@rohanpaul_ai: 我的新闻通讯今日版刚刚发布。https://rohan-paul.com/p/openai-has-proposed-giving-washington… OpenAI …
摘要
OpenAI 提议向美国政府提供其 8520 亿美元业务 5% 的股份,以缓解监管压力;其他 AI 新闻包括 Meta 限制工程师使用 Claude Code 和 Codex,以及 NVIDIA 优化了一个 30B 语言模型,实现 2.42 倍更快的写入速度。
查看缓存全文
缓存时间: 2026/07/04 00:42
今天的每日通讯刚刚发布。
https://rohan-paul.com/p/openai-has-proposed-giving-washington…
OpenAI 提议将其 8520 亿美元业务的 5% 给予华盛顿方面,以缓解 AI 监管压力。
安全路由器将更多提示从 Fable 5 分流至 Opus 4.8
关于 Claude Fable 5:以下案例可能是一个极端情况,但它仍然展示了 Fable 5 分类器如何迅速将常规编码任务重新路由至 Opus。
“红色女王哥德尔机:共同进化的智能体与其评估者”
The Information:据报道,Meta 已限制工程师使用 Claude Code 和 Codex,因为竞争对手模型的输出可能污染 Meta 自身的 AI 训练数据,并在与 Anthropic 和 OpenAI 的合同中制造麻烦。
“面向 LLM 集成应用的 MCP 服务器架构模式”
“量化推理模型认为自己需要思考更长时间,但实际并非如此”
NVIDIA 使一个 30B 参数的语言模型写入速度提升 2.42 倍,同时保留了 98.7% 的质量。
🗞️ OpenAI 提议将其 8520 亿美元业务的 5% 给予华盛顿,以缓解 AI 监管压力。
来源:https://www.rohan-paul.com/p/openai-has-proposed-giving-washington 图片 (https://substackcdn.com/image/fetch/$s_!b4hx!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fa03314ca-bf55-4a8e-ad00-0caf90cf7277_580x555.png) 阅读时间:10 分钟
📚 浏览过往版本请点击此处 (https://rohanpaul.substack.com/s/daily-ai-newsletter/archive?sort=new)。
(https://x.com/rohanpaul_ai**我每日发布此通讯 (https://x.com/rohanpaul_ai).**仅包含无噪音、可操作的应用 AI 发展动态)。
- 🗞️ OpenAI 提议将其 8520 亿美元业务的 5% 给予华盛顿,以缓解 AI 监管压力。
- 🗞️ 安全路由器将更多提示从 Fable 5 分流至 Opus 4.8
- 🗞️ 关于 Claude Fable 5:以下案例可能是一个极端情况,但它仍然展示了 Fable 5 分类器如何迅速将常规编码任务重新路由至 Opus。
- 🗞️ “红色女王哥德尔机: 共同进化的智能体与其评估者”
- 🗞️ The Information: 据报道,Meta 已限制工程师使用 Claude Code 和 Codex,因为竞争对手模型的输出可能污染 Meta 自身的 AI 训练数据,并在与 Anthropic 和 OpenAI 的合同中制造麻烦。
- 🗞️ “面向 LLM 集成应用的 MCP 服务器架构模式”
- 🗞️ “量化推理模型认为自己需要思考更长时间,但实际并非如此”
- 🗞️ NVIDIA 使一个 30B 参数的语言模型写入速度提升 2.42 倍,同时保留了 98.7% 的质量。
在 X (Twitter) 上与我联系 (https://x.com/rohanpaul_ai)
图片 (https://substackcdn.com/image/fetch/$s_!b4hx!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fa03314ca-bf55-4a8e-ad00-0caf90cf7277_580x555.png) 这个想法借鉴了阿拉斯加石油基金的模式,该基金与居民共享资源财富。(https://www.ft.com/content/7c803eab-8e80-4431-9a87-e943bf00e00b)
