@rohanpaul_ai: 我的newsletter最新一期已发布。https://rohanpaul.substack.com/p/central-bankers-now-fear-the-ai-gold… …
摘要
一份每日AI通讯,涵盖多个故事,包括央行行长对AI债务泡沫的警告、中国开发者通过灰色市场API购买便宜的Claude访问权限、Sakana的Fugu报告、中美AI模型成本对比、Deepseek新的推理优化方法,以及Meta开源的脑机文本系统。
查看缓存全文
缓存时间: 2026/06/30 23:55
今日的新闻通讯刚刚发布。
https://rohanpaul.substack.com/p/central-bankers-now-fear-the-ai-gold…
央行行长们现在担心,AI淘金热可能播下下一场重大金融危机的种子。
一则惊人的博客:中国开发者正通过灰市API中转站购买Claude访问权限,这些中转站能以官方价格的5%至10%出售Token,同时向Anthropic隐藏真实用户身份。
Sakana Fugu技术报告
中国AI模型在每Token基础上比美国同类产品便宜高达50倍。
Deepseek AI发布了他们新的推理优化方法。
Meta刚刚开源了一个脑电转文字系统,实现了无需手术的78%单词准确率。
🗞️ 央行行长们现在担心,AI淘金热可能播下下一场重大金融危机的种子。
来源:https://www.rohan-paul.com/p/central-bankers-now-fear-the-ai-gold 图片(https://substackcdn.com/image/fetch/$s_!HUVM!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F02bec1df-7218-4d25-a873-a529e11d6698_828x900.jpeg) 阅读时间:10分钟
📚 浏览往期版本(https://rohanpaul.substack.com/s/daily-ai-newsletter/archive?sort=new)。
(https://x.com/rohanpaul_ai 我每天发布这份新闻通讯(https://x.com/rohanpaul_ai)。仅限无噪音、可操作、应用导向的AI进展)。
- 🗞️ 央行行长们现在担心,AI淘金热可能播下下一场重大金融危机的种子。
- 🗞️ 一则惊人的博客:中国开发者正通过灰市API中转站购买Claude访问权限,这些中转站能以官方价格的5%至10%出售Token,同时向Anthropic隐藏真实用户身份。
- 🗞️ Sakana Fugu技术报告
- 🗞️ 中国AI模型在每Token基础上比美国同类产品便宜高达50倍。
- 🗞️ Deepseek AI发布了他们新的推理优化方法。
- 🗞️ Meta刚刚开源了一个脑电转文字系统,实现了无需手术的78%单词准确率。
在X(Twitter)上关注我(https://x.com/rohanpaul_ai)
图片(https://substackcdn.com/image/fetch/$s_!HUVM!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F02bec1df-7218-4d25-a873-a529e11d6698_828x900.jpeg) 国际清算银行(BIS)刚刚发布了关于AI热潮背后堆积的债务的最严厉警告之一。(https://www.bis.org/publ/arpdf/ar2026e1.htm)
