@laowangbabababa: 震惊了,抖音上祁博士一天卖 50w 的数字人 agent,我2 分钟就开发完成了。 用的就是Pixelle-Video这个项目,已经22k stars。包括数字人口播、动作迁移、图生视频全支持。 支持ComfyUI,输入主题,从写脚本到加…
摘要
介绍开源项目Pixelle-Video:一个全自动AI短视频引擎,输入主题即可自动生成带文案、配图、语音和背景音乐的视频,支持本地和云端模型,模块化设计可灵活替换各环节模型。
查看缓存全文
缓存时间: 2026/06/14 07:39
震惊了,抖音上祁博士一天卖 50w 的数字人 agent,我2 分钟就开发完成了。
用的就是Pixelle-Video这个项目,已经22k stars。包括数字人口播、动作迁移、图生视频全支持。 支持ComfyUI,输入主题,从写脚本到加 BGM 到出片,一条龙自动跑视频。
老王部署到本地,做了个简短的视频,属于插图式的视频,如果你需要更复杂的视频,需要自己配置云端模型比如 seedance2,kling 等等。
Pixelle-Video 最厉害的地方,是它把视频生产完全做成了可配置,支持本地部署模型和云端大模型。
文案、画面、配音、剪辑,它拆成四个可替换的模块,每块后面都能换模型,可以自由切换模型,使用非常方便
文案层:LLM 读主题,吐出带时间戳的结构化脚本,每>句对应一段画面。 画面层:脚本每句转生图提示词,扔给 ComfyUI 或直连 DashScope 出图,图生视频和数字人口播也走这一层。 语音层:脚本原文走 TTS 合成,多语言加音色克隆,不用自己录音。 合成层:画面对齐语音时间轴,叠上 BGM,输出 MP4。 仓库:http://github.com/AIDC-AI/Pixelle-Video…
P.S. 想到了就能出片,懂一点 AI 编程,这个项目就能自己做成适合各行业的数字人 agent。
AIDC-AI/Pixelle-Video
Source: https://github.com/AIDC-AI/Pixelle-Video
🎬 Pixelle-Video —— AI 全自动短视频引擎
English | 中文
![]()
![]()
![]()
![]()
https://github.com/user-attachments/assets/a42e7457-fcc8-40da-83fc-784c45a8b95d
只需输入一个 主题,Pixelle-Video 就能自动完成:
- ✍️ 撰写视频文案
- 🎨 生成 AI 配图/视频
- 🗣️ 合成语音解说
- 🎵 添加背景音乐
- 🎬 一键合成视频
零门槛,零剪辑经验,让视频创作成为一句话的事!
🖥️ Web 界面预览

📋 最近更新
- ✅ 2026-06-01: 新增直连 API 媒体模型配置,支持在 WebUI 中配置图像/视频模型供应商、Base URL 与代理开关
- ✅ 2026-01-26: 新增「动作迁移」模块,上传参考视频和图片进行动作迁移
- ✅ 2026-01-14: 新增「数字人口播」和「图生视频」流水线,新增多语言 TTS 音色支持
- ✅ 2026-01-06: 新增 RunningHub 48G 显存机器调用支持
- ✅ 2025-12-28: 支持 RunningHub 并发限制可配置,优化 LLM 返回结构化数据的逻辑
- ✅ 2025-12-17: 支持 ComfyUI API Key 配置,支持 Nano Banana 模型调用,API 接口支持模板自定义参数
- ✅ 2025-12-10: 侧边栏内置 FAQ,锁定 edge-tts 版本修复 TTS 服务不稳定问题
