@sheriyuo: Best-of-N, rejection sampling, and rubric-based ranking all assume you already have a reliable way to evaluate candidat…
Summary
Apodex releases Apodex-1.0, a deep-research model that uses a heavy-duty agent team with global verification, achieving state-of-the-art results on multiple benchmarks including BrowseComp, DeepSearchQA, and HLE.
View Cached Full Text
Cached at: 06/18/26, 10:13 AM
Best-of-N, rejection sampling, and rubric-based ranking all assume you already have a reliable way to evaluate candidate answers. That assumption breaks down for open-ended discovery and research tasks where there is no answer key to rank against.
Apodex, a self-evolving duty-heavy solver built for deep research, instead focuses on verification. Their setup scales verification through teams of agents, uses a generate verify revise loop without reference solutions, and explicitly targets pseudo correctness, where an answer survives its own checks despite being wrong.
The broader question is whether stronger research agents will come more from scaling generation or from building better verification systems. This work is clearly betting on the latter.
Blog: http://apodex.com/blog/apodex-1.0 Currently available for free trial at http://apodex.ai
Apodex | Self-Evolving Heavy-Duty Solver
Source: https://www.apodex.com/blog/apodex-1.0 Today we releaseApodex-1.0, our latest deep-research model, which runs as a standard tool-using ReAct agent. Deployed in ourheavy-duty mode—an asynchronous agent team that specializes, cross-checks, and audits its own evidence before answering—the same model becomesApodex-1.0-H, our flagshipheavy-duty solverand a new state of the art on deep-research benchmarks across both open- and closed-source models.
The hardest research problems an agent meets today are not bounded by model capacity but by what the model is allowed to interact with. Long-horizon research shares one structural feature: a single forward pass is not enough, and a single context window cannot hold the work. These tasks demand reasoning interleaved with retrieval, tool use, and verification, sustained over hundreds of steps and many parallel branches. Reliability on them cannot come from a model’s parametric memory alone. It must come fromdiscoverative intelligence: the capacity to reason through active engagement with the external world, and to check that engagement against itself before committing to an answer.