这里的资源不是石油,而是来自先进 AI 系统的未来收入。OpenAI 也希望其他主要 AI 公司捐出类似的 5% 股份。
Anthropic、Google、Meta 等公司尚未同意加入该计划。目前尚未达成任何协议。
其机制可能如下: OpenAI 将股份交给一个政府关联基金,该基金持有这些股份,未来 IPO 收益或股息将用于支持公众支出。难点在于法律层面。法律路径尚不明确,交易可能需要国会批准,特别是如果政府要为此设立一个正式的公共基金。
此前英特尔 (Intel) 的交易使这个想法不再那么理论化,因为纳税人获得了 9.9% 的股份。OpenAI 已经提议建立一个公共财富基金,让公民获得与 AI 相关的财务收益。
股东在这里非常重要。OpenAI 基金会持有 26% 的股份,微软持有约 27%,员工及其他投资者持有 47%。新的 5% 股份可能会稀释所有人的股份,除非这些股份来自现有持有者。
因此,OpenAI 的董事会、基金会、微软、主要投资者以及可能的监管机构都需要接受这一结构。最简洁的路径是向公共财富基金发行无投票权股份,这样政府获得收益,但不会获得控制权。最棘手的路径是发行有投票权的股份,因为那样华盛顿将既是监管者又是部分所有者。
图片 (https://substackcdn.com/image/fetch/$s_!F7-p!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fdd5db45f-11b6-4507-9a21-fbefcc7a5c7b_776x802.png) Claude Fable 5 在暂停 19 天后已恢复上线。但它并非真正“恢复正常”。
Fable 5 的回归显示了安全路由如何降级一个前沿模型。现在我们得到的只是“被许可了的智能”。
Fable 5 并没有被削弱,因为 Anthropic 让底层模型变笨了。它被削弱,是因为围绕该模型的公共产品路径现在受到了更多限制。
该模型功能非常强大,以至于 Anthropic 正在将一些请求从它路由出去,阻止更多模棱两可的行为,将 Mythos 模型保留在政府批准的门槛之后,限制包含在内的订阅使用量,并要求在某些企业和云提供商路径中保留 Mythos 级模型数据。
在智能内部设置守门员的代价。要注意的是,这种安全措施并非简单的拒绝层;它是一个分类器,会将标记过的 Fable 5 请求发送到 Opus 4.8。
我在想,普通人可能再也无法获得升级后的前沿模型了。Fable 5 回来了,但过去的承诺没有。一个时代的终结。☹️
图片 (https://substackcdn.com/image/fetch/$s_!vxKl!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F1f7d570d-5056-4627-b1b4-19b321df8659_846x760.png) 该会话将 75% 的工作路由到了 Opus,因为新的分类器不断将这里的编码提示误读为网络安全问题。
在 X (Twitter) 上与我联系 (https://x.com/rohanpaul_ai)
图片 (https://substackcdn.com/image/fetch/$s_!9Gby!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F28a5e974-90d8-47cd-9bdb-fc2865d5947e_863x783.png) 来自剑桥大学、NVIDIA 及其他顶级实验室的新论文,教导 AI 智能体和 AI 评判者共同进步,使任何一方都不会陷入停滞。(http://arxiv.org/abs/2606.26294)
将自我改进型 AI 从固定基准转向一个循环,在这个循环中,进行评判的一方也可以变得更好。问题是大多数自我改进的智能体都是针对固定基准或固定评估器进行训练的,因此分数可能变得过时、过于简单,或者容易被钻空子。
论文的想法是让评估器也能改进,但只在安全的交接点进行,这样每个训练阶段仍然有一个稳定的评判者。在每个阶段中,智能体由当前冻结的评估器进行测试,而潜在更好的评估器则对照保留的人类或客观答案进行单独测试。
作者们在编码、论文写作、论文评审、证明编写和证明评分方面尝试了这种方法,其中一些任务有明确答案,而另一些则需要学习判断。在编码方面,该系统超越了之前最好的自我改进编码智能体,同时使用的 token 减少了 1.35 倍到 1.72 倍,因为一个廉价的代码审查员提供了有用的反馈。