- ✅ 2025-12-08: 支持固定脚本多种分割方式(段落/行/句子),优化模板选择交互逻辑支持直接预览选择
- ✅ 2025-12-06: 修复视频生成 API 返回 URL 路径处理,支持跨平台兼容
- ✅ 2025-12-05: 新增 Windows 整合包下载,优化图片与视频反推工作流
- ✅ 2025-12-04: 新增「自定义素材」功能,支持用户上传自己的照片和视频,AI 智能分析生成脚本
- ✅ 2025-11-18: 优化 RunningHub 服务调用支持并行处理,新增历史记录页面,支持批量创建视频任务
✨ 功能亮点
- ✅ 全自动生成 - 输入主题,自动生成完整视频
- ✅ AI 智能文案 - 根据主题智能创作解说词,无需自己写脚本
- ✅ AI 生成配图 - 每句话都配上精美的 AI 插图
- ✅ AI 生成视频 - 支持使用 AI 视频生成模型(如 WAN 2.1)创建动态视频内容
- ✅ 直连模型 API - 可直接调用 DashScope、OpenAI、Seedream、Seedance、Kling 等图像/视频生成服务
- ✅ AI 生成语音 - 支持 Edge-TTS、Index-TTS 等众多主流 TTS 方案
- ✅ 背景音乐 - 支持添加 BGM,让视频更有氛围
- ✅ 视觉风格 - 多种模板可选,打造独特视频风格
- ✅ 灵活尺寸 - 支持竖屏、横屏等多种视频尺寸
- ✅ 多种 AI 模型 - 支持 GPT、通义千问、DeepSeek、Ollama 等
- ✅ 原子能力灵活组合 - 支持 ComfyUI / RunningHub 工作流,也支持直连 API 模型,可按需替换图像、视频、TTS、VLM 等能力
📊 视频生成流程
Pixelle-Video 采用模块化设计,整个视频生成流程清晰简洁:

从输入文本到最终视频输出,整个流程简洁清晰:文案生成 → 配图规划 → 逐帧处理 → 视频合成
每个环节都支持灵活定制,可选择不同的 AI 模型、音频引擎、视觉风格等,满足个性化创作需求。
🎬 视频示例
以下是使用 Pixelle-Video 生成的实际案例,展示了不同主题和风格的视频效果:
📱 扩展模块视频展示
👤 数字人口播韩语数字人口播 |
🖼️ 图生视频卡通视频 |
💃 动作迁移跳舞小猫 |
📱 竖屏视频展示
🌄 人文纪实类 - 视频默认模版旅行路上的风景让人流连忘返 |
🔍 文化解构类 - 视频默认模版Santa ID |
🔭 科学思辨类 - 视频默认模版为什么我们还没有找到外星文明? |
🌱 个人成长类 - 克隆音色如何提升自己 |
🧠 深度思考类 - 默认模板如何理解反脆弱 |
🏯 历史文化类 - 固定画面资治通鉴 |
☀️ 情感类 - 克隆音色冬日暖阳 |
📜 小说解说类 - 自创脚本斗破苍穹 |
🧬 知识科普类 - Qwen生图养生知识 |
🖥️ 横屏视频展示
💰 副业赚钱 - 电影模板副业赚钱 |
🏛️ 历史解说 - 自定义模板资治通鉴启示录 |
💡 提示: 这些视频都是通过输入一个主题关键词,由 AI 全自动生成的,无需任何视频剪辑经验!
🚀 快速开始
🪟 Windows 一键整合包(推荐 Windows 用户使用)
无需安装 Python、uv 或 ffmpeg,一键开箱即用!
- 下载最新的 Windows 一键整合包并解压
- 双击运行
start.bat启动 Web 界面 - 浏览器会自动打开 http://localhost:8501
- 在「⚙️ 系统配置」中配置 LLM API 和图像生成服务
- 开始生成视频!