Scaling Reasoning with an Agent Team
Apodex scales discovery by widening the frame rather than lengthening a single loop. Instead of one agent carrying the full cognitive load, an orchestrator dispatches aheavy-duty agent teamwhose specialized sub-agents explore in parallel, and aglobal verifieraudits the assembled evidence before any answer is committed. This combination delivers outstanding results: in deployment it coordinates up to150 sub-agents over 15,000 stepsin a single task, and it sets a new state of the art across the public deep-research suite—BrowseComp, BrowseComp-ZH, DeepSearchQA, HLE, and the FrontierScience benchmarks.
Two jointly designed pieces make this possible: aheavy-duty agent team with global verificationandAgentOS, a task-agnostic runtime that hosts it.
Where Apodex Stands
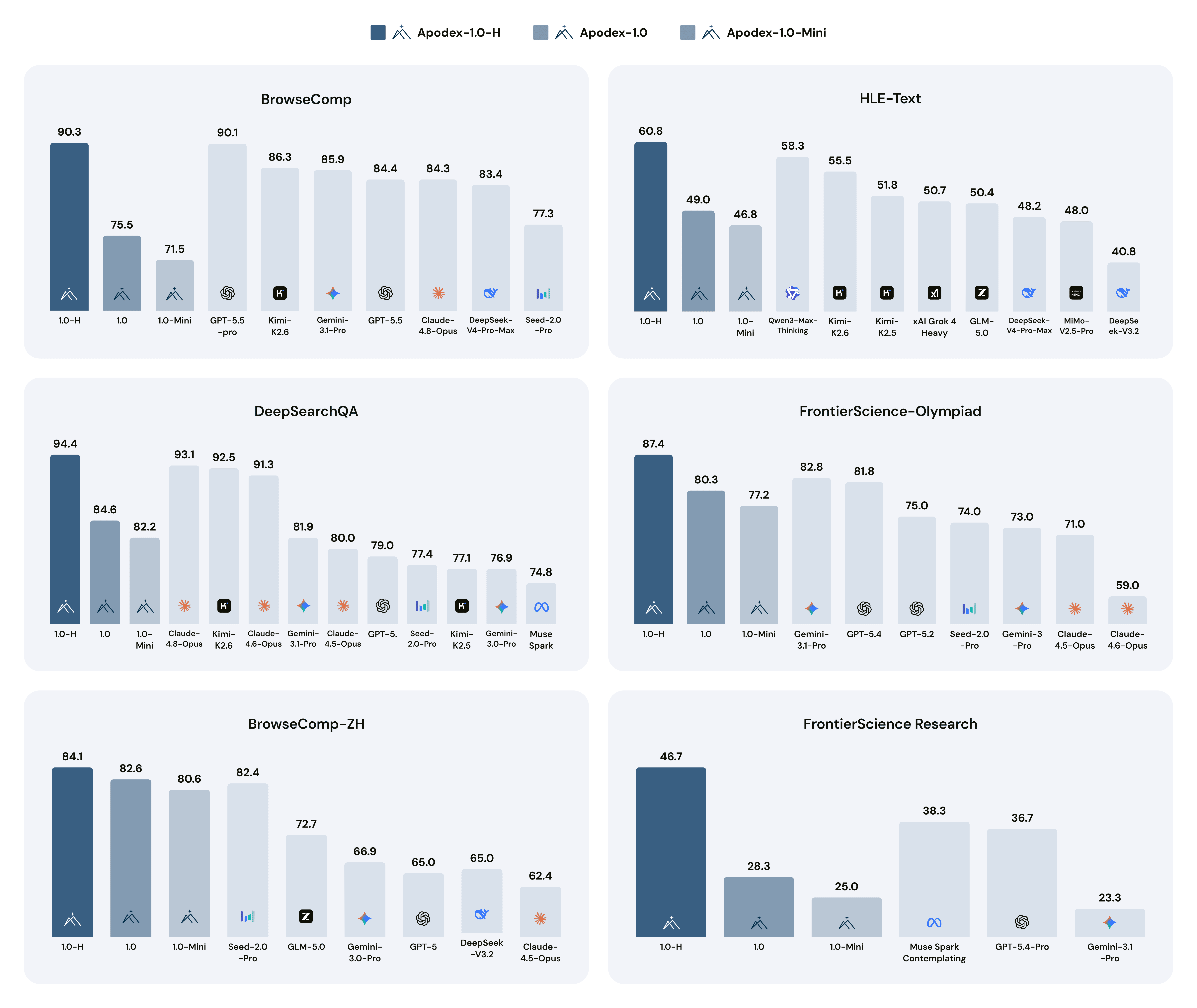
We report the latest publicly available benchmark results for competing models. See ourGitHubandHugging Facefor details.
Owning the deep-research benchmarks
As AI shifts from answering questions to executing complex tasks, the ability to navigate, parse, and synthesize information across the open web becomes the critical differentiator. As the figure above shows, on the search suiteApodex-1.0-H sets a new state of the art on BrowseComp (90.3), BrowseComp-ZH (84.1), DeepSearchQA (94.4), and text-only HLE with tools (60.8)—edging out GPT-5.5-pro on BrowseComp and clearing Claude-Opus-4.8 and Kimi-K2.6 on DeepSearchQA. The lead is wider still on scientific research:Apodex-1.0-H tops FrontierScience-Research (46.7), FrontierScience-Olympiad (87.4), and SuperChem (74.2)—beating the next-best competitor (Muse Spark 38.3, GPT-5.2 75.0, Gemini-3.0-Pro 63.2 respectively) by margins of 8 to 12 absolute points in each case. Comparing within the family quantifies what heavy-duty mode contributes: it lifts the base Apodex-1.0 by**+14.8 pointson BrowseComp (75.5 → 90.3) and by+18.4 points**on FrontierScience-Research (28.3 → 46.7).