在论文写作方面,与固定评估器的基线相比,共同进化的写手的论文被评审小组平均接受的概率提高了约 1.86 倍。关键点在于,更强大的 AI 系统可能需要在它们成长过程中配备更强大的评判者,因为固定的测试可能不再能提供有效的压力。
图片 (https://substackcdn.com/image/fetch/$s_!XxcI!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ff995e5c3-4260-4ea8-ba2c-d2951a29eabc_900x458.jpeg) 当 Meta 的新模型从另一个模型的输出(来自 OpenAI 或 Anthropic)中学习时,蒸馏风险就开始了。因此,即使是意外地重复使用 Claude 或 Codex 的答案,也可能看起来像是 Meta 从竞争对手那里提取了能力,而非自己构建的。(https://www.theinformation.com/articles/internal-docs-show-meta-putting-limits-claude-codex-fearing-distillation)
OpenAI 的服务条款禁止使用其输出来开发竞争性模型,而 Anthropic 则声称其条款不允许将 Claude 的输出用于训练与 Anthropic 自身系统竞争的其他模型。OpenAI 和 Anthropic 的条款都禁止使用输出来开发竞争性模型。
在我看来,最安全的策略可能是成分追踪: 仅当输出被禁止进入模型训练管道、评估集、基准生成、后训练数据、奖励模型数据以及后续用于模型开发的内部数据集时,才将竞争对手的工具用于日常生产力提升。 当然,强有力的诉讼通常需要更丑陋的事实,例如: 大规模抓取、虚假账户、规避速率限制、自动化提取、直接使用输出作为训练标签,或者内部记录显示买家明知是在克隆竞争对手的系统。 在这种情况下,一些典型的保护措施包括:隔离规则、经批准的企业账户、禁止为敏感工作使用消费者账户、训练数据来源日志、数据集隔离、提示和输出保留、用于检测“供应商 X 的 AI 生成”材料的自动扫描器,以及将编码智能体工作与模型训练数据隔离开的访问控制。 图片 (https://substackcdn.com/image/fetch/$s_!lGvc!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F7f53cd3c-f40d-4617-a9d1-1c713ea60057_900x822.png) 非常应景的论文。(http://arxiv.org/abs/2606.30317)
MCP 服务器需要清晰的设计模式,因为当展示太多工具或工具描述模糊时,LLM 会感到困惑。本文解释了如何构建 MCP 服务器,以确保 LLM 工具保持有用、安全且易于管理。
MCP 服务器设计不仅仅是普通的 API 设计,因为其客户端是一个通过阅读纯语言描述来选择工具的 LLM。它将真实的 MCP 服务器归纳为 5 种有用的模式,例如暴露数据的服务器、运行工作流的服务器、保持会话状态的服务器、组合多个服务器的服务器,或翻译混乱领域 API 的服务器。
作者还警告了 4 个常见错误,尤其是体积庞大的通用工具、模糊的工具描述、不安全的第三方内容,以及应该返回任务 ID 而非实时等待的慢速工具。他们还在 54 个额外的服务器上测试了这些模式标签,测量了传输延迟,并研究了当展示更多工具时,工具准确性如何变化。
关键结果是,显示太多可见工具会损害准确性,较弱的模型在工具数量介于 10 到 15 个时,准确率会下降到 90% 以下。良好的 MCP 设计主要在于使工具列表足够小、清晰、安全且稳定,以便 LLM 能够选择正确的操作。
图片 (https://substackcdn.com/image/fetch/$s_!QJh2!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc74336b6-cdd0-476a-87ef-311ffe49d686_869x633.png) 来自 Meta 的论文显示,量化推理模型常常失败,因为它们不断怀疑一个正确的答案,而不是完成它。(http://arxiv.org/abs/2606.00206)
其中许多模型推理得足够好,但压缩使它们在错误的时间犹豫不决。问题在于,后训练量化(一种在训练后压缩模型的方法)可以使推理模型运行成本更低,但同时也难以干脆利落地完成任务。
作者发现,强量化不仅仅是让模型能力变差,因为在许多失败案例中,模型已经得出了正确答案,但随后又自我怀疑。他们的核心观点是,量化在不确定的词汇选择上增加了噪声,使得模型更有可能选择像“wait”、“but”或“alternatively”这类会重新打开问题的词。