危险不在于AI本身,而在于围绕尚未证明持久性的收入构建了一个杠杆化的供应链。风险在于,如果AI需求令人失望,数据中心支出可能放缓,借款人可能难以偿还债务,压力可能从科技领域蔓延到信贷市场。
AI需求推动了超大规模云服务商在芯片、数据中心和电力容量上的巨额支出,这种支出支撑了增长、贸易和宽松的金融环境,而股票投资者则预计未来几年盈利将高速增长。债务改变了繁荣的形态,因为2025年超大规模云服务商的债券发行量超过了1000亿美元,而资产负债表外的工具将数据中心债务转移给了私人信贷基金、保险公司和其他非银行放贷机构。
循环融资增加了另一个薄弱环节:芯片制造商、超大规模云服务商、AI实验室和计算提供商可以相互融资,同时彼此预订未来的销售,这使得实际需求更难判断。资本支出放缓可能会首先打击供应商,然后是信贷市场,最后是家庭,因为美国股票约占MSCI全球指数的64%,家庭股票敞口高于以往周期。
私人信贷增加了系统性风险,因为直接贷款机构在5年内将AI和IT敞口增加了四倍,达到投资组合的约15%,而一些面向零售的基金已经面临赎回压力。AI仍然可以带来实际的生产力提升,但融资结构现在假设这种提升足够快地到来,以支撑巨大的固定成本。
BIS警告称,AI驱动的市场抛售可能很快蔓延到信贷市场,因为在过去的压力事件(如2008年和2020年)中,股票损失和信用利差同步变动。
图片(https://substackcdn.com/image/fetch/$s_!RLp7!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fbede22c7-3562-4d10-90e0-8c14e00ef9bc_806x606.png) 私人信贷也成为小型企业的更大放贷方,而软件借款人与多家贷款机构的联系日益紧密,因此AI冲击可能通过一个更不透明的信贷系统蔓延。
美国从亚洲进口的AI相关产品激增,而中国的份额骤降,供应转向东盟、台湾和韩国。
图片(https://substackcdn.com/image/fetch/$s_!cS6e!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fcb77a7a5-c657-4594-8575-b0e3e4bb55cf_588x833.png) 这支持了BIS的观点:AI繁荣与巨大的硬件供应链紧密相连,因此对芯片、电力、贸易路线或融资的任何冲击都可能蔓延到科技股之外。
AI相关的资本支出已从2021年的几千亿美元爆炸式增长,预计到2026年将达到约8000亿美元,其中美国超大规模云服务商推动了大部分增长。
图片(https://substackcdn.com/image/fetch/$s_!OQZs!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0e11420d-24e0-47ed-bf35-7aa7efd00442_392x544.png) BIS警告称,这种支出繁荣现在支撑着增长,但也创造了崩溃风险,如果AI收入无法证明大规模建设是合理的。
图片(https://substackcdn.com/image/fetch/$s_!gHLH!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F097df6d3-983b-42a9-8030-efa150558cd1_900x744.jpeg) 中转站是一个中间服务器,它接收用户的提示,通过海外账户将其发送给Claude,返回答案,并通过微信或支付宝收款。(https://www.chinatalk.media/p/how-to-buy-cheap-claude-tokens-in)