💡 提示: 整合包已包含所有依赖,无需手动安装任何环境。首次使用只需配置 API 密钥即可。
从源码安装(适合 macOS / Linux 用户或需要自定义的用户)
前置环境依赖
在开始之前,需要先安装 Python 包管理器 uv 和视频处理工具 ffmpeg:
安装 uv
请访问 uv 官方文档查看适合你系统的安装方法:
👉 uv 安装指南
安装完成后,在终端中运行 uv --version 验证安装成功。
安装 ffmpeg
macOS
brew install ffmpeg
Ubuntu / Debian
sudo apt update
sudo apt install ffmpeg
Windows
- 下载地址:https://ffmpeg.org/download.html
- 下载后解压,将
bin目录添加到系统环境变量 PATH 中
安装完成后,在终端中运行 ffmpeg -version 验证安装成功。
第一步:下载项目
git clone https://github.com/AIDC-AI/Pixelle-Video.git
cd Pixelle-Video
第二步:启动 Web 界面
# 使用 uv 运行(推荐,会自动安装依赖)
uv run streamlit run web/app.py
浏览器会自动打开 http://localhost:8501
第三步:在 Web 界面配置
首次使用时,展开「⚙️ 系统配置」面板,填写:
- LLM 配置: 选择 AI 模型(如通义千问、GPT 等)并填入 API Key
- ComfyUI / RunningHub 配置: 如需使用工作流生成图片、视频或语音,配置本地 ComfyUI 地址或 RunningHub API Key
- API 媒体模型配置: 如需直连图像/视频模型,配置 DashScope、OpenAI、ARK、Kling 等供应商的 API Key、Base URL 和代理选项
配置好后点击「保存配置」,就可以开始生成视频了!
💻 使用方法
打开 Web 界面后,你会看到三栏布局,下面详细讲解每个部分:
⚙️ 系统配置(首次必填)
首次使用时需要配置,点击展开「⚙️ 系统配置」面板:
1. LLM 配置(大语言模型)
用于生成视频文案的 AI。
快速选择预设
- 通过下拉菜单选择预设模型(通义千问、GPT-4o、DeepSeek 等)
- 选择后会自动填充 base_url 和 model
- 点击「🔑 获取 API Key」链接去注册并获取密钥
手动配置
- API Key: 填入你的密钥
- Base URL: API 地址
- Model: 模型名称
2. ComfyUI / RunningHub 配置
用于通过 ComfyUI 工作流生成视频配图、视频片段或语音。
本地部署(推荐)
- ComfyUI URL: 本地 ComfyUI 服务地址(默认 http://127.0.0.1:8188)
- 点击「测试连接」确认服务可用
云端部署
- RunningHub API Key: 云端图像生成服务的密钥
3. API 媒体模型配置
用于不依赖 ComfyUI/RunningHub,直接调用模型供应商的图像、视频或素材分析能力。
支持的供应商
- OpenAI / GPT Image:用于 GPT 图像生成模型
- DashScope / Wan / HappyHorse:用于通义万象图像、视频生成
- Volcengine ARK / Seedream / Seedance:用于字节 Seedream 图像和 Seedance 视频生成
- Kling AI / 可灵:用于可灵视频生成
可配置项
- API Key / Access Key / Secret Key:模型供应商鉴权信息
- Base URL:模型服务地址,WebUI 会提供官方默认地址
- 本地代理:如
http://127.0.0.1:9090 - 启用代理:每个供应商可单独选择是否走本地代理
- 打印模型请求参数:调试用,会在终端打印发送给模型的 prompt、模型名和输入文件路径
💡 如果你只使用 ComfyUI 或 RunningHub,可以不填写 API 媒体模型配置;如果你选择
api/...工作流,则需要配置对应供应商的密钥。
配置完成后点击「保存配置」。
📝 内容输入(左侧栏)
生成模式
- AI 生成内容: 输入主题,AI 自动创作文案
- 适合:想快速生成视频,让 AI 写稿
- 例如:「为什么要养成阅读习惯」
- 固定文案内容: 直接输入完整文案,跳过 AI 创作
- 适合:已有现成文案,直接生成视频
背景音乐(BGM)
- 无 BGM: 纯人声解说
- 内置音乐: 选择预置的背景音乐(如 default.mp3)
- 自定义音乐: 将你的音乐文件(MP3/WAV 等)放到
bgm/文件夹 - 点击「试听 BGM」可以预览音乐
🎤 语音设置(中间栏)