他们在数学、编码和科学任务上,使用了 5 个推理模型、多种量化方法以及从 1.5B 到 32B 不等的模型大小进行了测试。主要结果是,激进的量化导致过度思考的失败率高达 52%,而对 50 个犹豫词汇施加一个小的惩罚,可将推理长度减少 12% 到 23%,并且常常能保持或提高准确性。鉴于压缩模型被广泛用于节省内存和成本,了解到一个非常小的解码修复就可以阻止其中许多模型浪费 token 并丢失它们已经获得的答案,这一点至关重要。
NVIDIA 将 Nemotron-Labs-TwoTower-30B-A3B-Base-BF16 转变为一个写入速度提升 2.42 倍的生成器,同时保持了 98.7% 的基准测试质量。(https://huggingface.co/nvidia/Nemotron-Labs-TwoTower-30B-A3B-Base-BF16)
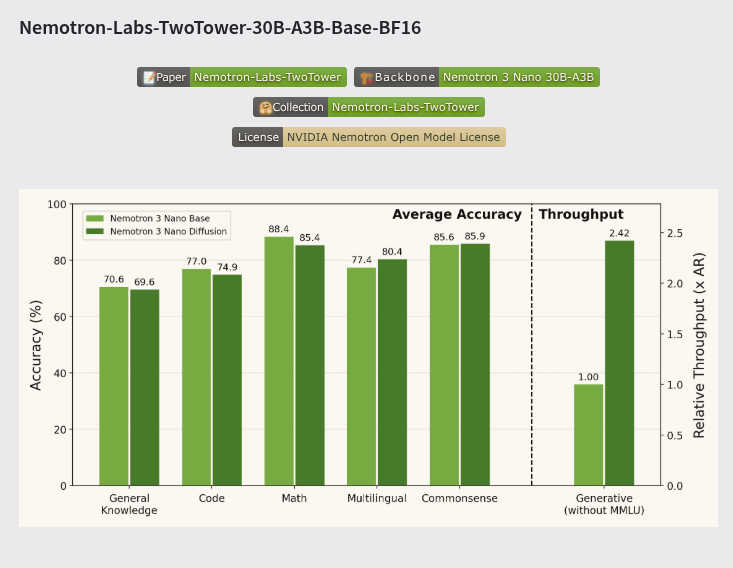{kind=link}
普通的 LLM 是一个一个地生成 token,因为每个新 token 都依赖于前一个。
NVIDIA 保留了上下文处理的旧系统,但增加了一个用于加速写入的第二塔。一个冻结的塔读取提示并存储记忆,而另一个塔则共同填充掩码 token 块。
第二个塔同时猜测多个位置,然后在多次传递中修正薄弱点。这将解码过程从一个狭窄的单 token 线性过程转变为一个基于块的细化过程。
所以,整体思路是:花费更多 GPU 内存来减少生成过程中的等待时间。
模型仍然逐块移动,因此过去的文本保持稳定,未来的文本也受到约束。
NVIDIA 报告称 MMLU 得分为 78.24,GSM8K 得分为 90.14,HumanEval 得分为 75.58。缺点在于硬件要求,因为全扩散模式需要 2 块 80GB 的 H100 或 A100 GPU。
这种方法看起来很有用,因为它重用了一个预训练的自回归骨干网络,而不是重建一切。在接近基线质量的情况下实现速度提升,对于长输出、智能体和高并发推理场景很有意义。
一个普通的 LLM 不断问一个问题:“下一个 token 是什么?”
Nemotron-Labs-TwoTower 问了一个更大的问题:“给定提示,我能否一次填充 16 个缺失的 token 槽位?”
第一个塔读取提示和已接受的文本,然后存储记忆。第二个塔查看一个掩码 slot 块,并行提出许多 token。
置信度低的猜测保持掩码状态,置信度高的猜测被锁定,然后该块再次被细化。一旦该块完成,第一个塔将其吸收为真实上下文,然后开始下一个块。
循环之所以存在,是因为语言在整个答案中仍然需要从左到右的顺序。速度来自于在每个块内部进行并行工作,而不是每一步只处理一个 token。
代价是,你运行的是两个大型模型副本,而不是一个。
以上就是今天的全部内容,我们明天见。
在 X (Twitter) 上与我联系 (https://x.com/rohanpaul_ai)
相似文章
@rohanpaul_ai: 我的newsletter最新一期已发布。https://rohanpaul.substack.com/p/central-bankers-now-fear-the-ai-gold… …
一份每日AI通讯,涵盖多个故事,包括央行行长对AI债务泡沫的警告、中国开发者通过灰色市场API购买便宜的Claude访问权限、Sakana的Fugu报告、中美AI模型成本对比、Deepseek新的推理优化方法,以及Meta开源的脑机文本系统。
@rohanpaul_ai: FT: OpenAI 提议将价值8520亿美元业务的5%股份给予美国政府,以缓解AI监管压力。这一想法借鉴了阿拉斯加……
OpenAI 已提议将其价值8520亿美元业务的5%股份给予美国政府,仿效阿拉斯加石油基金模式,以缓解AI监管压力。该计划需要获得国会和微软等主要利益相关者的批准,其他AI公司目前尚未加入。
OpenAI提议向特朗普政府提供5%股份以缓解华盛顿压力(5分钟阅读)
OpenAI提议向美国政府提供该公司5%的股份,价值约426亿美元,以缓解政治压力并解决对AI安全及来自中国模型竞争的担忧。
@DeRonin_: 哦老兄...太牛了,难道只有我看到了吗???
据报道,OpenAI提议向美国政府提供价值425亿美元的5%股份,这标志着AI治理和投资领域的一项重大举措。
美国250岁生日快乐,送上OpenAI的5%股权
OpenAI正与美政府谈判授予其5%股权,这反映了AI监管与产品开发同步推进的转变,并有人将其与阿拉斯加永久基金相提并论。