中转站通过免费额度、折扣账户、共享订阅、海外支付变通方案、虚假验证,有时甚至是盗刷卡账户来收集大量Claude账户。它将这些账户全部连接到一个代理后面,因此中国用户不与Anthropic直接交互,只需用人民币支付给代理。
低廉的价格来自于账户挖掘、滥用免费额度、转售未使用配额、拆分订阅、可能的盗刷卡,以及一个更阴暗的交易:用户提示和输出成为训练数据。所以价格极其便宜不是因为Anthropic给了折扣,而是因为中转站降低了自己的成本并创造了额外的隐藏收入。
用户以为他们在购买廉价的推理服务,但代理可能会用较弱的模型替换Opus,虚增Token使用量,或者存储私有代码、工具调用、推理轨迹和业务数据。代理可能会存储用户提示、代码、输出和工具痕迹,然后出售或重复使用这些数据进行模型训练。
这打破了KYC、账户封禁和滥用监控的核心假设: AI公司看到的是代理,而不是真实用户,因此封禁一个账户并不会切断上游供应链。 图片(https://substackcdn.com/image/fetch/$s_!CQYZ!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0db292fe-a698-4561-809a-4928d1b6f0c9_900x886.jpeg) 核心理念是:智能正在从模型转移到围绕模型的系统上。(http://arxiv.org/abs/2606.21228)Fugu是一个编排器,它读取任务,选择要使用的专用模型,在Ultra版本中可以构建小型工作流,让模型相互批评、扩展或纠正。大多数多模型系统使用简单规则,例如询问3个模型并进行投票,或者总是将编码任务发送给1个模型,数学任务发送给另一个模型。Fugu的不同之处在于,管理器是从数据中训练出来的,用于学习哪种模型实际上最适合每种情况,包括像“这看起来像编码,但难点是调试,所以引入更擅长调试的模型”这样的细微差别。
该机制有两个版本。
常规Fugu是快速版本,它读取用户的请求并快速从池中选择一个工作模型,因此用户体验就像是调用一个模型,但背后Fugu为该特定请求选择了它认为最好的模型。Fugu-Ultra是较慢但更强的版本,它可以创建一个小型工作流,例如让一个模型求解,另一个模型检查,另一个模型从不同角度求解,然后选择最佳模型来组合答案。
特别之处在于,工作流在任务开始前不是固定的,因为Fugu-Ultra可以为每个问题设计不同的协作模式。
该图显示了常规Fugu的快速路由机制:它读取用户请求,但自身不回答。
图片(https://substackcdn.com/image/fetch/$s_!ovJJ!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F8a21e107-ab80-4a66-8374-e7f76058232f_846x693.png) 关键部分是“轻量级头部”,这是一个附加在语言模型上的小型额外决策层。该层查看模型的隐藏状态,即其对请求内容的内部摘要。
然后它为每个可用的工作模型给出一个分数,最高分决定哪个外部LLM获得任务。红色对角线标记了一个小的调优技巧:他们只调整模型内部权重的一小部分,使其更擅长选择正确的工作模型。
在X(Twitter)上关注我(https://x.com/rohanpaul_ai)