TTS 工作流
- 从下拉菜单选择 TTS 工作流(支持 Edge-TTS、Index-TTS 等)
- 系统会自动扫描
workflows/文件夹中的 TTS 工作流 - 如果懂 ComfyUI,可以自定义 TTS 工作流
参考音频(可选)
- 上传参考音频文件用于声音克隆(支持 MP3/WAV/FLAC 等格式)
- 适用于支持声音克隆的 TTS 工作流(如 Index-TTS)
- 上传后可以直接试听
预览功能
- 输入测试文本,点击「预览语音」即可试听效果
- 支持使用参考音频进行预览
🎨 视觉设置(中间栏)
图像生成
决定 AI 生成什么风格的配图。
ComfyUI 工作流
- 从下拉菜单选择图像生成工作流
- 支持本地部署(selfhost)和云端(RunningHub)工作流
- 也支持选择
api/...直连图像模型工作流(需先在系统配置中填写对应供应商密钥) - 默认使用
image_flux.json - 如果懂 ComfyUI,可以放自己的工作流到
workflows/文件夹
图像尺寸
- 设置生成图像的宽度和高度(单位:像素)
- 默认 1024x1024,可根据需要调整
- 注意:不同的模型对尺寸有不同的限制
提示词前缀(Prompt Prefix)
- 控制图像的整体风格(语言需要是英文的)
- 例如:Minimalist black-and-white matchstick figure style illustration, clean lines, simple sketch style
- 点击「预览风格」可以测试效果
视频模板
决定视频画面的布局和设计。
模板命名规范
static_*.html: 静态模板(无需AI生成媒体,纯文字样式)image_*.html: 图片模板(使用AI生成的图片作为背景)video_*.html: 视频模板(使用AI生成的视频作为背景)
使用方法
- 从下拉菜单选择模板,按尺寸分组显示(竖屏/横屏/方形)
- 点击「预览模板」可以自定义参数测试效果
- 如果懂 HTML,可以在
templates/文件夹创建自己的模板 - 🔗 查看所有模板效果图
API 视频生成
当选择支持动态视频的模板或扩展工作流时,可以使用直连 API 视频模型生成片段。
- 支持 DashScope Wan / HappyHorse、Kling、Seedance 等视频模型
- 支持按模型能力显示分辨率、画幅比例、时长、水印、原生音频等参数
- 支持网络下载重试与内容审核失败后的提示词中性化重试
- 在「自定义素材」工作流中,API 视频片段会尽量根据旁白音频时长生成,并使用相邻片段信息提升连贯性
🎬 生成视频(右侧栏)
生成按钮
- 配置好所有参数后,点击「🎬 生成视频」
- 会显示实时进度(生成文案 → 生成配图 → 合成语音 → 合成视频)
- 生成完成后自动显示视频预览
进度显示
- 实时显示当前步骤
- 例如:「分镜 3/5 - 生成插图」
视频预览
- 生成完成后自动播放
- 显示视频时长、文件大小、分镜数等信息
- 视频文件保存在
output/文件夹
❓ 常见问题
Q: 第一次使用需要多久?
A: 生成时长取决于视频分镜数量、网络状况和 AI 推理速度,通常几分钟内即可完成。
Q: 视频效果不满意怎么办?
A: 可以尝试:
- 更换 LLM 模型(不同模型文案风格不同)
- 调整图像尺寸和提示词前缀(改变配图风格)
- 更换 TTS 工作流或上传参考音频(改变语音效果)
- 尝试不同的视频模板和尺寸
Q: 费用大概多少?
A: 本项目完全支持免费运行!
- 完全免费方案: LLM 使用 Ollama(本地运行)+ ComfyUI 本地部署 = 0 元
- 推荐方案: LLM 使用通义千问(成本极低,性价比高)+ ComfyUI 本地部署
- 云端方案: LLM 使用 OpenAI + 图像使用 RunningHub(费用较高但无需本地环境)
选择建议:本地有显卡建议完全免费方案,否则推荐使用通义千问(性价比高)
🤝 参考项目
Pixelle-Video 的设计受到以下优秀开源项目的启发:
- Pixelle-MCP - ComfyUI MCP 服务器,让 AI 助手直接调用 ComfyUI
- MoneyPrinterTurbo - 优秀的视频生成工具
- NarratoAI - 影视解说自动化工具
- MoneyPrinterPlus - 视频创作平台
- ComfyKit - ComfyUI 工作流封装库
感谢这些项目的开源精神!🙏
💬 社区交流
扫描下方二维码加入我们的社区,获取最新动态和技术支持:
| 微信群 | Discord 社区 |
|---|---|
 |  |
📢 反馈与支持
- 🐛 遇到问题: 提交 Issue
- 💡 功能建议: 提交 Feature Request
- ⭐ 给个 Star: 如果这个项目对你有帮助,欢迎给个 Star 支持一下!
