXL(ROCm Interconnect eXchange Library) – a plug-and-play replacement for NIXL that uses UCX transport over RDMA/RoCE InfiniBand.
The key point is that RIXL exposes the sameNixlConnectorinterface in vLLM. Zero code changes are needed in the serving layer. If your vLLM config sayskv\_connector: NixlConnector, it works on both NVIDIA (via NIXL) and AMD (via RIXL).
LinkContainer and Software Stackhttps://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings#container-and-software-stack
Our container image is built fromDockerfile\.v0\.18\.devwith the following components:
Component
Version / Source
Base image
anyscale/ray:nightly\-py312\-cu128(orrayproject/ray:nightly\-py312\-cu128for OSS)
ROCm
7.0 (rocm/dev\-ubuntu\-22\.04:7\.0\-complete for buildstages)
vLLM
0.18.0 viawheels\.vllm\.ai/rocm/0\.18\.0/rocm700prebuilt wheels
RIXL
Built from source (ROCm/RIXLcommitf33a5599)
UCX
Built from source (ROCm/ucx commitda3fac2a) with–with\-rocm,–with\-verbs,–enable\-mt
ROCm Triton
Built from source (ROCm/tritoncommitf9e5bf54)
Python
3.12
VLLM_ROCM_USE_AITER=1 # AMD AI Tensor Engine Runtime
VLLM_ROCM_USE_AITER_MOE=1 # Optimized MoE kernels
VLLM_ROCM_QUICK_REDUCE_QUANTIZATION=INT4 # Fast all-reduce with INT4 quantization
VLLM_ROCM_QUICK_REDUCE_CAST_BF16_TO_FP16=1 # BF16-to-FP16 cast for quick-reduce
LinkA Critical Operational Notehttps://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings#a-critical-operational-note
Network transport quality is everything.With proper UCX/RDMA configuration, cross-node KV transfer performs comparably to intra-node. With TCP fallback, throughput degrades catastrophically – we observed up to19x degradationin testing. Always validate the RDMA transport layer before benchmarking PD.
The UCX transport configuration in our deployments:
UCX_TLS=rc,sm,self,rocm_copy,rocm_ipc
UCX_NET_DEVICES=mlx5_0:1,mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1
This configures 8x Mellanox ConnectX interfaces for RoCE fabric, using reliable connected (RC) transport with shared memory and ROCm GPU direct paths. Hardware tested: AMD MI325X with 288GB HBM3e, 8 GPUs per node.
LinkHow to Reproducehttps://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings#how-to-reproduce
Everything needed to reproduce these results is consolidated in a single repository: Dockerfile, serve configs, and benchmark scripts. The instructions assume you have a Ray cluster running on AMD MI325X nodes – viaAnyscale,KubeRay, or bare metal. All artifacts are availablehere.
LinkConclusionhttps://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings#conclusion
PD disaggregation on Ray + vLLM delivers1.3 –2.3x more QPSunder the same GPU budget and SLA – up to67% cost reductionon AMD MI325X. To summarize the main insights:
- PD winswhen your SLA is TPOT- or E2E latency-sensitive and output is long enough for per-token savings to compound.
- Aggregated winswhen TTFT is the binding constraint, output is short, or cache hit rates are high enough to eliminate prefill-decode contention.
- **The P:D ratio matters.**Given the workload the optimal value could be different from case to case.
LinkGet Startedhttps://www.anyscale.com/blog/ray-vllm-prefill-decode-disaggregation-amd-mi325x-67-percent-savings#get-started
- **Reproduce our results.**Clone therepo, deploy a config, and run the benchmark CLI against your workload.
- Need managed solutions:Anyscalegives you managed Ray services. You can deploy Anyscale on k8s and from then on you don’t have to manage Ray clusters.
- **Talk to us.**Found a workload where PD behaves differently? We want to hear about it – reach out on theRay communityorRay’s slack.
Similar Articles
@CyrusHakha: One pattern we keep seeing with customers serving LLMs at scale: Prefill-decode disaggregation is often treated like a …
Discusses the nuanced reality of prefill-decode disaggregation in LLM serving at scale, based on customer patterns and validated on AMD with vLLM.
@kazukifujii: Sakura Internet's Michishita-san's article comprehensively summarizes LLM Inference and comes highly recommended. It fe…
This article summarizes a presentation by Junda Chen on disaggregated inference for LLMs, explaining why goodput (throughput meeting latency SLOs) matters more than raw throughput, and how separating prefill and decode phases improves performance. It also highlights the influence on NVIDIA Dynamo.
2X tk/s (from 19.4 -> 38.1 tk/s on 1 x MI50) Playing with a hypothesis like speculative decoding.. but instead of an additional side model, exploiting that I can run multiple computations side-by-side AS IF I had Qwen3.6-27B loaded twice in memory - small quants don't use all the available compute.
Packed Twin Inference (PTI) is a technique that achieves ~2× LLM throughput by running multiple token sequences in a single batch decode, exploiting weight sharing in llama.cpp without needing a draft model or additional VRAM.
PSD: Pushing the Pareto Frontier of Diffusion LLMs via Parallel Speculative Decoding
This paper introduces Parallel Speculative Decoding (PSD), a training-free framework that accelerates diffusion LLM inference by jointly improving spatial and temporal efficiency, achieving up to 5.5× tokens per forward pass with comparable quality to greedy decoding.
@raydistributed: Ray Serve LLM now offers 4.4x higher request throughput on prefill-heavy workloads, and 24.8x higher request throughput…
Ray Serve LLM achieves 4.4x and 24.8x throughput improvements on prefill- and decode-heavy workloads via direct streaming, a new vLLM V2 executor backend, and HAProxy ingress, now available in Ray 2.56 in partnership with Google Cloud and vLLM.