图片(https://substackcdn.com/image/fetch/$s_!Z7Ux!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F414b9988-fc69-4cd5-9a4a-c11996565717_597x772.png) 尤其是Qwen、DeepSeek和Kimi,这给OpenAI和Anthropic的定价带来了压力。(https://privatebank.jpmorgan.com/apac/en/insights/latest-and-featured/eotm/semiquincententacles)——摘自摩根大通题为“Semiquincententacles: the US grip on global markets at 250”的报告,该报告发现,到2026年4月,中国企业占AI聚合平台OpenRouter总流量的45%以上,而2024年底这一比例不到2%。报告的其他一些发现。
- 企业AI Token可能变得商品化,因为许多业务任务不需要前沿模型,可以在较小的开源模型上运行。
- 自ChatGPT以来,AI已推动标普500指数65%-80%的回报、利润和资本支出,在半导体领域出现了明显的投资者过度兴奋迹象。
- NVIDIA仍在AI加速器领域占据主导地位,但来自Google、Amazon、Microsoft和Meta的定制芯片正在崛起,因为它们可以将总成本降低30%-40%。
- 中国正在AI领域迎头赶上,拥有更好的模型、不断增长的GPU自给自足能力,以及尽管存在出口管制但仍可能实现芯片规模化的变通方案。
- 台湾是美国AI系统的薄弱环节,因为TSMC支撑着全球大部分先进芯片供应,而台湾高度暴露于能源和食品封锁的风险。
摩根大通资产管理公司策略师Michael Cembalest在报告中指出,中国正在利用低成本开源策略加速AI在全球的采用。截至2026年2月底,中国模型处理了OpenRouter上前10大模型消耗的约8.7万亿Token中的5.3万亿,其中MiniMax、Moonshot AI和智谱AI占据前三名。
图片(https://substackcdn.com/image/fetch/$s_!SbM6!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc2eab23e-7182-4ccc-b416-153e3fca5850_683x900.jpeg) 提出了DSpark,一种半并行投机解码系统,在匹配的吞吐量下,使DeepSeek-V4的每用户生成速度提高了约60%到85%。(https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf)
DSpark最大的想法是,更快的推理不仅关乎生成更多的Token草案,还关乎决定哪些草案Token值得检查。投机解码已经有了基本技巧:一个较小的草稿模型猜测接下来的几个Token,然后真实模型在一次传递中检查它们。
问题在于,长草案块通常会浪费工作,因为后面的猜测更可能出错,而检查错误的猜测仍然消耗GPU容量。DSpark的突破在于使这个过程具有选择性:它起草一个块,评估每个前缀存活的可能性,然后只验证可能见效的部分。
该机制有两个关联部分: 一个强大的并行草稿模型快速进行多次Token猜测,然后一个微小的马尔可夫头部利用前面的Token调整每个猜测。这个小的顺序部分很重要,因为纯并行起草速度快,但后面的Token会衰减,因为每个位置的猜测不知道之前实际采样的Token是什么。即,完全并行的草稿者每个位置的猜测过于独立,可能在块的后半部分产生糟糕的Token组合。然后,置信度调度器根据接受概率和当前GPU负载,估计每个请求应检查多少草稿Token。
DSpark是一个猜测-检查循环,其中真实模型首先创建Token D,然后DSpark利用D快速猜测E、F、G和H。