📝 许可证
本项目采用 Apache 2.0 许可证,详情请查看 LICENSE 文件。
📚 系列工作
| 框架图 | 论文信息 |
|---|---|
 | [SIGGRAPH Asia 2024] FilmAgent: Automating Virtual Film Production Through a Multi-Agent Collaborative Framework Zhenran Xu, Longyue Wang, Jifang Wang, Zhouyi Li, Senbao Shi, Xue Yang, Yiyu Wang, Baotian Hu, Jun Yu, Min Zhang [Paper] [GitHub] |
 | [SIGGRAPH Asia 2024] Anim-Director: A Large Multimodal Model Powered Agent for Controllable Animation Video Generation Yunxin Li, Haoyuan Shi, Baotian Hu, Longyue Wang, Jiashun Zhu, Jinyi Xu, Zhen Zhao, Min Zhang [Paper] [GitHub] |
 | [ACL 2025] ComfyUI-Copilot: An Intelligent Assistant for Automated Workflow Development Zhenran Xu, Xue Yang, Yiyu Wang, Qingli Hu, Zijiao Wu, Longyue Wang, Weihua Luo, Kaifu Zhang, Baotian Hu, Min Zhang [Paper] [GitHub] |
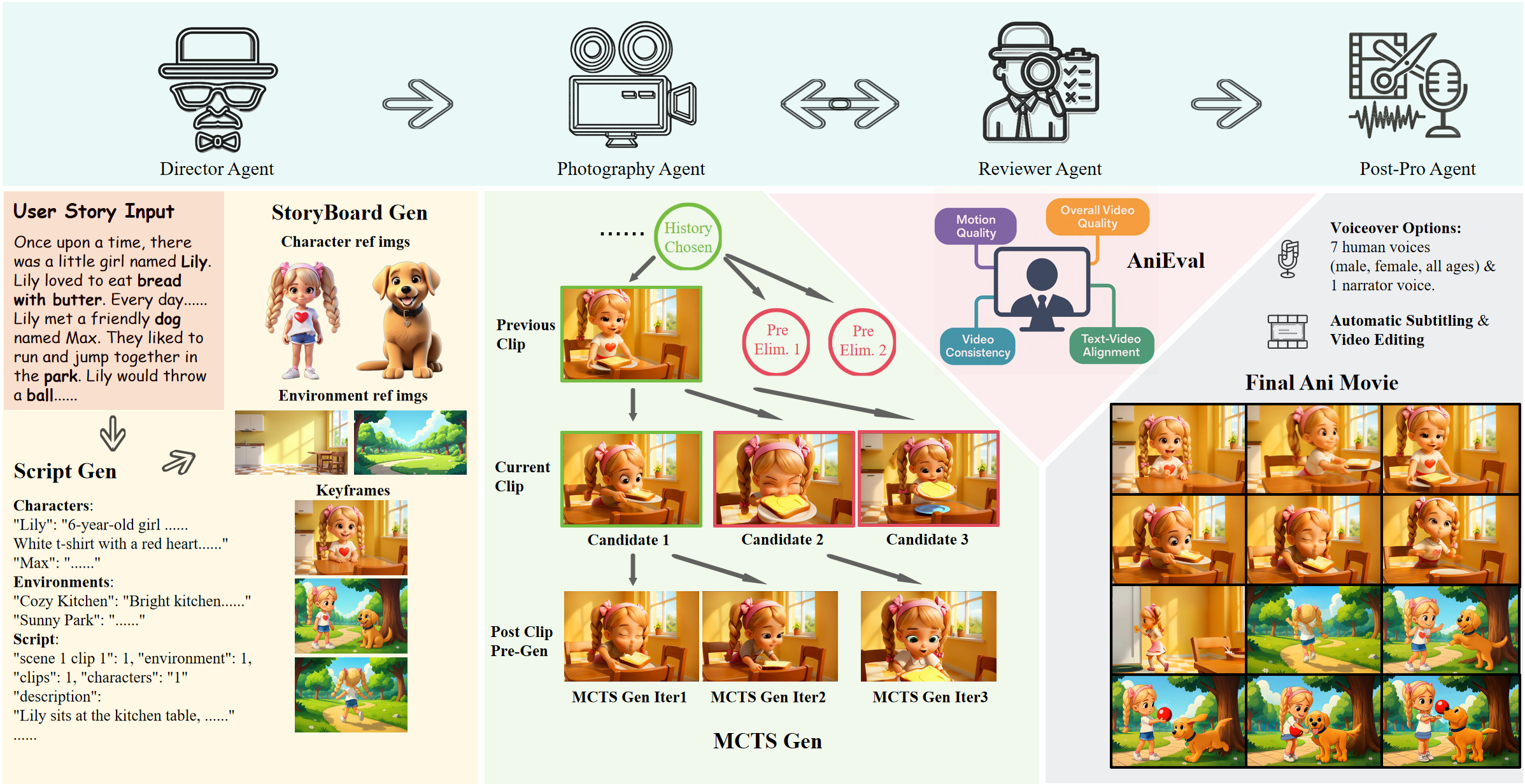 | [SIGGRAPH Asia 2025] AniMaker: Multi-Agent Animated Storytelling with MCTS-Driven Clip Generation Haoyuan Shi, Yunxin Li, Xinyu Chen, Longyue Wang, Baotian Hu, Min Zhang [Paper] [GitHub] |