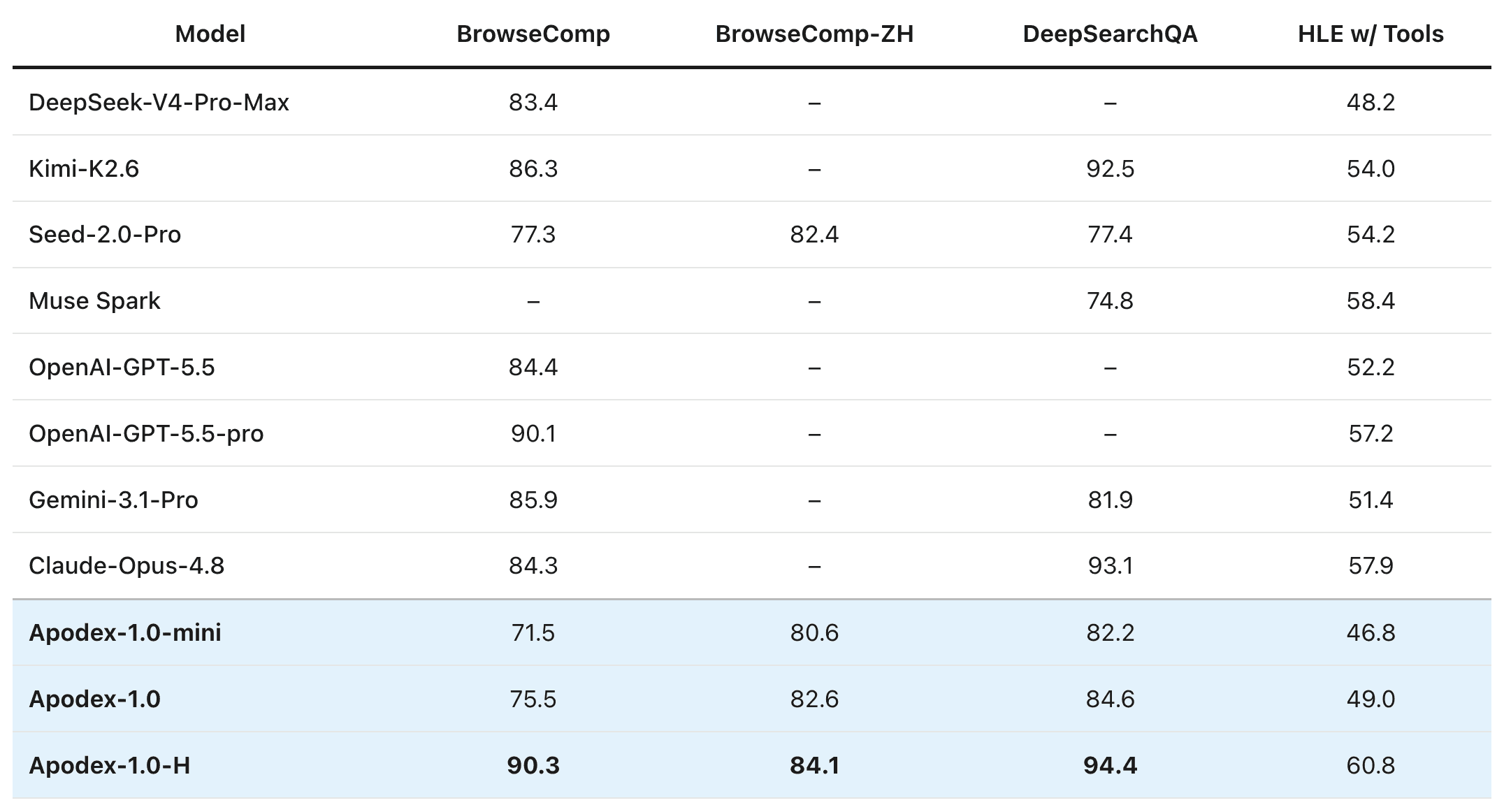
*Table 1: Performance comparison on agentic search benchmarks.*For Humanity’s Last Exam, Apodex-1.0 series and DeepSeek-V4-Pro-Max were tested on text-only subset, and other models were tested on the entire set which includes some multi-modal problems.
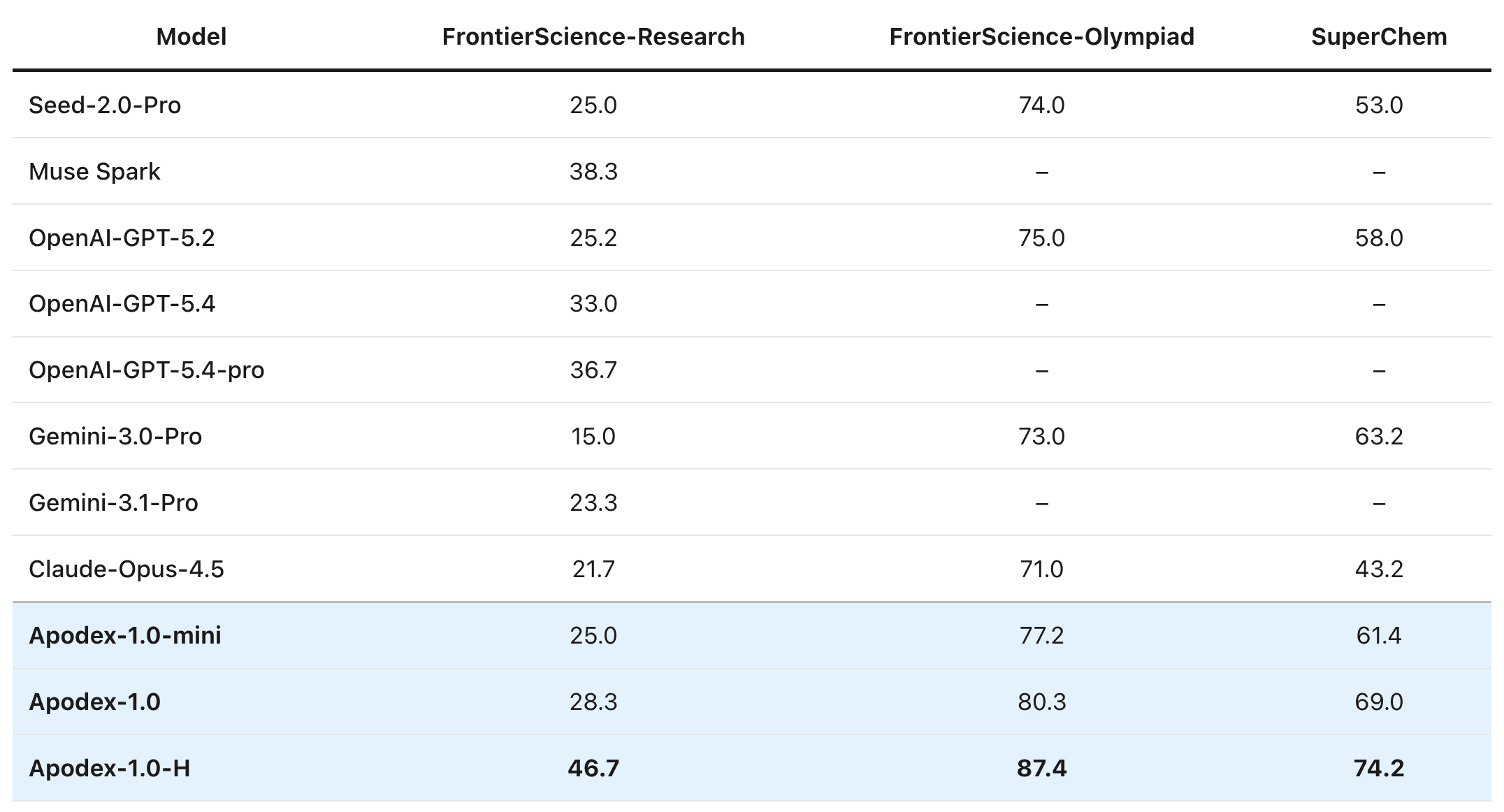
Table 2: Performance comparison on agentic science benchmarks
Strong deep research at small scale
A substantial amount of deep-research capability lives in the trained model itself, not only in test-time scaling. To support the community, weopen-source a family of small models—Apodex-1.0-mini (35B-A3B) and the 0.8B, 2B, and 4B variants. Trained on our deep-research SFT data alone, the compactApodex-1.0-4B-SFT outperforms every open-source 30B-class model on