图片(https://substackcdn.com/image/fetch/$s_!hHtX!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F9c045e37-dbf3-41a8-9eb6-292daaaa88e4_900x816.jpeg) 并行块使猜测快速,而小的顺序块通过让每个猜测对前一个猜测有所了解,修复了并行起草的主要弱点。调度器是关键的系统思想:它不验证每个猜测的Token,只保留看起来值得GPU成本的前缀。
这里它保留了E、F和G,丢弃了有风险的H,然后真实模型接受E和F但拒绝G并用G*替换它。所以主要观点是,DSpark通过结合更快的猜测、稍智能的猜测和选择性检查(而不是盲目检查固定长度的草案)来加速推理。
Meta的Brain2Qwerty v2将非侵入性脑部记录转换为文本,平均单词准确率为61%,最佳参与者的准确率达到78%。(https://ai.meta.com/blog/brain2qwerty-brain-ai-human-communication/)
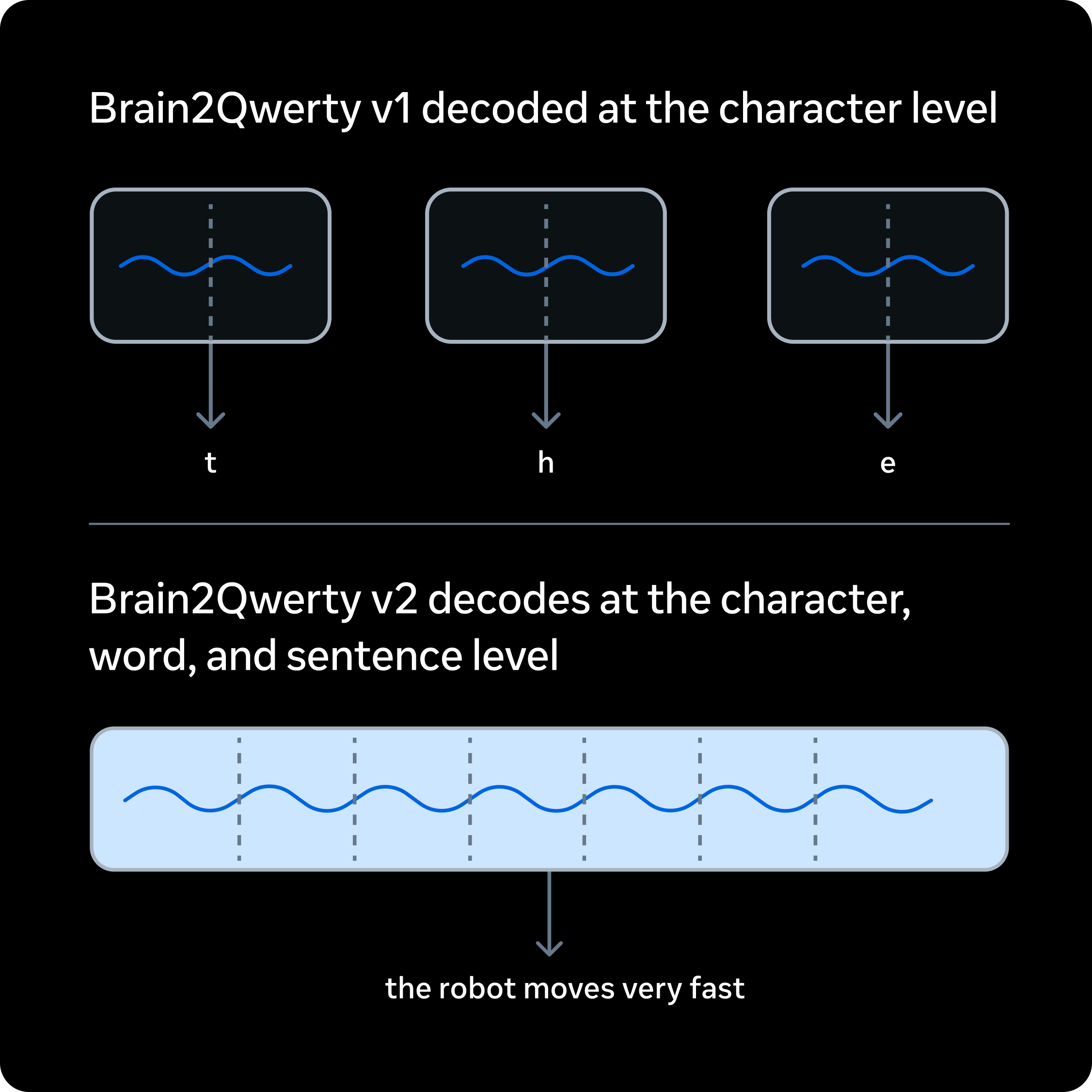{kind=link}
该系统读取来自头盔的MEG信号,而非植入脑组织的电极。9名志愿者输入了约22,000个句子,研究人员为每人记录了10小时的神经活动。
Brain2Qwerty v1主要将大脑信号映射到单个打字字符。它尝试同时恢复字符、单词和完整句子的含义。系统研究这些大脑信号,并试图将其转换为您想要打出的单词。
- 所有参与者的平均单词准确率为61%
- 最佳参与者的单词准确率为78%
- 超过50%的句子解码错误不超过1个单词
- 随着数据量增加,性能提升
原始大脑信号是混乱的,因为许多心理和生理过程同时触发。深度学习通过直接从原始录音中学习模式来处理这种混乱。
一个经过微调的LLM随后利用语言上下文来修复可能的单词和句子错误。这解释了为什么该系统优于此前报告单词准确率8%的非侵入性方法。
来自最佳参与者的句子中,超过一半的错误不超过一个单词。准确率也随着训练数据的增加而提高,这表明更多的录音可能会进一步缩小差距。
今天就到这里。
相似文章
2026年5月简讯
月度简讯涵盖2026年5月AI领域的发展,包括成本上升、Anthropic的强劲表现、令人失望的模型发布、会议以及Datasette Agent的发布。
针对数据中心的攻击、各种尺寸的Qwen3.5、DeepSeek与华为的合作、Apple的多模态分词器
Andrew Ng的时事通讯涵盖了近期AI发展,包括针对数据中心的攻击、各种尺寸的Qwen3.5的发布、DeepSeek与华为的合作、Apple的多模态分词器,以及对AI驱动的就业不确定性和地缘政治风险的反思。
The Download:超越Mythos的AI黑客攻击,以及聊天机器人对我们大脑的影响
一份新闻通讯,报道了一起Meta AI代理黑客事件,该事件盗取了Instagram账户,以及研究表明AI聊天机器人正在削弱人类认知能力;同时还提到Anthropic呼吁全球放缓AI开发。
2026年4月通讯
月度通讯,总结2026年4月的人工智能发展,包括Opus 4.7、GPT-5.5、Claude Mythos和ChatGPT Images 2.0。
OpenClaw 肆虐,Kimi 的开放模型,Ministral 蒸馏版本,Wikipedia 的合作伙伴
Andrew Ng 讨论了人工智能对就业市场的微妙影响,指出虽然大规模裁员被过度夸大,但人工智能技能正变得至关重要。该通讯还报道了关于 OpenClaw、Kimi 的开放模型、Ministral 蒸馏版本和 Wikipedia 的合作伙伴的新闻。