⭐ Star History
相似文章
@Russell3402: 阿里国际的开源 AI 全自动短视频引擎 Pixelle-Video 你只需要输入主题,就能自动生成完整短视频 从文案到配音,从配图到剪辑,全部 AI 搞定 gitHub:
阿里国际开源了 AI 全自动短视频引擎 Pixelle-Video,用户只需输入主题即可自动生成包含文案、配音、配图及剪辑的完整短视频。
@yhslgg: 老杨再特么分享一个宝藏开源工具——KrillinAI,GitHub 10000 星,做多语言音视频内容的绝对值得看! 一句话:从视频下载到字幕翻译、AI配音、视频合成,整条链路全包,还能自动生成平台封面,B站、抖音、小红书、YouTube…
KrillinAI 是一款开源工具,整合了视频下载、字幕翻译、AI配音、视频合成全流程,支持上下文感知翻译、语音克隆、自动布局和封面生成,兼容多种AI模型,适合多语言音视频内容创作与分发。
AIDC-AI/Pixelle-Video
Pixelle-Video 是一个开源、全自动的短视频引擎,只需输入一个主题,即可通过 ComfyUI 模块化工作流自动生成完整视频,包括 AI 脚本、画面、配音、BGM 与剪辑。
@hank_aibtc: https://x.com/victormustar/status/2058492201261244458/video/1… 我操!美团直接把商业闭源Avatar干翻了, 开源免费版LongCat-Video-Avatar-1.5来了! …
美团开源了LongCat-Video-Avatar-1.5模型,支持单张照片和语音生成逼真的说话视频,支持多语言、长视频,性能超越商业闭源方案。
@QT9277: 《不是,这AI声音合成已经变态到这种程度了???》 阿台我今天刷GitHub直接懵了。 VoxCPM2,趋势榜第一,星标干到2万+,海外彻底炸了。我本来以为是又一个PPT开源项目,结果仔细看了眼Demo——我耳朵真的分不清哪个是真人了。 …
介绍VoxCPM2,一个完全免费商用、开源的多语言语音合成模型,支持声音设计、克隆及48kHz高质量输出,在GitHub趋势榜第一。