both BrowseComp and BrowseComp-ZH—evidence that careful data construction, not just parameter count, drives research ability.
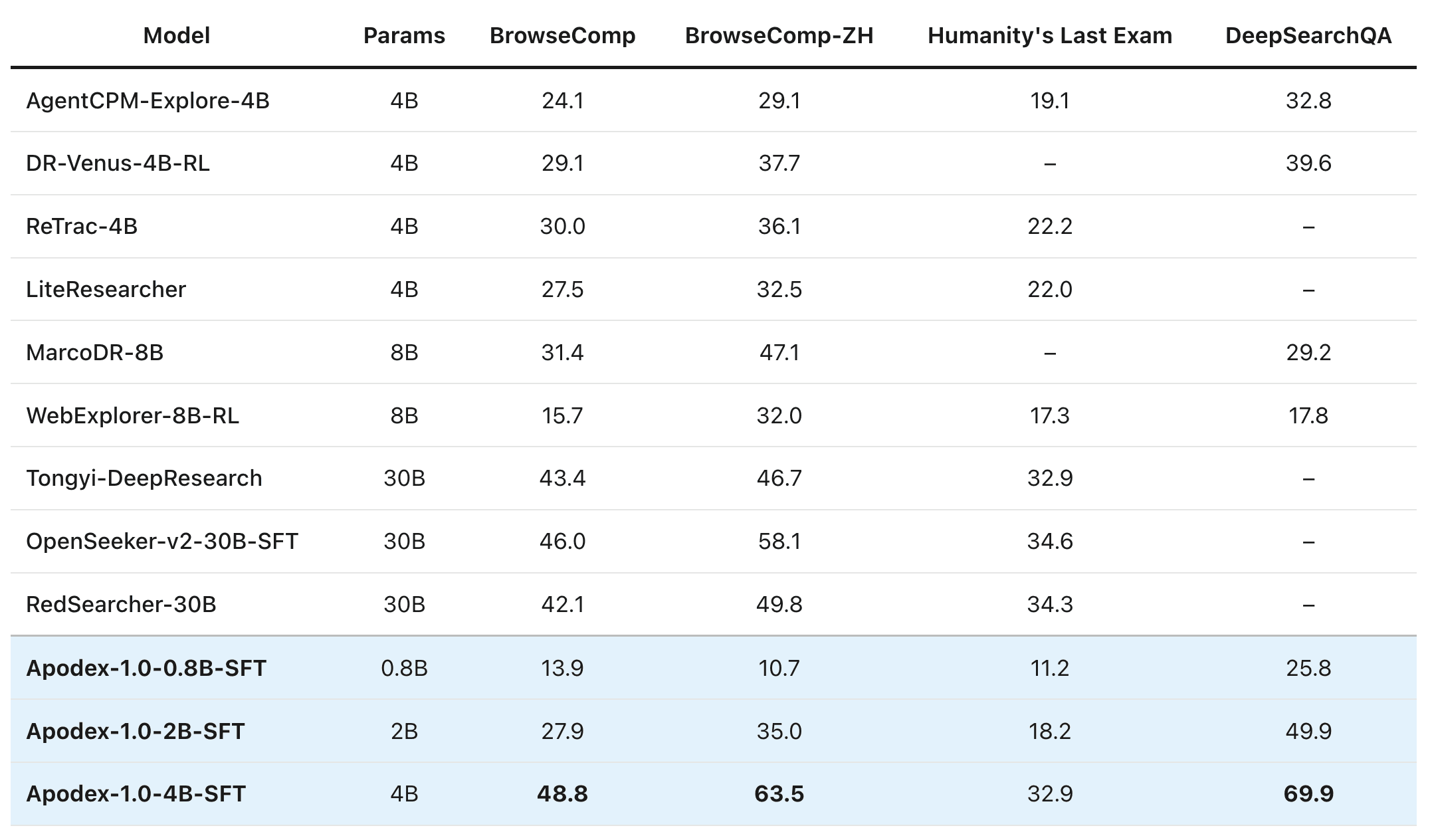
Table 3. Smaller open-source deep-research models. HLE is text-only. Bold marks where Apodex-1.0-4B-SFT leads its column.
Generalist breadth, intact
The deep-research focus does not come at the expense of the base model. Our post-training is designed topreserve rather than override: across general knowledge (MMLU-Pro/Redux, C-Eval), mathematics (AIME 2026, HMMT), instruction-following (IFEval, IFBench), and long-context (LongBench v2, AA-LCR), Apodex-1.0-mini and Apodex-1.0 track their matched-size Qwen3.5 bases within roughly a point. Coding holds up too—Apodex-1.0-H reaches 79.0 on SWE-bench Verified and 58.4 on Terminal-Bench v2. Post-training is additive on the deep-research axis rather than a trade across axes.
The Bet: Reasoning Is a Team Sport
We hold a foundational view: reliability on hard, open-ended problems cannot come from a model’s parametric memory alone.Scaling the loop is not the same as scaling discovery.When a single agent owns the full cognitive load, the context congests, exploration branches contaminate one another, and self-reflection—the only verification mechanism inside one context window—degrades. We refused to treat trajectory length as a proxy for capability. In place of one agent carrying the full load, Apodex constructs anagent team: an orchestrator decomposes the task and dynamically spawns specialized sub-agents for retrieval and verification, coordinating them asynchronously.
Heavy-duty mode: an agent team with global verification
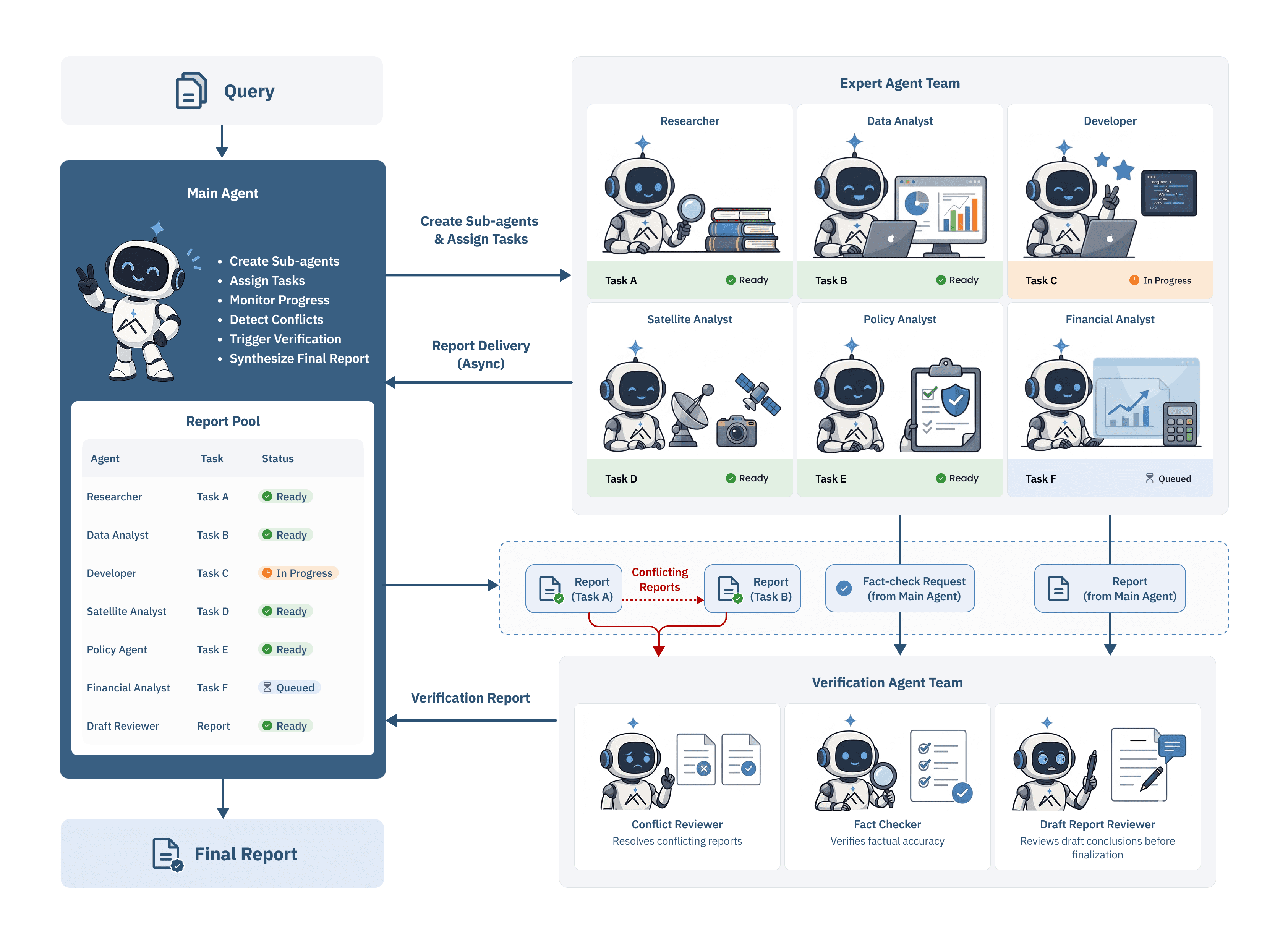
When the trained model is deployed in heavy-duty mode, amain agentreceives the query, decomposes it, andasynchronouslyspawns specialized sub-agents—each running with its own context, prompt, and tool set—and assigns them retrieval and verification tasks. Their reports flow into ashared report poolwhose status table the orchestrator reads asynchronously, never blocking on the slowest task. When two reports disagree, when a specific claim needs grounding, or when a draft is ready for a final pass, the orchestrator dispatches the work to a dedicatedverification agent team—a conflict reviewer, a fact checker, and a draft-report reviewer. Once exploration completes, aglobal verifierreasons over the assembled evidence to produce the final answer.
The question this shifts is fundamental: from*“which answer is most agreed upon”to“what does the full body of evidence support.”Verification is structurallyexternalto the reasoner being audited—a verifier is prompted to evaluate rather than to continue the reasoning, and is free to disagree. In our deployment this architecture coordinates up to150 sub-agents executing over 15,000 stepswithin a single task—two orders of magnitude beyond the saturation point of a single-agent loop. And heavy-duty often spendsfewer*steps than the base agent, not more: the verifier filters out steps that produce no information gain and concentrates compute where it advances the solution.
AgentOS, a task-agnostic runtime
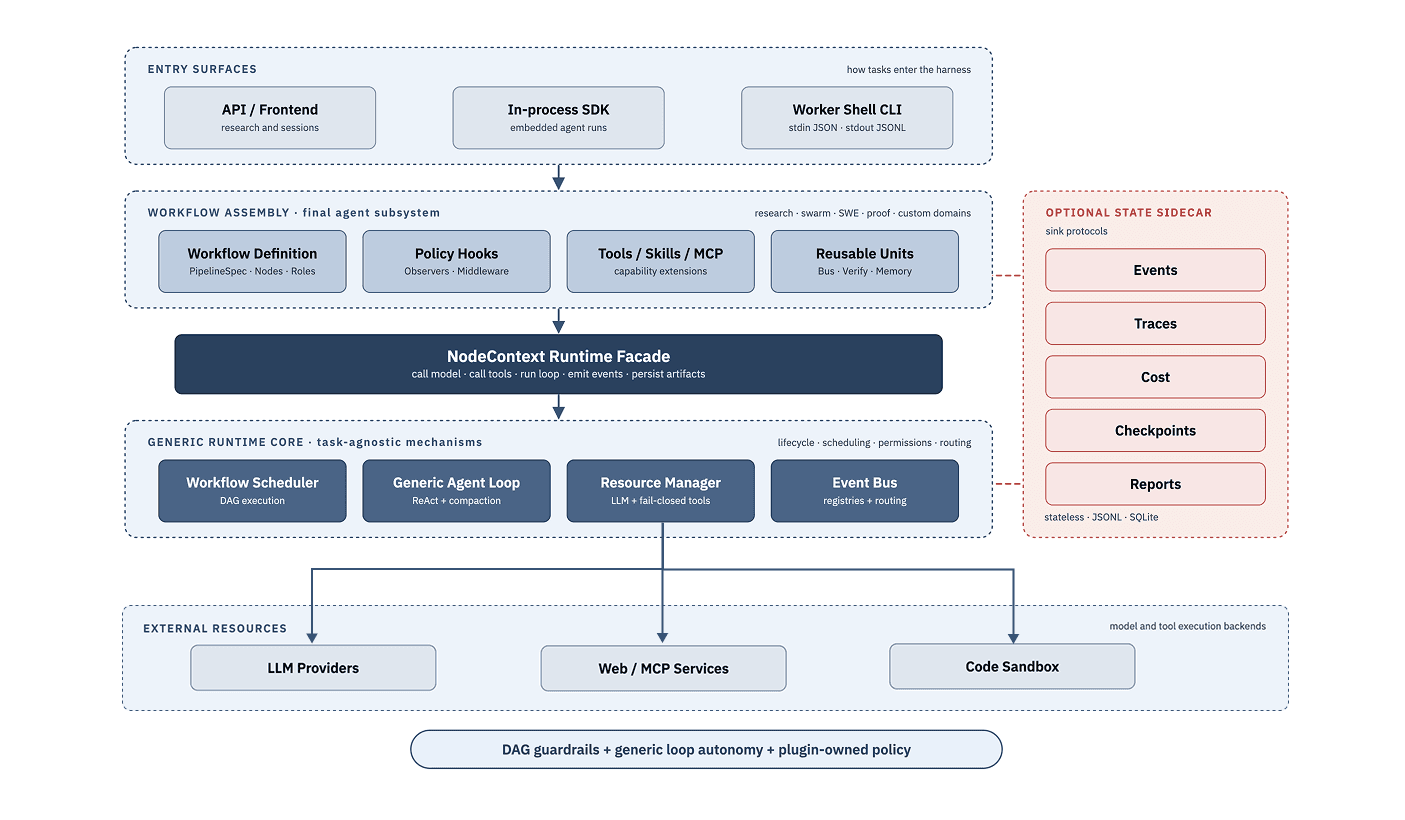
AgentOSis the runtime that hosts the agent team and its sibling workflows on a single task-agnostic kernel. The kernel provides scheduling, model and tool routing, event streaming, checkpoints, traces, cost accounting, permission enforcement, and reusable agent components—and knows nothing about any specific task. The design principle is strict separation: workflow policy lives above a narrow runtime facade, and task-agnostic execution mechanisms live below it. Adding a new application is a folder of plugin code, not a patch to the kernel. The runtime never grows a new branch for a new task.
Sample Showcase
Use Case 1: Life Sciences and Clinical Medicine
- **Query type:**Complex biomedical research design question
- **Question:**How should one design a mechanism-validation framework to determine whether a small molecule’s anti-tumor activity genuinely arises from multi-target synergy, rather than prediction bias, non-specific cytotoxicity, or a single dominant target?
- **Apodex output:**Delivered a four-layer decision framework (target engagement → causal linkage → multi-target superiority → toxicity exclusion), complete with quantitative go/no-go thresholds, synergy model selection logic, CRISPR-based genetic controls, and explicit project-termination and repositioning conditions
Use Case 2: Finance
- **Query type:**Complex financial / equity research question (FX risk and guidance reliability)
- **Question:**Across the past eight quarters through Q4 2025, has Adidas management systematically underestimated FX impact relative to its own guidance, and — given the early-2026 USD rebound and the company’s disclosed hedge-ratio policy — how will that history shape FY2026 operating profit?
- **Apodex output:**Caught the flawed premise that Adidas issues quarterly FX guidance (it does not — full-year guidance is currency-neutral only, and FX effects are disclosed solely in results), then reframed the question into two answerable substitutes: the realized full-year FX-headwind trajectory and the plausibility of FY2026 guidance. Assembled an eight-quarter actual FX-impact table from primary filings, showed management’s implicit baseline ran materially below the >€1bn FY2025 headwind that materialized, and stress-tested whether the €400m combined FX + tariff drag baked into the €2.3bn FY2026 operating-profit target is sufficient against the hedge position and early-2026 USD moves.
Use Case 3: Law
- **Query type:**Complex corporate-law analysis question (Delaware law, primary-authority citation)
- **Question:**Can a corporation or its other stockholders successfully challenge a contractual veto exercised out of pure personal animus by a sub-15% minority stockholder who — via a stockholders’ agreement — holds the right to appoint all directors/officers and pre-approval over all transactions, and under what legal framework (accounting for Moelis, DGCL §122(18)/SB 313, charter-enforceability limits, and controlling-stockholder fiduciary duties)?
- **Apodex output:**Delivered a two-theory litigation strategy pursued together: (A) an as-applied enforceability challenge — DGCL §122(18) makes the pre-approval right unenforceable where it conflicts with a charter that only restates §141(a) and never authorizes the veto; and (B) a fiduciary-duty claim treating the stockholder as a controlling stockholder under §144(e)(2) by virtue of contractual control, where an animus-driven veto breaches the duty of loyalty (unshielded by §144(d)(5)) and fails entire-fairness review under Kahn v. Lynch. Ruled out a facial attack as laches-barred under Moelis, cited primary authorities throughout, and stated the three conditions under which the conclusion holds (and what weakens Theory A if the charter is later amended).
Available Today
Apodex is built on the conviction that the leap in machine reasoning comes not from larger context windows or more polished conversation, but fromheavy-duty solvers: systems that engage the external world deliberately, verify themselves before they commit, and scale by spinning upteamsrather than lengthening a single loop. Every claim in the final report Apodex produces is backed by an explicit evidence chain and independently audited before delivery—certainty that is structural, not statistical. Apodex-1.0 and Apodex-1.0-H are live now, and we open-source Apodex-1.0-mini (35B-A3B) together with three smaller variants (0.8B, 2B, 4B) for the community to build on.
Full Technical Report•GitHub•Hugging Face•Apodex AI•Apodex API
Similar Articles
@Apodex_AI: Dive in Blog: https://apodex.com/blog/apodex-1.0 Tech report: http://apodex.com/pdf/20260608 Github: https://github.com…
ApodexAI releases Apodex-1.0, a deep-research model that operates as a tool-using ReAct agent. Its heavy-duty mode, Apodex-1.0-H, uses an asynchronous agent team with up to 150 sub-agents and achieves new state-of-the-art results on deep-research benchmarks including BrowseComp, DeepSearchQA, HLE, and FrontierScience, surpassing models like GPT-5.5-pro and Claude-Opus-4.8.
@heyshrutimishra: Apodex 1.0 dropped and the architecture is genuinely different. It's post-trained on Qwen3.5 as a self-evolving system:…
Apodex 1.0 is a self-evolving AI system post-trained on Qwen3.5, achieving SOTA on BrowseComp, DeepSearchQA, and HLE-text. Its 4B mini model outperforms 30B-class models, with an AgentOS runtime for task orchestration. Open weights available.
DuMate-DeepResearch: An Auditable Multi-Agent System with Recursive Search and Rubric-Grounded Reasoning
This technical report introduces DuMate-DeepResearch, a multi-agent framework for deep research tasks that decouples the agent core from a tool ecosystem, and incorporates graph-based dynamic planning, recursive two-level execution, and rubric-based test-time optimization. The system achieves state-of-the-art results on two deep research benchmarks, demonstrating the value of auditable agent infrastructure.
@Ex0byt: A must bookmark.. tiny cracked team, 4 H100 nodes, open source 3 stage recipe, trained on 8k synthetic rubric tasks, fu…
A small team trained a frontier-level Deep Research Agent on an academic budget using only 32 H100s and 8K synthetic samples, releasing fully open weights, code, and paper for models from 2B to 35B that match or beat closed frontier agents on key benchmarks.
@_avichawla: The No. 1 deep researcher beats Claude and ChatGPT with a trick neither uses. I studied the open-source architecture be…
The Onyx open-source deep research system achieves top ranking by stripping search access from its orchestrator agent, forcing it to decompose queries into focused research threads. Its three-phase pipeline and two-level architecture prevent information distortion and premature answering, outperforming proprietary solutions from OpenAI, Anthropic, and Google.